У додатку Excel крім майстра функцій є набір більш потужних інструментів для роботи з декількома вибірками і поглибленого аналізу даних. Це, зокрема, «Пакет анализа», який можна використовувати для розв’язання задач статистичної обробки вибіркових даних.
«Пакет анализа» – це надбудова, допоміжна програма, яка додає до Microsoft Office спеціальні команди або можливості. Щоб використовувати цю надбудову в програмі Excel, її потрібно передусім завантажити, для цього необхідно виконати такі дії:
-перейти на вкладку «Файл» і вибрати пункт «Параметры»;
-вибрати пункт «Надстройки», а потім у полі «Управление» – пункт «Надстройки Excel»;
-натиснути кнопку «Перейти»;
-у полі «Надстройки» встановити прапорець для надбудови «Пакет анализа» та натиснути кнопку ОК;
-якщо з'явиться повідомлення, що надбудову «Пакет анализа» ще не інстальовано на комп'ютері, натиснути кнопку «Да», щоб інсталювати її.
Після завантаження надбудови «Пакет анализа» на вкладці «Данные» у групі «Анализ» з’явиться команда «Анализ данных».
Досліджувані дані слід ввести у вигляді таблиці, де стовпцями є відповідні показники.
Для використання статистичного пакета аналіза даних необхідно:
-вибрати на стрічці вкладку «Данные»;
-вибрати команду «Анализ данных» (якщо команда відсутня, то необхідно встановити в Excel пакет аналізу даних);
-вибрати необхідний рядок у списку, що з'явився у вікні «Инструменты анализа» (рис. V);
-ввести вхідний і вихідний діапазони і вибрати необхідні параметри.
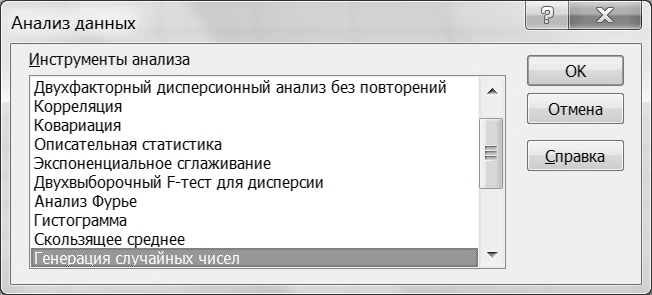
Рис. V. Вікно аналізу даних
Для визначення характеристик вибірки застосовують процедуру «Описательная статистика». Процедура дозволяє отримати статистичний звіт, що містить інформацію про центральну тенденцію і мінливість вхідних даних. Для виконання процедури необхідно:
-виконати команду «Данные» – «Анализ данных»;
-у списку «Инструменты анализа» вибрати рядок «Описательная статистика» і натиснути кнопку ОК, у діалоговому вікні вказати вхідний діапазон, тобто ввести посилання на комірки, які містять аналізовані дані;
-указати вихідний діапазон, тобто ввести посилання на комірки, у яких будуть виведені результати аналізу;
-установити прапорець у полі «Итоговая статистика»;
-установити прапорець у полі «Уровень надежности 95%»;
-натиснути кнопку ОК.
У результаті аналізу в зазначеному вихідному діапазоні для кожного стовпця даних будуть виведені такі статистичні характеристики: середнє, стандартна похибка (середнього), медіана, мода, стандартне відхилення, дисперсія вибірки, ексцес, асиметричність, інтервал, мінімум, максимум, сума, рахунок, найбільше, найменше, рівень надійності.
Усі отримані характеристики було розглянуто раніше, за винятком останніх чотирьох:
- мінімум – значення мінімального елемента вибірки;
- максимум – значення максимального елемента вибірки;
- сума – сума значень усіх елементів вибірки;
- рахунок – кількість елементів у вибірці.
Серед указаних характеристик найбільш важливими є такі показники, як середнє, стандартна похибка (середнього) і стандартне відхилення.
Для побудови лінійної моделі застосовують метод регресійного аналізу. Розглянемо приклад: побудувати лінійну модель залежності приросту прибутку Y залежно від інвестиційних вкладень в оборотні кошти X1 і основний капітал X2. Є статистичні дані за 7 підприємствами галузі (табл. Д.1).
