Кафедра математических проблем управления
Н.Б. Осипенко
ОСНОВЫ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Практическое пособие
Гомель 2010
Предисловие
1. ВВЕДЕНИЕ В ПРИКЛАДНУЮ СТАТИСТИКУ.. 4
1.1. Что такое прикладная статистика. 4
1.2. Возможные подходы к статистическому анализу данных. 4
1.3. Основные этапы статистической обработки исходных данных. 6
1.3.1. Этап 1. 7
1.3.2. Этап 2. 7
1.3.3. Этап 3. 7
1.3.4. Этап 4. 7
1.3.5. Этап 5. 8
1.3.6. Этап 6. 8
1.3.7. Этап 7. 8
1.4. Причины малоэффективного использования машинных методов анализа данных. 8
1.5. Измерение признаковых значений в анализе данных. 9
1.5.1. Измерение. 9
1.5.2. Шкалы.. 9
1.6. Разведочный анализ данных. 10
1.6.1. Основные особенности разведочного анализа данных. 10
1.6.2. Модели структуры многомерных данных в разведочном анализе данных. 10
1.7. Упрощение описания. 11
2. СТАТИСТИЧЕСКОЕ ИССЛЕДОВАНИЕ ЗАВИСИМОСТЕЙ.. 12
2.1. Общая схема взаимодействия переменных при статистическом исследовании зависимостей. 12
2.2. Конечные прикладные цели статистического исследования зависимостей. 12
2.3. Математический инструментарий статистического исследования зависимостей. 13
3. ИНТЕЛЛЕКТУАЛЬНЫЙ АНАЛИЗ ДАННЫХ (ИАД) - НОВОЕ РАЗВИТИЕ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ 14
3.1. Основные факторы пересмотра технологий анализа данных. 14
3.2. Характерные особенности задач нового типа в компьютерном анализе данных. 14
3.3. Схема эволюции систем анализа данных и систем поддержки принятия решений. 15
3.4. Направления интеллектуального анализа данных (DM) 16
4. КРАТКАЯ ХАРАКТЕРИСТИКА CASE - ТЕХНОЛОГИЙ.. 18
4.1. Два способа улучшения бизнес-процесса: непрерывное усовершенствование и реинжиниринг. 18
4.1.1. Что такое бизнес-процесс, зачем и как его усовершенствовать... 18
4.1.2. «Непрерывное совершенствование бизнес-процессов». 18
4.1.3. Реинжиниринг. 18
4.2. Понятие консалтинга в области информационных технологий. 19
4.3. CASE-технологии - методологическая и инструментальная база консалтинга. 20
4.4. BPwin - средство концептуального моделирования бизнес-процессов предприятия. 21
4.4.1. Общие сведения о работе в среде пакета BPwin. 21
4.4.2. BPwin как SADT технология. 22
4.4.3. Основные элементы и понятия методологии IDEF0. 22
4.5. Классификация структурных методологий. 25
5. ЗАКЛЮЧЕНИЕ.. 27
6. СПИСОК ЛИТЕРАТУРЫ... 28
ПРЕДИСЛОВИЕ
Всех специалистов, профессионально занимающихся обработкой статистических данных, условно можно разделить на три категории: 1) приверженцы классической математической статистики (объектами их исследований обычно являются некоторые разделы биологии или физики); 2) представители школы обработки экспериментальных данных в рамках идеологии исследования операций (предметом их разработок чаще всего бывают результаты активных экспериментов над сложной технической системой); 3) специалисты по прикладной статистике и анализу данных, ориентированные на исследование естественных и социальных систем в таких, например, областях, как геология, медицина, экономика и социология. Характер данных и методологическое видение проблемного материала во всех трёх случаях столь различны, что в действительности эти три течения статистических исследований следовало бы признать самостоятельными. В настоящем пособии авторы придерживаются тематики прикладной статистики и анализа данных, окончательно сформировавшейся к концу 80-х годов. Наиболее полно эта область прикладной математики изложена в трёхтомном справочном издании по прикладной статистике под редакцией С.А.Айвазяна [1, 2, 3]. В настоящее время это издание стало большой редкостью, а равноценная и более доступная литература так и не появилась. Поэтому форма подачи материала настоящего пособия соответствует упомянутому выше справочнику, при этом упор сделан на технологию исследования и идеи алгоритмов.
