Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.
В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами – потому что, без псевдонимов наш запрос бы выглядел следующим образом:
SELECT Employees.ID,Employees.Name,Employees.DepartmentID,Departments.ID,Departments.Name
FROM Employees
JOIN Departments ON Employees.DepartmentID=Departments.ID
По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
SELECT
e1.ID EmpID1,
e1.Name EmpName1,
e2.ID EmpID2,
e2.Name EmpName2
FROM Employees e1
LEFT JOIN Employees e2 ON e1.ID=e2.ID+1 -- получить данные предыдущего сотрудника
Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения
Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable:
CREATE TABLE LeftTable(
LCode int,
LDescr varchar(10)
)
GO
CREATE TABLE RightTable(
RCode int,
RDescr varchar(10)
)
GO
INSERT LeftTable(LCode,LDescr)VALUES
(1,'L-1'),
(2,'L-2'),
(3,'L-3'),
(5,'L-5')
INSERT RightTable(RCode,RDescr)VALUES
(2,'B-2'),
(3,'B-3'),
(4,'B-4')
Посмотрим, что в этих таблицах:
SELECT * FROM LeftTable
| LCode
| LDescr
|
| 1
| L-1
|
| 2
| L-2
|
| 3
| L-3
|
| 5
| L-5
|
SELECT * FROM RightTable
| RCode
| RDescr
|
| 2
| B-2
|
| 3
| B-3
|
| 4
| B-4
|
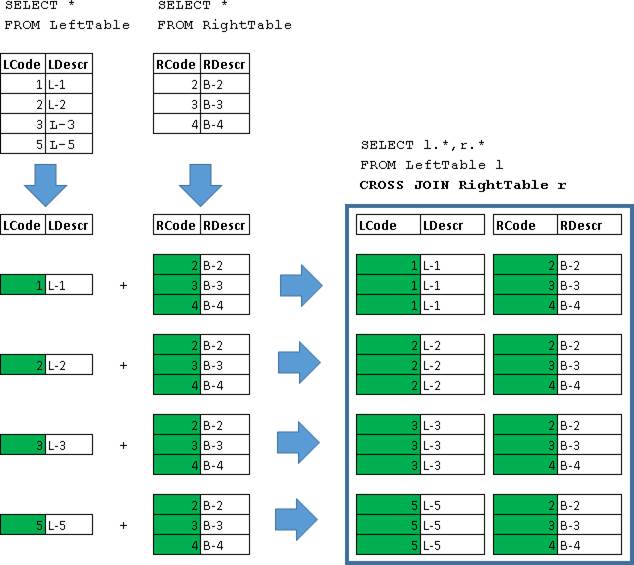
JOIN
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 2
| L-2
| 2
| B-2
|
| 3
| L-3
| 3
| B-3
|
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
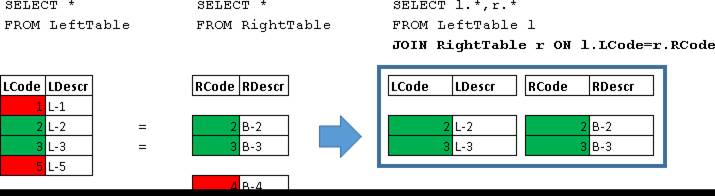
LEFT JOIN
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 1
| L-1
| NULL
| NULL
|
| 2
| L-2
| 2
| B-2
|
| 3
| L-3
| 3
| B-3
|
| 5
| L-5
| NULL
| NULL
|
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)
RIGHT JOIN
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 2
| L-2
| 2
| B-2
|
| 3
| L-3
| 3
| B-3
|
| NULL
| NULL
| 4
| B-4
|
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)

По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
SELECT l.*,r.*
FROM RightTable r
LEFT JOIN LeftTable l ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 2
| L-2
| 2
| B-2
|
| 3
| L-3
| 3
| B-3
|
| NULL
| NULL
| 4
| B-4
|
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
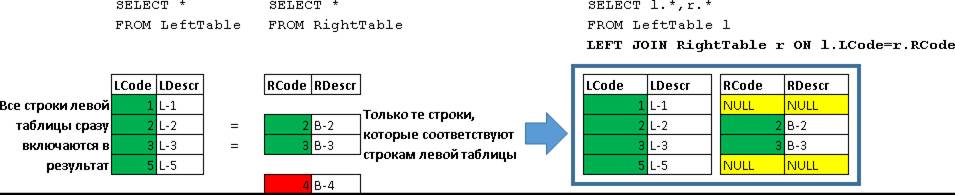
FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 1
| L-1
| NULL
| NULL
|
| 2
| L-2
| 2
| B-2
|
| 3
| L-3
| 3
| B-3
|
| 5
| L-5
| NULL
| NULL
|
| NULL
| NULL
| 4
| B-4
|
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.
