Дискриминантный анализ является методом классификации многомерных наблюдений и позволяет изучать различия между двумя и более группами объектов по нескольким признакам. Например, разбиение совокупности экономических объектов на несколько однородных групп по значениям каких-либо показателей производственно-хозяйственной деятельности.
Совокупность экономических объектов трактуется как совокупность носителей многомерных выборочных значений, образующих выборку наблюдений за многомерной случайной величиной. Каждое многомерное наблюдение – реализация многомерной случайной величины – описывает конкретный объект изучаемой совокупности и может быть отнесено к одному из классов. Для реализации дискриминантного анализа необходимо иметь априорную информацию о типе распределения многомерной случайной величины. Если же такой априорной информации нет, то классы выделяются по степени «близости» объектов: объекты внутри класса «близки» между собой, но далеки от объектов других классов. Расстояние между объектами определяется, например, как обычное евклидово расстояние в n-мерном пространстве.
Дискриминантный анализ решает задачи нескольких типов. Задачи первого типа предполагают наличие информации о некотором числе объектов, характеристики каждого из которых позволяют отнести объекты к одной из двух или более группировок. На основе этой информации находится функция, позволяющая поставить в соответствие новым объектам характерные для них группы. Построение такой функции и составляет задачу дискриминации.
Второй тип задачи относится к ситуации, когда признаки принадлежности объекта к той или иной группе потеряны, и их нужно восстановить.
Задачи третьего типа связаны с предсказанием будущих событий на основании имеющихся данных. Такие задачи возникают при прогнозе, например, финансового состояния предприятий в будущих периодах.
Дискриминантный анализ объединяет методы классификации наблюдений по группам и методы дискриминации для интерпретации межгрупповых различий.
Методы классификации связаны с получением одной или нескольких функций, обеспечивающих возможность отнесения данного объекта к одной из групп. Эти функции называются классифицирующими и зависят от значений переменных таким образом, что появляется возможность отнести каждый объект к одной из групп.
Основной целью дискриминации является нахождение линейной комбинации переменных, которая оптимально разделяет рассматриваемые группы. Линейная функция
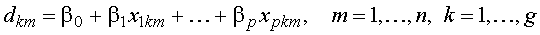
называется канонической дискриминантной функцией с неизвестными коэффициентами 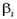 .
.
где, nk – число объектов в каждой группе;
g – число групп (классов);
p – число дискриминантных переменных.
dkm – значение дискриминантной функции для m-го объекта в группе k;
xikm – значение дискриминантной переменной xi для m-го объекта в группе k.
При разработке модели дискриминации учитываются предлагаемые методом дискриминантного анализа условия:
1. g ≥ 2 – число групп (классов) должно быть больше или равно 2.
2. nk ≥ 2 – число объектов в каждой группе должно быть больше или равно 2.
3. 0 < p < (n – 2) – число дискриминантных переменных (показателей) должно быть по крайней мере на 2 меньше общего числа объектов.
4. Дискриминантные переменные измеряются в интервальной шкале. Переменные относятся к интервальной шкале, если разность (интервал) между двумя значениями имеет эмпирическую значимость. Они могут обрабатываться любыми статистическими методами без ограничений. Так, например, среднее значение является полноценным статистическим показателем для характеристики таких переменных.
5. Дискриминантные переменные линейно независимы.
6. Ковариационные матрицы групп примерно равны. Если независимые переменные принадлежат к интервальной шкале, то их называют ковариациями, а соответствующий анализ — ковариационным.
7. Дискриминантные переменные в каждой группе подчиняются нормальному закону распределения. При таком распределении большая часть значений группируется около некоторого среднего значения, по обе стороны от которого частота наблюдений равномерно снижается.
Каноническая дискриминантная функция строится при известной принадлежности объектов к тому или иному классу и используется для объяснения различий между классами.
С геометрической точки зрения дискриминантные функции определяют гиперповерхности в p-мерном пространстве. В частном случае при p = 2 она является прямой, а при p = 3 – плоскостью.
Число канонических дискриминантных функций на единицу меньше числа групп g. Коэффициенты 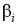 первой канонической дискриминантной функции выбираются так, чтобы центроиды различных групп как можно больше отличались друг от друга. Коэффициенты второй группы выбираются также, но при этом налагается дополнительное условие, чтобы значения второй функции были некоррелированы со значениями первой. Аналогично определяются и другие функции. Отсюда следует, что любая каноническая дискриминантная функция
первой канонической дискриминантной функции выбираются так, чтобы центроиды различных групп как можно больше отличались друг от друга. Коэффициенты второй группы выбираются также, но при этом налагается дополнительное условие, чтобы значения второй функции были некоррелированы со значениями первой. Аналогично определяются и другие функции. Отсюда следует, что любая каноническая дискриминантная функция 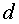 имеет нулевую внутригрупповую корреляцию с
имеет нулевую внутригрупповую корреляцию с 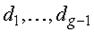 .
.
