Объект исследования: процесс адаптивного тестирования.
Результаты, полученные лично автором: разработан алгоритм адаптивного тестирования, удовлетворяющий всем поставленным требованиям.
Анализ выявил что, для увеличения точности оценки знаний студента, за исключением устного опроса и выполнения заданий, применяется тестирование. В данной дипломной работе мы затронем такую тему как компьютерное тестирование. Для улучшения теста применяют алгоритмы адаптации, что в свою очередь повышает точность оценки «простого» тестирования и сокращает время его прохождения студентом.
Адаптивное тестирование – разновидность тестирования, при которой порядок предъявления заданий (или трудность заданий) зависит от ответов испытуемого на предыдущие задания. В настоящее время адаптивное тестирование реализуется в основном в виде различных алгоритмов компьютерного тестирования.
Типы алгоритмов тестирования:
Алгоритм тестирования «жесткий»
Данный алгоритм основывается на формировании области незнания, т.е. вопросы будут задаваться по темам, которые пользователь не знает, или знает плохо. Таким образом, пользователь наказывается за незнание какой-либо темы.
Алгоритм тестирования «мягкий»
Алгоритм основывается на формировании области знания, т.е. вопросы будут задаваться по темам, которые пользователь знает хорошо. Таким образом, пользователь не наказывается за незнание какой-либо темы.
Алгоритм тестирования «комбинированный»
Алгоритм сочетает в себе достоинства предыдущих алгоритмов. Пользователь не наказывается за незнание какой-либо темы, но и не поощряется чрезмерно. В данном алгоритме нет области знания и незнания – есть просто область тем, из которых выбираются вопросы.
Таким образом, пользователь не штрафуется, если у него мало баллов, но и не поощряется, если баллов много. Этот алгоритм самый предпочтительный по моему мнению.
После прекращения процесса тестирования определяется рейтинг пользователя, который вычисляется по формуле:
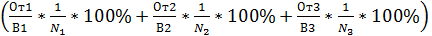 , где
, где
· От1, От2, От3 – количество верных ответов первого, второго и третьего соответственно.
· В1, В2, В3 – общее количество заданных вопросов первого, второго и третьего уровня соответственно.
· N1, N2, N3 – коэффициенты адаптивности для каждого уровня.
Основные критерии вопросов тестирования:
Основные критерии вопросов для алгоритма адаптивного тестирования будут разделяться по двум направлениям: уровень сложности вопроса и тема вопроса.
Уровень сложности вопроса будет разделяться на:
Сложный
Базовый
Лёгкий
Количество тем для вопросов может быть любым на усмотрение преподавателя.
Список литературы
1. Данг Х.Ф., Камаев В.А., Шабалина О.Ф. Метод разработки алгоритмов адаптивного тестирования. Волгоград: ВГТУ, 2012.
2. Андреев, А. Б. Экспертная система анализа знаний «Эксперт-ТС» / А. Б. Андреев, А. В. Акимов, Ю. Е. Усачев // Proceedings. IEEE International Conference on Advanced Learning Technologies (ICALT 2002). 9-12 September 2002. Kazan, Tatrstan, Russia, 2002.
3. Артемов, А. Модульно-рейтинговая система / А. Артемов, Н. Павлова, Т. Сидорова - Высшее образование в России. - 1999. - № 4. - С. 121-125.
Материал поступил в редколлегию 03.04.2017
УДК 004.4
О.И. Драгуновская
Научный руководитель: доцент кафедры «Информатика и программное обеспечение», к.т.н., Д.И. Булатицкий
o.dragunovskaya@gmail.com
РАЗРАБОТКА ПОДСИСТЕМЫ ИМПОРТА ДАННЫХ ИЗ БАНКОВСКИХ ВЫПИСОК В СИСТЕМЕ ФИНАНСОВОГО УЧЁТА «ПЛАНФАКТ»
Объект исследования: система финансового учета «ПланФакт».
Результаты, полученные лично автором: разработка алгоритмов и программная реализация распознавания и импорта данных из банковских выписок и синхронизации с банками.
«ПланФакт» (https://planfact.io) представляет собой сервис для ведения финансового учета, разрабатываемый компанией «Максимум Веб». Он позволяет владельцам малого бизнеса контролировать все денежные потоки предприятия, видеть сводные данные о балансе, вести счета в разных валютах, разносить операции по разным видам деятельности.
Для работы с системой пользователю в первую очередь необходимо корректно и регулярно заносить всю информацию о движении денег в бизнесе. Основной способ – это ручной ввод операций через интерфейс приложения. Но он отнимает у пользователей много времени, может приводить к неточностям. Поэтому важнейшей частью системы, во многом влияющей на ее успех, является возможность загрузки данных из внешних источников.