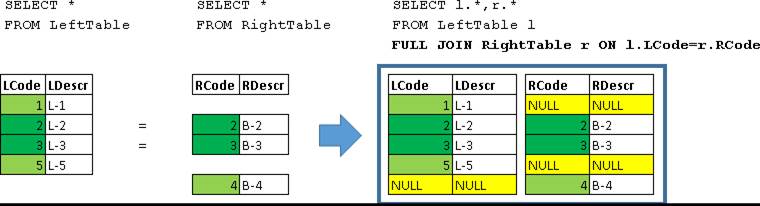
CROSS JOIN
SELECT l.*,r.*
FROM LeftTable l
CROSS JOIN RightTable r
| LCode
| LDescr
| RCode
| RDescr
|
| 1
| L-1
| 2
| B-2
|
| 2
| L-2
| 2
| B-2
|
| 3
| L-3
| 2
| B-2
|
| 5
| L-5
| 2
| B-2
|
| 1
| L-1
| 3
| B-3
|
| 2
| L-2
| 3
| B-3
|
| 3
| L-3
| 3
| B-3
|
| 5
| L-5
| 3
| B-3
|
| 1
| L-1
| 4
| B-4
|
| 2
| L-2
| 4
| B-4
|
| 3
| L-3
| 4
| B-4
|
| 5
| L-5
| 4
| B-4
|
Каждая строка LeftTable соединяется с данными всех строк RightTable.
Возвращаемся к таблицам Employees и Departments
Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения – операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.
Давайте попробуем вместе подвести резюме для каждого запроса:
| Запрос
| Резюме
|
| -- JOIN вернет 5 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
| По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID. Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков).
|
| -- LEFT JOIN вернет 6 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
| Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL. Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,'вне штата'). Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП.
|
| -- RIGHT JOIN вернет 7 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
| Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет. Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел.
|
| -- FULL JOIN вернет 8 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
FULL JOIN Departments dep ON emp.DepartmentID=dep.ID
| Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники). Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел.
|
| -- CROSS JOIN вернет 30 строк - (6 строк таблицы Employees) * (5 строк таблицы Departments)
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
CROSS JOIN Departments dep
| В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже.
|
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID):
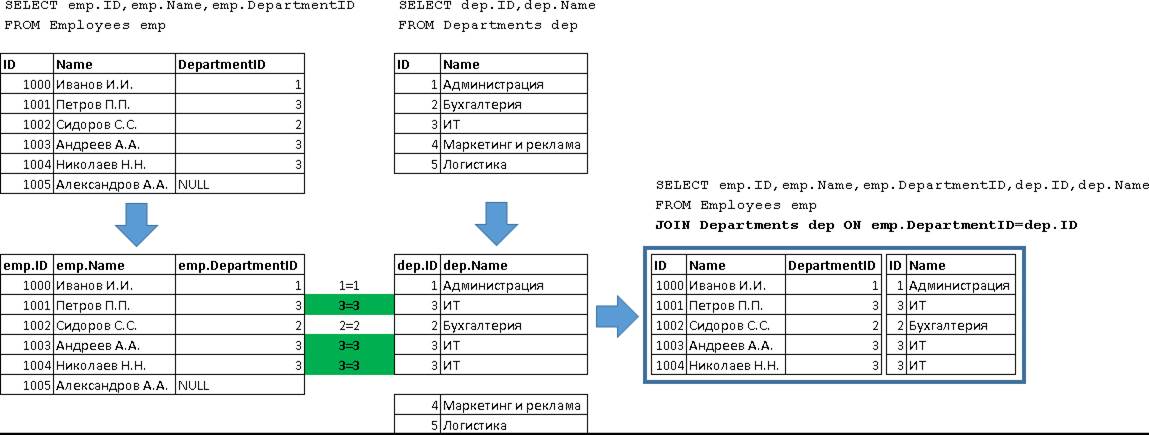
В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу – для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение – просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
SELECT dep.ID,dep.Name,emp.ID,emp.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID
| Name
| ID
| Name
|
| 1
| Администрация
| 1000
| Иванов И.И.