Коэффициенты канонической дискриминантной функции. Для получения коэффициентов 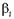 канонической дискриминантной функции необходим статистический критерий различения групп. Классификация переменных будет осуществляться тем лучше, чем меньше рассеяние точек относительно центроида (срединного значения) внутри группы и чем больше расстояние между центроидами групп. Большая внутригрупповая вариация нежелательна, так как в этом случае любое заданное расстояние между двумя средними тем менее значимо в статистическом смысле, чем больше вариация распределений, соответствующих этим средним.
канонической дискриминантной функции необходим статистический критерий различения групп. Классификация переменных будет осуществляться тем лучше, чем меньше рассеяние точек относительно центроида (срединного значения) внутри группы и чем больше расстояние между центроидами групп. Большая внутригрупповая вариация нежелательна, так как в этом случае любое заданное расстояние между двумя средними тем менее значимо в статистическом смысле, чем больше вариация распределений, соответствующих этим средним.
Один из методов поиска наилучшей дискриминации данных заключается в нахождении такой канонической дискриминантной функции d, которая бы максимизировала отношение межгрупповой вариации к внутригрупповой:
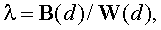
где B – межгрупповая и W – внутригрупповая матрицы рассеяния наблюдаемых переменных от средних.
Матрицы W и B содержат всю основную информацию о зависимости внутри групп и между группами. Для лучшего разделения наблюдений на группы подбираются коэффициенты дискриминантной функции из условия максимизации отношения межгрупповой матрицы рассеяния к внутригрупповой матрице рассеяния при условии ортогональности дискриминантных плоскостей.
Структурные коэффициенты дискриминантной функции определяются коэффициентами взаимной корреляции между отдельными переменными и дискриминантной функцией. Если относительно некоторой переменной абсолютная величина коэффициента велика, то вся информация о дискриминантной функции заключена в этой переменной.
Структурные коэффициенты полезны при классификации групп. Они по своей информативности несколько отличаются от стандартизованных коэффициентов. Стандартизованные коэффициенты показывают вклад переменных в значение дискриминантной функции. Если две переменные сильно коррелированы, то их стандартизованные коэффициенты могут быть меньше по сравнению с теми случаями, когда используется только одна из этих переменных. Такое распределение величины стандартизованного коэффициента объясняется тем, что при их вычислении учитывается влияние всех переменных. Структурные же коэффициенты являются парными корреляциями и на них не влияют взаимные зависимости прочих переменных.
Число дискриминантных функций. Общее число дискриминантных функций не превышает числа дискриминантных переменных и, по крайней мере, на 1 меньше числа групп. Степень разделения выборочных групп зависит от величины собственных чисел: чем больше собственное число, тем сильнее разделение. Наибольшей разделительной способностью обладает первая дискриминантная функция, соответствующая наибольшему собственному числу 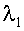 , вторая обеспечивает максимальное различение после первой и т. д. Различительную способность i-й функции оценивают по относительной величине в процентах собственного числа
, вторая обеспечивает максимальное различение после первой и т. д. Различительную способность i-й функции оценивают по относительной величине в процентах собственного числа 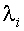 от суммы всех
от суммы всех 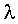 .
.
Коэффициент канонической корреляции 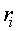 позволяет оценить полезность дискриминантной функции. Каноническая корреляция является мерой связи между двумя множествами переменных. Максимальная величина этого коэффициента равна 1. Чем больше величина , тем лучше разделительная способность дискриминантной функции.
позволяет оценить полезность дискриминантной функции. Каноническая корреляция является мерой связи между двумя множествами переменных. Максимальная величина этого коэффициента равна 1. Чем больше величина , тем лучше разделительная способность дискриминантной функции.
Для классификации наблюдений по группам используют информацию, содержащуюся в дискриминантных переменных.
Классифицирующие функции. В дискриминантном анализе процедура классификации используется для определения принадлежности к той или иной группе случайно выбранных объектов, которые не были включены при выводе дискриминантной и классифицирующих функций. Для проверки точности классификации применяют классифицирующие функции к тем объектам, по которым они были получены. По доле правильно классифицированных объектов можно оценить точность процедуры классификации.
Число классифицирующих функций равняется количеству групп, изначально заданных при построении дискриминантных функций по выборке. Для отнесения нового предприятия к одной из групп следует подставить значения его соответствующих показателей в каждую из классифицирующих функций. Предприятие должно быть отнесено к той группе, для которой величина классифицирующей функции окажется наибольшей.
Рассмотрим возможность использования метода дискриминантного анализапри решении задачи по оценке платежеспособности промышленного предприятия.
Имеется некоторое множество промышленных предприятий, каждое из которых характеризуется одинаковым набором финансовых показателей. Множество предприятий экспертным путем разделено на группы (классы) по степени платежеспособности. При этом степень платежеспособности определяется некоторым сочетанием финансовых показателей, значения которых устанавливаются по отношению к их нормативным величинам.