Компьютерные технологии в научных исследованиях непрерывно совершенствуются и пополняются новыми разработками в области прикладного программного обеспечения. В пособии приводится краткая характеристика особенностей интеллектуального анализа данных и современных CASE-средств - инструментария для системных аналитиков, разработчиков и программистов, а также методологий структурного анализа и проектирования программного обеспечения.
ВВЕДЕНИЕ В ПРИКЛАДНУЮ СТАТИСТИКУ
Этап 1
На этом этапе определяются: основные цели исследования на неформализованном, содержательном уровне; совокупность единиц (объектов), представляющая предмет статистического исследования; набор параметров-признаков 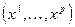 для описания обследуемых объектов; степень формализации соответствующих записей при сборе данных; время и трудозатраты, объем работ; выделение ситуаций, требующих предварительной проверки перед составлением детального плана исследований; формализованная постановка задачи; в каком виде осуществляется сбор первичной информации и введение в ЭВМ.
для описания обследуемых объектов; степень формализации соответствующих записей при сборе данных; время и трудозатраты, объем работ; выделение ситуаций, требующих предварительной проверки перед составлением детального плана исследований; формализованная постановка задачи; в каком виде осуществляется сбор первичной информации и введение в ЭВМ.
Если обработка проводится с помощью существующего пакета статистической обработки, то трудоемкость этого этапа бывает сравнима с суммарной трудоемкостью остальных этапов.
Этап 2
При составлении детального плана сбора первичной информации необходимо учитывать как и для чего данные анализируются, т.е. учитывать полную схему анализа. Этот этап называют "организационно-методической подготовкой", так как на нем планируется: какой должна быть выборка - случайной, пропорциональной, расслоенной (если используется аппарат общей теории выборочных обследований); объем и продолжительность исследования; схема проведения активного эксперимента (в случае, если он возможен) с привлечением методов планирования эксперимента и регрессионного анализа для определения некоторых входных переменных.
Этап 3
Сбор исходных данных и введение их в ЭВМ, а также внесение в ЭВМ полного и краткого определения используемых терминов. Существует два вида представления исходных данных: матрица “объект-признак” (1.4):
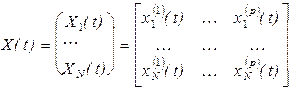 ,
, 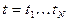 ,
,  (1.4)
(1.4)
где  ,
,  ,
,  - значение k-го признака, характеризующего i-й объект в момент t (числа, текст);
- значение k-го признака, характеризующего i-й объект в момент t (числа, текст);
и матрица “объект-объект”(1.5):
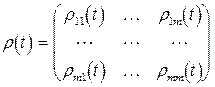 (1.5)
(1.5)
где  - характеристика попарной близости i-го и j-го объектов (при этом m=N) или признаков (при этом m=p) в момент t. Второй вид представления (1.5) часто используется в социологии, где данные собираются с помощью специальных опросников, анкет. Примером характеристики попарной близости признаков может служить ковариационная матрица.
- характеристика попарной близости i-го и j-го объектов (при этом m=N) или признаков (при этом m=p) в момент t. Второй вид представления (1.5) часто используется в социологии, где данные собираются с помощью специальных опросников, анкет. Примером характеристики попарной близости признаков может служить ковариационная матрица.
Этап 4
При первичной статистической обработке данных обычно решаются следующие задачи: отображение вербальных переменных в номинальную (с предписанным числом градаций) или ординальную (порядковую) шкалу; статистическое описание исходных совокупностей с определением пределов варьирования переменных; анализ резко выделяющихся переменных; восстановление пропущенных значений наблюдений; проверка статистической независимости последовательности наблюдений, составляющих массив исходных данных; унификация типов переменных, когда с помощью различных приёмов добиваются унифицированной записи всех переменных; экспериментальный анализ закона распределения исследуемой генеральной совокупности и параметризация сведений о природе изучаемых распределений (эту разновидность первичной статистической обработки называют иногда процессом составления сводки и группировки); вычислительная реализация учета сложности задачи и возможностей ЭВМ; формулировка задачи на входном языке пакета статистической обработки.