|
| 2
| Бухгалтерия
| 1002
| Сидоров С.С.
|
| 3
| ИТ
| 1001
| Петров П.П.
|
| 3
| ИТ
| 1003
| Андреев А.А.
|
| 3
| ИТ
| 1004
| Николаев Н.Н.
|
| 4
| Маркетинг и реклама
| NULL
| NULL
|
| 5
| Логистика
| NULL
| NULL
|
Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н.
Задачу такого рода, можно решить, например, при помощи использования подзапроса:
SELECT dep.ID,dep.Name,emp.ID,emp.Name
FROM Employees emp
/*
объединяем с подзапросом возвращающим последний (максимальный - MAX(ID))
идентификатор сотрудника для каждого отдела (GROUP BY DepartmentID)
*/
JOIN
(
SELECT MAX(ID) MaxEmployeeID
FROM Employees
GROUP BY DepartmentID
) lastEmp
ON emp.ID=lastEmp.MaxEmployeeID
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID -- все данные Departments
| ID
| Name
| ID
| Name
|
| 1
| Администрация
| 1000
| Иванов И.И.
|
| 2
| Бухгалтерия
| 1002
| Сидоров С.С.
|
| 3
| ИТ
| 1004
| Николаев Н.Н.
|
| 4
| Маркетинг и реклама
| NULL
| NULL
|
| 5
| Логистика
| NULL
| NULL
|
При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.
Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
SELECT MAX(ID) MaxEmployeeID
FROM Employees
GROUP BY DepartmentID
| MaxEmployeeID
|
| 1005
|
| 1000
|
| 1002
|
| 1004
|
Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.
Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:
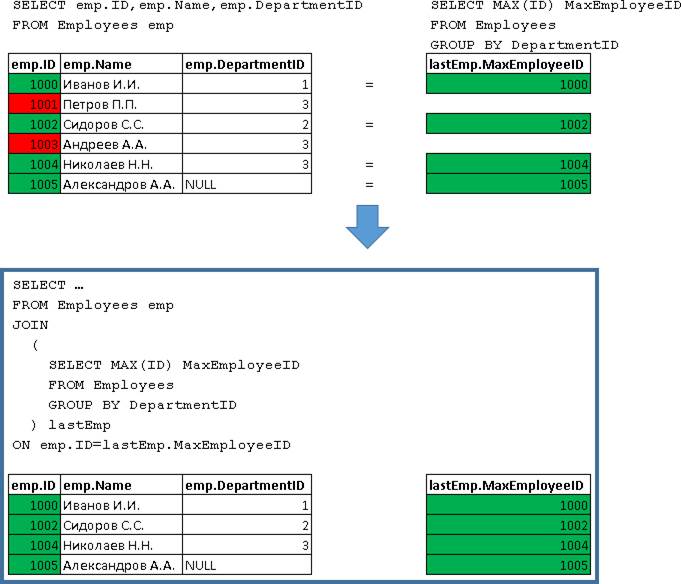
Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:

Самостоятельная работа для закрепления материала
Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.