Необходимо определить, к какому классу следует отнести новое, не участвующее в классификации, предприятие с известными значениями аналогичных финансовых показателей.
Процесс построения модели оценки платежеспособности предприятия с использованием метода дискриминантного анализа включает подготовительный и основной этапы. На подготовительном этапе осуществляется подготовка исходных данных, необходимых для проведения сложных математических расчетов по нахождению дискриминантной функции и статистических параметров классификации, в том числе:
· разработка системы показателей, характеризующих платежеспособность предприятия;
· формирование выборки предприятий аналогичного типа, содержащей как обанкротившиеся предприятия, так и избежавшие банкротства;
· разбиение сформированной совокупности предприятий на группы и их описание с помощью выбранной системы финансовых показателей.
Подготовительная работа выполняется экспертами – специалистами в области финансового анализа промышленных предприятий.
Основной этап многомерного анализа связан с большим объемом трудоемких вычислений, и проводится с помощью соответствующего технического и программного обеспечения (пакеты SPSS и Statistica). Расчет дискриминантной функции в данном примере проводился в пакете статистического анализа SPSS. Исходные данные по выборке предприятий содержались в формате книги Microsoft Excel.
При построении дискриминантной функции использовались данные выборки из 50 промышленных предприятий Республики Беларусь. Для оценки их платежеспособности рекомендована следующая система показателей:
1.Коэффициент общей платежеспособности по денежным потокам (К1). Рекомендуемое значение – 1.
2.Коэффициент текущей ликвидности (К2). Нормативное значение коэффициента ‑ 1,70 и выше.
3.Коэффициент обеспеченности собственными оборотными средствами (К3). Норматив – 0,30 и выше.
4.Доля уставного фонда и нераспределенной прибыли в источниках собственных средств (К4). Рекомендуемое значение больше либо равно 10 %.
5.Рентабельность реализации, исчисленная как отношение прибыли от реализации к выручке-нетто (К5). Рекомендуемое значение – 12% и выше.
6.Средняя длительность погашения кредиторской задолженности (К6), в днях. Рекомендуемый диапазон значений – не более 35 дней.
Коэффициенты К2 и К3 установлены в соответствии с нормативными значениями для отрасли «Промышленность», содержащимися в Инструкции по анализу и контролю за финансовым состоянием и платежеспособностью субъектов предпринимательской деятельности, утвержденной постановлением Министерства финансов Республики Беларусь, Министерства экономики Республики Беларусь, Министерства статистики и анализа Республики Беларусь от 14 мая 2004 г. № 81/128/65.
Для классификации предприятий по степени их платежеспособности введены 4 группы: хорошая, устойчивая, неустойчивая, кризисная. В табл. 2.4 представлены критерии классификации предприятий, в табл.2.5 априорная информация об уровне платежеспособности исследуемых предприятий.
Таблица 2.4. Критерии классификации предприятий по группам исходя из их платежеспособности
| Платежеспособность
| Номер группы
| Условия отнесения предприятия к группе
|
| Хорошая
|
| Значения пяти либо шести показателей (в том числе обязательно К1 и по меньшей мере одного из К2, К3) должны соответствовать нормативным либо рекомендуемым
|
| Устойчивая
|
| Значения четырех либо пяти показателей (в том числе любых двух из показателей К1, К2, К3) должны соответствовать нормативным либо рекомендуемым. Значение К1 должно быть не менее 0,75
|
| Неустойчивая
|
| Значения трех либо четырех показателей (в том числе одного из показателей К1, К2, К3) должны соответствовать нормативным либо рекомендуемым. Значение К1 должно быть от 0,5 до 0,75
|
| Кризисная
