Во-первых, т.к. мы в запросе не указали WHERE-условия, то итоги будут считаться для детальных данных, которые получаются запросом:
SELECT * FROM Employees
т.е. для всех строк таблицы Employees.
Для наглядности выберем только поля и выражения, которые используются в агрегатных функциях:
SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent [Salary/100*BonusPercent],
Salary
FROM Employees
| DepartmentID
| PositionID
| BonusPercent
| Salary/100*BonusPercent
| Salary
|
| 1
| 2
| 50
| 2500
| 5000
|
| 3
| 3
| 15
| 225
| 1500
|
| 2
| 1
| NULL
| NULL
| 2500
|
| 3
| 4
| 30
| 600
| 2000
|
| 3
| 3
| NULL
| NULL
| 1500
|
| NULL
| NULL
| NULL
| NULL
| 2000
|
Это исходные данные (детальные строки), по которым и будут считаться итоги агрегированного запроса.
Теперь разберем каждое агрегированное значение:
COUNT(*) – т.к. мы не задали в запросе условия фильтрации в блоке WHERE, то COUNT(*) дало нам общее количество записей в таблице, т.е. это количество строк, которое возвращает запрос:
SELECT * FROM Employees

|
COUNT(DISTINCT DepartmentID) – вернуло нам значение 3, т.е. это число соответствует числу уникальных значений департаментов указанных в столбце DepartmentID без учета NULL значений. Пройдемся по значениям колонки DepartmentID и раскрасим одинаковые значения в один цвет (не стесняйтесь, для обучения все методы хороши): 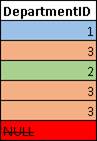 Отбрасываем NULL, после чего, мы получили 3 уникальных значения (1, 2 и 3). Т.е. значение получаемое COUNT(DISTINCT DepartmentID), в развернутом виде можно представить следующей выборкой:
SELECT DISTINCT DepartmentID -- 2. берем только уникальные значения
FROM Employees
WHERE DepartmentID IS NOT NULL -- 1. отбрасываем NULL значения Отбрасываем NULL, после чего, мы получили 3 уникальных значения (1, 2 и 3). Т.е. значение получаемое COUNT(DISTINCT DepartmentID), в развернутом виде можно представить следующей выборкой:
SELECT DISTINCT DepartmentID -- 2. берем только уникальные значения
FROM Employees
WHERE DepartmentID IS NOT NULL -- 1. отбрасываем NULL значения

|
COUNT(DISTINCT PositionID) – то же самое, что было сказано про COUNT(DISTINCT DepartmentID), только полю PositionID. Смотрим на значения колонки PositionID и не жалеем красок: 
|
COUNT(BonusPercent) – возвращает количество строк, у которых указано значение BonusPercent, т.е. подсчитывается количество записей, у которых BonusPercent IS NOT NULL. Здесь нам будет проще, т.к. не нужно считать уникальные значения, достаточно просто отбросить записи с NULL значениями. Берем значения колонки BonusPercent и вычеркиваем все NULL значения:  Остается 3 значения. Т.е. в развернутом виде выборку можно представить так:
SELECT BonusPercent -- 2. берем все значения
FROM Employees
WHERE BonusPercent IS NOT NULL -- 1. отбрасываем NULL значения Остается 3 значения. Т.е. в развернутом виде выборку можно представить так:
SELECT BonusPercent -- 2. берем все значения
FROM Employees
WHERE BonusPercent IS NOT NULL -- 1. отбрасываем NULL значения
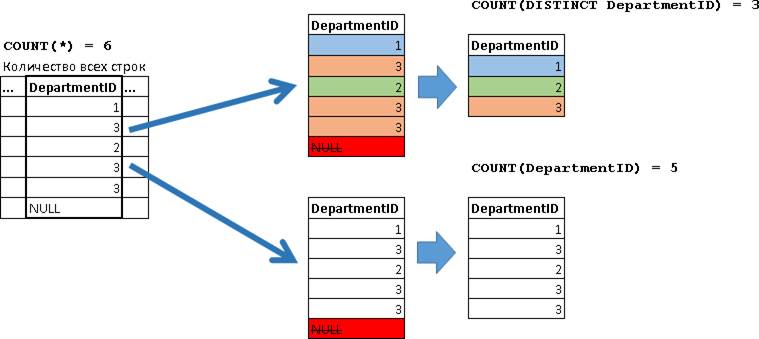
 Т.к. мы не использовали слова DISTINCT, то посчитаются и повторяющиеся BonusPercent в случае их наличия, без учета BonusPercent равных NULL. Для примера давайте сделаем сравнение результата с использованием DISTINCT и без него. Для большей наглядности воспользуемся значениями поля DepartmentID:
