ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ
ПОНЯТИЕ КОНСАЛТИНГА В ОБЛАСТИ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ.
ЦЕЛИ И ЭТАПЫ РАЗРАБОТКИ КОНСАЛТИНГОВЫХ ПРОЕКТОВ
CASE-ТЕХНОЛОГИИ - МЕТОДОЛОГИЧЕСКАЯ И ИНСТРУМЕНТАЛЬНАЯ БАЗА КОНСАЛТИНГА
ПОНЯТИЕ СТРУКТУРНОГО АНАЛИЗА
ЖИЗНЕННЫЙ ЦИКЛ ПРОГРАММНОГО ИЗДЕЛИЯ И ЕГО КРИТИЧНЫЕ ЭТАПЫ
ИДЕИ, ЛЕЖАЩИЕ В ОСНОВЕ СТРУКТУРНЫХ МЕТОДОВ
ПРИНЦИПЫ СТРУКТУРНОГО АНАЛИЗА
СРЕДСТВА СТРУКТУРНОГО АНАЛИЗА И ИХ ВЗАИМООТНОШЕНИЯ
ДИАГРАММЫ ПОТОКОВ ДАННЫХ
ОСНОВНЫЕ СИМВОЛЫ ДИАГРАММЫ
КОНТЕКСТНАЯ ДИАГРАММА И ДЕТАЛИЗАЦИЯ ПРОЦЕССОВ
ДЕКОМПОЗИЦИЯ ДАННЫХ И СООТВЕТСТВУЮЩИЕ РАСШИРЕНИЯ ДИАГРАММ ПОТОКОВ ДАННЫХ
ПОСТРОЕНИЕ МОДЕЛИ
СЛОВАРЬ ДАННЫХ
СОДЕРЖИМОЕ СЛОВАРЯ ДАННЫХ
БНФ - НОТАЦИЯ
МЕТОДЫ ЗАДАНИЯ СПЕЦИФИКАЦИЙ ПРОЦЕССОВ
СТРУКТУРИРОВАННЫЙ ЕСТЕСТВЕННЫЙ ЯЗЫК
ТАБЛИЦЫ РЕШЕНИЙ
ВИЗУАЛЬНЫЕ ЯЗЫКИ ПРОЕКТИРОВАНИЯ СПЕЦИФИКАЦИЙ
ДИАГРАММЫ "СУЩНОСТЬ-СВЯЗЬ"
СУЩНОСТИ, ОТНОШЕНИЯ И СВЯЗИ В НОТАЦИИ ЧЕНА
ДИАГРАММЫ АТРИБУТОВ
КАТЕГОРИЗАЦИЯ СУЩНОСТЕЙ
ПОСТРОЕНИЕ МОДЕЛИ
СПЕЦИФИКАЦИИ УПРАВЛЕНИЯ
СРЕДСТВА СТРУКТУРНОГО ПРОЕКТИРОВАНИЯ
СТРУКТУРНЫЕ КАРТЫ КОНСТАНТАЙНА
СТРУКТУРНЫЕ КАРТЫ ДЖЕКСОНА
ХАРАКТЕРИСТИКИ ХОРОШЕЙ МОДЕЛИ РЕАЛИЗАЦИИ
Сцепление
Связность
МЕТОДОЛОГИИ СТРУКТУРНОГО И СИСТЕМНОГО АНАЛИЗА И ПРОЕКТИРОВАНИЯ
МЕТОДОЛОГИИ СТРУКТУРНОГО АНАЛИЗА ЙОДАНА/ДЕ МАРКО И ГЕЙНА-САРСОНА
SADT - ТЕХНОЛОГИЯ СТРУКТУРНОГО АНАЛИЗА И ПРОЕКТИРОВАНИЯ
ИЕРАРХИЯ ДИАГРАММ
СИНТАКСИС ДИАГРАММ
РАЗВЕТВЛЕНИЕ ДУГ.
СЛИЯНИЕ ДУГ.