|
| Значения двух и менее показателей соответствуют нормативным либо рекомендуемым, или среди показателей, соответствующих нормативным либо рекомендуемым, нет показателей К1, К2, К3, либо значение К1 меньше 0,5
|
Таблица 2.5. Выборка промышленных предприятий для построения дискриминантной функции оценки платежеспособности
| Номер предприятия в выборке
| Платежеспо-собность
| К1
| К2
| К3
| К4
| К5
| К6
|
|
| хорошая
| 0,98
| 1,76
| 0,45
| 19,00
| 19,00
| 24,00
|
|
| хорошая
| 0,90
| 2,15
| 0,46
| 16,00
| 24,50
| 48,00
|
|
| хорошая
| 0,97
| 1,45
| 0,35
| 23,00
| 13,00
| 29,00
|
|
| хорошая
| 0,92
| 1,97
| 0,31
| 16,00
| 14,50
| 30,00
|
|
| хорошая
| 0,95
| 1,55
| 0,37
| 19,00
| 14,80
| 30,00
|
|
| хорошая
| 0,97
| 1,98
| 0,45
| 18,00
| 12,30
| 28,00
|
|
| хорошая
| 0,94
| 1,47
| 0,32
| 19,00
| 14,50
| 35,00
|
|
| хорошая
| 0,92
| 1,75
| 0,37
| 11,00
| 12,80
| 30,00
|
|
| хорошая
| 0,98
| 1,75
| 0,36
| 19,00
| 15,60
| 32,00
|
|
| хорошая
| 0,97
| 1,92
| 0,29
| 17,00
| 14,00
| 31,00
|
|
| хорошая
| 0,99
| 1,63
| 0,39
| 18,00
| 16,00
| 31,00
|
|
| хорошая
| 0,96
| 1,71
| 0,47
| 19,00
| 19,00
| 30,00
|
|
| хорошая
| 0,91
| 2,01
| 0,28
| 25,00
| 19,80
| 35,00
|
|
| хорошая
| 0,92
| 1,85
| 0,32
| 16,00
| 18,70
| 30,00
|
|
| хорошая
| 0,98
| 1,86
| 0,37
| 16,00
| 11,50
| 15,00
|
|
| хорошая
| 0,93
| 1,62
| 0,48
| 19,00
| 12,80
| 29,00
|
|
| хорошая
| 0,97
| 1,75
| 0,41
| 11,00
| 15,30
| 17,00
|
|
| хорошая
| 0,98
| 1,42
| 0,36
| 24,00
| 24,10
| 18,00
|
|
| хорошая
| 0,94
| 1,25
| 0,34
| 16,00
| 20,50
| 14,00
|
|
| хорошая
| 0,91
| 2,05
| 0,37
| 14,00
| 18,90
| 30,00
|
|
| хорошая
| 0,93
| 1,75
| 0,32
| 15,00
| 18,70
| 31,00
|
|
| хорошая
| 0,99
| 1,69
| 0,54
| 16,00
| 12,30
| 29,00
|
|
| хорошая
| 0,97
| 1,11
| 0,38
| 15,00
| 12,30
| 30,00
|
|
| устойчивая
| 0,88
| 1,72
| 0,38
| 18,00
| 12,10
| 33,00
|
|
| устойчивая
| 0,92
| 1,31
| 0,29
| 17,00
| 18,90
| 32,00
|
|
| устойчивая
| 0,90
| 1,57
| 0,37
| 14,00
| 14,50
| 31,00
|
|
| устойчивая
| 0,85
| 1,72
| 0,32
| 17,00
| 11,30
| 30,00
|
|
| устойчивая
| 0,85
| 1,70
| 0,39
| 19,00
| 20,00
| 41,00
|
|
| устойчивая
| 0,89
| 1,69
| 0,31
| 18,00
| 12,00
| 27,00
|
|
| устойчивая
| 0,91
| 1,31
| 0,34
| 12,00
| 13,10
| 31,00
|
|
| устойчивая
| 0,76
| 1,70
| 0,25
| 15,00
| 12,00
| 35,00
|
|
| устойчивая
| 0,90
| 1,40
| 0,34
| 24,00
| 14,10
| 42,00
|
|
| устойчивая
| 0,75
| 1,72
| 0,37
| 16,00
| 13,20
| 45,00
|
|
| устойчивая
| 0,78
| 1,70
| 0,41
| 15,00
| 12,50
| 40,00
|
|
| устойчивая
| 0,75
| 1,68
| 0,31
| 16,00
| 12,50
| 27,00
|
|
| устойчивая
| 0,90
| 1,27
| 0,32
| 18,00
| 12,00
| 43,00
|
|
| неустойчивая
| 0,50
| 1,72
| 0,12
| 16,00
| 12,10
| 40,00
|
|
| неустойчивая
| 0,55
| 1,63
| 0,09
| 18,00
| 13,10
| 32,00
|
|
| неустойчивая
| 0,55
| 1,87
| 0,12
| 11,00
| 14,10
| 37,00
|
|
| неустойчивая
| 0,51
| 1,54
| 0,16
| 17,00
| 12,30
| 45,00
|
|
| неустойчивая
| 0,55
| 1,83
| 0,17
| 19,00
| 15,30
| 43,00
|
|
| кризисная
| 0,43
| 1,45
| -0,16
| 18,00
| 14,50
| 49,00
|
|
| кризисная
| 0,44
| 1,19
| 0,09
| 16,00
| 12,30
| 45,00
|
|
| кризисная
| 0,43
| 1,05
| -0,17
| 19,00
| 14,20
| 41,00
|
|
| кризисная
| 0,47
| 1,51
| 0,19
| 17,00
| 15,30
| 49,00
|
|
| кризисная
| 0,49
| 1,62
| -0,16
| 19,00
| 17,80
| 50,00
|
|
| кризисная
| 0,48
| 1,43
| 0,07
| 20,00
| 15,30
| 47,00
|
|
| кризисная
| 0,46
| 1,44
| 0,18
| 19,00
| 18,10
| 44,00
|
|
| кризисная
| 0,50
| 1,62
| 0,12
| 10,00
| 18,30
| 40,00
|
|
| кризисная
| 0,51
| 1,71
| 0,15
| 13,00
| 12,40
| 45,00
|
Примечание: жирным шрифтом отмечены значения показателей, соответствующие нормативным либо рекомендуемым
В соответствии с методом дискриминантного анализа платежеспособность выступает как группирующая переменная, а коэффициенты К1…К6 являются независимыми переменными.