SELECT
COUNT(*), -- 6
COUNT(DISTINCT DepartmentID), -- 3
COUNT(DepartmentID) -- 5
FROM Employees Т.к. мы не использовали слова DISTINCT, то посчитаются и повторяющиеся BonusPercent в случае их наличия, без учета BonusPercent равных NULL. Для примера давайте сделаем сравнение результата с использованием DISTINCT и без него. Для большей наглядности воспользуемся значениями поля DepartmentID:
SELECT
COUNT(*), -- 6
COUNT(DISTINCT DepartmentID), -- 3
COUNT(DepartmentID) -- 5
FROM Employees
|
MAX(BonusPercent) – возвращает максимальное значение BonusPercent, опять же без учета NULL значений. Берем значения колонки BonusPercent и ищем среди них максимальное значение, на NULL значения не обращаем внимания: 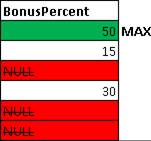 Т.е. мы получаем следующее значение:
SELECT TOP 1 BonusPercent
FROM Employees
WHERE BonusPercent IS NOT NULL
ORDER BY BonusPercent DESC -- сортируем по убыванию Т.е. мы получаем следующее значение:
SELECT TOP 1 BonusPercent
FROM Employees
WHERE BonusPercent IS NOT NULL
ORDER BY BonusPercent DESC -- сортируем по убыванию
|
MIN(BonusPercent) – возвращает минимальное значение BonusPercent, опять же без учета NULL значений. Как в случае с MAX, только ищем минимальное значение, игнорируя NULL: 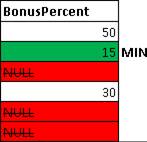 Т.е. мы получаем следующее значение:
SELECT TOP 1 BonusPercent
FROM Employees
WHERE BonusPercent IS NOT NULL
ORDER BY BonusPercent -- сортируем по возрастанию
Наглядное представление MIN(BonusPercent) и MAX(BonusPercent): Т.е. мы получаем следующее значение:
SELECT TOP 1 BonusPercent
FROM Employees
WHERE BonusPercent IS NOT NULL
ORDER BY BonusPercent -- сортируем по возрастанию
Наглядное представление MIN(BonusPercent) и MAX(BonusPercent): 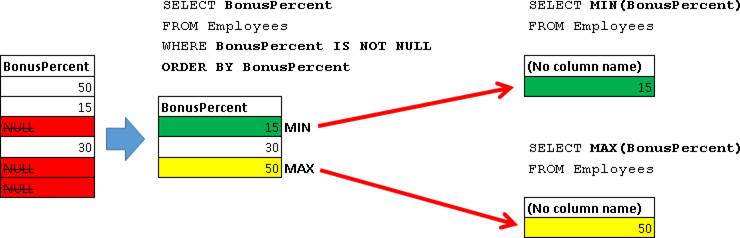
|
SUM(Salary/100*BonusPercent) – возвращает сумму всех не NULL значений. Разбираем значения выражения (Salary/100*BonusPercent):  Т.е. происходит суммирование следующих значений:
SELECT Salary/100*BonusPercent
FROM Employees
WHERE Salary/100*BonusPercent IS NOT NULL Т.е. происходит суммирование следующих значений:
SELECT Salary/100*BonusPercent
FROM Employees
WHERE Salary/100*BonusPercent IS NOT NULL

|
AVG(Salary/100*BonusPercent) – возвращает среднее значений. NULL-выражения не учитываются, т.е. это соответствует второму выражению:
SELECT
AVG(Salary/100*BonusPercent), -- 1108.33333333333
SUM(Salary/100*BonusPercent)/COUNT(Salary/100*BonusPercent), -- 1108.33333333333
SUM(Salary/100*BonusPercent)/COUNT(*) -- 554.166666666667
FROM Employees
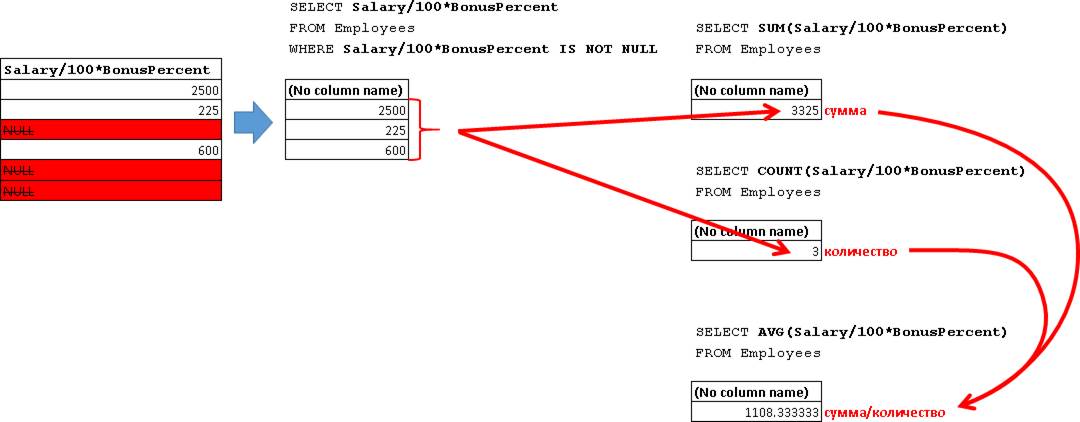 Т.е. опять же NULL-значения не учитываются при подсчете количества. Если же вам необходимо вычислить среднее по всем сотрудникам, как в третьем выражении, которое дает 554.166666666667, то используйте предварительное преобразование NULL значений в ноль:
SELECT
AVG(ISNULL(Salary/100*BonusPercent,0)), -- 554.166666666667
SUM(Salary/100*BonusPercent)/COUNT(*) -- 554.166666666667
FROM Employees Т.е. опять же NULL-значения не учитываются при подсчете количества. Если же вам необходимо вычислить среднее по всем сотрудникам, как в третьем выражении, которое дает 554.166666666667, то используйте предварительное преобразование NULL значений в ноль:
