Психоакустические факторы и их учет при построении систем сжатия звуковой информации
Сжатие (компрессия) аудиоданных представляет собой процесс уменьшения скорости цифрового потока за счет сокращения статистической и психоакустической избыточности цифрового звукового сигнала.
Методы сокращения статистической избыточности аудиоданных также называют сжатием без потерь, а, соответственно, методы сокращения психоакустической избыточности - сжатием с потерями.
Сжатие без потерь
Сокращение статистической избыточности основано на учете свойств самих звуковых сигналов. Она определяется наличием корреляционной связи между соседними отсчетами цифрового звукового сигнала, устранение которой позволяет сокращать объем передаваемых данных на 15...25% по сравнению с их исходной величиной. Для передачи сигнала необходимо получить более компактное его представление, что возможно осуществить с помощью ортогонального преобразования. Важными условиями применения такого метода преобразования являются:
§ возможность восстанавливать исходный сигнал без искажений
§ способность обеспечивать наибольшую концентрацию энергии в небольшом числе коэффициентов преобразования
§ быстрый вычислительный алгоритмом
Этим требованиям отвечает модифицированное дискретно-косинусное преобразование (МДКП).
Уменьшить скорость цифрового потока позволяют методы кодирования, учитывающие статистику звуковых сигналов, например, вероятности появления уровней разной величины. Одним из таких методов является код Хаффмана, где наиболее вероятным значениям сигнала приписываются более короткие кодовые слова, а значения отсчетов, вероятность появления которых мала, кодируются кодовыми словами большей длины. Именно в силу этих двух причин в наиболее эффективных алгоритмах компрессии цифровых аудиоданных кодированию подвергаются не сами отсчеты звукового сигнала, а коэффициенты МДКП.
Сжатие с потерями
Сжатие аудиоданных с потерями (сокращение психоакустической избыточности) основывается на несовершенстве человеческого слуха при восприятии звуковой информации. Неспособность человека в определенных случаях различать тихие звуки в присутствии более громких, называемая эффектом маскировки, была использована в алгоритмах сокращения психоакустической избыточности.
Эффекты слухового маскирования зависят от спектральных и временных характеристик маскируемого и маскирующего сигналов и могут быть разделены на две основные группы:
§ частотное (одновременное) маскирование
§ временное (неодновременное) маскирование
Эффект маскирования в частотной области связан с тем, что в присутствии больших звуковых амплитуд человеческое ухо нечувствительно к малым амплитудам близких частот. То есть, когда два сигнала одновременно находятся в ограниченной частотной области, то более слабый сигнал становится неслышимым на фоне более сильного.
Маскирование во временной области характеризует динамические свойства слуха, показывая изменение во времени относительного порога слышимости (порог слышимости одного сигнала в присутствии другого), когда маскирующий и маскируемый сигналы звучат не одновременно. При этом следует различать явления послемаскировки (изменение порога слышимости после сигнала высокого уровня) и предмаскировки (изменение порога слышимости перед приходом сигнала максимального уровня). Более слабый сигнал становится неслышимым за 5 − 20 мс до включения сигнала маскирования и становится слышимым через 50 − 200 мс после его включения.
Очевидно, что после устранения психоакустической избыточности звуковых сигналов их точное восстановления при декодировании оказывается уже невозможным. Методами устранения психофизической избыточности можно обеспечить сжатие цифровых аудиоданных в 10 − 12 раз без существенных потерь в качестве.
Психоакустическая модель — использование феномена восприятия человеком звука, для сжатия информации с потерями при хранении звуковой информации
Оболонин, Аудиотехнические устройства и системы, стр 184:
Ключевыми моментами при разработке любой психоакустической модели являются:
1) вид ортогонального преобразования;
2) алгоритм обработки коэффициентов преобразования (БПФ или МДКП) с целью максимально возможного уменьшения числа учитываемых спектральных составляющих;
3) выбор аппроксимирующих функций для учета явления маскировки, включая проблему суммирования индивидуальных кривых маскировки;
4) процедура расчета глобального порога маскировки для спектральной выборки сигнала.
Известны в основном три психоакустические модели: NMR (Noise to Mask Ratio - отношение сигнал/маска); PAQM - Perceptual Audio Quality Measure; PERCEVAL - PerCeptual EVALion. Наибольшее распространение пока получила модель NMR, в которой учитываются абсолютный порог слышимости, и явление маскировки в частотной области. Это позволяет частично устранить при передаче части звукового сигнала не важные для слухового восприятия - Redundanz und Irrelevanz.