Дискриминантный анализ выполнен методом одновременного учета всех независимых переменных (‘Enter Independents Together’ Method).
Формирования базы данных в формате SPSS осуществляется одним из способов:
1. Импорт базы данных из других программных источников (Microsoft Access, Microsoft Excel, текстовых файлов и других).
2. Ввод данных непосредственно в SPSS при помощи специализированного программного обеспечения (SPSS Data Entry).
3. Ручной ввод данных в SPSS.
Наиболее распространенным является импорт данных из других источников. Что бы осуществить импорт данных в SPSS, необходимо сформировать в соответствующей программе (из которой будет осуществляться импорт) таблицу данных, отформатированную определенным способом.
Наиболее эффективным средством создания базы данных для работы в SPSS является Microsoft Excel. Файл данных SPSS напоминает рабочую книгу Microsoft Excel (электронную таблицу), что представлено на рис. 2.8. Однако SPSS не обладает функциональностью электронной таблицы.
 Таблица данных в программе Microsoft Excel, из которой осуществляется импорт, соответствует схеме «заголовок переменной значения переменной».
Таблица данных в программе Microsoft Excel, из которой осуществляется импорт, соответствует схеме «заголовок переменной значения переменной».
Импорт данных осуществляется через диалоговое окно импорта данных Database Wizard при помощи меню File / Open Database / New Query (рис. 2.9.). В окне Database Wizard указывается источник данных, из которого производится импорт данных. Например, Файлы Excel. Пользователь может добавить новый источник, отсутствующий в перечне с помощью кнопки Add Data Source. SPSS поддерживает импорт из любых источников данных, совместимых с технологией ODBC через стандартное окно Microsoft Windows «Администратор источников данных ODBC».
Рис. 2.8. Общая схема построения файла данных SPSS
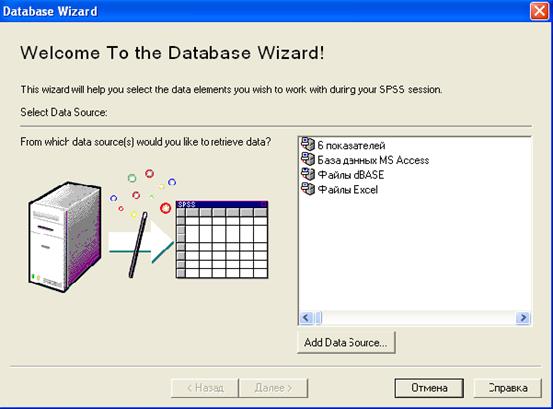
Рис. 2.9. Диалоговое окно Database Wizard
После выбора источника данных в диалоговом окне ODBC Driver Login указывается полный путь к базе данных, из которой производится импорт таблицы. Завершающим шагом является выбор таблицы, содержащей импортируемые данные, путем перемещения ее в правый список в диалоговом окне Database Wizard – Step 2 of 6 (рис. 2.10). Нажатие кнопки Готово завершает ввод данных и в окне SPSS Data Editor появляется импортированная таблица.
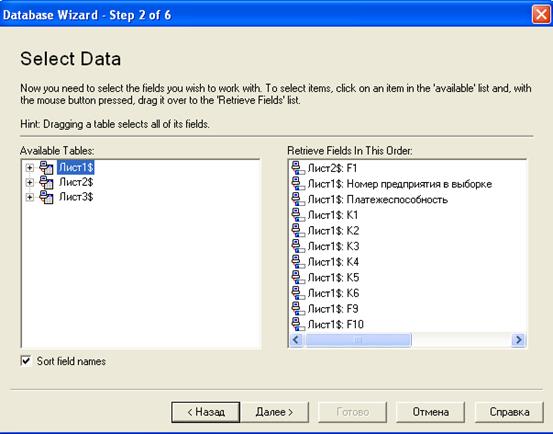
Рис. 2.10. Диалоговое окно Database Wizard – Step 2 of 6
Ввод данных непосредственно в SPSS при помощи специализированного программного обеспечения SPSS Data Entry не получил должного распространения на практике.
Ручной ввод данных наиболее эффективен при малых размерах выборки.
Формирование базы данных для анализа предполагает кодирование переменных. Кодирование переменных осуществляется в таблице на вкладке Variable View основного окна программы Data Editor (рис. 2.11).
Таблица Variable View содержит поля для ввода имени и типа переменных, указания количества разрядов (для числовых переменных) или букв (для текстовых переменных), кодирования одновариантных и многовариантных переменных и др. Особо важным является определение типа шкалы переменных: номинальная (Nominal), порядковая (Ordinal) или интервальная (Scale). Номинальные переменные принимают дискретные, не связанные друг с другом значения. Порядковые переменные кодируют связанные между собой группы значений. Интервальными являются переменные, не имеющие выделенных категорий. Они содержат числовые данные и являются основным ресурсом для SPSS.
