

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Топ:
Методика измерений сопротивления растеканию тока анодного заземления: Анодный заземлитель (анод) – проводник, погруженный в электролитическую среду (грунт, раствор электролита) и подключенный к положительному...
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Интересное:
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Национальное богатство страны и его составляющие: для оценки элементов национального богатства используются...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Перечисленные исследования предлагают интригующие проблески знания о том, как речь может дополнить музыкальный вокабуляр. Но они относятся только к «поверхностным» функциям музыки и не подразумевают, что музыка разделяет формальные «глубинные» структурные атрибуты языка: оба звуковых феномена связываются похожим образом. И в этот момент возникает вопрос о синтаксисе.
В языке синтаксис относится к правилам объединения слов во фразы и предложения, в то время как семантика относится к значению, которое получают эти конструкции. Предложения могут быть синтаксически правильными, но семантически неверными («Я видел зеленый запах») и наоборот («Она купил шесть помидоров»). Синтаксические правила языка не подразумевают, что существует единственный способ сделать конкретное высказывание, – или, можно сказать, тот факт, что язык обладает синтаксисом, не мешает вам говорить одно и то же по‑разному. Именно поэтому язык так удивителен: синтаксические правила служат руководством как для говорящего, так и для слушателя, сохраняя при этом огромное разнообразие высказываний (возможно, вы задумаетесь о музыкальных аналогиях во время этой дискуссии).
Неизвестно, как мы обретаем понимание языкового синтаксиса. Одна из возможностей заключается в том, что мы просто заучиваем его путем дедукции в ранний период развития речи. Американский лингвист Ноам Хомский, однако, утверждал, что это маловероятно: правила слишком абстрактны и тонки, в детстве мы не в достаточной степени знакомимся с их разнообразным использованием, чтобы обрести возможность делать верные обобщения. Его последователи предполагают, что в наш мозг действительно встроена «универсальная грамматика».
|
|
Один из наиболее знакомых грамматических порядков предполагает, что предложение может состоять из подлежащего и дополнения, связанных сказуемым: «Я [подлежащее] видел [сказуемое] дерево [дополнение]». А традиционное правило гласит, что три элемента должны быть расположены в этом порядке. Другие языки могут использовать иной порядок: в германских языках, например, глагол может идти последним, а в некоторых языках порядок слов может быть более гибким, поскольку другие индикаторы (такие как окончания слов, как в латинице) определяют синтаксис.[90]
Иногда изменение порядка слов делает предложение странным и трудным для анализа, но его все равно возможно расшифровать: «Я дерево видел» имеет более или менее четкое значение. Но «Мария видела Джона» явно не то же самое, что «Джон видел Марию»: здесь синтаксис предлагает различие между субъектом и объектом, которое определяется транспозицией. В музыкальной фразе также важен порядок нот: он обуславливает нашу интерпретацию фразы. Скажем, в тональности до переход от до к си создает ожидание того, что сейчас будут разворачиваться дальнейшие события, тогда как противоположная последовательность предполагает завершение.
Языковой синтаксис отражает разветвленную иерархическую грамматику. Рассмотрим предложение:
Водитель, которого остановил полицейский, получил предупреждение.
В основе предложения лежит тот же порядок слов [подлежащее][сказуемое][дополнение], что и в примере выше: подлежащее [Водитель, которого остановил полицейский], сказуемое [получил] и дополнение [предупреждение]. Только в этот раз подлежащее выглядит много сложнее: оно сопровождается определением, выраженным придаточным предложением полицейский остановил водителя. Мы видим дополнительное неглагольное ответвление «остановил полицейский» (Рис. 12.4). Сложность можно развить еще сильнее:
«Водитель, которого остановил стоящий за углом полицейский, получил предупреждение»
|
|
и так далее. Вы можете заметить, что соблюдение синтаксиса не может гарантировать итоговое правильное понимание, тем не менее мы в состоянии расшифровать данное предложение, потому что нам известны законы синтаксиса. Они помогают не только составлять простые предложения, но и собирать сложные, не являющиеся простой последовательностью простых. Мы можем сказать:
«Полицейский стоял за углом. Он остановил водителя. Водитель получил предупреждение»,
но в большинстве языков присутствует синтаксис, который позволяет компоновать более плотную иерархическую структуру, избегая появления двусмысленности.