Эффект маскировки
В определённых случаях один звук может быть скрыт другим звуком. Например, разговор рядом с железнодорожными путями может быть совершенно невозможен, если мимо проезжает поезд. Этот эффект называется маскировкой. Говорят, что слабый звук маскируется, если он становится неразличимым в присутствии более громкого звука.
МАСКИРОВКА ЗВУКА - явление, заключающееся в ухудшении слышимости одного звука (сигнала) в присутствии др. звуков (помех).
несколько видов маскировки: одновре́менное (моноуральное) маскирование; вре́менное (неодновременное) маскирование
Одновременная маскировка
Любые два звука при одновременном прослушивании оказывают влияние на восприятие относительной громкости между ними. Более громкий звук снижает восприятие более слабого, вплоть до исчезновения его слышимости. Чем ближе частота маскируемого звука к частоте маскирующего, тем сильнее он будет скрываться. Эффект маскировки не одинаков при смещении маскируемого звука ниже или выше по частоте относительно маскирующего. Более низкочастотный звук сильнее маскирует высокочастотный. При этом важно отметить, что высокочастотный звук не может маскировать низкочастотный звук.
Вре́менная маскировка
Это явление похоже на частотную маскировку, но здесь происходит маскировка во времени. При прекращении подачи маскирующего звука маскируемый некоторое время продолжает быть неслышимым. В обычных условиях эффект от временной маскировки длится значительно меньше. Время маскировки зависит от частоты и амплитуды сигнала и может достигать 100 мс.
В случае, когда маскирующий тон появляется по времени позже маскируемого, эффект называют пост-маскировкой. Когда маскирующий тон появляется раньше маскируемого (возможен и такой случай), эффект называют пре-маскировкой.
 рисунок: Частотная зависимость уровня маскирующего сигнала LM, необходимого для маскировки тонального сигнала с частотой 1 кГц и уровнем 20 дБ: 1 - при одновременной маскировке; 2 - при прямой последовательной маскировке.
рисунок: Частотная зависимость уровня маскирующего сигнала LM, необходимого для маскировки тонального сигнала с частотой 1 кГц и уровнем 20 дБ: 1 - при одновременной маскировке; 2 - при прямой последовательной маскировке.
При одноврем. маскировке тонального сигнала шумовым, спектр к-рого ограничен полосой с центр, частотой, соответствующей сигналу, расширение спектра маскера при постоянной интегральной энергии до нек-рого значения ширины полосы не влияет на величину M. з. Расширение же вне этой полосы, называемой критической, приводит к снижению M. з.
Постстимульное утомление
Нередко после воздействия громких звуков высокой интенсивности у человека резко снижается слуховая чувствительность. Восстановление обычных порогов может продолжаться до 16 часов. Этот процесс называется «временный сдвиг порога слуховой чувствительности» или «постстимульное утомление». Сдвиг порога начинает появляться при уровне звукового давления выше 75 дБ и соответственно увеличивается при повышении уровня сигнала. Причём наибольшее влияние на сдвиг порога чувствительности оказывают высокочастотные составляющие сигнала.
Фантомы
Иногда человек может слышать звуки в низкочастотной области, хотя в реальности звуков такой частоты не было. Так происходит из-за того, что колебания базилярной мембраны в ухе не являются линейными и в ней могут возникать колебания с разностной частотой между двумя более высокочастотными.
Этот эффект используется в некоторых коммерческих звуковых системах, чтобы расширить область воспроизводимых низких частот, если невозможно адекватно воспроизвести такие частоты напрямую, например в наушниках. При долгом прослушивании это может быть вредно для слуха.
Если сигнал и помеха широкополосны, то величина одновременной M. з. в большом динамич. диапазоне пропорциональна уровню интенсивности помехи. Если сигнал и маскер - тоны одинаковой частоты, то M. з. растёт медленнее уровня маскера. При различии спектрального состава сигнала и помехи M. з. определяется гл. обр. составляющими помехи, близкими по спектру к сигналу. Для выявления частотной избирательности слуха в качестве сигнала и маскера используют чистые тоны или очень узкополосные шумы. Зависимость от частоты уровня маскера, необходимого для маскировки слабого сигнала фиксиров. частоты и уровня, характеризует частотную настройку слуховой системы в области частоты сигнала (рис.). В режиме прямой последо-ват. маскировки частотная избирательность повышается, что объясняется проявлением нелинейных свойств улитки уха.
