Индивидуальные данные в системе часто являются независимыми. Однако иногда необходимо иметь дело с несколькими независимыми данными одновременно. Например, в системе имеются потоки ЯБЛОКИ, АПЕЛЬСИНЫ и ГРУШИ. Эти потоки могут быть сгруппированы с помощью введения нового потока ФРУКТЫ. Для этого необходимо определить формально поток ФРУКТЫ как состоящий из нескольких элементов-потомков. Такое определение задается с помощью формы Бэкуса-Наура (БНФ) в словаре данных (эту форму мы рассмотрим на след. лекции). В свою очередь поток ФРУКТЫ сам может содержаться в потоке-предке ЕДА вместе с потоками ОВОЩИ, МЯСО и др. Такие потоки, объединяющие несколько потоков, получили название групповых.
Обратная операция, расщепление потоков на подпотоки, осуществляется с использованием группового узла, позволяющего расщепить поток на любое число подпотоков. Возможный способ изображения узлов приведен на рис. 6.
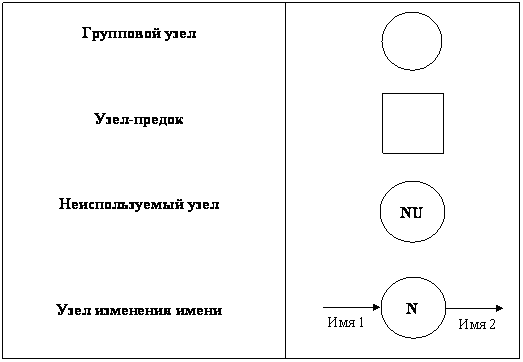
Рис. 6 Элементы, используемые при расщеплении
При расщеплении также необходимо формально определить подпотоки в словаре данных (с помощью БНФ).
Аналогичным образом осуществляется и декомпозиция потоков через границы диаграмм, позволяющая упростить детализирующую DFD. Пусть имеется поток ФРУКТЫ, входящий в детализируемый процесс. На детализирующей этот процесс диаграмме потока ФРУКТЫ может не быть вовсе, но вместо него могут быть потоки ЯБЛОКИ и АПЕЛЬСИНЫ (как будто бы они переданы из детализируемого процесса). В этом случае должно существовать БНФ-определение потока ФРУКТЫ, состоящего из подпотоков ЯБЛОКИ и АПЕЛЬСИНЫ, для целей балансирования.
Применение этих операций над данными позволяет обеспечить структуризацию данных, увеличивает наглядность и читабельность диаграмм.
Для обеспечения декомпозиции данных и некоторых других сервисных возможностей к DFD добавляются следующие типы объектов:
1) ГРУППОВОЙ УЗЕЛ. Предназначен для расщепления и объединения потоков. В некоторых случаях может отсутствовать (т.е. фактически вырождаться в точку слияния/расщепления потоков на диаграмме).
2) УЗЕЛ-ПРЕДОК. Позволяет увязывать входящие и выходящие потоки между детализируемым процессом и детализирующей DFD.
3) НЕИСПОЛЬЗУЕМЫЙ УЗЕЛ. Применяется в ситуации, когда декомпозиция данных производится в групповом узле, при этом требуются не все элементы входящего в узел потока.
4) УЗЕЛ ИЗМЕНЕНИЯ ИМЕНИ. Позволяет неоднозначно именовать потоки, при этом их содержимое эквивалентно. Например, если при проектировании разных частей системы один и тот же фрагмент данных получил различные имена, то эквивалентность соответствующих потоков данных обеспечивается узлом изменения имени. При этом один из потоков данных является входным для данного узла, а другой - выходным.
5) Текст в свободном формате в любом месте диаграммы.
Построение модели
Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
1. Размещать на каждой диаграмме от 3 до 6-7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса.
2. Не загромождать диаграммы несущественными на данном уровне деталями.
3. Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов; эти две работы должны выполняться одновременно, а не одна после завершения другой.
4. Выбирать ясные, отражающие суть дела, имена процессов и потоков для улучшения понимаемости диаграмм, при этом стараться не использовать аббревиатуры.