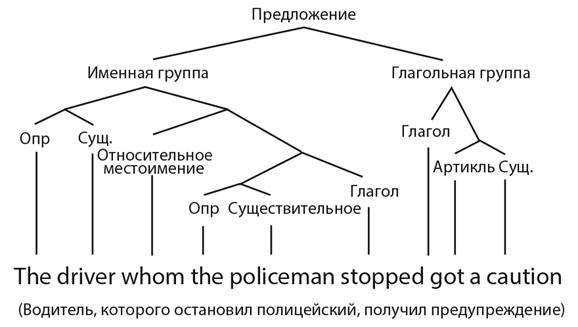
Рис. 12.4 Иерархическая многоплановая структура языковой грамматики (здесь упрощена). «Опр» означает определитель.
Справедливо ли подобное для музыки? По‑видимому, да. С одной стороны, как язык создает связанные предложения, в которых определенные элементы могут быть законно изменены, – скажем, один глагол или существительное заменяет другой, – так можно взаимозаменять разные ноты или аккорды на определенных позициях в музыке. Мы могли бы сказать:
Я видел тебя.
Я рассматривал тебя.
Я изучал тебя;
и мы можем исполнить каденциальные структуры из Рисунка 12.5 с разными аккордами на второй позиции. В результате каждый из вариантов будет обладать универсальной узнаваемой формой, но при этом иметь разное значение.
Не только «значение» базовых музыкально‑синтаксических структур, таких как каденции, определяется порядком нот и аккордов; также и музыкальные произведения являются не просто сериями простых формул, нанизанных друг за другом. Мы запросто можем различать придаточные предложения и обороты в музыке; давайте разберемся, каким образом.

Рис. 12.5 Эти вариации простых прогрессий от тоники к тонике можно рассматривать как подобие грамматических структур с измененными глаголами и существительными.
Генрих Шенкер был первым, кто заговорил о музыкальной синтаксической структуре. Он считал, что каждую музыкальную последовательность можно последовательно упрощать, если предположить, что некоторые ноты только украшают другие, и, отбросив их, мы постепенно можем прийти к глубинной структуре музыкальной фразы всего из нескольких нот гармонической прогрессии. С такой позиции можно говорить о тональной иерархии в тональных мелодиях. Обычно основные ноты являются более стабильными (например, тоника и квинта), они несут на себе главную нагрузку и закрепляют мелодию в ключевых точках. Хроматические ноты, лежащие за пределами гаммы, являются проходящими нотами, и большинство мелодий все равно остается узнаваемым, если эти ноты убрать (Рис. 12.6). Таким же образом все остальные короткие ноты, на которые не приходятся сильные доли, тоже можно удалить без значительных потерь; мы можем последовательно обнажить мелодию до самого остова – скелетной формы. В какой‑то момент облик мелодии может пропасть из вида, потому что мы отсечем элементы, которые отличают ее от других, похожих на нее напевов, но даже на этом этапе мы будем в состоянии различить основной контур оригинальной мелодии, зная, какой она была изначально.
|
|

Рис. 12.6 Сокращение Шенкера для Вариации 3 И. С. Баха «Aria variata» (BWV989). Оригинал показан в примере (а); пример (б) – так называемое «ритмическое сокращение», где редукции подверглись «поверхностные» шестнадцатые, а в примере (в) мы видим мелодический и гармонический скелет. В примере (в) ноты со штилями являются ключевыми для темы, а лиги указывают на их взаимозависимость.