Человеческое ухо способно воспринять звуки с частотой от 20 до 22000 Гц, но его чувствительность не является одинаковой в этом интервале. Она зависит от частоты звука. Эксперименты указывают на то, что в тихой окружающей обстановке чувствительность уха максимальна при частотах от 2 до 4 кГц. На рис. 6.4а показан порог слышимости для тихого окружения.
Для эффективного сжатия звука применяются два свойства органов слуха человека. Эти свойства называются частотное маскирование и временное маскирование.
Частотное маскирование (его еще называют слуховое маскирование) происходит тогда, когда нормально слышимый звук накрывается другим громким звуком с близкой частотой. Толстая стрелка на рис. 6.4b обозначает громкий источник звука с частотой 800 Гц. Этот звук приподнимает порог слышимости в своей окрестности (пунктирная линия). В результате звук, обозначенный тоненькой стрелкой в точке «х» и имеющий нормальную громкость выше своего порога чувствительности, становится неслышимым; он маскируется более громким звуком. Хороший метод сжатия звука должен использовать это свойство слуха и удалять сигналы, соответствующие звуку «х», поскольку они все равно не будут услышаны человеком. Это один возможный путь сжатия с потерями.
 Частотное маскирование (область под пунктирной линией на рис. 6.4b) зависит от частоты сигнала. Оно варьируется от 100 Гц для низких слышимых частот до более, чем 4 кГц высоких частот. Следовательно, область слышимых частот можно разделить на несколько критических полос, которые обозначают падение чувствительности уха (не путать со снижением мощности разрешения) для более высоких частот.
Частотное маскирование (область под пунктирной линией на рис. 6.4b) зависит от частоты сигнала. Оно варьируется от 100 Гц для низких слышимых частот до более, чем 4 кГц высоких частот. Следовательно, область слышимых частот можно разделить на несколько критических полос, которые обозначают падение чувствительности уха (не путать со снижением мощности разрешения) для более высоких частот.
Рис. 6.4. Порог и маскирование звука.
Можно считать критические полосы еще одной характеристикой звука, подобной его частоте. Однако, в отличие от частоты, которая абсолютна и не зависит от органов слуха, критические полосы определяются в соответствии со слуховым восприятием.
Критические полосы можно описать следующим образом: из-за ограниченности слухового восприятия звуковых частот порог слышимости частоты  приподнимается соседним звуком, если звук находится в критической полосе . Это свойство открывает путь для разработки практического алгоритма сжатия аудиоданных с потерями. Звук необходимо преобразовать в частотную область, а получившиеся величины (частотный спектр) следует разделить на подполосы, которые максимально приближают критические полосы. Если это сделано, то сигналы каждой из подполос нужно квантовать так, что шум квантования (разность между исходным звуковым сэмплом и его квантованными значениями) был неслышимым.
приподнимается соседним звуком, если звук находится в критической полосе . Это свойство открывает путь для разработки практического алгоритма сжатия аудиоданных с потерями. Звук необходимо преобразовать в частотную область, а получившиеся величины (частотный спектр) следует разделить на подполосы, которые максимально приближают критические полосы. Если это сделано, то сигналы каждой из подполос нужно квантовать так, что шум квантования (разность между исходным звуковым сэмплом и его квантованными значениями) был неслышимым.
Еще один возможный взгляд на концепцию критической полосы состоит в том, что органы слуха человека можно представить себе как своего рода фильтр, который пропускает только частоты из некоторой области (полосы пропускания) от 20 до 20000 Гц. В качестве модели ухо- мозг мы рассматриваем некоторое семейство фильтров, каждый из которых имеет свою полосу пропускания. Эти полосы называются критическими. Они пересекаются и имеют разную ширину.
В области низких слышимых частот ширина критической полосы менее 100 Гц, в районе 2 кГц она равна 300 Гц и возрастает до 4 кГц в области высших воспринимаемых частот
 Ширина критической полосы называется ее размером. Для измерения этой величины вводится новая единица «барк» («Bark» от H.G.Barkhausen). Один барк равен ширине (в герцах) одной критической полосы. Эта единица определяется по формуле:
Ширина критической полосы называется ее размером. Для измерения этой величины вводится новая единица «барк» («Bark» от H.G.Barkhausen). Один барк равен ширине (в герцах) одной критической полосы. Эта единица определяется по формуле:
На рисунке в Мамчев, основы цифр ТВ стр 127, рис 2.8 показаны несколько критических полос которые помещены над кривой порогов слышимости.