Этап 5
Составление детального плана вычислительного анализа. Определяются основные группы, для которых будет проводиться дальнейший анализ.
Пополняется и уточняется тезаурус содержательных понятий. Описывается блок-схема анализа с указанием привлекаемых методов. Формируется оптимизационный критерий, по которому выбирается один из альтернативных методов.
Этап 6
Исследователь на этом этапе осуществляет управление вычислительным процессом, формирует задачу обработки и описания данных на входном языке пакета. Учитываются размерность задачи, алгоритмическая сложность вычислительного процесса, возможности ЭВМ, и особенности данных (обусловленность операций, надежность используемых оценок параметров).
Этап 7
Строится формальный отчет о проведенном исследовании. Интерпретируются результаты применения статистических процедур (оценки параметров, проверки гипотез, отображения в пространство меньшей размерности, классификации). При интерпретации могут использоваться методы имитационного моделирования.
Если исследование проводится в рамках первого подхода (см. п.1.2), то выводы формируются в терминах оценок неизвестных параметров, или в виде отчета о справедливости гипотез с указанием количественной степени достоверности. В случае второго подхода вероятностная интерпретация не делается.
Работа завершается содержательной формулировкой новых задач, вытекающих из проведенного исследования.
1.4. Причины малоэффективного использования
машинных методов анализа данных
В последние десятилетия для решения многочисленных практических задач стали интенсивно использоваться машинные методы анализа данных. Не будучи математиком специалист выбирает модель обработки либо по традиции, либо из доступного и легко интерпретируемого математического обеспечения. При этом он, как правило, не задумывается: соответствует ли его модель природе исходных данных? Подобная некомпетентность исследователя обусловлена рядом причин. Приведем наиболее важные из них.
1. Отсутствие подробных описаний алгоритмов программ, а также информации об ограниченности возможностей модельных алгоритмов и ориентиров по их применению (как в литературе, так и в сопроводительной документации к программному обеспечению).
2. Разделение труда специалиста и математика, появление ничейной зоны деятельности.
Математик ограничен рамками: "Есть множество объектов, описанных признаками..." - "В результате получены закономерности, которые неплохо согласуются с представлениями специалиста...". Он не задумывается о содержании предложенных признаков, имеет ли смысл их совместный анализ, учтены ли все существенные факторы. С другой стороны, специалист не вникает в механизм обработки данных, не интересуется, на каком этапе происходит искажение информации. Интуитивные соображения привлекает только на этапе интерпретации результата, в котором ничего изменить не может.
3. Организационная разобщенность разработчиков алгоритмов и программ; отсутствие гибкой системы распространения программного обеспечения анализа данных.
Измерение
Рассмотрим способы измерения признаков. Обычно под процедурой измерения какого-либо свойства понимается приписывание некоторых числовых значений отдельным уровням этого свойства в определенных единицах. При этом важно знать в какой мере условность в выборе единиц измерения повлияет на значение показателя. Например, если стоимость продукции измерить в рублях, а потом в тысячах рублей, то изменится лишь число единиц измерения, суть же останется прежней. Здесь возможно умножение, деление на константу, т. е. масштабирование. Бессмысленно задавать масштаб для температуры по Цельсию, так как мы не можем сказать во сколько раз -5  меньше +10 . Таким образом разные типы признаков имеют разное множество допустимых преобразований
меньше +10 . Таким образом разные типы признаков имеют разное множество допустимых преобразований  своих значений, которое определяет тип шкалы.
своих значений, которое определяет тип шкалы.
Шкалы
Отображение  , называется шкалой наименований, если его допустимым преобразованием является взаимно однозначное отображение
, называется шкалой наименований, если его допустимым преобразованием является взаимно однозначное отображение  . Шкальные значения играют роль имен объектов. Здесь определено отношение равенства, которое соответствует отношению эквивалентности. Оно индуцирует на А разбиение на непересекающиеся классы. Эти признаки называют классификационными или номинальными. Примеры: профессия, национальность, пол, место рождения.
. Шкальные значения играют роль имен объектов. Здесь определено отношение равенства, которое соответствует отношению эквивалентности. Оно индуцирует на А разбиение на непересекающиеся классы. Эти признаки называют классификационными или номинальными. Примеры: профессия, национальность, пол, место рождения.