Шенкер сформулировал конкретные (хотя на самом деле не очень строгие) правила для «сокращения» музыки путем постепенного устранения нот, которые считаются украшающими и декоративными. В итоге он оставляет только скелетный урзац, который, по его мнению, состоит из простых нисходящих линий нот звукоряда: 3–2–1, например, или 5–4–3–2–1, завершающихся автентической каденцией. Шенкера в действительности не волновало, могут ли слушатели воспринимать эти базовые конструкции; он стремился отыскать способ для изучения музыкальной формы, чтобы определить подобия и различия в композициях или частях одной композиции. По словам Шенкера, успех или неудача композиции зависели от того, насколько хорошо композитор понял динамику базового урзаца (его теория, развитая в начале двадцатого века, несла невысказанную повестку дня и «доказательство» того, что композиции (преимущественно немецких) тональных мастеров эпохи барокко и классицизма структурно превосходили и были более связными, чем у модернистов, таких как Стравинский и Шёнберг).[91]
|
|
Основная проблема этого подхода заключается в том, что он недостаточно определен, – правила разделения пьесы несколько произвольны, и поэтому не существует уникального способа регрессии от музыкальной «поверхности» – полной партитуры – до «глубинной структуры», хуже того, не существует способа двигаться в обратном направлении. И даже если глубинная структура является, вероятно, скелетом композиции, то она представляет столь же интересна с точки зрения музыки, как картина Тициана на этапе «палка, палка, огуречик» с точки зрения визуального искусства. Автор метода не выводит никаких правил для облечения этих костей в плоть – несмотря на то что Шенкер полагал свои методы отражением подсознательных процессов, с помощью которых композитор связывает поверхность с глубинной структурой, кажется более вероятным, что именно первое обеспечивает основной музыкальный импульс. Нет сомнений в том, что классические тональные композиторы чувствовали глубинную гармоническую траекторию, по которой двигались их мелодии, но нельзя считать шенкеровский анализ «ответом» на вопрос, почему симфонии «Героическая» или «Юпитер» звучат именно так, а не иначе: это не теория, которая объяснит наблюдение с позиции фундаментальных постулатов. Кроме того, шенкеровский подход в полной мере применим только к композициям, отвечающим традиционным гармоническим правилам восемнадцатого и девятнадцатого веков, и не подходит для анализа классической музыки до Баха или после Брамса, а также для популярных музыкальных форм, таких как рок (сам Шенкер говорит о своем подходе как о способе размышления о музыке, а не как полноценной теории).

Рис. 12.7 Синтаксическая структура первой строчки «Norwegian Wood» (а). Основные ноты нисходящего трезвучия (б), которое после украшения составляют диатоническую (ладовую) гамму (в).
Тем не менее, в шенкеровском понятии иерархического развертывания музыкальной структуры, безусловно, есть некоторая обоснованность, и именно поэтому шенкеровский анализ информирует большинство систем, используемых сегодня для раскрытия «грамматики» музыки: все они имеют тенденцию предполагать, что музыкальные фразы можно свести к минимуму согласно различному статусу составляющих их нот; этот процесс называется «редукция тонов» и его можно сравнить с пикселизацией изображения при последовательном ухудшении качества, когда каждый пиксель несет в себе только основную информацию о цвете и яркости данного участка картинки.[92]
|
|
Рассмотрим в качестве примере первую строчку песни» Битлз» «Norwegian Wood», иерархическую структуру которой проанализировали теоретики музыки Фред Лердал и Рэй Джекендоф (Рис. 12.7а). Самые важные ноты, по их мнению, сопровождают слова «I», «girl», «say» и «me» (Рис. 12.7б). Эта субструктура довольно очевидна, потому что ключевые ноты выпадают на сильные доли, а еще они самые долгие. Более того, они сравнительно тонально‑стабильные и представляют собой ноты тонического трезвучия в тональности ми мажор: си, соль‑диез, ми, си. Если вы пропоете только эти четыре ноты, то сразу ощутите законченную, полную фразу. Якорные ноты составляют аккорд ми мажор, только в обратном порядке, как арпеджио, таким образом, общий контур фразы является нисходящим. Если мы добавим еще несколько нот мелодии, то сможем создать нисходящую гамму (Рис. 12.7) (обратите внимание, что это не мажорная гамма, а ладовая, потому что ре на слове «she» натуральная, а не диез; это придает песне некоторый фолк‑оттенок).
Как и шенкеровский анализ, «генеративная теория тональной музыки» (GTTM), разработанная Джекендофом и Лердалом, предлагает формальную процедуру для выполнения редукции тонов, так что скелет любой музыкальной пьесы может постепенно проступить, даже если сперва невозможно было понять, как дробятся музыкальные фразы. В результате возникает древовидная структура, где главные ветви оканчиваются на самых важных нотах, а короткие боковые ветки венчают украшения. Рис. 12.8 показывает, как этот метод работает на фразе из песни «Norwegian Wood».[93]
Обратите внимание, что две самые основополагающие ноты здесь первая и последняя: верхняя и нижняя си. Поэтому мы можем рассматривать всю фразу как шаг на октаву вниз, украшенный сопутствующими нотами. К тому же «значимость» нот в этом анализе не равняется их воспринимаемой важности: например, ля на слова «once» в дереве GTTM похожа на случайную ноту, но она всплывает в самой мелодии, потому что только в этом месте мелодия фразы совершает большой скачок, даже два, от ре к ля и затем вниз к до‑диез. Я хочу сказать, что именно ля мы обязаны тем напряжением, которое чувствуем от музыки: скачок происходит неожиданно и заставляет нас гадать, куда дальше отправится мелодия. Но это отражено в форме дерева, потому что правила GTTM подразумевают, что наклон ветви воспроизводит степень напряжения или расслабления, связанные с соответствующей нотой (по крайней мере, в отношении высоты тона): чем выраженнее наклон, тем сильнее напряжение. По этой мерке ля на «once» вызывает большое напряжение по сравнению с другими нотами фразы.[94]

Рис. 12.8 Иерархическая древовидная структура тонов песни «Norwegian Wood» по генеративной теории тональной музыки Лердала и Джекендофа.