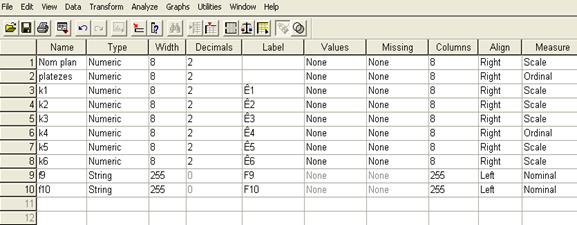
Рис 2.11. Окно SPSS Data Editor, вкладка Variable View
Реализации процедур дискриминантного анализа осуществляется через меню Analyze/Classify/Discriminant в диалоговом окне Discriminant Analysis (рис. 2.12). В данном окне необходимо задать зависимые и анализируемые независимые переменные. Зависимая переменная (классифицирующий признак) помещается в область Grouping Variable и нажатием кнопки Define Range открывается окно для определения границ ее изменения. Указываются минимальные и максимальные значения. Например, число групп от 1 до 4. Анализируемые независимые переменные помещают в область Independents. Далее выбирается метод ввода независимых переменных пошаговый (Use stepwise method) или одновременный (Enter independents together).
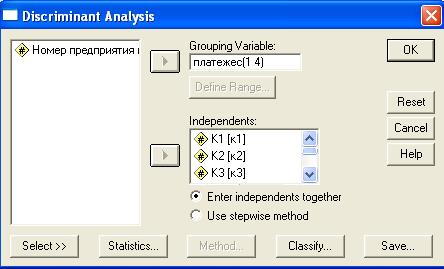
Рис. 2.12. Диалоговое окно Discriminant Analysis
При помощи диалогового окна Statistics, активизируемого одноименной кнопкой, задается вывод результатов одномерного дисперсионного анализа (параметры Means и Univariate ANOVAs) и функциональных коэффициентов регрессии (параметры Fisher^s и Unstandardized) (рис. 2.13).
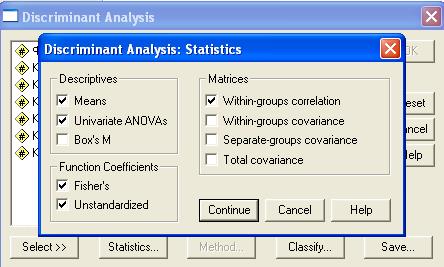
Рис. 2.13. Диалоговое окно Statistics
В следующем диалоговом окне Classification задаются порядок проведения классификации и вывод полученных результатов с помощью четырех блоков (рис.2.14). В блоке Prior Probabilities (Априорные вероятности) задается параметр Compute from group sizes (Вычислять от размера групп). Использование матрицы ковариантов определяется одним из двух параметров Within – groups (В пределах групп) или Separate – groups (Отдельные группы). Оптимальным является использование первого параметра.
В блоке Display (Отображение) основным параметром является Summary table (Итоговая таблица). Для полноты представления и характеристики результатов анализа могут быть заданы и другие параметры, например Casewise results (Случайные результаты).
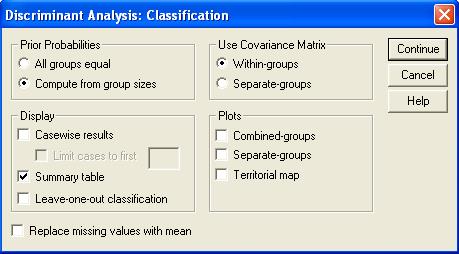
Рис. 2.14. Диалоговое окно Classification
В завершении при помощи кнопки Save сохраняются новые переменные в файле данных.
Для запуска программы проведения дискриминантного анализа после задания необходимых параметров следует щелкнуть кнопкой OK в диалоговом окне Discriminant Analysis. В окне SPSS Viewer будут представлены результаты расчетов (рис. 2.15)
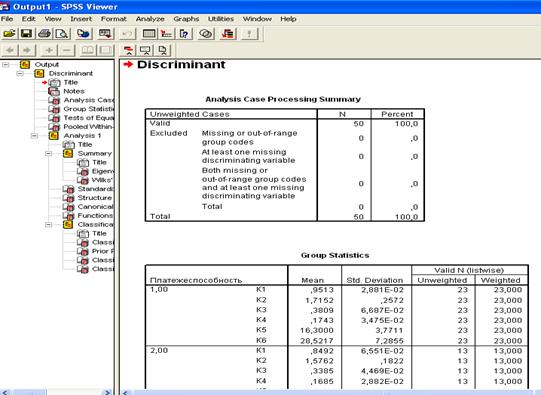
Рис. 2.15. Результаты проведенного дискриминантного анализа
Первой характеристикой выходной информации является сводка результатов обработки наблюдений (табл. 2.6)
Таблица 2.6. Сводка результатов обработки наблюдений
| Невзвешенные наблюдения
|
| N
| Процент
|
| Валидные
|
| 100,0
|
| Исключенные
| Пропущенные или лежащие вне диапазона коды группирующей переменной
|
| ,0
|
| По крайней мере одна пропущенная дискриминантная переменная
|
| ,0
|
| Оба групповых кода пропущены или лежат вне диапазона, и отсутствует по крайней мере одна дискриминантная переменная.