Таблиця Д. 1
| Y
| 50
| 120
| 290
| 190
| 200
| 300
| 320
|
| X1
| 30
| 66
| 78
| 110
| 130
| 190
| 250
|
| X2
| 6
| 10
| 20
| 15
| 16
| 18
| 20
|
Виберемо лінійну модель  . Знайдемо її параметри й оцінимо якість з використанням засобів пакета аналізу. Насамперед запишемо вихідні дані в таблицю, показану на рис. VІ.
. Знайдемо її параметри й оцінимо якість з використанням засобів пакета аналізу. Насамперед запишемо вихідні дані в таблицю, показану на рис. VІ.
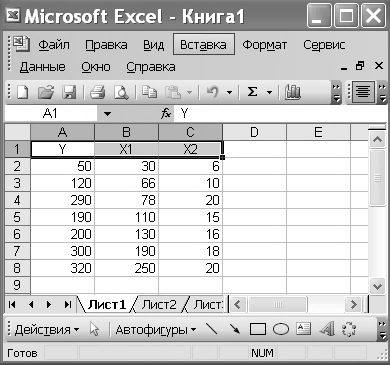
Рис. VІ. Введення даних на аркуші 1 таблиці Excel
На вкладці «Данные» натиснемо кнопку «Анализ данных». На екрані з'явиться вікно, у якому виберемо пункт «Регрессия». З'явиться діалогове вікно, зображене на рис. VІІ.
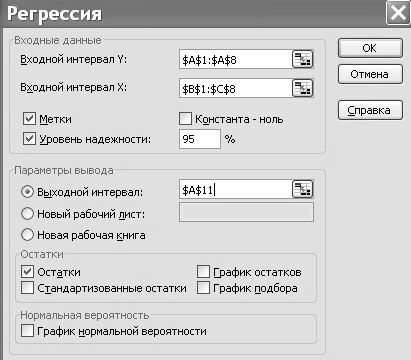
Рис. VІІ. Діалогове вікно функції «Регрессия» пакета аналізу
Діалогове вікно заповнюють таким чином:
· вхідний інтервал Y – діапазон (стовпець), який містить дані зі значеннями пояснювальної змінної, у розглядуваному прикладі: $A$1:$A$8;
· вхідний інтервал X – діапазон (стовпці), що містить дані зі значеннями пояснювальних змінних: $B$1:$C$8;
· «Метки» – прапорець, який указує, чи містять перші елементи зазначених діапазонів назви змінних (стовпців);
· константа-нуль – прапорець, який указує на наявність або відсутність вільного члена в рівнянні моделі;
· рівень надійності 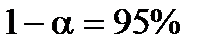 (вибирається однозначно);
(вибирається однозначно);
· вихідний інтервал. Достатньо вказати ліву верхню комірку майбутнього діапазону, у якій буде збережений звіт щодо побудови моделі ($A$11). Можна також вивести звіт на новий робочий аркуш або в нову книгу, для чого вводять прапорець у відповідне вікно.
Для отримання розрахункових значень 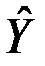 , залишків
, залишків 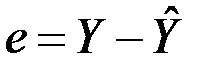 або графіків слід установити відповідні прапорці в діалоговому вікні. Після заповнення діалогового вікна необхідно натиснути OК.
або графіків слід установити відповідні прапорці в діалоговому вікні. Після заповнення діалогового вікна необхідно натиснути OК.
У результаті аналізу одержимо звіт, наведений на рис. VІІІ.