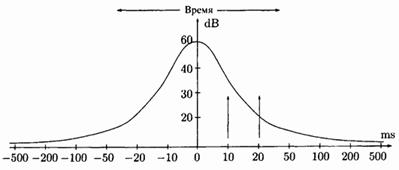 Рис. 6.6. Порог и маскирование звука.
Рис. 6.6. Порог и маскирование звука.
Временное маскирование происходит, когда громкому звуку  частоты по времени предшествует или за ним следует более слабый звук
частоты по времени предшествует или за ним следует более слабый звук  близкой частоты. Если интервал времени между этими звуками не велик, то звук будет не слышен. Рис. 6.6 иллюстрирует пример временного маскирования. Порог временного маскирования от громкого звука в момент времени 0 идет вверх сначала круто, а потом полого. Более слабый звук в 30 дБ не будет слышен, если он раздастся за 10 мсек до или после громкого звука, но будет различим, если временной интервал между ними будет больше 20 мсек.
близкой частоты. Если интервал времени между этими звуками не велик, то звук будет не слышен. Рис. 6.6 иллюстрирует пример временного маскирования. Порог временного маскирования от громкого звука в момент времени 0 идет вверх сначала круто, а потом полого. Более слабый звук в 30 дБ не будет слышен, если он раздастся за 10 мсек до или после громкого звука, но будет различим, если временной интервал между ними будет больше 20 мсек.
Выделение границ Канни
Канни изучил математическую проблему получения фильтра, оптимального по критериям выделения, локализации и минимизации нескольких откликов одного края. Он показал, что искомый фильтр является суммой четырех экспонент. Он также показал, что этот фильтр может быть хорошо приближен первой производной Гауссианы. Канни ввел понятие Non-Maximum Suppression (подавление не-максимумов), которое означает, что пикселями границ объявляются пиксели, в которых достигается локальный максимум градиента в направлении вектора градиента.
Хотя его работа была проведена на заре компьютерного зрения, детектор границ Канни до сих пор является одним из лучших детекторов. Кроме особенных частных случаев трудно найти детектор, который бы работал существенно лучше, чем детектор Канни.
Детектор Канни-Дерише был выведен из похожего математического критерия, как и детектор Канни, хотя, отталкиваясь от другой точки зрения, он привел к набору рекурсивных фильтров для сглаживания изображения вместо экспоненциальных фильтров и фильтров Гаусса.
Уточнение границы
Уточнение границы — процесс, который делает границы тонкими, удаляя нежелательные ложные точки, которые появляются на границе. Эта техника применяется уже после того, как изображение было сглажено (используя медиану или фильтр Гаусса), был применен оператор границ (как один из описанных выше) для вычисления силы края и после того, как границы были очищены используя подходящие пороги. Этот метод удаляет все нежелательные точки и при аккуратном применении выдает границы толщиной в один пиксель.
Плюсы:
§ резкие и тонкие границы позволяют повысить эффективность распознавания объектов
§ при использовании трансформации Хафа для обнаружения прямых или эллипсов, тонкие границы дают значительно лучшие результаты
§ если граница представляет собой границу некоторой области, тонкие границы позволяют вычислить такие параметры, как периметр, без какой-то сложной арифметики
Существует много популярных методов для решения этой задачи. Один из них описан далее:
1. Выбрать тип связности: 8, 6 или 4
§ Предпочтительна 8-связность, при которой рассматриваются все пиксели, непосредственно окружающие текущий пиксель
2. Удалить точки сверху, снизу, слева и справа от точки
§ Делать это следует в несколько проходов, то есть сначала удалить точки в одном направлении, затем на обработанном изображении удалить точки на другом.
§ Точка удаляется в следующем случае:
1. У этой точки нет соседей сверху (в случае обработки «верхнего» направления, иначе — в соответствующем направлении)
2. Эта точка не является концом линии
3. Удаление этой точки никак не повлияет на связанность её соседей
4. ИЛИ это изолированная точка
§ Иначе, точка не удаляется
3. Предыдущий шаг можно повторять несколько раз, в зависимости от желаемого уровня «аккуратности» границы.
Семейство стандартов MPEG
MPEG расшифровывается как «Moving Picture Coding Experts Group», дословно - группа экспертов по кодированию подвижных изображений. MPEG ведет свою историю с января 1988 года. Начиная с первого собрания в мае 1988 года, группа начала расти, и выросла до очень большого коллектива специалистов. Обычно, в собрании MPEG принимают участие около 350 специалистов из более чем 200 компаний. Большая часть участников MPEG — это специалисты, занятые в тех или иных научных и академических учреждениях.