Отображение называется шкалой порядка, если его допустимым преобразованием является монотонно возрастающее непрерывное отображение  . Определены отношения равенства и порядка. Первое соответствует эквивалентности объектов, второе - порядку. Отношение эквивалентности индуцирует разбиение А на классы, а отношение порядка задает линейный порядок на множестве классов эквивалентности. Соответствующее отношение порядка задает порядок на множестве различных значений признака
. Определены отношения равенства и порядка. Первое соответствует эквивалентности объектов, второе - порядку. Отношение эквивалентности индуцирует разбиение А на классы, а отношение порядка задает линейный порядок на множестве классов эквивалентности. Соответствующее отношение порядка задает порядок на множестве различных значений признака  , которые называются градациями шкалы порядка. Эти признаки называют порядковыми или ординальными. В строгом смысле примеров шкалы нет. Условно примерами шкалы являются: сила ветра в баллах, образование, оценка на экзамене, шкала твердости минералов.
, которые называются градациями шкалы порядка. Эти признаки называют порядковыми или ординальными. В строгом смысле примеров шкалы нет. Условно примерами шкалы являются: сила ветра в баллах, образование, оценка на экзамене, шкала твердости минералов.
Отображение 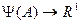 называется количественной шкалой: а) интервалов; б) отношений; в) разностей; г) абсолютной, если допустимым преобразованием является положительное линейное преобразование вида:
называется количественной шкалой: а) интервалов; б) отношений; в) разностей; г) абсолютной, если допустимым преобразованием является положительное линейное преобразование вида:
 ,
,
где для каждого подвида количественной шкалы а) 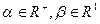 ; б)
; б)  ; в)
; в)  ; г)
; г)  . Примеры: а) любые показатели, значение которых может быть отрицательным: температура по Цельсию, летоисчисление, убытки - прибыль; б) возраст, вес, длина; в) квалификационные разряды, балльные оценки; г) количество элементов некоторого множества, адрес в памяти ЭВМ.
. Примеры: а) любые показатели, значение которых может быть отрицательным: температура по Цельсию, летоисчисление, убытки - прибыль; б) возраст, вес, длина; в) квалификационные разряды, балльные оценки; г) количество элементов некоторого множества, адрес в памяти ЭВМ.
Разведочный анализ данных
Упрощение описания
Стремление комплексно, многомерно описать изучаемую систему или процесс противоречит желанию делать это сжато, ясно. Т.е. с одной стороны: все больший охват количества сторон и связей явлений, а с другой - выделение базисных узловых. Поэтому и возникает вопрос: можно ли проводить статистическую обработку в пространстве меньшей размерности, не теряя определенных свойств исходного пространства. Само сокращение выгодно в связи с тем, что:
- выбираются наиболее важные информативные характеристики (в таком пространстве результаты устойчивее и надежнее);
- упрощается содержательное восприятие и анализ;
- при сокращении до размерности 1-3 возможна визуализация;
- упрощается вычислительный процедуры.
При упрощении описания обычно стремятся не исказить геометрическую структуру множества. При этом за основу для сравнения принимают исходные свойства совокупности, либо выбирают некоторый внешний критерий сокращения размерности.
Рассмотрим три способа сокращения размерности.
1. Переход из исходного описания в новое пространство, оси которого составляют некоторые комбинации исходных признаков. Наиболее распространенным методом такого типа является компонентный анализ, в котором точки проецируются в пространство первых двух компонент. Главные компоненты имеют свойства: сумма квадратов евклидовых расстояний от исходных точек до пространства натянутого на m первых главных компонент, наименьшая относительно любых других подпространств в той же размерности (полученных с помощью линейных преобразований исходных признаков); среди всех подпространств размерности  в пространстве компонент меньше других искажается сумма квадратов евклидовых расстояний между объектами; наилучшим образом сохраняется сумма расстояний до центра тяжести точек и сумма углов между объектами с вершинами в центре тяжести.
в пространстве компонент меньше других искажается сумма квадратов евклидовых расстояний между объектами; наилучшим образом сохраняется сумма расстояний до центра тяжести точек и сумма углов между объектами с вершинами в центре тяжести.