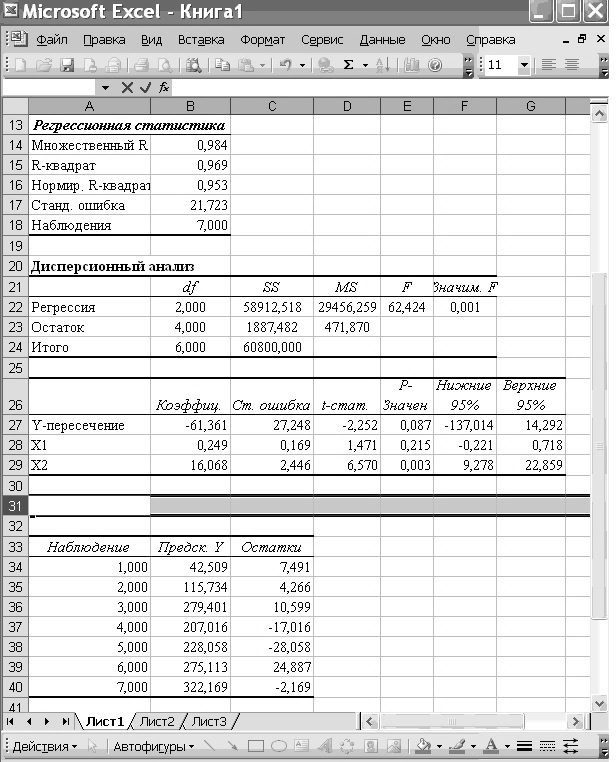
Рис. VІІІ . Звіт про результати регресійного аналізу
Розглянемо регресійну статистику:
· множинний R – це 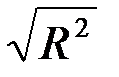 , де
, де 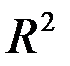 – R-квадрат (коефіцієнт детермінації);
– R-квадрат (коефіцієнт детермінації); 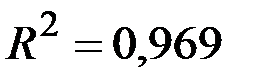 свідчить про те, що зміни залежної змінної на 96,9% визначені змінами включених у модель пояснювальних змінних;
свідчить про те, що зміни залежної змінної на 96,9% визначені змінами включених у модель пояснювальних змінних;
· нормований R-квадрат – скорегований коефіцієнт детермінації 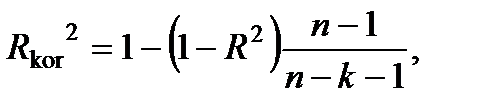 де n – кількість спостережень; k – кількість пояснювальних змінних;
де n – кількість спостережень; k – кількість пояснювальних змінних;
· стандартна похибка регресії 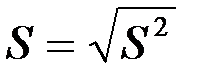 , де
, де 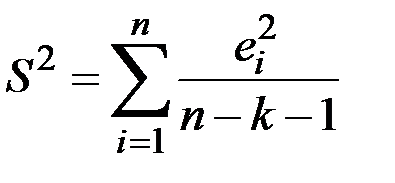 – непояснена дисперсія;
– непояснена дисперсія;
· спостереження – кількість спостережень n.
У табл. Д. 2 наведено параметри моделі (стовпець «Коефіцієнти») і результати їх перевірки на статистичну значущість. Таким чином, рівняння моделі має вигляд 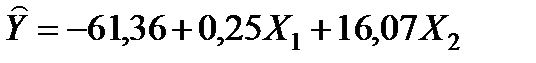 .
.
Таблиця Д. 2
|
| Коефіцієнти
| Стандартна похибка
| t-статистика
| P-значення
| Нижні 95%
| Верхні 95%
|
| Y-перетин
| 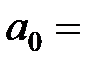 -61,36 -61,36
| 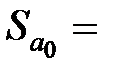 27,25 27,25
| 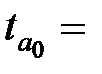 -2,25 -2,25
| 0,09
| -137,01
| 14,29
|
| X1
| 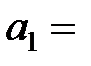 0,25 0,25
| 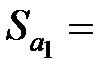 0,17 0,17
| 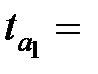 1,47 1,47
| 0,22
| -0,22
| 0,72
|
| X2
| 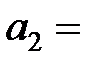 16,07 16,07
| 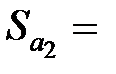 2,45 2,45
| 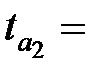 6,57 6,57
| 0,00
| 9,28
| 22,86
|
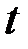 -Статистика отримана діленням коефіцієнтів на стандартні похибки. Як нам уже відомо, якщо розрахункове значення t-статистики перевищує критичне, отримане з таблиць теоретичного розподілу Стьюдента з параметрами
-Статистика отримана діленням коефіцієнтів на стандартні похибки. Як нам уже відомо, якщо розрахункове значення t-статистики перевищує критичне, отримане з таблиць теоретичного розподілу Стьюдента з параметрами 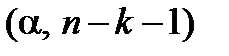 , то коефіцієнти регресії є статистично значущі. Можна знайти критичні значення за таблицями t-розподілу і провести порівняння [для даного прикладу t (0,05, 4)=2,77].
, то коефіцієнти регресії є статистично значущі. Можна знайти критичні значення за таблицями t-розподілу і провести порівняння [для даного прикладу t (0,05, 4)=2,77].