Стандарт MPEG -1
Стандарт MPEG-1 (ISO/IEC 11172-3) включает в себя три алгоритма различных уровней сложности: Layer (уровень) I, Layer II и Layer III. Общая структура процесса кодирования одинакова для всех уровней. Однако, несмотря схожесть уровней в общем подходе к кодированию, уровни различаются п левому использованию и внутренним механизмам. Для каждого уровня определен цифровой поток (общая ширина потока) и свой алгоритм декодирования
MPEG-1 предназначен для кодирования сигналов, оцифрованных с частотой дискретизации 32, 44.1 и 48 КГц. Как было указано выше, MPEG-1 имеет три уровня (Layer I, II и Ш). Эти уровни имеют различия в обеспечиваемом коэффициенте сжатия и качестве звучания получаемых потоков.
MPEG-1 нормирует для всех трех уровней следующие номиналы скоростей цифрового потока: 32, 48, 56, 64, 96, 112, 192, 256, 384 и 448 кбит/с, число уровней квантования входного сигнала - от 16 до 24. Стандартным входным сигналом для кодера MPEG-1 принят цифровой сигнал AES/EBU (двухканальный цифровой звуковой сигнал с разрядностью квантования 20... 24 бита на отчет) Предусматриваются следующие режимы работы звукового кодера:
■ одиночный канал (моно);
■ двойной канал (стерео или два моноканала);
■ joint stereo (сигнал с частичным разделением правого и левого каналов). Важнейшим свойством MPEG-1 является полная обратная совместимость
всех трех уровней. Это означает, что каждый декодер может декодировать сигналы не только своего, но и нижележащих уровней.
В основу алгоритма Уровня I положен, разработанный компанией Philips для записи на компакт-кассеты, формат DCC (Digital Compact Cassette). Кодирование первого уровня применяется там, где не очень важна степень компрессии и решающими факторами являются сложность и стоимость кодера и декодера. Кодер Уровня I обеспечивает высококачественный звук при скорости цифрового потока 384 кбит/с на стереопрограмму.
Уровень II требует более сложного кодера и несколько более сложного декодера, но обеспечивает лучшее сжатие — «прозрачность» канала достигается уже при скорости 256 кбит/с. Он допускает до 8 кодирований/декодирований без заметного ухудшения качества звука. В основу алгоритма Уровня П положен популярный в Европе формат MUSICAM.
Самый сложный Уровень III включает все основные инструменты сжатия: полосное кодирование, дополнительное ДКП, энтропийное кодирование, усовершенствованную ПАМ. За счет усложнения кодера и декодера он обеспечивает высокую степень компрессии - считается, что «прозрачный» канал формируется на скорости 128 кбит/с, хотя высококачественная передача возможна и на более низких скоростях,
В стандарте рекомендованы две психоакустические модели: более простая Модель 1 и более сложная, но и более высококачественная Модель 2. Они
отличаются алгоритмом обработки отсчетов. Обе модели могут использоваться
всех трех уровней, но Модель 2 имеет специальную модификацию для Уровня III.
MPEG -1 оказался первым международным стандартом цифрового сжатия звуковых сигналов и это обусловило его широкое применение во многих областях: вещании, звукозаписи, связи и мультимедийных приложениях. Наиболее широко используется Уровень II, он вошел составной частью в европейские спутникового, кабельного и наземного цифрового ТВ вещания, в стандарты звукового вещания, записи на DVD, Рекомендации МСЭ BS.1115 и J.52. Уровень III (его еще называют МР-3) нашел широкое применение в цифровых сетях с интегральным обслуживанием (ISDN) и в сети Интернет Подавляющее большинство музыкальных файлов в сети записаны именно в этом стандарте.
Цифровой аудиоформат — формат представления звуковых данных, используемый при цифровой звукозаписи, а также для дальнейшего хранения записанного материала на компьютере и других электронных носителях информации, так называемых звуковых носителях.
Разновидности цифровых аудиоформатов
Существуют различные понятия звукового формата.
Формат представления звуковых данных в цифровом виде зависит от способа квантования цифро-аналоговым преобразователем (ЦАП). В звукотехнике в настоящее время наиболее распространены два вида квантования:
§ импульсно-кодовая модуляция
§ сигма-дельта-модуляция
Зачастую разрядность квантования и частоту дискретизации указывают для различных звуковых устройств записи и воспроизведения как формат представления цифрового звука (24 бита/192 кГц; 16 бит/48 кГц).