Недостатки подхода: близость измеряется лишь в евклидовом пространстве и по евклидовым расстояниям; первые главные компоненты не всегда хорошо описывают все признаки; критерии гарантируют лишь сохранность суммарных характеристик.
2. Шкалирование - поиск подпространства размерности , в котором разница между расстояниями в исходном и найденном пространстве была бы минимальной. Критерии основаны на оценке отличий матрицы расстояний в двух пространствах:  . Если стремятся точно приблизить матрицы, то шкалирование называют метрическим, если в приближении стремятся сохранить порядок в двух пространствах - то неметрическим. В шкалировании отыскиваются не новые признаки, а новые пространства. Поэтому его результаты интерпретируются как восстановление структуры расположения точек в пространстве (при
. Если стремятся точно приблизить матрицы, то шкалирование называют метрическим, если в приближении стремятся сохранить порядок в двух пространствах - то неметрическим. В шкалировании отыскиваются не новые признаки, а новые пространства. Поэтому его результаты интерпретируются как восстановление структуры расположения точек в пространстве (при  - на плоскости).
- на плоскости).
3. При выборе информативных признаков сокращается размерность без введения новых комбинированных признаков. Если в качестве измерителя близости использовать квадраты евклидовых расстояний, то структуру данных лучше всего описывают признаки с наибольшими дисперсиями.
Удобна любая визуализация данных, а не только проецирование точек. Остановимся на концепции образного анализа. Его идея: представление многомерных данных в виде доступной для человека информации. А. Эндрюс разработал способ кодирования каждой многомерной точки некоторой кривой, которая выдается на печать. Оригинален метод Г. Чернова [5], предполагающий ставить в соответствие объекту черты человеческого лица.
Методы визуализации внутренне парадоксальны - они используют точные алгоритмы с экстремальными свойствами, чтобы впоследствии человек на их основе принял весьма приближенное, естественное в его понимании решение. Такая парадоксальность не тормозит познание, а способствует его успехам.
ИНТЕЛЛЕКТУАЛЬНЫЙ АНАЛИЗ ДАННЫХ (ИАД) - НОВОЕ РАЗВИТИЕ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Наиболее впечатляющий результат в области информационных технологий: к середине 90-х годов объем накопленной информации удваивался каждые 20 месяцев. Объемы БД росли еще быстрее.
Технология БД
БД - специальная форма организации данных, поддерживаемая СУБД для поиска нужного значения параметра в системе формализованных отношений.
Технология OLTP
Стандарт промышленных СУБД, не способных быстро извлекать нужную информацию в режиме РВ был вытеснен с рынка информационных технологий.
Технология OLAP
Усложнение средств АД в процессе принятия решений потребовало усовершенствований в технологиях накопления и обработки данных ("расчеты по заранее заданным формулам")
| Свойство
| OLTP
| OLAP
|
| Назначение данных
| Оперативный поиск, несложная обработка
| Аналитическая обработка, прогнозирование, моделирование
|
| Уровень агрегации
| Детализированный
| Агрегированный
|
| Период хранения
| Несколько месяцев - до 1 года
| Несколько лет - до нескольких. десятков лет
|
| Частота обновления, объем
| Высокая, малыми порциями
| Малая, большими порциями
|
| Критерий эффективности
| Мало транзактов в единицу времени
| Скорость выполнения сложных запросов, прозрачность структуры хранения информации для пользователей
|
4) Технология DWH & DM
Наряду с задачами OLAP-обработки поиск всех релевантных данным и целям их обработки функциональных зависимостей. Характерна взаимная согласованность технологий накопленияданны х (представления данных и знаний, эффективного хранения, поиска и доставки) и автоматического извлечения из них полезных зависимостей (моделей, правил, функциональных отношений).
На 4-м этапе эволюции технологий анализа данных (АД) и систем поддержки принятия решений ( СППР) оказался востребованным опыт, методология и инструментальные средства, характерные для создания и приложений искусственного интеллекта (НН). Причем, основанные, прежде всего, на методах машинного обучения (machine learning) систем интеллектуального АД (ИАД), способных:
1) Выявлять скрытые взаимные влияния различных факторов и вести причинный анализ (то есть давать ответы на вопросы "Почему?")