СИНТАКСИС МОДЕЛЕЙ И РАБОТА С НИМИ
СИНТАКСИС ДИАГРАММ
СОЗДАНИЕ ФУНКЦИОНАЛЬНЫХ МОДЕЛЕЙ И ДИАГРАММ
Типы опроса
Процесс опроса
ДОПОЛНЕНИЯ К ДИАГРАММАМ И МОДЕЛЯМ
ОЦЕНКА И ВЫБОР CASE-СРЕДСТВ
КРИТЕРИИ ОЦЕНКИ И ВЫБОРА
ХАРАКТЕРИСТИКИ CASE-СРЕДСТВ
SILVERRUN
VANTAGE TEAM BUILDER (WESTMOUNT I-CASE)
UNIFACE
DESIGNER/2000 + DEVELOPER/2000
ЛОКАЛЬНЫЕ СРЕДСТВА (ERWIN, BPWIN, S-DESIGNOR, CASE.АНАЛИТИК)
ОБЪЕКТНО-ОРИЕНТИРОВАННЫЕ CASE-СРЕДСТВА (RATIONAL ROSE)
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
ВВЕДЕНИЕ
Курс "Проектирование Информационных Систем" предназначен для ознакомления с такими понятиями, как: консалтинг в области информационных технологий, консалтинговые проекты, методы и средства структурного системного анализа и проектирования, методологии структурного системного анализа и проектирования, CASE-технологии. Вы познакомитесь с последовательностью действий, а также методологиями, методами и средствами, которые будут использоваться при выполнении этой последовательности действий при постановке такой задачи, как автоматизация предприятия.
В современных условиях динамично развивается рынок комплексных интегрированных систем автоматизации предприятий и учреждений самого различного профиля (финансовых, промышленных, офисных) и самых различных размеров с разнообразными схемами иерархии, начиная от малых предприятий с численностью в несколько десятков человек и заканчивая крупными корпорациями численностью в десятки тысяч сотрудников. Такие системы предназначены для решения задач как предприятия в целом (управление финансовыми ресурсами, управление запасами, планирование и производство, сбыт и снабжение и т.д.), так и уровня его производственных подразделений, цехов и участков.
Главная особенность индустрии систем автоматизации различных предприятий и учреждений, характеризующихся широкой номенклатурой входных данных с различными маршрутами обработки этих данных, состоит в концентрации сложности на начальных этапах анализа требований и проектирования спецификаций системы при относительно невысокой сложности и трудоемкости последующих этапов. Фактически здесь и происходит понимание того, что будет делать будущая система, и каким образом она будет работать, чтобы удовлетворить предъявленные к ней требования. А именно нечеткость и неполнота системных требований, нерешенные вопросы и ошибки, допущенные на этапах анализа и проектирования, порождают на последующих этапах трудные, часто неразрешимые проблемы и, в конечном счете, приводят к неуспеху всей работы в целом.
С другой стороны, не существует двух одинаковых организаций. А следовательно, простое тиражирование даже очень хорошей системы управления предприятием никогда не устроит заказчика полностью, поскольку не может учесть его специфики. Более того, в данном случае возникает проблема выбора именно той системы, которая наиболее подходит для конкретного предприятия. А эта проблема осложняется еще и тем, что ключевые слова, характеризующие различные информационные системы, практически одни и те же:
· Единая информационная среда предприятия;
· Режим реального времени;
· Независимость от законодательства;
· Интеграция с другими приложениями (в том числе с уже работающими на предприятии системами);
· Поэтапное внедрение и т.п.
Фактически проблема комплексной автоматизации стала актуальной для каждого предприятия. А чтобы заниматься комплексной автоматизацией, необходимы структурированные знания в этой области.
ДИАГРАММЫ ПОТОКОВ ДАННЫХ
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Диаграммы потоков данных известны очень давно. Приведу следующий пример использования DFD для реорганизации переполненного клерками офиса, относящийся к 20-м годам. Осуществлявший реорганизацию консультант обозначил кружком каждого клерка, а стрелкой - каждый документ, передаваемый между ними. Используя такую диаграмму, он предложил схему реорганизации, в соответствии с которой двое клерков, обменивающиеся множеством документов, были посажены рядом, а клерки с малым взаимодействием были посажены на большом расстоянии. Так родилась первая модель, представляющая собой потоковую диаграмму - предвестника DFD.