Формат файла определяет структуру и особенности представления звуковых данных при хранении на запоминающем устройстве ПК. Для устранения избыточности аудио данных используются аудиокодеки, при помощи которых производится сжатие аудиоданных. Выделяют три группы звуковых форматов файлов:
§ аудиоформаты без сжатия, такие как WAV, AIFF
§ аудиоформаты со сжатием без потерь (APE, FLAC)
§ аудиоформаты, с применением сжатия с потерями (mp3, ogg)
Особняком стоят модульные музыкальные форматы файлов. Созданные синтетически или из сэмплов заранее записанных живых инструментов, они, в основном, служат для создания современной электронной музыки (MOD). Также сюда можно отнести формат MIDI, который не является звукозаписью, но при этом с помощью секвенсора позволяет записывать и воспроизводить музыку, используя определенный набор команд в текстовом виде.
Форматы носителей цифрового звука применяют как для массового распространения звуковых записей (CD, SACD), так и в профессиональной звукозаписи (DAT, минидиск).
Для систем пространственного звучания также можно выделить форматы звука, в основном являющиеся звуковым многоканальным сопровождением к кинофильмам. Такие системы имеют целые семейства форматов от двух крупных конкурирующих компаний Digital Theater Systems Inc. — DTS и Dolby Laboratories Inc. — Dolby Digital.
Также форматом называют количество каналов в системах многоканального звука (5.1; 7.1). Изначально такая система была разработана для кинотеатров, но впоследствии была расширена для систем домашнего кинотеатра.
MP3 (более точно, англ. MPEG-1/2/2.5 Layer 3; но не MPEG-3) — третий слой формата кодирования звуковой дорожки MPEG, лицензируемый формат файла для хранения аудиоинформации.
В формате MP3 используется алгоритм сжатия с потерями, разработанный для существенного уменьшения размера данных, необходимых для воспроизведения записи и обеспечения качества воспроизведения звука очень близкого к оригинальному (по мнению большинства слушателей). При создании MP3 со средним битрейтом 128 кбит/с в результате получается файл, размер которого примерно равен 1/11 от оригинального файла с CD-Audio. Само по себе несжатое аудио формата CD-Audio имеет битрейт 1411,2 кбит/с. MP3-файлы могут создаваться с высоким или низким битрейтом, который влияет на качество файла-результата. Принцип сжатия заключается в снижении точности некоторых частей звукового потока, что практически неразличимо для слуха большинства людей. Данный метод называюткодированием восприятия.[1] При этом на первом этапе строится диаграмма звука в виде последовательности коротких промежутков времени, затем на ней удаляется информация не различимая человеческим ухом, а оставшаяся информация сохраняется в компактном виде. Данный подход похож на метод сжатия, используемый при сжатии картинок в формат JPEG.
Описание формата
Как и формат JPEG, MP3 использует спектральные отсечения, согласно психоакустической модели. Вспомним анатомию уха (Улитка является механическим измерителемАЧХ и по действию схожа с АЧХ-метром) следовательно звук необходимо представить как спектр. Звуковой сигнал разбивается на равные по продолжительности отрезки, каждый из которых после обработки упаковывается в свой фрейм (кадр). Разложение в спектр требует непрерывности входного сигнала, посему для расчётов используется также предыдуший и следующий фрейм. В звуковом сигнале есть гармоники с меньшой амплитудой и гармоники, лежащие вблизи более интенсивных — такие гармоники отсекаются, так как среднестатистическое человеческое ухо не всегда сможет определить присутствие либо отсутствие таких гармоник (пример: световая завеса — когда яркий источник света не позволяет разглядеть более тёмный предмет, который находится на заднем плане). Также возможна замена двух и более близлежащих пиков одним усреднённым (что как правило и приводит к искажению звука). Критерий отсечения определяется требованием к выходному потоку. Поскольку весь спектр актуален, мы не можем отсекать высокочастотные гармоники как в JPEG, но мы можем облегчить информацию за счёт разрежения спектра. После спектральной «зачистки» применяются математические методы сжатия и упаковка во фреймы. Каждый фрейм может иметь несколько контейнеров, что позволяет хранить информацию о нескольких потоках (левый и правый канал либо центральный канал и разница каналов). Степень сжатия можно варьировать, в том числе в пределах одного файла. Интервал возможных значений битрейтасоставляет 8-320 кбит/c.