Для закрепления материала про JOIN-соединения сделаем следующее:
-- очистим таблицы LeftTable и RightTable
TRUNCATE TABLE LeftTable
TRUNCATE TABLE RightTable
GO
-- и зальем в них другие данные
INSERT LeftTable(LCode,LDescr)VALUES
(1,'L-1'),
(2,'L-2a'),
(2,'L-2b'),
(3,'L-3'),
(5,'L-5')
INSERT RightTable(RCode,RDescr)VALUES
(2,'B-2a'),
(2,'B-2b'),
(3,'B-3'),
(4,'B-4')
Посмотрим, что в таблицах:
SELECT *
FROM LeftTable
| LCode
| LDescr
|
| 1
| L-1
|
| 2
| L-2a
|
| 2
| L-2b
|
| 3
| L-3
|
| 5
| L-5
|
SELECT *
FROM RightTable
| RCode
| RDescr
|
| 2
| B-2a
|
| 2
| B-2b
|
| 3
| B-3
|
| 4
| B-4
|
А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 2
| L-2a
| 2
| B-2a
|
| 2
| L-2a
| 2
| B-2b
|
| 2
| L-2b
| 2
| B-2a
|
| 2
| L-2b
| 2
| B-2b
|
| 3
| L-3
| 3
| B-3
|
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 1
| L-1
| NULL
| NULL
|
| 2
| L-2a
| 2
| B-2a
|
| 2
| L-2a
| 2
| B-2b
|
| 2
| L-2b
| 2
| B-2a
|
| 2
| L-2b
| 2
| B-2b
|
| 3
| L-3
| 3
| B-3
|
| 5
| L-5
| NULL
| NULL
|
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 2
| L-2a
| 2
| B-2a
|
| 2
| L-2b
| 2
| B-2a
|
| 2
| L-2a
| 2
| B-2b
|
| 2
| L-2b
| 2
| B-2b
|
| 3
| L-3
| 3
| B-3
|
| NULL
| NULL
| 4
| B-4
|
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode
| LDescr
| RCode
| RDescr
|
| 1
| L-1
| NULL
| NULL
|
| 2
| L-2a
| 2
| B-2a
|
| 2
| L-2a
| 2
| B-2b
|
| 2
| L-2b
| 2
| B-2a
|
| 2
| L-2b
| 2
| B-2b
|
| 3
| L-3
| 3
| B-3
|
| 5
| L-5
| NULL
| NULL
|
| NULL
| NULL
| 4
| B-4
|
SELECT l.*,r.*
FROM LeftTable l
CROSS JOIN RightTable r
| LCode
| LDescr
| RCode
| RDescr
|
| 1
| L-1
| 2
| B-2a
|
| 2
| L-2a
| 2
| B-2a
|
| 2
| L-2b
| 2
| B-2a
|
| 3
| L-3
| 2
| B-2a
|
| 5
| L-5
| 2
| B-2a
|
| 1
| L-1
| 2
| B-2b
|
| 2
| L-2a
| 2
| B-2b
|
| 2
| L-2b
| 2
| B-2b
|
| 3
| L-3
| 2
| B-2b
|
| 5
| L-5
| 2
| B-2b
|
| 1
| L-1
| 3
| B-3
|
| 2
| L-2a
| 3
| B-3
|
| 2
| L-2b
| 3
| B-3
|
| 3
| L-3
| 3
| B-3
|
| 5
| L-5
| 3
| B-3
|
| 1
| L-1
| 4
| B-4
|
| 2
| L-2a
| 4
| B-4
|
| 2
| L-2b
| 4
| B-4
|
| 3
| L-3
| 4
| B-4
|
| 5
| L-5
| 4
| B-4
|
Еще раз про JOIN-соединения
Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось – не выбрасывать же материал.;) Но ничего «повторение – мать учения».
Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
SELECT
e.ID,
e.Name EmployeeName,
p.Name PositionName,
d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
Первым делом выбрались все записи таблицы Employees:
SELECT
e.*
FROM Employees e -- 1
Дальше произошло соединение с таблицей Departments:
SELECT
e.*, -- к полям Employees
d.* -- добавились соответствующие (e.DepartmentID=d.ID) поля Departments
FROM Employees e -- 1
LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2
Дальше уже идет соединение этого набора с таблицей Positions:
SELECT
e.*, -- к полям Employees
d.*, -- добавились соответствующие (e.DepartmentID=d.ID) поля Departments
p.* -- добавились соответствующие (e.PositionID=p.ID) поля Positions
FROM Employees e -- 1
LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2
LEFT JOIN Positions p ON e.PositionID=p.ID -- 3
Т.е. это выглядит примерно так:

И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
SELECT
e.ID, -- 1. идентификатор сотрудника
e.Name EmployeeName, -- 2. имя сотрудника
p.Name PositionName, -- 3. название должности
d.Name DepartmentName -- 4. название отдела
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
SELECT
e.ID, -- 1. идентификатор сотрудника
e.Name EmployeeName, -- 2. имя сотрудника
p.Name PositionName, -- 3. название должности
d.Name DepartmentName -- 4. название отдела
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
WHERE d.ID=3 -- используем поля из поле ID из Departments
AND p.ID=3 -- используем для фильтрации поле ID из Positions
ORDER BY e.Name -- используем для сортировки поле Name из Employees
| ID
| EmployeeName
| PositionName
| DepartmentName
|
| 1004
| Николаев Н.Н.
| Программист
| ИТ
|
| 1001
| Петров П.П.
| Программист
| ИТ
|
То есть последний полученный набор – представляет собой такую же таблицу, над которой можно выполнять базовый запрос:
SELECT [DISTINCT] список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
В результате чего получаем тот же самый базовый запрос:
SELECT
e.ID,
e.Name EmployeeName,
p.Name PositionName,
d.Name DepartmentName
FROM
/* источник - начало */
Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
/* источник - конец */
WHERE d.ID=3
AND p.ID=3
ORDER BY e.Name
А теперь, применим группировку:
SELECT
ISNULL(dep.Name,'Прочие') DepName,
COUNT(DISTINCT emp.PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(emp.Salary) SalaryAmount,
AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM
/* источник - начало */
Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
/* источник - конец */
GROUP BY emp.DepartmentID,dep.Name
ORDER BY DepName
Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
SELECT
d.Name DepartmentName,
p.Name PositionName,
e.EmplCount
FROM Departments d
CROSS JOIN Positions p
LEFT JOIN
(
/*
здесь я использовал подзапрос для подсчета сотрудников
в разрезе групп (DepartmentID,PositionID)
*/
SELECT DepartmentID,PositionID,COUNT(*) EmplCount
FROM Employees
GROUP BY DepartmentID,PositionID
) e
ON e.DepartmentID=d.ID AND e.PositionID=p.ID
ORDER BY DepartmentName,PositionName
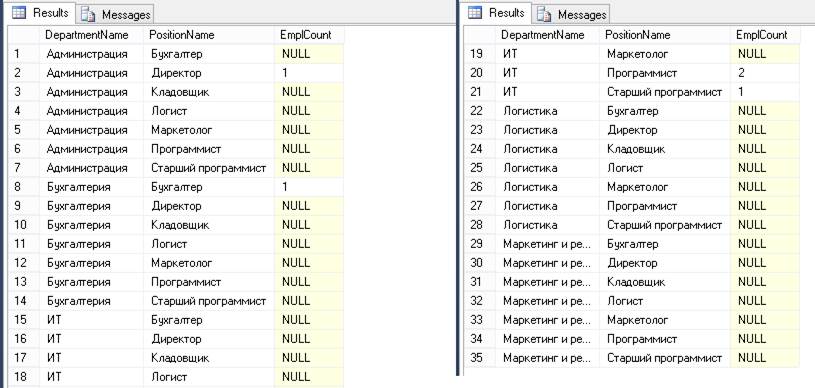
В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
SELECT DepartmentID,PositionID,COUNT(*) EmplCount
FROM Employees
GROUP BY DepartmentID,PositionID
| DepartmentID
| PositionID
| EmplCount
|
| NULL
| NULL
| 1
|
| 2
| 1
| 1
|
| 1
| 2
| 1
|
| 3
| 3
| 2
|
| 3
| 4
| 1
|
Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы,
все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.





