менее 9 баллов - pиск суицида незначителен
9.1 -15.50 баллов - pиск суицида пpисутствует
более 15.51 балла - pиск суицида значителен
Приложение 4
Методика экспертной диагностики социометрического статуса
"Социометрия"*
Для социометрического обследования может использоваться компьютерный вариант методики “Социометрия”, выполненный в среде FoxPro 2.5 для Windows. Она представляет собой несколько баз данных и процедуры обработки, а также графической интерпретации результатов тестирования. Структура баз данных представлена в схеме.
| Main
|
| naim
|
|
 n_g n_g
|
| n_g
|
|
 fam fam
|
| naim
|
|
| v1
|
|
|
|
| ...
|
|
|
|
| v8
|
|
|
|
| st¯
|
|
|
|
 kl kl
|
| inter
|
|
| int
|
| int
|
|
|
|
| text
|
|
Рис. 1 Структура баз данных
База main содержит поле Fam, предназначенное для хранения фамилии и инициалов сотрудников. Каждый из членов коллектива оценивает всех, включая себя самого по восьми вопросам, поэтому поля v1 - v8 содержат символьные строки оценок для каждого тестируемого по каждому из вопросов во всех анкетах. Поля st, kl, int заполняются в процессе обработки результатов тестирования. Поле n_g является индексным и служит для установления реляционного отношения с базой naim, содержащей названия подразделений для различных групп тестирования и заполняемой на этапе ввода данных. База inter содержит различные текстовые интерпретации результатов обследования. В процессе обработки информации создается несколько вспомогательных баз, которые после завершения процедуры обработки уничтожаются.
Для анализа данных необходимо провести некоторые вспомогательные вычисления, которые назовем этапом подготовки данных. Для каждого сотрудника коллектива рассчитываются значения статуса (делового – вопросы анкеты 1,3,6 или эмоционального – вопросы 2,4,5) и записывается в поле st базы main:
 - частота появления значения “+” для i -того сотрудника в k анкетах по t вопросам,
- частота появления значения “+” для i -того сотрудника в k анкетах по t вопросам,
где l+ – количество положительных выборов ("+") i -го сотрудника, i =  . Расчет значений статуса для каждого сотрудника требует 1+N арифметических операций умножения и деления.
. Расчет значений статуса для каждого сотрудника требует 1+N арифметических операций умножения и деления.
Социометрический тест при традиционной обработке данных ограничивается расчетом значений статуса, по которым можно судить лишь о том, является ли сотрудник коллектива “лидером”, “предпочитаемым” или “аутсайдером”. Сотрудники располагаются в порядке убывания статуса. В базе данных поле статуса является индексным, записи в базе располагаются в порядке убывания индекса. Для каждой пары сослуживцев вводятся два дополнительных показателя:
 – коэффициент “психологической сплоченности пары” (частота появления оценок “++” и “- -” для i- того и j -того сотрудников в k анкетах по t вопросам),
– коэффициент “психологической сплоченности пары” (частота появления оценок “++” и “- -” для i- того и j -того сотрудников в k анкетах по t вопросам),
 – коэффициент “психологической напряженности пары” (частота появления оценок “+ -” в k анкетах по t вопросам),
– коэффициент “психологической напряженности пары” (частота появления оценок “+ -” в k анкетах по t вопросам),
где l 1 – количество одинаковых по знаку оценок (“+ +”, либо “- -”);
l2 – количество разных по знаку оценок (“+ - ”);
k – количество анкет;
t – количество вопросов (3 или 6);
N – количество человек в коллективе;
i =  ; j =
; j =  .
.
Значения pij и qij расчитываются для всех возможных пар сотрудников. В процедуре обработки теста это одна из самых продолжительных по времени операций, т.к. организована в виде вложенных циклов. Начиная перебор фамилий в ранжированном списке “сверху - вниз” (или продвигаясь по базе данных от первой к последней записи), для каждой фамилии (записи) необходимо последовательно выбрать все фамилии которые расположенные ниже нее и для каждой пары посчитать нужные значения. Таким образом, необходимо выполнить 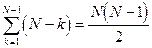 операций умножения и деления.
операций умножения и деления.
Далее проводится процесс кластеризации: первый сотрудник в ранжированном списке образует первый кластер. Перебирая поочередно сотрудников из списка, поступаем согласно разработанному алгоритму.
При объединении сотрудников A и B в один кластер (одну группировку) происходит усреднение значений p и q у оставшихся сотрудников с сотрудниками, вошедшими в один кластер. То есть вместо двух значений p и q с сотрудниками A и B у каждого из оставшихся сотрудников будет по одному значению p и q с кластером AB. При присоединении С к кластеру АВ происходит пересчет матриц P и Q следующим образом:

 ,
,  ,
,
 , где
, где 
 , N – количество сотрудников, не вошедших ни в один из кластеров, NAB – количество сотрудников в кластере AB.
, N – количество сотрудников, не вошедших ни в один из кластеров, NAB – количество сотрудников в кластере AB.
На этапе подготовки к процессу кластеризации количество арифметических операций составляет  . Процесс кластеризации данных, ввиду пересчета матриц P и Q, может значительно увеличить количество операций при образовании новых кластеров. Очевидно, что в данном случае применение ПЭВМ является не только возможным, но и необходимым.
. Процесс кластеризации данных, ввиду пересчета матриц P и Q, может значительно увеличить количество операций при образовании новых кластеров. Очевидно, что в данном случае применение ПЭВМ является не только возможным, но и необходимым.
Программой реализована графическая интерпретация результатов кластеризации: по оси Y откладываются значения статуса, по оси X – точки, соответствующие сотрудникам коллектива. Кластеры отделяются друг от друга вертикальной пунктирной линией. В каждом кластере левее точки с максимальным статусом лежат точки ядра кластера, правее – точки неопределенной группы. Правая асимметрия кластеров свидетельствует о монолитности, сплоченности кластера; левая асимметрия – о рыхлости, неустойчивости кластера (Рис. 2-4).
Применение процесса кластеризации данных позволяет получить списки лидеров, состав группировок коллектива, члены которых поддерживают каждого из лидеров, выделить в группировках ядро и неопределенную группу, рассчитать количественные показатели межличностных взаимоотношений внутри каждой из группировок и между группировками, рассчитать количественные показатели межличностных взаимоотношений для всего коллектива.