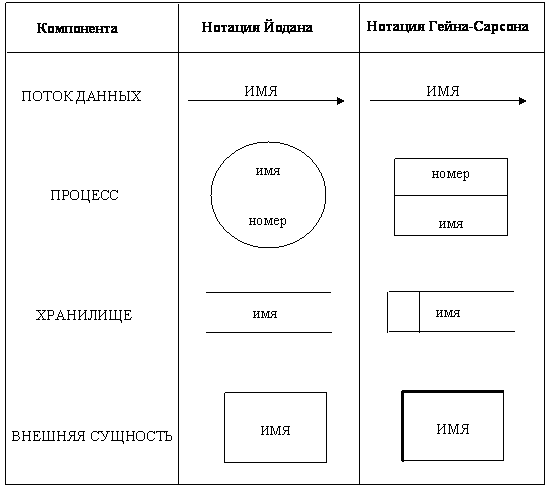
Для изображения DFD традиционно используются две различные нотации: Йодана (Yourdon) и Гейна-Сарсона (Gane-Sarson). Мы будем при построении примеров использовать нотации Йодана.
Основные символы диаграммы
Основные символы DFD изображены на рис.3.
Рис.3 Основные компоненты диаграммы потоков данных
Опишем их назначение. На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных.
ПОТОКИ ДАННЫХ являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним - двунаправленным.
Назначение ПРОЦЕССА состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, ВЫЧИСЛИТЬ МАКСИМАЛЬНУЮ ВЫСОТУ). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
ХРАНИЛИЩЕ (НАКОПИТЕЛЬ) ДАННЫХ позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет "срезы" потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
ВНЕШНЯЯ СУЩНОСТЬ (или ТЕРМИНАТОР) представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, СКЛАД ТОВАРОВ, Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке.
Построение модели
Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
1. Размещать на каждой диаграмме от 3 до 6-7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса.
2. Не загромождать диаграммы несущественными на данном уровне деталями.
3. Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов; эти две работы должны выполняться одновременно, а не одна после завершения другой.
4. Выбирать ясные, отражающие суть дела, имена процессов и потоков для улучшения понимаемости диаграмм, при этом стараться не использовать аббревиатуры.
5. Однократно определять функционально идентичные процессы на самом верхнем уровне, где такой процесс необходим, и ссылаться к нему на нижних уровнях.
6. Пользоваться простейшими диаграммными техниками: если что-либо возможно описать с помощью DFD, то это и необходимо делать, а не использовать для описания более сложные объекты.
7. Отделять управляющие структуры от обрабатывающих структур (т.е. процессов), локализовать управляющие структуры.
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы:
1) Расчленение множества требований и организация их в основные функциональные группы.
2) Идентификация внешних объектов, с которыми система должна быть связана.
3) Идентификация основных видов информации, циркулирующей между системой и внешними объектами.
4) Предварительная разработка контекстной диаграммы, на которой основные функциональные группы представляются процессами, внешние объекты - внешними сущностями, основные виды информации - потоками данных между процессами и внешними сущностями.
5) Изучение предварительной контекстной диаграммы и внесение в нее изменений по результатам ответов на возникающие при этом изучении вопросы по всем ее частям.
6) Построение контекстной диаграммы путем объединения всех процессов предварительной диаграммы в один процесс, а также группирования потоков.
7) Формирование DFD первого уровня на базе процессов предварительной контекстной диаграммы.
8) Проверка основных требований по DFD первого уровня.
9) Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или спецификации процесса.
10) Проверка основных требований по DFD соответствующего уровня.
11) Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
12) Параллельное (с процессом декомпозиции) изучение требований (в том числе и вновь поступающих), разбиение их на элементарные и идентификация процессов или спецификаций процессов, соответствующих этим требованиям.
13) После построения двух-трех уровней проведение ревизии с целью проверки корректности и улучшения понимаемости модели.
14) Построение спецификации процесса (а не простейшей диаграммы) в случае, если некоторую функцию сложно или невозможно выразить комбинацией процессов.