Рис. 12.9 Ритмическая иерархия фразы из «Norwegian Wood» Обратите внимание на ее отличие от тоновой иерархии.
Но это еще не все, что касается иерархической структуры музыки. Ритм также вовлечен в структуру: важные ноты обычно стоят на сильных долях. Дерево иерархии тонов связывает следующие друг за другом ноты в небольшие группы по три или около того [I once had] [a girl or] [should I say] [she once] [had me] («у меня когда‑то была девушка или, скорее, у нее был я»). Но когда вы произносите эту раскладку вслух (даже лучше, если пропеваете), то замечаете, что она не так легко вписывается в ритмический поток строки. В действительности он разбивается так: [I] [once had a girl] [or should I say] [she once had me]. GTTM имеет возможность определять группы, которые вновь разделяются на несколько уровней иерархии (Рис. 12.9).
Богатство музыкального содержания этой песни проистекает из того, что шаблоны – группирование по высоте тона и ритму и напряжение, создаваемое тональной стабильностью высоты тона, – перекрываются, взаимодействуют и пересекаются. Мейеровская модель эмоций в музыке предлагает еще один не вполне независимый набор существенных факторов, основанных на ожиданиях и их нарушениях: скажем, хроматизм или изменения ритма.
И это только одна строчка из песни. Иерархии продолжаются в более крупных масштабах, например, с точки зрения того, как последовательные линии связаны друг с другом: они повторяются, или слегка изменяются, или переходят к совершенно другим траекториям в контуре или тональности? В конце концов, мы сталкиваемся с крупномасштабными элементами структуры, знакомыми на разговорном уровне: куплетами и припевами, темами и развитием, частями и целыми масштабными архитектурными единицами западной художественной музыки, такими как соната и симфония. Они тоже являются частью иерархической структуры, но, как правило, не имеют фундаментального когнитивного значения. Хотя некоторые теоретики музыки говорят о том, как музыкальный опыт может привести к нарушению ожиданий в этих объемных музыкальных формах, когнитивные исследования показывают, что их практически не слышат даже профессиональные музыканты, если прослушивают фрагменты незнакомой музыки. Конечно, мы можем слышать, где начинаются и заканчиваются части, и мы можем (обычно) отличать анданте от скерцо, но наша память о детальной структуре, пожалуй, не выходит за рамки нескольких минут. Таким образом, мы должны с известной долей сомнения принимать все эти программные заметки об умных вещах, которые композиторы делают с формой: данные манипуляции могли дать творческий стимул композитору, но они не имеют ничего общего с тем, как мы воспринимаем музыку, если только мы не изучили композицию заранее.
Музыкальный синтаксис и грамматика не являются произвольными конструкциями, но имеют логику, которая помогает сделать музыку понятной даже для неискушенных слушателей, способных довольно быстро, подсознательно и интуитивно понимать правила организации. Большинство детей осваивает музыкальную грамматику в возрасте около шести или семи лет без какого‑либо специального обучения.