Каждый бизнесмен, имеющий банковский счет юридического лица, может получить в своем банк-клиенте выписку за выбранный период и загрузить ее в «ПланФакт». Выписки предоставляются в стандартном формате «1c Format Exchange». Но такой способ не позволяет выгрузить информацию о наличных счетах. Многие пользователи хотят выгружать такие данные из сторонних систем, для этого реализован импорт из Excel, а также разработан расширенный формат выписки, который в отличии от стандартного позволяет загружать информацию о статьях и проектах, к которым относятся операции.
Импорт из файла существенно сокращает затраты пользователей при использовании сервиса, но все же требует получения и загрузки данных через определенные интервалы времени. Для избавления клиентов от этой работы в сервисе реализуется возможность автоматической интеграции данных. На данный момент уже внедрена синхронизация с банком «Тинькофф», на финальной стадии находится реализация синхронизации с банком «Точка». Также на стадии внедрения находится возможность интеграции с онлайн-кассами, которые по законодательству РФ в скором времени должны заменить обычные кассовые аппараты.
Непосредственно мною из ранее рассмотренных способов загрузки разрабатывается подсистема импорта из банковских выписок в стандартном и расширенном формате, автоматическая интеграция из банков «Тинькофф» и «Точка». Среди плюсов данных способов стоит отметить колоссальное уменьшение затрат на ведение учета, сокращение числа ошибок, а также возможность сохранить более детальную информацию, которая опускается при ручном вводе. К существующим на данном этапе недостаткам можно отнести возможное дублирование информации, а также неверное распознавание типов некоторых операций.
Разработка подсистемы импорта – нетривиальная задача, которая подразумевает проведение глубокого анализа, составление и написание совокупности алгоритмов, а также тестирование выписок с различными типами операций из разных банков. К данному моменту мы уже столкнулись с рядом проблем, часть из которых полностью или частично решена. Среди них сопоставление плана с фактом. Сложность состоит в том, чтобы сопоставить операцию из выписки с нужной из системы, поняв какие поля и с какой точностью должны совпадать.
Банковская выписка формируется пользователем, как правило, по каждому счету отдельно, и поэтому необходимо анализировать каждую операцию на предмет того, не является ли она перемещением на собственный счет, в случае которого необходимо создавать парную операцию.
Несмотря на возможность импорта пользователи частично все равно заносят информацию вручную, и из-за этого при импорте из выписок возникает проблема сопоставления контрагентов в системе, информацию о которых человек, как правило, вносит только частично. Усложняет это процесс подстановка для физических лиц в платежах из выписок ИНН банков.
Как уже было сказано выше, для безналичных операций в выписках из банка не указываются статьи, в связи с этим реализуется возможность запоминания этих сведений по определенным правилам и дальнейшая их подстановка.
При внедрении автоматической интеграции добавляется еще одна сложность – отсутствие какого-либо единого формата ответа банков через API, стоит отметить, что хоть при ручном формировании выписок этот формат и есть, но в реальности каждый банк все равно имеет свои нюансы при составлении выписок.
Подводя итог, следует сказать, что на текущий момент уже проделан большой объем работ, как исследовательского характера (изучение форматов разных банков, тонкостей интерпретации некоторых операций), так и, непосредственно, по разработке и внедрению алгоритмов импорта и синхронизации.
Среди планов дальнейшей работы: синхронизация с новыми банками, улучшение алгоритма распознавания выписок (решение проблемы сопоставления контрагентов с учетом возможной подстановки ИНН банков, увеличение возможностей расширенной выписки, добавление возможности пользовательской настройки правил сопоставлений для различных сущностей), а также реализация возможности загрузки данных через API сервиса.
Материал поступил в редколлегию 03.04.2017
УДК 519.81
И.Г. Егорова
Научный руководитель: заведующий кафедрой «Информатика и программное обеспечение», к.т.н., доцент А.Г. Подвесовский
irishka-egorova14@yandex.ru
РАЗРАБОТКА СИСТЕМЫ ПОДДЕРЖКИ РАСПРЕДЕЛЕНИЯ СТУДЕНТОВ ПО РУКОВОДИТЕЛЯМ ВЫПУСКНЫХ КВАЛИФИКАЦИОННЫХ РАБОТ С ПРИМЕНЕНИЕМ МОДЕЛИ ДВУСТОРОННЕГО МАТЧИНГА
Объект исследования: задача распределения студентов по руководителям выпускных квалификационных работ.