СЛОВАРЬ ДАННЫХ
Диаграммы потоков данных обеспечивают удобное описание функционирования компонент системы, но не снабжают аналитика средствами описания деталей этих компонент, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных задач предназначены текстовые средства моделирования, служащие для описания структуры преобразуемой информации и получившие название словарей данных.
Словарь данных представляет собой определенным образом организованный список всех элементов данных системы с их точными определениями, что дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ. Определения элементов данных в словаре осуществляются следующими видами описаний:
· описанием значений потоков и хранилищ, изображенных на DFD;
· описанием композиции агрегатов данных, движущихся вдоль потоков, т.е. комплексных данных, которые могут расчленяться на элементарные символы (например, АДРЕС ПОКУПАТЕЛЯ содержит ПОЧТОВЫЙ ИНДЕКС, ГОРОД, УЛИЦУ и т.д.);
· описанием композиции групповых данных в хранилище;
· специфицированием значений и областей действия элементарных фрагментов информации в потоках данных и хранилищах;
· описанием деталей отношений между хранилищами.
Содержимое словаря данных
Для каждого потока данных в словаре необходимо хранить имя потока, его тип и атрибуты. Информация по каждому потоку состоит из ряда словарных статей, каждая из которых начинается с ключевого слова - заголовка соответствующей статьи, которому предшествует символ "@".
По типу потока в словаре содержится информация, идентифицирующая:
· простые (элементарные) или групповые (комплексные) потоки;
· внутренние (существующие только внутри системы) или внешние (связывающие систему с другими системами) потоки;
· потоки данных или потоки управления;
· непрерывные (принимающие любые значения в пределах определенного диапазона) или дискретные (принимающие определенные значения) потоки.
Атрибуты потока данных включают:
· имена-синонимы потока данных в соответствии с узлами изменения имени;
· БНФ-определение в случае группового потока;
· единицы измерения потока;
· диапазон значений для непрерывного потока, типичное его значение и информацию по обработке экстремальных значений;
· список значений и их смысл для дискретного потока;
· список номеров диаграмм различных типов, в которых поток встречается;
· список потоков, в которые данный поток входит (как элемент БНФ-определения);
· комментарий, включающий дополнительную информацию (например, о цели введения данного потока).
БНФ-нотация
БНФ-нотация позволяет формально описать расщепление/объединение потоков. Поток может расщепляться на собственные отдельные ветви, на компоненты потока-предка или на то и другое одновременно. При расщеплении/объединении потока существенно чтобы каждый компонент потока-предка являлся именованным.
Если поток расщепляется на подпотоки, необходимо, чтобы все подпотоки являлись компонентами потока-предка. И, наоборот, при объединении потоков каждый компонент потока-предка должен по крайней мере однажды встречаться среди подпотоков. Отметим, что при объединении подпотоков нет необходимости осуществлять включение общих компонент, а при расщеплении подпотоки могут иметь такие общие (одинаковые) компоненты.
Важно понимать, что точные определения потоков содержатся в словаре данных, а не на диаграммах. Например, на диаграмме может иметься групповой узел с входным потоком X и выходными подпотоками Y и Z. Однако это вовсе не означает, что соответствующее определение в словаре данных обязательно должно быть X=Y+Z. Это определение может быть следующим:
Х=А+В+С; Y=A+B; Z=B+C
Такие определения хранятся в словаре данных в так называемой БНФ-статье. БНФ-статья используется для описания компонент данных в потоках данных и в хранилищах. Ее синтаксис имеет вид:
@БНФ = <простой оператор>! <БНФ-выражение>,
где <простой оператор> есть текстовое описание, заключенное в '", а <БНФ-выражение> есть выражение в форме Бэкуса-Наура, допускающее следующие операции отношений:
= - означает "композиция из",
+ - означает "И",
[!] - означает "ИЛИ",
() - означает, что компонент в скобках не обязателен,
{ } - означает итерацию компонента в скобках,
" " - означает литерал.