2) Порождать возможные зависимости в накопленных данных (причем не только заранее заданного вида, например, линейные функции)
3) Анализировать наблюдаемые в накопленных данных аномалии
4) Прогнозировать (на основе порожденных зависимостей) характер поведения объекта исследования.
Реинжиниринг
Приведенная выше модель совершенствования бизнес-процессов эффективна для постепенных, накопительных улучшений. Однако за последние 10 лет в силу ряда причин возникла необходимость ускорить эту работу. Наиболее очевидная причина – технологическая. Современные технологии (например, Интернет) стремительно открывают новые возможности, тем самым поднимая планку соревнования и требуя коренного улучшения бизнес-процессов.
Другая очевидная тенденция – увеличение открытости мировых рынков и объема свободной торговли. На рынок приходит все больше компаний, ужесточается конкуренция. Серьезные перемены нужны уже лишь для того, чтобы не сдать позиции. Для многих предприятий это буквально вопрос жизни и смерти. Таким компаниям требуются не постепенные изменения, а прорыв, и немедленно. Редкое предприятие может позволить себе роскошь постепенных преобразований. Один из новых методов стремительно менять и существенно улучшать бизнес-процессы – реинжиниринг (Business Process Reengineering – BPR).
BRP по своей философии отличается от постоянного совершенствования процессов. В своей радикальной форме он вообще не берет в расчет существующие процессы: раз они не работают, значит испорчены – забудь о них и начни сначала. Такой подход «с чистого листа» позволяет отстраниться от настоящего и сосредоточиться на будущем, задать себе вопрос: как должен выглядеть процесс? Каким хотели бы его видеть мои клиенты? Каким хотели бы его видеть другие сотрудники? Как это делают первоклассные компании? Чего мы могли бы достичь с помощью новой технологии?
Такой подход изображен на рис.4.3: сначала задается объем и цели проекта по реинжинирингу, затем проходит процесс обучения. На этой базе можно выстроить перспективу и разработать новые бизнес-процессы. Определив, «как надо», можно создать план действий исходя из разницы между существующими процессами, технологиями и структурами и теми, которых нужно достичь. В дальнейшем все зависит от реализации.
Рис.4.3.
Таким образом, существуют два полярных способа улучшить бизнес-процессы: непрерывное усовершенствование и реинжиниринг. Разница между ними в том, чтo принимается за основу (существующий процесс или «чистый лист»), а также в величине и скорости итоговых изменений.
Со временем эти две крайности, то есть постепенное улучшение и реформа «скачком», дали много производных. Все они – попытка решить проблему глобальных преобразований на предприятии. Трудно найти единый подход, точно отвечающий конкретным требованиям компании. Задача состоит в том, чтобы понять, какой метод в каком случае выбрать и как применить, чтобы достичь искомого результата.
BPwin как SADT технология
BPwin- представляет собой SADT-технологию, являющуюся одной из самых известных и широко используемых систем проектирования. SADT-аббревиатура слов Structured Analysis Design Technique (Технология структурного анализа и проектирования)-это графические обозначения и подход к описанию систем. SADT-технология представляет собой иерархическую многоуровневую модельную систему сверху-вниз до нужного уровня детализации. Каждый уровень представляет собой законченную систему(блок), поддерживаемую и контролируемую системой(блоком), находящейся над ней. Под словом "система" мы понимаем совокупность взаимодействующих компонент и взаимосвязей между ними. Под термином "моделирование" мы понимаем процесс создания точного описания системы. SADT является полной методологией для создания описания систем, основанной на концепциях системного моделирования. С точки зрения SADT модель может быть сосредоточена либо на функциях системы, либо на ее объектах. SADT-модели, ориентированные на функции, принято называть функциональными моделями, а ориентированные на объекты системы - моделями данных. BPwin ориентирован на построение функциональных моделей с учётом особенностей SADT-технологии. Эта модель представляет с требуемой степенью детализации систему функций, которые в свою очередь отражают свои взаимоотношения через объекты системы.
Три методологии — IDEF0, DFD и IDEF3, поддерживаемые в пакете BPwin, позволяют посмотреть с разных сторон на деятельность предприятия.