Результаты, полученные лично автором: разработана система программной поддержки распределения студентов по руководителям выпускных квалификационных работ (программная реализация).
Подготовка и защита выпускной квалификационной работы (ВКР) является важным завершающим этапом освоения образовательной программы студентами любого уровня образования. Распределение студентов старших курсов по руководителям ВКР происходит на выпускающих кафедрах не реже одного раза в год, а в ряде случаев, при наличии на кафедре нескольких форм и уровней образования – несколько раз в год. При этом в процессе распределения необходимо учитывать множество факторов, в той или иной степени определяющих соответствие студента и преподавателя и, как следствие, возможность и эффективность совместной работы.
Обеспечить эффективное распределение, которое бы учитывало многообразие критериев и удовлетворяло как студентов, так и преподавателей, представляет собой весьма непростую задачу. Особенно ярко это проявляется в условиях крупной выпускающей кафедры, реализующей несколько образовательных программ и характеризующейся большим количеством студентов и многочисленным преподавательским составом. Как показывает практика, распределение в «ручном» режиме не позволяет в полной мере учесть все критерии соответствия и пожелания обеих сторон и, как следствие, порождает волну неудовлетворенности как со стороны студентов, так и со стороны преподавателей, что приводит в дальнейшем к многочисленным переходам студентов от руководителя к руководителю, и в конечном итоге негативно отражается на организации процесса выполнения ВКР в целом.
С учетом этого, на кафедре «Информатика и программное обеспечение» было принято решение создать систему программной поддержки распределения студентов по руководителям ВКР, для которой разработать модель оптимизации распределения. В качестве основы для построения оптимизационной модели было предложено использовать модель двустороннего матчинга. Данная модель опирается на решение задачи о формировании набора устойчивых паросочетаний между элементами двух непересекающихся множеств, где для каждого элемента первого множества существует свое распределение предпочтений между элементами второго множества, и наоборот. Применительно к рассматриваемой задаче, имеются множества студентов и преподавателей, и для формирования паросочетаний используется схема «многие к одному»: каждый студент работает под руководством одного преподавателя, но каждый преподаватель может руководить несколькими студентами. Под устойчивостью понимается отсутствие у любого студента желания и возможности перехода от назначенного ему руководителя к другому (при этом без наложения административных запретов на подобные переходы)
Процедура распределения основана на алгоритме Гейла-Шепли, называемом также алгоритмом «отложенного принятия предложения». Рассмотрим ее основные этапы.
1. Для каждого направления подготовки, реализуемого кафедрой, формируется список преподавателей, привлекаемых к руководству ВКР по данному направлению.
2. Для каждого руководителя устанавливается объем квоты q (максимальное число студентов, которыми он может руководить).
3. Каждый студент формирует список преподавателей, под руководством которых он хотел бы работать, ранжируя его по убыванию предпочтений.
4. Каждый преподаватель получает список студентов, указавших его на первом месте в своих списках предпочтений. Соответствующий список называется списком ожидания преподавателя. Если число студентов в списке ожидания превышает объем квоты преподавателя, то он оставляет в нем q наиболее предпочтительных для себя студентов, а остальные студенты получают отказ.
5. Студенты, получившие отказ от преподавателя своего первого выбора, попадают в списки ожидания преподавателей своего второго выбора. Соответствующая информация сообщается преподавателям. Обновленные (дополненные) списки ожидания, в случае превышения квоты, ранжируются преподавателем по предпочтительности и вновь усекаются до объема q.
6. Аналогичная процедура повторяется, пока каждый студент не закрепится в списке ожидания у одного из преподавателей, либо не будет отклонен всеми преподавателями.
Описанная процедура положена в основу системы программной поддержки распределения студентов по руководителям ВКР, которая реализована в виде web-сервиса в составе комплексной информационной системы кафедры «Информатика и программное обеспечение», разработанной на основе сервис-ориентированной платформы. Сервис распределения взаимодействует с ядром этой платформы с помощью шины (Enterprise Service Bus), получая информацию о студентах и преподавателях, которая хранится главным образом на сервере OpenLDAP.
Основу серверной части разработанной системы составляет описанная выше процедура распределения. Клиентской часть содержит личные кабинеты студентов, преподавателей и ответственного за распределение. Для хранения информации о всех шагах распределения используется база данных сервера.
Материал поступил в редколлегию 20.04.2017
УДК 519.81
М.А. Ермакова
Научный руководитель: доцент кафедры «Информатика и программное обеспечение», к.т.н., Д.В. Титарев
ermakova_marina_bstu@mail.ru