Итерационные скобки могут иметь нижний и верхний предел, например:
3{болт} 7 - от 3 до 7 итераций
1 {болт} - 1 и более итераций
{шайба}3 - не более 3 итераций
БНФ-выражение может содержать произвольные комбинации операций:
@БНФ = [ винт! болт + 2 {гайка}2 + (прокладка)! клей ]
Ниже приведен пример описания потока данных с помощью БНФ:
@ = ВОСЬМЕРИЧНАЯ ЦИФРА
@ТИП=дискретный поток
@БНФ=["0"!"1"!"2"!"3"!"4"!"5"!"6"!"7"]
Рассмотрим элементы словаря данных для примера, в котором описан процесс "Сдача экзамена".
Рассмотрим информационный поток "Приглашение тянуть билет":
@ИМЯ = ПРИГЛАШЕНИЕ ТЯНУТЬ БИЛЕТ
@ТИП = управляющий поток
@БНФ = /указывает, что студент допущен к экзамену/
Рассмотрим еще один поток "Сформированное мнение о знаниях студента"
@ИМЯ = СФОРМИРОВАННОЕ МНЕНИЕ О ЗНАНИЯХ СТУДЕНТА
@ТИП = внутренний поток
@БНФ = /на основании этого потока формируется оценка студента/
МЕТОДЫ ЗАДАНИЯ СПЕЦИФИКАЦИЙ ПРОЦЕССОВ
Спецификация процесса (СП) используется для описания функционирования процесса в случае отсутствия необходимости детализировать его с помощью DFD (т.е. если он достаточно невелик, и его описание может занимать до одной страницы текста). Фактически СП представляют собой алгоритмы описания задач, выполняемых процессами: множество всех СП является полной спецификацией системы. СП содержат номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое число разнообразных методов, позволяющих задать тело процесса, соответствующий язык может варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования (типа FLOW-форм и диаграмм Насси-Шнейдермана) и формальных компьютерных языков.
Независимо от используемой нотации спецификация процесса должна начинаться с ключевого слова (например, @СПЕЦПРОЦ). Требуемые входные и выходные данные должны быть специфицированы следующим образом:
@ВХОД = <имя символа данных>
@ВЫХОД = <имя символа данных>
@ВХОДВЫХОД = <имя символа данных>,
где <имя символа данных> - соответствующее имя из словаря Данных.
Эти ключевые слова должны использоваться перед определением СП, например,
@ВХОД = СЛОВА ПАМЯТИ
@ВЫХОД = ХРАНИМЫЕ ЗНАЧЕНИЯ
@СПЕЦПРОЦ
Для всех СЛОВ ПАМЯТИ выполнить:
ИНАЧЕ
ВЫПОЛНИТЬ функция2
КОНЕЦЕСЛИ
3)итерация:
ДЛЯ <условие>
ВЫПОЛНИТЬ функция
КОНЕЦДЛЯ
или
ПОКА <условие>
ВЫПОЛНИТЬ функция
КОНЕЦПОКА
При использовании структурированного естественного языка приняты следующие соглашения:
1) Логика процесса выражается в виде комбинации последовательных конструкций, конструкций выбора и итераций.
2) Ключевые слова ЕСЛИ, ВЫПОЛНИТЬ, ИНАЧЕ и т.д. должны быть написаны заглавными буквами.
3) Слова или фразы, определенные в словаре данных, должны быть написаны заглавными буквами.
4) Глаголы должны быть активными, недвусмысленными и ориентированными на целевое действие (заполнить, вычислить, извлечь, а не модернизировать, обработать).
5) Логика процесса должна быть выражена четко недвусмысленно.
Таблицы решений
Структурированный естественный язык неприемлем да некоторых типов преобразований. Например, если действие зависит от нескольких переменных, которые в совокупности могут продуцировать большое число комбинаций, то его описание будет слишком запутанным и с большим числом уровней вложенности. Для описания подобных действий традиционно используются таблицы и деревья решений.
Проектирование спецификаций процессов с помощью таблиц решений (ТР) заключается в задании матрицы, отображающей множество входных условий во множество действий.