|
| ,0
|
| Итого искл.
|
| ,0
|
| Всего наблюдений.
|
| 100,0
|
Из табл. 2.6 видно, что все 50 наблюдений являются валидными (т.е. достоверными). После вводного обзора действительных и пропущенных значений приводятся средние значения, стандартные отклонения, количество наблюдений для каждой группы в отдельности и суммарные показатели для всех групп.
Результаты расчетов статистических характеристик (средние значения, стандартные отклонения, количество наблюдений для каждой группы в отдельности и суммарные показатели для всех групп) (табл. 2.7) показывают, что наибольшей группой по количеству участников является группа, к которой относятся предприятия с хорошей платежеспособностью (23 из 50, или 60% от общего объема выборки).
Таблица 2.7. Групповые статистики
| Групповые статистики
| |
| Платежеспособность
|
| Среднее
| Стд.отклонение
| Кол-во валидных (искл.целиком)
| |
| Невзвешенные
| Взвешенные
| |
| Хорошая
| К1
| ,9513
| ,02881
|
| 23,000
| |
| К2
| 1,7152
| ,25722
|
| 23,000
| |
| К3
| ,3809
| ,06687
|
| 23,000
| |
| К4
| ,1743
| ,03475
|
| 23,000
| |
| К5
| 16,3000
| 3,77106
|
| 23,000
| |
| К6
| 28,5217
| 7,28554
|
| 23,000
| |
| Устойчивая
| К1
| ,8492
| ,06551
|
| 13,000
| |
| К2
| 1,5762
| ,18219
|
| 13,000
| |
| К3
| ,3385
| ,04469
|
| 13,000
| |
| К4
| ,1685
| ,02882
|
| 13,000
| |
| К5
| 13,7077
| 2,70815
|
| 13,000
| |
| К6
| 35,1538
| 6,26958
|
| 13,000
| |
| Неустойчивая
| К1
| ,5320
| ,02490
|
| 5,000
| |
| К2
| 1,7180
| ,13700
|
| 5,000
| |
| К3
| ,1320
| ,03271
|
| 5,000
| |
| К4
| ,1620
| ,03114
|
| 5,000
| |
| К5
| 13,3800
| 1,33116
|
| 5,000
| |
| К6
| 39,4000
| 5,12835
|
| 5,000
| |
| Кризисная
| К1
| ,4678
| ,02991
|
| 9,000
| |
| К2
| 1,4467
| ,21125
|
| 9,000
| |
| К3
| ,0344
| ,15322
|
| 9,000
| |
| К4
| ,1678
| ,03308
|
| 9,000
| |
| К5
| 15,3556
| 2,30006
|
| 9,000
| |
| К6
| 45,5556
| 3,53946
|
| 9,000
| |
|
Итого
| К1
| ,7958
| ,20148
|
| 50,000
| |
| К2
| 1,6310
| ,24040
|
| 50,000
| |
| К3
| ,2826
| ,15938
|
| 50,000
| |
| К4
| ,1704
| ,03194
|
| 50,000
| |
| К5
| 15,1640
| 3,26945
|
| 50,000
| |
| К6
| 34,4000
| 8,91227
|
| 50,000
| |
Для определения степени различия между переменными во всех 4 группах был выбран критерий Лямбда Уилкса (Willks’ Lambda) и простой дисперсионный анализ. Результаты расчетов представлены в табл.2.8.
Таблица 2.8. Критерий равенства групповых средних
| Независимая переменная
| Лямбда Уилкса
| F
| Число степеней свободы 1
| Число степеней свободы 2
| Значимость
|
| Коэффициент общей платежеспособности по денежным потокам (К1)
| ,040
| 368,830
|
|
| ,000
|
| Коэффициент текущей ликвидности (К2)
| ,807
| 3,662
|
|
| ,019
|
| Коэффициент обеспеченности собственными оборотными средствами (К3)
| ,253
| 45,363
|
|
| ,000
|
| Доля уставного фонда и нераспределенной прибыли в источниках собственных средств (К4)
| ,984
| ,256
|
|
| ,856
|
| Рентабельность реализации (К5)
| ,860
| 2,503
|
|
| ,071
|
| Средняя длительность погашения кредиторской задолженности (К6)
| ,474
| 17,015
|
|
| ,000
|
Как видно из табл.2.8 для всех переменных, кроме рентабельности реализации и доли уставного фонда и нераспределенной прибыли в источниках собственных средств, получается значимое различие между группами.