И все же языковые параллели имеют свои пределы. В языке синтаксическая структура имеет тенденцию навязывать только одно правильное чтение; создание действительно двусмысленных, но грамматически правильных предложений требует определенных усилий. Но в музыке часто не существует уникального способа разбора фразы, и мы можем попробовать несколько стратегий, переключаясь между ними в поисках подтверждения или опровержения своих идей. Если бы это происходило в прозе (поэзия может отличаться), мы бы скоро утомились; в музыке же, судя по всему, именно это для нас и ценно. Разбор, основанный на мелодии или гармонии, может поддерживаться или не поддерживаться тем, что основан на ритме. Интересная музыка часто ставит одно против другого, заставляя нас постоянно пересматривать и обновлять собственные интерпретации. Мелодии, которые полностью прозрачны по своей синтаксической структуре, могут некоторое время радовать нас, но в конечном итоге мы понимаем, что слушаем эквивалент детской песенки.[95]
К тому же, мы можем с уверенностью заявить, что некоторые предложения являются грамматически неправильными (даже если правила имеют размытые границы), в то время как в отношении музыки то же самое говорить едва ли уместно, ведь мы можем построить музыку, которая кажется грамматически странной и неожиданной, например, завершить каденцию на «неправильном» аккорде, но мы не можем обозначить такие варианты как недопустимые. Эти очевидные синтаксические ляпы потенциально могут обрести искупление – объяснение, вы могли бы сказать, – с помощью того, что происходит следом за ними.
Из того, что схемы, подобные GTTM, предлагают формальный способ разделения или телескопирования музыки в иерархические структуры, не следует, что именно эту схему использует человеческий ум. Помимо смутного чувства правильности и неправильности, воспринимаем ли мы вообще синтаксические структуры? Этот вопрос остается открытым. Вполне вероятно, что многие слушатели улавливают в «Norwegian Wood» только изменяющийся ритм мелодии и ее нисходящий контур. Конечно, я не представляю, что кто‑то видит, как прорастает дерево Джекендофа и Лердаля по мере развертывания мелодии. Более того, это и нельзя увидеть, поскольку правильное дерево составляется только ретроспективно. В целом данный вопрос можно исследовать с помощью тестов – и посмотреть, будут ли испытуемые узнавать усиление и ослабление напряжения, как предсказывает теория. Как я уже говорил в Главе 10, такое тестирование проводили несколькими способами, но результаты не оказались однозначными, потому что такое явление, как музыкальное напряжение, не так легко поддается измерениям без появления двусмысленности. Фред Лердал предполагает, что люди воспринимают музыку как иерархически, так и последовательно – они могут интуитивно понять повторяющуюся структуру, но при этом они движутся по траектории от одного события к другому в мелодии и гармонии. Он думает, что все дело в опыте: слушатели‑любители остаются плавать «на поверхности» произведения, а более искушенные поклонники музыки способны услышать глубинные структуры. В этом случае, заявляет Лердал, меломаны могут аккумулировать и переносить вперед напряжение, заключенное в рекурсивных отношениях, а неопытные слушатели и их степень напряжения зависят от того, как данная нота связана с теми, которые только что прозвучали, – например, является ли нота разрешением и переходом к более тонально‑стабильной ноте или, наоборот, делает шаг в сторону от нее.
Как можно понять из названия, Лердал и Джекендоф разработали свою древовидную карту только для разбора тональной музыки. Не вполне ясно, может ли существовать подобная структура для анализа атональной музыки, потому что грамматические и иерархические порядки в ней не определены; то есть их вообще может не быть. Не существует атонального эквивалента такой грамматической формы, ка каденция, и нет никакой причины, по которой один аккорд должен следовать за другим или предшествовать ему (за пределами тонового ряда, в сериалистической композиции). Поэтому, когда Лердал и Джекендоф применяют свой подход к атональной музыке, он обнаруживают «хрупкие для восприятия» структуры (то есть сложность определения начала и конца фразы, по крайней мере, при опоре только на высоту тона) и «ограниченную иерархическую глубину»: все лежит на поверхности с незначительным рекурсивным ветвлением. Исследования музыковеда Николя Диббена при участии студентов музыкальных училищ и специалистов подтверждают их выводы: испытуемые не могли точно идентифицировать, какой из двух редуцированных вариантов атональной композиции больше похож на оригинал. Это означает, что иерархическая структура, которая, возможно, в музыке присутствовала, осталась непонятой. Более того, нет смысла говорить об изменении музыкального напряжения, как при наличии прозрачных отношений между музыкальными элементами в тональной музыке, – за исключением, быть может, вариаций сенсорного диссонанса в качестве нового «индикатора напряжения». На основе этого можно заключить, что, хотя сериализм имеет руководящие правила (и, как правило, применяет их негибко), они не относятся к тому типу правил, который допускает возникновение музыкальной грамматики. Синтаксически говоря, эта музыка довольно поверхностная.