Так как формат MP3 поддерживает двухканальное кодирование (стерео), существует 4 режима:
§ Стерео — это
§ Моно — одноканальное кодирование
§ Двухканальное стерео (англ. Dual Channel) — два независимых канала,
§ Объединённое стерео (англ. Joint Stereo, M/S Stereo) —
AAC
+ мамчев основы цтв стр 139
AAC — это широкополосный алгоритм кодирования аудио, который использует два основных принципа кодирования для сильного уменьшения количества данных, требуемых для передачи высококачественного цифрового аудио. Данный формат является одним из наиболее качественных, использующих сжатие с потерями, поддерживаемый большинством современного оборудования, в том числе портативного
Как работает AAC
1. Удаляются невоспринимаемые составляющие сигнала.
2. Удаляется избыточность в кодированном аудио сигнале.
3. Затем сигнал обрабатывается по методу МДКП согласно его сложности.
4. Добавляются коды коррекции внутренних ошибок.
5. Сигнал сохраняется или передаётся.
Аудио стандарт MPEG-4 не требует единственного или малого набора высокоэффективных схем компрессии, а скорее сложный набор для выполнения широкого круга операций от кодирования низкокачественной речи до высококачественного аудио и синтезирования музыки.
§ Семейство алгоритмов аудио кодирования MPEG-4 охватывает диапазон от кодирования низкокачественной речи (до 2 кбит/с) до высококачественного аудио (от 64 кбит/с на канал и выше).
§ AAC имеет частоту дискретизации от 8 Гц до 96 кГц и количество каналов от 1 до 48.
§ В отличие от гибридного набора фильтров MP3, AAC использует Модифицированное Дискретное Косинусное Преобразование (MDCT) вместе с увеличенным размером «окна» в 2048 пунктов. AAC более подходит для кодирования аудио с потоком сложных импульсов и прямоугольных сигналов, чем MP3.
AAC может динамически переключаться между длинами блоков MDCT от 2048 пунктов до 256.
§ Если происходит единственная или кратковременная смена, используется малое «окно» в 256 пунктов для лучшего разрешения.
§ По умолчанию используется большое 2048-пунктовое «окно» для улучшения эффективности кодирования.
Преимущества AAC перед MP3
§ До 48 звуковых каналов;
§ Бо́льшая эффективность кодирования как при постоянном, так и при переменном битрейте;
§ Частоты дискретизации от 8 Гц до 96 кГц (MP3: 8 Гц — 48 кГц);
§ Более гибкий режим Joint stereo.
OGG
OGG Vorbis - относительно новый формат аудио компресии, официально вышедшей летом 2002 года. Он пренадлежит к таким видов форматов, как MP3, AAC, VQF и WMA, то есть к форматам компрессии с потерями. Психоаккустическая модель OGG близка к MP3, но математическая обработка и практическая реализация этой модели в корне отличаются. преимущество формата Ogg Vorbis - использование новейшей и наиболее качественной психоаккустической модели, из-за чего соотношение битрейт/качество значительно ниже, чем у других форматов. Как результат качество звука лучше, но размер файла меньше. Ogg Vorbis не ограничивает пользователя только двумя аудио каналами (стерео левый и правый). Он поддерживает до 255 отдельных каналов с частотой дискретизации до 192kHz и разрядностью до 32bit (чего не позволяет ни один формат сжатия с потерями), поэтому Ogg Vorbis великолепно подходит для кодирования 6-ти канального звука DVD-Audio. К тому же, формат OGG Vorbis sample accurate. Это гарантирует, что звуковые данные перед кодированием и после декодирования не будут иметь смещений или дополнительных/потерянных сэмплов относительно друг друга. Ogg Vorbis был разработан сообществом Xiphophorus для того, чтобы заменить все платные запатентованные аудио форматы. Несмотря на то, что это самый молодой формат из всех конкурентов МР3, Ogg Vorbis имеет полную поддержку на всех известных платформах (Windows, PocketPC, Symbian, DOS, Linux, MacOS, FreeBSD, BeOS и др.), а также большое количество аппаратных реализаций. Популярность на сегодняшний день значительно превосходит все альтернативные решения. Как правило, формат.OGG используеться в играх.
OGG Vorbis — свободный формат сжатия звука с потерями, официально появившийся летом 2002 года. По функциональности и качеству аналогичен таким кодекам как AAC, AC3 и VQF, превосходящим MP3.Психоакустическая модель, используемая в Vorbis, по принципам действия близка к MP3 и подобным, однако математическая обработка и практическая реализация этой модели существенно отличаются, что позволило авторам объявить свой формат совершенно независимым от всех предшественников.
Vorbis идеален для применения в качестве звуковых дорожек фильмов, так как не изменяет их длину при переменном битрейте, что позволяет сохранять синхронность с видеодорожкой и применим для многоканального звука (например 6-канальный звук DVD).