Таблица Решений состоит из двух частей. Верхняя часть таблицы используется для определения условий. Обычно условие является ЕСЛИ-частью оператора ЕСЛИ-ТО и требует ответа "да-нет". Однако иногда в условии может присутствовать и ограниченное множество значений, например, ЯВЛЯЕТСЯ ЛИ ДЛИНА СТРОКИ БОЛЬШЕЙ, МЕНЬШЕЙ ИЛИ РАВНОЙ ГРАНИЧНОМУ ЗНАЧЕНИЮ?
Нижняя часть Таблицы Решений используется для определения действий, т.е. ТО-части оператора ЕСЛИ-ТО. Так, в конструкции ЕСЛИ ИДЕТ ДОЖДЬ, ТО РАСКРЫТЬ ЗОНТ. ИДЕТ ДОЖДЬ является условием, а РАСКРЫТЬ ЗОНТ - действием.
Левая часть Таблицы Решений содержит собственно описание условий и действий, а в правой части перечисляются все возможные комбинации условий и, соответственно, указывается, какие конкретно действия и в какой последовательности выполняются, когда определенная комбинация условий имеет место.
Поясним вышесказанное на примере спецификации процесса выбора верхней одежды из корзины с вещами. При выборе верхней одежды необходимо руководствоваться следующими правилами:
1) если очередная вещь является верхней одеждой, то взять и положить в свою сумку;
2) если своя сумка полная, то закончить поиск верхней одежды;
3) если корзина с вещами пуста, то закончить поиск;
4) иначе поместить вещь в контейнер для просмотренных вещей.
Таблица решений для данного примера выглядит следующим образом (таблица 1):
Таблица 1
|
| УСЛОВИЯ
|
|
|
|
|
|
|
|
|
| C1
| id_wear(c)
| Д
| Н
| Д
| Н
| Д
| Н
| Д
| Н
|
| C2
| Full_bag()
| Н
| Д
| Д
| Д
| Н
| Н
| Д
| Н
|
| C3
| Clear_kor()
| Н
| Д
| Н
| Н
| Д
| Д
| Д
| Н
|
|
| ДЕЙСТВИЯ
|
|
|
|
|
|
|
|
|
| D1
| Put_bag(c)
|
|
|
|
|
|
|
|
|
| D2
| End_search()
|
|
|
|
|
|
|
|
|
| D3
| Put_kont(c)
|
|
|
|
|
|
|
|
|
Заметим, что если выполняется условие C2, то нет необходимости в проверке условий C1 и С3. Поэтому комбинации 2,3,4 и 7 могут быть заменены обобщающей комбинацией (-,Д,-), где "-" означает любую из возможных альтернатив (в нашем случае, Д или Н). Тогда мы получим редуцированную таблицу решений:
Таблица 2
|
| УСЛОВИЯ
|
|
|
|
|
|
| C1
| id_wear(c)
| Д
| -
| Д
| Н
| Н
|
| C2
| Full_bag()
| Н
| Д
| Н
| Н
| Н
|
| C3
| Clear_kor()
| Н
| -
| Д
| Д
| Н
|
|
| ДЕЙСТВИЯ
|
|
|
|
|
|
| D1
| Put_bag(c)
|
|
|
|
|
|
| D2
| End_search()
|
|
|
|
|
|
| D3
| Put_kont(c)
|
|
|
|
|
|
Построение Таблицы Решений рекомендуется осуществлять по следующим шагам:
1. Идентифицировать все условия (или переменные) в спецификации. Идентифицировать все значения, которые каждая переменная может иметь.
2. Вычислить число комбинаций условий. Если все условия являются бинарными, то существует 2**N комбинаций N переменных.
3. Идентифицировать каждое из возможных действий, которые могут вызываться в спецификации.
4. Построить пустую таблицу, включающую все возможные условия и действия, а также номера комбинаций условий.
5. Выписать и занести в таблицу все возможные комбинации условий.
6. Редуцировать комбинации условий.
7. Проверить каждую комбинацию условий и идентифицировать соответствующие выполняемые действия.
8. Выделить комбинации условий, для которых спецификация не указывает список выполняемых действий.
9. Обсудить построенную таблицу.