IDEF0 –это функциональная модель, предназначенная для описания бизнес-процессов на предприятии. Она позволяет понять, какие объекты или информация служат сырьем для процессов, какие результаты производят работы, что является управляющими факторами и какие ресурсы для этого необходимы. Методология структурного моделирования предполагает построение модели AS-IS (как есть), анализ и выявление недостатков существующих бизнес-процессов и построение модели TO-BE (как должно быть), то есть модели, которая должна использоваться при построении автоматизированной системы управлением предприятия. DFD (Data flow diagramming) переводится на русский как «схемы потоков данных». С их помощью описываются документооборот и обработка информации. Подобно IDEF0, DFD представляет модельную систему как сеть связанных между собой работ. DFD можно использовать как дополнение к модели IDEF0, когда требуется более наглядное отображение текущих операций документооборота, описания функций обработки информации, документов, объектов, а также сотрудников или отделов, которые участвуют в обработке информационных потоков. Для описания логики взаимодействия информационных потоков более подходит IDEF3. Иногда ее называют workflow diagramming (моделирование потоков работ) — моделирование с использованием графического описания информационных потоков, взаимоотношений между процессами обработки информации и объектами, являющимися частью этих процессов. У IDEF3 имеется специфический элемент перекресток. Им описывают последовательность выполнения работ, очередность их запуска и завершения. С помощью workflow-схем можно моделировать сценарии действий сотрудников организации, например порядок обработки заказа или события, на которые необходимо реагировать за конечное время. Каждый сценарий сопровождается описанием процесса и может быть использован для документирования любой функции, моделируемой на схеме IDEF0. Если в одной модели необходимо учесть специфические стороны бизнес-процессов предприятия, BPwin позволяет переключиться на любую нотацию (IDEF0, IDEF3, DFD), находясь на любой ветви схемы, и создать смешанную модель. Пакет BPwin оснащён мощным инструментом навигации под названием Model Explorer. В нем смешанная модель может быть представлена в виде дерева схем, что существенно облегчает навигацию. В пакете BPwin версии 2.5 с помощью Model Explorer и техники перетаскивания можно переносить и копировать работы вместе со всеми соответствующими стрелками как внутри моделей, так и между ними. Все работы IDEF0 показываются в Model Explorer зеленым цветом, DFD — желтым, а IDEF3 — синим.
ЗАКЛЮЧЕНИЕ
В пособии рассмотрены некоторые аспекты, связанные с компьютерными технологиями в научных исследованиях. В пособии приводится краткая характеристика особенностей интеллектуального анализа данных и современных CASE-средств - инструментария для системных аналитиков, разработчиков и программистов, а также методологий структурного анализа и проектирования программного обеспечения.
СПИСОК ЛИТЕРАТУРЫ
1 Айвазян С.А. и др. Прикладная статистика. Основы моделирования и первичная обработка данных. - М: Финансы и статистика, 1983.
2 Афифи А., Эйзен С. Статистический анализ: Подход с использованием ЭВМ. М: Высшая школа, 1991.
3 Буч Г. Обьектно-ориентированное проектирование с примерами применения. -М.: «Конкорд». 1990.
4 Боггс У. Боггс У. UML и Rational Rose. –М.: «Лори», 2001.
5 Корнеев В.В., Гарев А.Ф., Васютин С.В., Райх В.В.. Базы данных. Интеллектуальная обработка информации. -М.:”Номидж”, 2000.
6 Калянов Г.Н. Case-технологии. Консалтинг при автоматизации бизнес-процессов. -М.: «Горячая линия = Телеком», 2002.
7 Макарова Н.В. и др. Информатика. –М.: «Наука», 1998.
Учебное издание
ОСИПЕНКО Наталья Борисовна
ОСНОВЫ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Учреждение образования
«Гомельский государственный университет
имени Франциска Скорины»
246019, г. Гомель, ул. Советская, 104.