С точки зрения когниции это очень важное замечание. Одна из причин, по которой музыка привлекает наше внимание, может заключаться в том, что ее синтаксис и грамматика вводят нас в заблуждение и мы слышим ее как некий псевдоязык. Это не означает, что музыка на самом деле – приятная тарабарщина; скорее, наши механизмы лингвистической обработки могут быть направлены на то, чтобы обнаружить видимую логику в сложной музыке. Наша способность развивать музыкальную грамматику означает, что мы не обречены оставаться на уровне детских песенок (которые, я мог бы добавить, уже имеют простой синтаксис), но музыка без четкой грамматической основы может не справиться с задачей составить нечто большее, чем линейный ряд нот и неглубоких мотивов Может быть, поэтому некоторые из самых сильных произведений Шенберга – это миниатюры?
Общие ресурсы
Если музыка и язык демонстрируют хоть какое‑то структурное сходство, воспринимает ли наш мозг их одинаково? Вопрос довольно спорный. Самые ранние стадии слуховой обработки должны обязательно обрабатывать все раздражители одинаково: «ухо» не может решить, слышит ли оно речь или музыку, и направить сигнал соответственно в разные части мозга. Но это различие очевидно развивается на некоторой стадии, так как мы обычно не путаем их. Таким образом, в принципе возможно, что свойства высокого порядка, такие как синтаксис, могут обрабатываться различными нейронными цепями. И все же, если они ссылаются на аналогичные принципы, почему мозг так расточает свои ресурсы?
Уже многие годы обсуждается неврологическая связь между музыкой и речью, потому что люди могут страдать от повреждения мозга, которое мешает им обрабатывать слова (афазия), но не трогает музыку, и наоборот (состояние, известное как амузия). Наиболее известный случай касается русского композитора Виссариона Шебалина, у которого после пережитого в 1959 году инсульта настолько повредился речевой центр, что он не мог повторить три простых коротких предложения. Тем не менее, он продолжал сочинять музыку, а его пятая симфония 1962 года по словам Шостаковича была «блистательной творческой работой, наполненной высочайшими эмоциями». Кроме того, бывали случаи, иногда просто поразительные, когда люди страдали от серьезных когнитивных расстройств, связанных с речью и пользованием языком, например, от выраженных форм аутизма, но вместе с тем обладали выдающимися музыкальными способностями. Они не просто могли исполнять музыку с точностью звукозаписывающего устройства, но и были способны с большим вкусом импровизировать. Другие теряли способность распознавать мелодию, сохраняя четкое восприятие просодии в речи. Как это возможно, если язык и музыка обрабатываются по одним и тем же ментальным каналам?
Для начала я поясню, что в универсальном смысле они не обрабатываются в одном месте: речь и язык являются специализированной функцией мозга, а обработкой музыки занимается весь мозг. Но, может, хотя бы синтаксические качества обоих явлений проходят через одинаковый анализ? Мы не знаем, могут ли случаи афазии без амузии ответить на этот вопрос, потому что такие расстройства случаются очень редко (все описанные в литературе случаи можно пересчитать по пальцам одной руки), и обычно задокументированные случаи касаются людей с выдающимися музыкальными способностями, таких как Шебалин, а они никак не подходят под репрезентацию среднестатистических представителей популяции.
Современные методы нейронной визуализации позволяют более точно исследовать этот вопрос. Анирудх Патель совместно с коллегами обнаружил, что несовместимые аккорды в гармонической последовательности создают характерные сигналы мозговой активности, похожие на те, что производят нарушения языкового синтаксиса. Эти гармонические огрехи воспринимаются так же, как лишенное смысла предложение: в разуме загорается сигнал «Чего?». Но это не означает, что реакции возникают на основе одних и тех же ментальных процессов, хотя обе реакции связаны с нарушением синтаксиса, – их запускает недостаток семантики в речи и разлад в музыке, причем и то, и другое может быть следствием соответствующих синтаксических нарушений, которые в общем для них не существенны.
