Собственно, если вы поняли, что такое группировка, то с HAVING ничего сложного нет. HAVING – чем-то подобен WHERE, только если WHERE-условие применяется к детальным данным, то HAVING-условие применяется к уже сгруппированным данным. По этой причине в условиях блока HAVING мы можем использовать либо выражения с полями, входящими в группировку, либо выражения, заключенные в агрегатные функции.
Рассмотрим пример:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
| DepartmentID
| SalaryAmount
|
| 1
| 5000
|
| 3
| 5000
|
Т.е. данный запрос вернул нам сгруппированные данные только по тем отделам, у которых сумма ЗП всех сотрудников превышает 3000, т.е. «SUM(Salary)>3000».
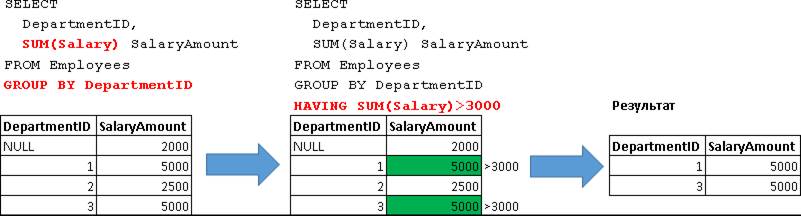
Т.е. здесь в первую очередь происходит группировка и вычисляются данные по всем отделам:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам
А уже к этим данным применяется условие указанно в блоке HAVING:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID -- 1. получаем сгруппированные данные по всем отделам
HAVING SUM(Salary)>3000 -- 2. условие для фильтрации сгруппированных данных
В HAVING-условии так же можно строить сложные условия используя операторы AND, OR и NOT:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
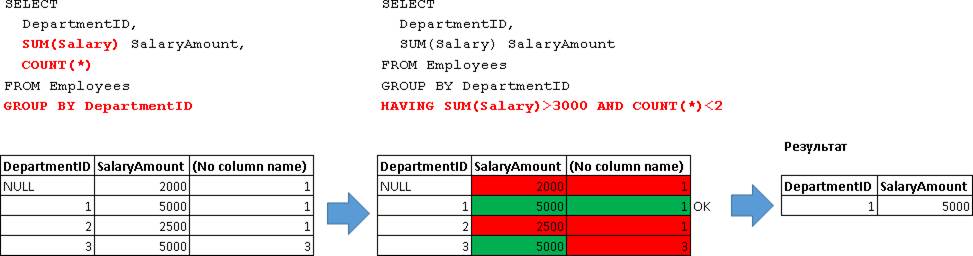
Как можно здесь заметить агрегатная функция (см. «COUNT(*)») может быть указана только в блоке HAVING.
Соответственно мы можем отобразить только номер отдела, подпадающего под HAVING-условие:
SELECT
DepartmentID
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Пример использования HAVING-условия по полю включенного в GROUP BY:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID -- 1. сделать группировку
HAVING DepartmentID=3 -- 2. наложить фильтр на результат группировки
Это только пример, т.к. в данном случае проверку логичнее было бы сделать через WHERE-условие:
SELECT
DepartmentID,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- 1. провести фильтрацию детальных данных
GROUP BY DepartmentID -- 2. сделать группировку только по отобранным записям
Т.е. сначала отфильтровать сотрудников по отделу 3, и только потом сделать расчет.
Примечание. На самом деле, несмотря на то, что эти два запроса выглядят по-разному оптимизатор СУБД может выполнить их одинаково.
Думаю, на этом рассказ о HAVING-условиях можно окончить.
Подведем итоги
Сведем данные полученные во второй и третьей части и рассмотрим конкретное месторасположение каждой изученной нами конструкции и укажем порядок их выполнения:
| Конструкция/Блок
| Порядок выполнения
| Выполняемая функция
|
| SELECT возвращаемые выражения
| 4
| Возврат данных полученных запросом
|
| FROM источник
| 0
| В нашем случае это пока все строки таблицы
|
| WHERE условие выборки из источника
| 1
| Отбираются только строки, проходящие по условию
|
| GROUP BY выражения группировки
| 2
| Создание групп по указанному выражению группировки. Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках
|
| HAVING фильтр по сгруппированным данным
| 3
| Фильтрация, накладываемая на сгруппированные данные
|
| ORDER BY выражение сортировки результата
| 5
| Сортировка данных по указанному выражению
|
Конечно же, вы так же можете применить к сгруппированным данным предложения DISTINCT и TOP, изученные во второй части.
Эти предложения в данном случае применятся к окончательному результату:
SELECT
TOP 1 -- 6. применится в последнюю очередь
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
ORDER BY DepartmentID -- 5. сортировка результата
SELECT
DISTINCT -- показать только уникальные значения SalaryAmount
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
| SalaryAmount
|
| 2000
|
| 2500
|
| 5000
|
Как получились данные результаты проанализируйте самостоятельно.
Заключение
Основная цель которую я ставил в данной части – раскрыть для вас суть агрегатных функций и группировок.
Если базовая конструкция позволяла нам получить необходимые детальные данные, то применение агрегатных функций и группировок к этим детальным данным, дало нам возможность получить по ним сводные данные. Так что, как видите здесь все важно, т.к. одно опирается на другое – без знания базовой конструкции мы не сможем, например, правильно отобрать данные, по которым нам нужно просчитать итоги.
Здесь я намеренно стараюсь показывать только основы, чтобы сосредоточить внимание начинающих на самых главных конструкциях и не перегружать их лишней информацией. Твердое понимание основных конструкций (о которых я еще продолжу рассказ в последующих частях) даст вам возможность решить практически любую задачу по выборке данных из РБД. Основные конструкции оператора SELECT применимы в таком же виде практически во всех СУБД (отличия в основном состоят в деталях, например, в реализации функций – для работы со строками, временем, и т.д.).
В последующем, твердое знание базы даст вам возможность самостоятельно легко изучить разные расширения языка SQL, такие как:
·GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), …
·PIVOT, UNPIVOT
·и т.п.
В рамках данного учебника я решил не рассказывать об этих расширениях, т.к. и без их знания, владея только базовыми конструкциями языка SQL, вы сможете решать очень большой спектр задач. Расширения языка SQL по сути служат для решения какого-то определенного круга задач, т.е. позволяют решить задачу определенного класса более изящно (но не всегда эффективней в плане скорости или затраченных ресурсов).
Если вы делаете первые шаги в SQL, то сосредоточьтесь в первую очередь, именно на изучении базовых конструкций, т.к. владея базой, все остальное вам понять будет гораздо легче, и к тому же самостоятельно. Вам в первую очередь, как бы нужно объемно понять возможности языка SQL, т.е. какого рода операции он вообще позволяет совершить над данными. Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции.