Диаграммы атрибутов
Каждая сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности. При этом любой атрибут может быть определен как ключевой.
Детализация сущности осуществляется с использованием диаграмм атрибутов, которые раскрывают ассоциированные сущностью атрибуты. Диаграмма атрибутов состоит из детализируемой сущности, соответствующих атрибутов и доменов, описывающих области значений атрибутов. На диаграмме каждый атрибут представляется в виде связи между сущностью и соответствующим доменом, являющимся графическим представлением множества возможных значений атрибута. Все атрибутные связи имеют значения на своем окончании. Для идентификации ключевого атрибута используется подчеркивание имени атрибута.
Категоризация сущностей
Сущность может быть разделена и представлена в виде двух или более сущностей-категорий, каждая из которых имеет общие атрибуты и/или отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем. Сущности-категории могут иметь и свои собственные атрибуты и/или отношения, а также, в свою очередь, могут быть декомпозированы своими сущностями-категориями на следующем уровне. Расщепляемая на категории сущность получила название общей сущности (отметим, что на промежуточных уровнях декомпозиции одна и та же сущность может быть как общей сущностью, так и сущностью-категорией).
Для демонстрации декомпозиции сущности на категории используются диаграммы категоризации. Такая диаграмма содержит общую сущность, две и более сущности-категории и специальный узел-дискриминатор, который описывает способы декомпозиции сущностей (см. рис. 10).
Рис. 10 Узел-дискриминатор
Существуют 4 возможных типа дискриминатора:
1) Полное и обязательное вхождение Е/М (exclusive/mandatory) - сущность должна быть одной и только одной из следуемых категорий.
2) Полное и необязательное вхождение Е/О (exclusive/optional) - сущность может быть одной и только одной из следуемых категорий.
3) Неполное и обязательное вхождение I/M (inclusive/mandatory) - сущность должна быть, по крайней мере, одной из следуемых категорий.
4) Неполное и необязательное вхождение I/O (inclusive/optional) - сущность может быть, по крайней мере, одной из следуемых категорий.
Построение модели
Разработка ERD включает следующие этапы:
1) Идентификация сущностей, их атрибутов, а также первичных и альтернативных ключей.
2) Идентификация отношений между сущностями и указаний типов отношений.
3) Разрешение неспецифических отношений (отношений n*m).
Этап 1 является определяющим при построении модели, его исходной информацией служит содержимое хранилищ данных определяемое входящими и выходящими в/из него потоками данных. Первоначально осуществляется анализ хранилища, включающий сравнение содержимого входных и выходных потоков и создание на основе этого сравнения варианта схемы хранилища, описание структур данных, содержащихся во входных и выходных потоках.
Затем, если полученная схема обладает избыточностью, то происходит упрощение схемы путем нормализации (удаления повторяющихся групп). Концепции и методы нормализации были разработаны Коддом, установившим существование трех типов нормализованных схем, называемых в порядке уменьшения сложности первой, второй и третьей нормальной формой (1НФ, 2НФ, 3НФ).
Пример НФ. Рассмотрим все три нормальные формы на примере Группы Студентов. У Студента ключом является реквизит Номер (№ личного дела), к описательным реквизитам относятся: Фамилия (Фамилия студента), Имя (Имя студента), Отчество (Отчество студента), Дата (Дата рождения), Группа (N группы). Если отсутствует реквизит Номер, то для однозначного определения характеристик конкретного студента необходимо использование составного ключа из трех реквизитов: Фамилия + Имя + Отчество.
Первая нормальная форма
Отношение называется нормализованным или приведенным к первой нормальной форме, если все его атрибуты простые (далее неделимы). Преобразование отношения к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа.
Например, отношение Студент=(Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой нормальной форме.
Вторая нормальная форма
Чтобы рассмотреть вопрос приведения отношений ко второй нормальной форме, необходимо дать пояснения к таким понятиям, как функциональная зависимость и полная функциональная зависимость.
Описательные реквизиты информационного объекта логически связаны с общим для них ключом, эта связь носит характер функциональной зависимости реквизитов.