5. Однократно определять функционально идентичные процессы на самом верхнем уровне, где такой процесс необходим, и ссылаться к нему на нижних уровнях.
6. Пользоваться простейшими диаграммными техниками: если что-либо возможно описать с помощью DFD, то это и необходимо делать, а не использовать для описания более сложные объекты.
7. Отделять управляющие структуры от обрабатывающих структур (т.е. процессов), локализовать управляющие структуры.
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы:
1) Расчленение множества требований и организация их в основные функциональные группы.
2) Идентификация внешних объектов, с которыми система должна быть связана.
3) Идентификация основных видов информации, циркулирующей между системой и внешними объектами.
4) Предварительная разработка контекстной диаграммы, на которой основные функциональные группы представляются процессами, внешние объекты - внешними сущностями, основные виды информации - потоками данных между процессами и внешними сущностями.
5) Изучение предварительной контекстной диаграммы и внесение в нее изменений по результатам ответов на возникающие при этом изучении вопросы по всем ее частям.
6) Построение контекстной диаграммы путем объединения всех процессов предварительной диаграммы в один процесс, а также группирования потоков.
7) Формирование DFD первого уровня на базе процессов предварительной контекстной диаграммы.
8) Проверка основных требований по DFD первого уровня.
9) Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или спецификации процесса.
10) Проверка основных требований по DFD соответствующего уровня.
11) Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
12) Параллельное (с процессом декомпозиции) изучение требований (в том числе и вновь поступающих), разбиение их на элементарные и идентификация процессов или спецификаций процессов, соответствующих этим требованиям.
13) После построения двух-трех уровней проведение ревизии с целью проверки корректности и улучшения понимаемости модели.
14) Построение спецификации процесса (а не простейшей диаграммы) в случае, если некоторую функцию сложно или невозможно выразить комбинацией процессов.
СЛОВАРЬ ДАННЫХ
Диаграммы потоков данных обеспечивают удобное описание функционирования компонент системы, но не снабжают аналитика средствами описания деталей этих компонент, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных задач предназначены текстовые средства моделирования, служащие для описания структуры преобразуемой информации и получившие название словарей данных.
Словарь данных представляет собой определенным образом организованный список всех элементов данных системы с их точными определениями, что дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ. Определения элементов данных в словаре осуществляются следующими видами описаний:
· описанием значений потоков и хранилищ, изображенных на DFD;
· описанием композиции агрегатов данных, движущихся вдоль потоков, т.е. комплексных данных, которые могут расчленяться на элементарные символы (например, АДРЕС ПОКУПАТЕЛЯ содержит ПОЧТОВЫЙ ИНДЕКС, ГОРОД, УЛИЦУ и т.д.);
· описанием композиции групповых данных в хранилище;
· специфицированием значений и областей действия элементарных фрагментов информации в потоках данных и хранилищах;
· описанием деталей отношений между хранилищами.
Содержимое словаря данных
Для каждого потока данных в словаре необходимо хранить имя потока, его тип и атрибуты. Информация по каждому потоку состоит из ряда словарных статей, каждая из которых начинается с ключевого слова - заголовка соответствующей статьи, которому предшествует символ "@".
По типу потока в словаре содержится информация, идентифицирующая:
· простые (элементарные) или групповые (комплексные) потоки;
· внутренние (существующие только внутри системы) или внешние (связывающие систему с другими системами) потоки;
· потоки данных или потоки управления;
· непрерывные (принимающие любые значения в пределах определенного диапазона) или дискретные (принимающие определенные значения) потоки.
Атрибуты потока данных включают:
· имена-синонимы потока данных в соответствии с узлами изменения имени;
· БНФ-определение в случае группового потока;
· единицы измерения потока;
· диапазон значений для непрерывного потока, типичное его значение и информацию по обработке экстремальных значений;
· список значений и их смысл для дискретного потока;
· список номеров диаграмм различных типов, в которых поток встречается;
· список потоков, в которые данный поток входит (как элемент БНФ-определения);
· комментарий, включающий дополнительную информацию (например, о цели введения данного потока).