У пакеті аналізу передбачено інший інструмент оцінки t-статистики: p-значення – величину, застосовну для статистичної перевірки гіпотез. Вона є ймовірністю того, що критичне значення статистики за використовуваним критерієм (у розглядуваному випадку – t-статистики Стьюдента) перевищить значення, обчислене за вибіркою. Рішення про прийняття або відхилення нульової гіпотези приймають, порівнюючи p-значення з вибраним рівнем значущості a. Якщо 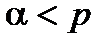 , то нульову гіпотезу відхиляють і приймають альтернативну, про статистичну значущість параметра.
, то нульову гіпотезу відхиляють і приймають альтернативну, про статистичну значущість параметра.
У даному прикладі параметр 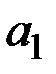 є статистично незначущий, тому що
є статистично незначущий, тому що 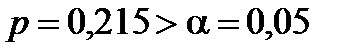 ; параметр
; параметр 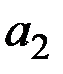 є статистично значущий,
є статистично значущий, 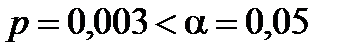 .
.
Нижні 95%, верхні 95% – довірчі інтервали для параметрів моделі. Довірчі інтервали будують тільки для статистично значущих величин. У розглядуваному випадку для параметра 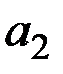 слушне таке:
слушне таке: 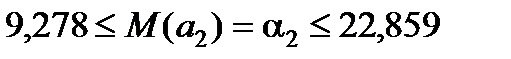 , тобто з надійністю 95% істинне значення параметра належить указаному інтервалу.
, тобто з надійністю 95% істинне значення параметра належить указаному інтервалу.
Розглянемо таблицю дисперсійного аналізу (табл. Д. 3).
Таблиця Д. 3
|
| df
| SS
| MS
| F
| Значущість F
|
| Регресія
| 2,000
| 58912,518
| 29456,259
| 62,424
| 0,001
|
| Залишок
| 4,000
| 1887,482
| 471,870
|
|
|
| Всього
| 6,000
| 60800,000
|
|
|
|
У табл. Д. 3 наведено такі показники:
· df (degrees of freedom) – кількість степенів вільності, пов’язана з кількістю одиниць сукупності 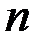 і з кількістю визначених для неї констант
і з кількістю визначених для неї констант 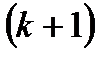 ;
;
· SS – позначення повних сум квадратів. У цьому стовпці рядка «Регресія» виводиться факторна сума відхилень ESS.= 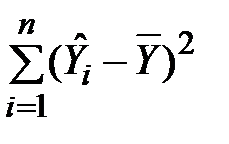 ; у рядку «Залишок» – залишкова сума відхилень RSS=
; у рядку «Залишок» – залишкова сума відхилень RSS= 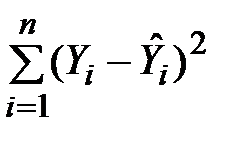 , а в рядку «Всього» – загальна сума відхилень TSS=
, а в рядку «Всього» – загальна сума відхилень TSS= 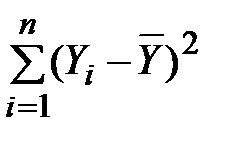 ;
;
· MS – позначення середніх сум квадратів;
· F і Значущість F – дозволяють перевірити значущість рівняння регресії. За емпіричним значенням статистики F перевіряють гіпотезу про рівність нулю одночасно всіх рівнянь моделі. Рівняння регресії є значуще за рівнем a, якщо 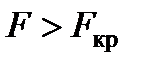 , де
, де 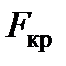 – табличне значення
– табличне значення
F-критерію Фішера з параметрами 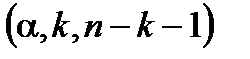 . Якщо значущість
. Якщо значущість 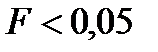 , то рівняння регресії є статистично значуще з імовірністю 95%.
, то рівняння регресії є статистично значуще з імовірністю 95%.
Зміст
Передмова. 3
Лабораторна робота 1. Аналіз щільності зв’язків між факторами.
Основи кореляційного аналізу. 4
Лабораторна робота 2. Економетрична модель із двома змінними:
побудова і аналіз. 16
Лабораторна робота 3. Загальна лінійна економетрична модель:
побудова і аналіз. 39
Додатки. 64