Кафедра математических проблем управления
Н.Б. Осипенко
ОСНОВЫ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Практическое пособие
Гомель 2010
Предисловие
1. ВВЕДЕНИЕ В ПРИКЛАДНУЮ СТАТИСТИКУ.. 4
1.1. Что такое прикладная статистика. 4
1.2. Возможные подходы к статистическому анализу данных. 4
1.3. Основные этапы статистической обработки исходных данных. 6
1.3.1. Этап 1. 7
1.3.2. Этап 2. 7
1.3.3. Этап 3. 7
1.3.4. Этап 4. 7
1.3.5. Этап 5. 8
1.3.6. Этап 6. 8
1.3.7. Этап 7. 8
1.4. Причины малоэффективного использования машинных методов анализа данных. 8
1.5. Измерение признаковых значений в анализе данных. 9
1.5.1. Измерение. 9
1.5.2. Шкалы.. 9
1.6. Разведочный анализ данных. 10
1.6.1. Основные особенности разведочного анализа данных. 10
1.6.2. Модели структуры многомерных данных в разведочном анализе данных. 10
1.7. Упрощение описания. 11
2. СТАТИСТИЧЕСКОЕ ИССЛЕДОВАНИЕ ЗАВИСИМОСТЕЙ.. 12
2.1. Общая схема взаимодействия переменных при статистическом исследовании зависимостей. 12
2.2. Конечные прикладные цели статистического исследования зависимостей. 12
2.3. Математический инструментарий статистического исследования зависимостей. 13
3. ИНТЕЛЛЕКТУАЛЬНЫЙ АНАЛИЗ ДАННЫХ (ИАД) - НОВОЕ РАЗВИТИЕ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ 14
3.1. Основные факторы пересмотра технологий анализа данных. 14
3.2. Характерные особенности задач нового типа в компьютерном анализе данных. 14
3.3. Схема эволюции систем анализа данных и систем поддержки принятия решений. 15
3.4. Направления интеллектуального анализа данных (DM) 16
4. КРАТКАЯ ХАРАКТЕРИСТИКА CASE - ТЕХНОЛОГИЙ.. 18
4.1. Два способа улучшения бизнес-процесса: непрерывное усовершенствование и реинжиниринг. 18
4.1.1. Что такое бизнес-процесс, зачем и как его усовершенствовать... 18
4.1.2. «Непрерывное совершенствование бизнес-процессов». 18
4.1.3. Реинжиниринг. 18
4.2. Понятие консалтинга в области информационных технологий. 19
4.3. CASE-технологии - методологическая и инструментальная база консалтинга. 20
4.4. BPwin - средство концептуального моделирования бизнес-процессов предприятия. 21
4.4.1. Общие сведения о работе в среде пакета BPwin. 21
4.4.2. BPwin как SADT технология. 22
4.4.3. Основные элементы и понятия методологии IDEF0. 22
4.5. Классификация структурных методологий. 25
5. ЗАКЛЮЧЕНИЕ.. 27
6. СПИСОК ЛИТЕРАТУРЫ... 28
ПРЕДИСЛОВИЕ
Всех специалистов, профессионально занимающихся обработкой статистических данных, условно можно разделить на три категории: 1) приверженцы классической математической статистики (объектами их исследований обычно являются некоторые разделы биологии или физики); 2) представители школы обработки экспериментальных данных в рамках идеологии исследования операций (предметом их разработок чаще всего бывают результаты активных экспериментов над сложной технической системой); 3) специалисты по прикладной статистике и анализу данных, ориентированные на исследование естественных и социальных систем в таких, например, областях, как геология, медицина, экономика и социология. Характер данных и методологическое видение проблемного материала во всех трёх случаях столь различны, что в действительности эти три течения статистических исследований следовало бы признать самостоятельными. В настоящем пособии авторы придерживаются тематики прикладной статистики и анализа данных, окончательно сформировавшейся к концу 80-х годов. Наиболее полно эта область прикладной математики изложена в трёхтомном справочном издании по прикладной статистике под редакцией С.А.Айвазяна [1, 2, 3]. В настоящее время это издание стало большой редкостью, а равноценная и более доступная литература так и не появилась. Поэтому форма подачи материала настоящего пособия соответствует упомянутому выше справочнику, при этом упор сделан на технологию исследования и идеи алгоритмов.
Компьютерные технологии в научных исследованиях непрерывно совершенствуются и пополняются новыми разработками в области прикладного программного обеспечения. В пособии приводится краткая характеристика особенностей интеллектуального анализа данных и современных CASE-средств - инструментария для системных аналитиков, разработчиков и программистов, а также методологий структурного анализа и проектирования программного обеспечения.