Преимущества Vorbis
§ Отсутствие патентных ограничений.
§ До 255 каналов.
§ «Sample accurate» — звуковые данные не будут иметь смещений, дополнительных или потерянных семплов относительно друг друга.
§ «Streamable» — поддержка поточного воспроизведения.
§ Эффективные алгоритмы переменного битрейта.
§ Частота дискретизации до 192 кГц.
§ Разрядность до 32 бит.
§ Гибкий Joint stereo.
§ Гибкая психоакустическая модель.
§ Теги хранятся в Юникоде, а не в национальной кодировке.
Недостатки
§ Требует большей вычислительной мощи, чем MP3.
WMA (Windows Media Audio)
WMA (Windows Media Audio) является продуктом небезызвестной компании Microsoft. Он был создан как альтернатива «народному» формату МРЗ, чтобы стать еще «народней». Последнее утверждение считаем справедливым, потому что в последних версиях Windows Media Player установлен кодировщик, позволяющий сжимать компакт-диски сразу в формат WMA. А с учетом того, что Windows установлена на большинстве компьютеров мира, разработчики рассчитывали переманить пользователей на сторону ■ своего формата.
С точки зрения качества звучания формат WMA практически идентичен формату МРЗ, в чем-то превосходя, в чем-то уступая ему. WMA 8 с битрейтом 128 кбит/с уступает по качеству не только CD, но и МРЗ. Но на низких битрейтах он превосходит своего соперника, опять же, по понятным нам причинам.
Выпущенный WMA 9 стал поддерживать сжатие с переменным битрейтом и сжатие без потерь, однако по качеству звучания так и не превзошел WMA8.
Интересной особенностью формата WMA является защита авторских прав. Если вы не отключите защиту (DRM) при кодировании, то вы не сможете воспроизвести созданный файл на любом другом компьютере. Для этого необходимо загрузить специальный сертификат, разрешающий проигрывать файл ограниченное время, после которого необходимо будет купить его или целый диск.
Большим плюсом является поддержка формата многими бытовыми проигрывателями, портативными устройствами, автомагнитолами и другой ау-диотехникой.
Аудио, сжатое в формат WMA поддерживается сегодня большим количеством аппаратных плееров.
Плюсы
§ Полная поддержка со стороны Windows.
Минусы
§ Чрезвычайно низкое качество при низком битрейте.
§ Полная закрытость.
Microsoft WMA V1
Microsoft WMA V2
Microsoft WMA V7
Microsoft WMA V9
Схема вокодера

| Анализатор
А - анализатор спектра
Т-Ш - выделитель сигнала тон-шум
ВОТ - выделитель основного тона
УО - устройство объедин. сигналов
КС - канал связи
Синтезатор
УР - устройство разъед. сигналов
С - синтезатор спектра
П - переключатель вида спектра
ГОТ - генератор основного тона
ГШ - генератор шума
|
Вокодеры.
Вокодеры можно разделить на два класа:- речеэлементные;- параметрические.
В речеэлементных вокодерах при кодировании распознаются произносимые элементы речи (например, фонема) и на выход кодера подаются только их номера. В декодере эти элементы создаются по правилам речеобразования или берутся из памяти декодера. Фонемные вокодеры предназначены для получения предельной компрессии речевых сигналов. Область применения фонемных вокодеров - линии командной связи, управление и говорящие автоматы информационно-справочной службы. В таких вокодерах происходит автоматическое распознавание слуховых образов, а не определение параметров речи и, соответственно, теряются все индивидуальные особенности диктора.
Вообще вокодер (от английских слов voice-голос и coder-кодер) представляет собой устройство, которое совершает параметрическое компандирование речевых сигналов.
Компрессия речевых сигналов в кодере осуществляется в анализаторе, который выделяет с речевого сигнала параметры, которые медленно меняются. В декодере при помощи местных источников сигналов, которые управляются принятыми параметрами, синтезируется речевой сигнал.
В параметрических вокодерах с речевого сигнала выделяют два типа параметров и по этим параметрам в декодере синтезируют речь:
- Параметры, которые характеризуют источник речевых колебаний (генераторную функцию) - частота основного тона, ее изменение во времени, моменты появления и исчезновения основного тона (огласованные или гортанные звуки), шумового сигнала (шипящие и свистящие звуки);
- Параметры, которые характеризуют огибающую спектра речевого сигнала.
В декодере, соответственно, по заданным параметрам генерируются основной тон, шу