К счастью, мозг обладает набором сигналов, которые срабатывают исключительно на «Чего?» в синтаксическом смысле. Измерения электрической активности мозга с помощью электроэнцефалографии, когда электродные датчики закрепляются на черепе, показали, что нарушения синтаксиса в языке выявляют четко определенные модели активности, которые отличаются от нарушений семантики. Патель и его коллеги ориентировались на электрический импульс Р600, который достигает пиковой интенсивности через 600 миллисекунд после звучания синтаксически неподходящего слова. Р600 можно засечь, например, когда испытуемые слышат предложение «Брокер надеялся продать акции отправлен в тюрьму». Не то чтобы предложение было совершенно непонятным, просто сразу появляется ощущение, что что‑то не так: по правилам синтаксиса слово «отправлен» не должно следовать за словом «акции» в данном контексте. Сигнал Р600 достигает пика через 600 миллисекунд после звучания слова «отправлен».[96]
Патель с коллегами создали гармоничные последовательности аккордов в популярном стиле, что‑то вроде маленьких джинглов. В определенном месте последовательности они вставили аккорды, которые казались более или менее неуместными, например, последовательность в до мажор вдруг неожиданно прерывалась аккордом ми‑бемоль мажор, который, пусть и неожиданный, все же умеренно связан с тоникой (и является консонантным сам по себе), или аккордом ре‑бемоль мажор, который стоит дальше от тоники, а поэтому кажется еще более неуместным. В обоих случаях инородные аккорды представляют собой нарушения нормального гармонического синтаксиса – но эти неожиданности, конечно, не идут в сравнение со случаем, когда пианист, например, вдруг бьет кулаком по клавишам. Исследователи определили, что умеренные и сильные нарушения музыкального синтаксиса провоцируют у слушателей появление сигнала Р600, при этом более выраженное гармоническое несоответствие вызывало более яркий сигнал.
Эти результаты были подтверждены исследованиями команды Штефана Кельша – немецкого нейроученого, работавшего в Лейпциге. Исследователи ставили испытуемым записи различных каденциальных аккордовых последовательностей, некоторые из которых были обычными, как автентические каденции, а иные состояли из нетрадиционных аккордов; ученые делали различные пробы «синтаксического стресса» и изучали сигналы мозга, например, так называемый сигнал раннего правого переднего негативного эффекта (ERAN), который появляется спустя 180 миллисекунд после звучания раздражителя, и поздний билатеральный фронтальный негативный эффект (N5), который возникает спустя примерно полсекунды после звучания раздражителя.

Рис. 12.10 Примеры гармонических прогрессий, используемых Стефаном Кельшем и его коллегами для проверки того, как мозг обрабатывает музыкальный синтаксис. Ожидаемая последовательность является нормальной каденциальной структурой, а неожиданная заканчивается необычным (но не полностью несогласованным) аккордом.
Исследователи использовали пять аккордов в гармонической прогрессии, которая начиналась и заканчивалась тоникой и наблюдали за последствиями внедрения неподходящего аккорда (неаполитанского секстаккорда) в третьей или в пятой позиции (Рис. 12.10). Неаполитанский секстаккорд основан на минорном субдоминантовом аккорде – то есть если тоника до, то аккорд основывается на фа минор, но вместо обычной квинты (здесь до) стоит пониженная секста (ре‑бемоль). Звучит странно, но не полностью диссонантно – этот прием можно встретить в музыке от эпохи барокко до романтизма. Как и Патель с товарищами, команда Кельша пришла к выводу, что неаполитанский секстаккорд воспринимается не как ошибка, а как озадачивающее отклонение от нормальной гармонической грамматики.[97]
Исследователи обнаружили, что сигналы ERAN и N5 возникали из‑за неаполитанского секстаккорда как у музыкантов, так и у не музыкантов, знакомых с западной тональной музыкой. Отклик был сильнее, когда неожиданный аккорд появлялся в конце последовательности, чем когда он стоял третьим, поскольку в первом случае ожидания, создаваемые обычной гармонической грамматикой, – то, что последовательность направлялась к тонике, – были более интенсивными. Позже исследования показали, что отклики ERAN и N5 также могут быть вызваны гармоническими нарушениями, намеренно примененными композиторами: ученые использовали отрывки из сонат Бетховена, Гайдна, Моцарта и Шуберта, в которых композиторы поместили несколько необычных аккордов вместо очевидных. Наряду с доказательством того, что полученные данные являются не просто артефактом использования «странной лабораторной музыки», эти исследования напоминают, что, как и в речи, синтаксис в музыке не определяет деятельность художника: он вбирает в себя нормы, которые можно нарушать в большей или в меньшей степени с целью добиться выразительности. Если бы плохой синтаксис был объявлен вне закона, поэзия стала бы действительно скучной. В последующих экспериментах Кельш и его коллеги смогли определить, из каких частей мозга поступают сигналы ERAN: из области в левом полушарии, называемой областью Брока, и соответствующего места в правом полушарии. Аналогичный сигнал поступает из того же источника при обработке синтаксиса языка. Более того, эксперименты, в которых синтаксические нарушения слов и музыки представлены одновременно, показывают, что между нейронными ресурсами, используемыми в обоих случаях, существует значительное совпадение. Это довольно убедительно говорит о том, что мозг использует один и тот же механизм для интерпретации языкового и музыкального синтаксиса. Нет доказательств, что два типа синтаксиса эквивалентны, – возможно, эта часть мозга выполняет несколько более обобщенную функцию интерпретации ожидаемого порядка психических стимулов, – но это вполне возможно.