SELECT
AVG(ISNULL(Salary/100*BonusPercent,0)), -- 554.166666666667
SUM(Salary/100*BonusPercent)/COUNT(*) -- 554.166666666667
FROM Employees
|
| AVG(Salary) – собственно, здесь все то же самое что и в предыдущем случае, т.е. если у сотрудника Salary равен NULL, то он не учтется. Чтобы учесть всех сотрудников, соответственно делаете предварительное преобразование NULL значений AVG(ISNULL(Salary,0))
|
Подведем некоторые итоги:
·COUNT(*) – служит для подсчета общего количества строк, которые получены оператором «SELECT … WHERE …»
·во всех остальных вышеперечисленных агрегатных функциях при расчете итога, NULL-значения не учитываются
·если нам нужно учесть все строки, это больше актуально для функции AVG, то предварительно необходимо осуществить обработку NULL значений, например, как было показано выше «AVG(ISNULL(Salary,0))»
Соответственно при задании с агрегатными функциями дополнительного условия в блоке WHERE, будут подсчитаны только итоги, по строкам удовлетворяющих условию. Т.е. расчет агрегатных значений происходит для итогового набора, который получен при помощи конструкции SELECT. Например, сделаем все тоже самое, но только в разрезе ИТ-отдела:
SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
| Общее кол-во сотрудников
| Число уникальных отделов
| Число уникальных должностей
| Кол-во сотрудников у которых указан % бонуса
| Максимальный процент бонуса
| Минимальный процент бонуса
| Сумма всех бонусов
| Средний размер бонуса
| Средний размер ЗП
|
| 3
| 1
| 2
| 2
| 30
| 15
| 825
| 412.5
| 1666.66666666667
|
Предлагаю вам, для большего понимания работы агрегатных функций, самостоятельно проанализировать каждое полученное значение. Расчеты здесь ведем, соответственно, по детальным данным полученным запросом:
SELECT
DepartmentID,
PositionID,
BonusPercent,
Salary/100*BonusPercent [Salary/100*BonusPercent],
Salary
FROM Employees
WHERE DepartmentID=3 -- учесть только ИТ-отдел
| DepartmentID
| PositionID
| BonusPercent
| Salary/100*BonusPercent
| Salary
|
| 3
| 3
| 15
| 225
| 1500
|
| 3
| 4
| 30
| 600
| 2000
|
| 3
| 3
| NULL
| NULL
| 1500
|
Идем, дальше. В случае, если агрегатная функция возвращает NULL (например, у всех сотрудников не указано значение Salary), или в выборку не попало ни одной записи, а в отчете, для такого случая нам нужно показать 0, то функцией ISNULL можно обернуть агрегатное выражение:
SELECT
SUM(Salary),
AVG(Salary),
-- обрабатываем итог при помощи ISNULL
ISNULL(SUM(Salary),0),
ISNULL(AVG(Salary),0)
FROM Employees
WHERE DepartmentID=10 -- здесь специально указан несуществующий отдел, чтобы запрос не вернул записей
| (No column name)
| (No column name)
| (No column name)
| (No column name)
|
| NULL
| NULL
| 0
| 0
|
Я считаю, что очень важно понимать назначение каждой агрегатной функции и то каким образом они производят расчет, т.к. в SQL это главный инструмент, который служит для расчета итоговых значений.
В данном случае мы рассмотрели, как каждая агрегатная функция ведет себя самостоятельно, т.е. она применялась к значениям всего набора записей полученным командой SELECT. Дальше мы рассмотрим, как эти же функции применяются для вычисления итогов по группам, при помощи конструкции GROUP BY.