Функциональная зависимость реквизитов - зависимость, при которой в экземпляре сущности (в нашем случае, сущность - это студент) определенному значению ключевого реквизита соответствует только одно значение описательного реквизита.
Такое определение функциональной зависимости позволяет при анализе всех взаимосвязей реквизитов предметной области выделить самостоятельные информационные объекты.
В случае составного ключа вводится понятие функционально полной зависимости.
Функционально полная зависимость неключевых атрибутов заключается в том, что каждый неключевой атрибут функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа.
Отношение будет находиться во второй нормальной форме, если оно находится в первой нормальной форме, и каждый неключевой атрибут функционально полно зависит от составного ключа.
Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой и во второй нормальной форме одновременно, так как описательные реквизиты однозначно определены и функционально зависят от ключа Номер. Отношение Успеваемость = (Номер, Фамилия, Имя, Отчество, Дисциплина, оценка) находится в первой нормальной форме и имеет составной ключ Номер+Дисциплина. Это отношение не находится во второй нормальной форме, так как атрибуты Фамилия, Имя, Отчество не находятся в полной функциональной зависимости с составным ключом отношения.
Третья нормальная форма
Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости.
Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита.
Отношение будет находиться в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Пример. Если в состав описательных реквизитов Студент включить фамилию старосты группы (Староста), которая определяется только номером группы, то одна и та же фамилия старосты будет многократна повторяться в разных экземплярах Студентов. В этом случае наблюдаются затруднения в корректировке фамилии старосты в случае назначения нового старосты, а также неоправданный расход памяти для хранения дублированной информации.
Для устранения транзитивной зависимости описательных реквизитов необходимо провести "расщепление" исходной сущности. В результате расщепления часть реквизитов удаляется из исходной сущности и включается в состав другой (возможно, вновь созданных) сущности.
Пример. Студент группы представляется в виде совокупности правильно структурированных информационных объектов (Студент и Группа), реквизитный состав которых тождественен исходному объекту. Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится одновременно в первой, второй и третьей нормальной форме.
3НФ является наиболее простым способом представления данных, отражающим здравый смысл. Построив 3НФ, мы фактически выделяем базовые сущности предметной области.
Этап 2 служит для выявления и определения отношений между сущностями, а также для идентификации типов отношений. Некоторые отношения на данном этапе могут быть неспецифическими (n*m многие-ко-многим). Такие отношения потребуют дальнейшей детализации на этапе 3.
Определение отношений включает выявление связей, для этого отношение должно быть проверено в обоих направлениях следующим образом: выбирается экземпляр одной из сущностей и определяется, сколько различных экземпляров второй сущности может быть связано с ним и наоборот.
Пример. Связь "1-к-1". Человек и его паспорт. Связь "1-ко-многим": Человек и телефоны.
Этап 3 предназначен для разрешения неспецифических отношений. Для этого каждое неспецифическое отношение преобразуется в два специфических отношения с введением новых (а именно, ассоциативных) сущностей. Пример. Студент может изучать много Предметов, а Предмет может изучаться многими Студентами. Мы не можем определить, какой Студент изучает какой Предмет. Следовательно, у нас есть неспецифическое отношение, которое можно расщепить на два специфических отношения, введя ассоциативную сущность Изучение_Предмета. Каждый экземпляр введенной сущности связан с одним Студентом и одним Предметом (рис.11).
Рис. 11 Пример разрешения неспецифического отношения
Спецификации управления
Спецификации управления предназначены для моделирования и документирования аспектов систем, зависящих от времени или реакции на событие. Они позволяют осуществлять декомпозицию управляющих процессов и описывают отношения между входными и выходными управляющими потоками на управляющем процессе-предке. Для этой цели обычно используются диаграммы переходов состояний (STD).
С помощью STD можно моделировать последующее функционирование системы на основе ее предыдущего и текущего функционирования. Моделируемая система в любой заданный момент времени находится точно в одном из конечного множества состояний. С течением времени она может изменить свое состояние, при этом переходы между состояниями должны быть точно определены.
STD состоит из следующих объектов:
СОСТОЯНИЕ - может рассматриваться как условие