Анирудх Патель считает, что подобные исследования дают веские основания полагать, что синтаксическая обработка в музыке и в речи делит общие ресурсы в мозге. Но это не означает, что лингвистическая и музыкальная информация просто помещается в одну и ту же ментальную коробку с надписью «Синтаксис», которая должна декодироваться в соответствии с одинаковыми правилами. Скорее, основные элементы синтаксиса – слова и категории слов для языка, ноты и аккорды для музыки – остаются закодированными в разных местах мозга, но нейронные схемы, которые выясняют, как эти «синтаксические репрезентации» объединяются и интегрируются, могут быть общими как для музыки, так и для языка.
Теория музыкальных эмоций Леонарда Мейера, основанная на неоправданных ожиданиях, предполагает, что манипуляции Кельша с гармоническим синтаксисом должны вызывать некоторый эмоциональный отклик, а также сигнал «ошибка». Похоже, что дело обстояло так: Кельш и его коллеги обнаружили, что «неправильная» последовательность аккордов, заканчивающаяся на неаполитанский секстаккорд, стимулирует активность в амигдале, одном из ключевых эмоциональных центров мозга, и слушатели оценивают эту последовательность как менее приятную, чем обычную последовательность, заканчивающуюся на тонике (обратите внимание, что нет ничего «неприятного» в неаполитанском секстаккорде, который сам по себе является консонантным аккордом; именно синтаксический подтекст, странность положения аккорда в последовательности создает негативную реакцию). Более того, нарушения гармонического синтаксиса приводят к увеличению электрической проводимости кожи слушателя, реакции, обычно возникающей из‑за изменений в эмоциональном состоянии. И величина реакции N5 на синтаксические нарушения увеличивалась, если отрывки исполнялись более экспрессивно (в этом случае выразительная динамика вводилась или устранялась посредством искажения цифровых записей). Можно предположить, что регистрация «неожиданности» в некоторой степени зависит от эмоциональных особенностей исполнения. Эти выводы уходят в копилку доводов в пользу плодотворной теории Леонарда Мейера.
Любопытно, что отклик ERAN не показал такой чувствительности к экспресии. Это говорит о том, что у нас может быть как минимум два пути обработки нарушений музыкального синтаксиса, один из которых связан с эмоциями, а другой – чисто когнитивный. Речевые эмоциональные сигналы, по‑видимому, обрабатываются независимо от семантических и синтаксических: некоторые люди с поражением мозга могут «слышать» эмоциональные коннотации речи без должного понимания смысла (на самом деле, это иногда случается и у здоровых людей), и наоборот. Но музыкальные исследования показывают, что в музыке нет простого разделения между логосом синтаксиса и эросом выразительности.
Музыкальный прайминг
Я говорил, что отложу непростой вопрос семантики до следующей главы, но есть аспект, который кажется весьма уместным в теме взаимодействия музыки и речи, так что предлагаю обсудить его прямо здесь. Нейронаука предоставила доказательства того, что музыка может обладать внутренним смысловым содержанием: она может нести определенный смысл.
Если два семантически связанных слова или предложения читаются или слышатся одно за другим, второе легче обрабатывается мозгом, как если бы первая фраза переводила его в «правильный образ мышления». Таким образом, мы понимаем слово «музыка» чуть быстрее, если ему предшествует предложение «Она поет песню», но это предложение не да<
|
|
|

Историки об Елизавете Петровне: Елизавета попала между двумя встречными культурными течениями, воспитывалась среди новых европейских веяний и преданий...

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Биохимия спиртового брожения: Основу технологии получения пива составляет спиртовое брожение, - при котором сахар превращается...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!