В корреляционной матрице (табл. 2.9) приводятся коэффициенты, усредненные для всех четырех групп.
Таблица 2.9. Объединенные внутригрупповые матрицы
| | Независимая переменная
| К1
| К2
| К3
| К4
| К5
| К6
|
| Корреляция
| К1
| 1,000
| -,259
| ,182
| ,075
| ,001
| -,270
|
| К2
| -,259
| 1,000
| ,142
| -,193
| ,121
| ,247
|
| К3
| ,182
| ,142
| 1,000
| -,185
| -,016
| ,061
|
| К4
| ,075
| -,193
| -,185
| 1,000
| ,197
| ,202
|
| К5
| ,001
| ,121
| -,016
| ,197
| 1,000
| ,127
|
| К6
| -,270
| ,247
| ,061
| ,202
| ,127
| 1,000
|
Из данных табл. 2.9 можно сделать вывод о низкой степени корреляции (между отдельными переменными значения корреляционных коэффициентов менее 0,3). В связи с этим их подбор для построения дискриминантной функции можно охарактеризовать как удачный.
На следующем шаге выполняется расчет и анализ коэффициентов дискриминантных функций.
Согласно методике дискриминантного анализа количество дискриминантных функций равно числу классификационных групп минус 1.Мерой удачности классификации предприятий по уровню стабильности их платежеспособности служит корреляционный коэффициент между рассчитанным значением дискриминантной функции и показателем принадлежности к классификационной группе.
На удачно подобранную дискриминантную функцию указывает большое собственное значение (как в данном случае). Собственное значение дискриминантной функции соответствует отношению суммы квадратов между группами к сумме квадратов внутри групп (табл. 2.10).
Таблица 2.10. Собственные значения канонических дискриминантных функций
| Собственное значение
| % объясненной дисперсии
| Кумулятивный %
| Каноническая корреляция
|
| 27,101(а)
| 98,3
| 98,3
| ,982
|
| ,305(a)
| 1,1
| 99,4
| ,484
|
| ,176(a)
| ,6
| 100,0
| ,387
|
Из табл. 2.10 видно, что для первой дискриминантной функции коэффициент канонической корреляции равен 0,982. Этот факт позволяет выбрать ее в качестве классификационной функции для определения платежеспособности предприятий, не попавших в выборку. В нашем примере из 3-х дискриминантных функций будет выбрана первая, поскольку она может корректно классифицировать существенный процент первичной информации ‑ более 90%.
Рассмотрим канонические значения коэффициентов дискриминантных функций (табл.2.11).
Таблица 2.11. Коэффициенты канонической дискриминантной функции
| | Функция
|
|
|
|
|
| К1
| 24,038
| -5,074
| 4,708
|
| К2
| 1,438
| 3,454
| -1,689
|
| К3
| 1,293
| -1,029
| -5,833
|
| К4
| ,973
| 8,905
| -5,545
|
| К5
| -,004
| ,085
| ,267
|
| К6
| -,003
| -,131
| ,020
|
| (Константа)
| -21,862
| ,388
| -3,117
|
Выберем коэффициенты первой дискриминантной функции. В итоге получим выражение искомой дискриминантной функции:
D= – 21,862 + 24,038*K1 + 1,438*K2 + 1,293*K3 + 0,973*K4 – 0,004*K5 +0,003*K6,
где D – числовое значение, позволяющее распределить предприятия по группам в зависимости от значений их финансовых показателей K1…K6 в соответствии с центроидами (срединными значениями) групп.
Какие из переменных вносят наибольший вклад в итоговое значение дискриминантной функции показывает структурная матрица в табл. 2.12.
Таблица 2.12. Структурная матрица
| | Функция
|
|
|
|
|
| К1
| ,942(*)
| -,180
| ,159
|
| К2
| ,065
| ,584(*)
| -,329
|
| К5
| -,195
| -,495(*)
| ,018
|
| К6
| ,032
| ,314
| ,777(*)
|
| К4
| ,328
| -,123
| -,473(*)
|
| К3
| ,020
| ,027
| ,185(*)
|
| Объединенные внутригрупповые корреляции между дискриминантными переменными и нормированными каноническими дискриминантными функциями. Переменные упорядочены по абсолютной величине корреляций внутри функции.
|
| * Максимальная по абсолютной величине корреляция между переменными и дискриминантными функциями.
|
Из таблицы 2.12 видно, что К1 (коэффициент общей платежеспособности по денежным потокам) имеет сильно влияние (коэффициент корреляции >0,9) на значение первой дискриминантной функции. Слабо коррелируют с дискриминантной функцией показатели К3 (коэффициент обеспеченности собственными оборотными средствами) и К6 (средняя длительность погашения кредиторской задолженности) – с обратным знаком. Влияние остальных переменных на значение дискриминантной функции очень слабое.
Таблица 2.13 и