БНФ-нотация
БНФ-нотация позволяет формально описать расщепление/объединение потоков. Поток может расщепляться на собственные отдельные ветви, на компоненты потока-предка или на то и другое одновременно. При расщеплении/объединении потока существенно чтобы каждый компонент потока-предка являлся именованным.
Если поток расщепляется на подпотоки, необходимо, чтобы все подпотоки являлись компонентами потока-предка. И, наоборот, при объединении потоков каждый компонент потока-предка должен по крайней мере однажды встречаться среди подпотоков. Отметим, что при объединении подпотоков нет необходимости осуществлять включение общих компонент, а при расщеплении подпотоки могут иметь такие общие (одинаковые) компоненты.
Важно понимать, что точные определения потоков содержатся в словаре данных, а не на диаграммах. Например, на диаграмме может иметься групповой узел с входным потоком X и выходными подпотоками Y и Z. Однако это вовсе не означает, что соответствующее определение в словаре данных обязательно должно быть X=Y+Z. Это определение может быть следующим:
Х=А+В+С; Y=A+B; Z=B+C
Такие определения хранятся в словаре данных в так называемой БНФ-статье. БНФ-статья используется для описания компонент данных в потоках данных и в хранилищах. Ее синтаксис имеет вид:
@БНФ = <простой оператор>! <БНФ-выражение>,
где <простой оператор> есть текстовое описание, заключенное в '", а <БНФ-выражение> есть выражение в форме Бэкуса-Наура, допускающее следующие операции отношений:
= - означает "композиция из",
+ - означает "И",
[!] - означает "ИЛИ",
() - означает, что компонент в скобках не обязателен,
{ } - означает итерацию компонента в скобках,
" " - означает литерал.
Итерационные скобки могут иметь нижний и верхний предел, например:
3{болт} 7 - от 3 до 7 итераций
1 {болт} - 1 и более итераций
{шайба}3 - не более 3 итераций
БНФ-выражение может содержать произвольные комбинации операций:
@БНФ = [ винт! болт + 2 {гайка}2 + (прокладка)! клей ]
Ниже приведен пример описания потока данных с помощью БНФ:
@ = ВОСЬМЕРИЧНАЯ ЦИФРА
@ТИП=дискретный поток
@БНФ=["0"!"1"!"2"!"3"!"4"!"5"!"6"!"7"]
Рассмотрим элементы словаря данных для примера, в котором описан процесс "Сдача экзамена".
Рассмотрим информационный поток "Приглашение тянуть билет":
@ИМЯ = ПРИГЛАШЕНИЕ ТЯНУТЬ БИЛЕТ
@ТИП = управляющий поток
@БНФ = /указывает, что студент допущен к экзамену/
Рассмотрим еще один поток "Сформированное мнение о знаниях студента"
@ИМЯ = СФОРМИРОВАННОЕ МНЕНИЕ О ЗНАНИЯХ СТУДЕНТА
@ТИП = внутренний поток
@БНФ = /на основании этого потока формируется оценка студента/
МЕТОДЫ ЗАДАНИЯ СПЕЦИФИКАЦИЙ ПРОЦЕССОВ
Спецификация процесса (СП) используется для описания функционирования процесса в случае отсутствия необходимости детализировать его с помощью DFD (т.е. если он достаточно невелик, и его описание может занимать до одной страницы текста). Фактически СП представляют собой алгоритмы описания задач, выполняемых процессами: множество всех СП является полной спецификацией системы. СП содержат номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое число разнообразных методов, позволяющих задать тело процесса, соответствующий язык может варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования (типа FLOW-форм и диаграмм Насси-Шнейдермана) и формальных компьютерных языков.
Независимо от используемой нотации спецификация процесса должна начинаться с ключевого слова (например, @СПЕЦПРОЦ). Требуемые входные и выходные данные должны быть специфицированы следующим образом:
@ВХОД = <имя символа данных>
@ВЫХОД = <имя символа данных>
@ВХОДВЫХОД = <имя символа данных>,
где <имя символа данных> - соответствующее имя из словаря Данных.
Эти ключевые слова должны использоваться перед определением СП, например,
@ВХОД = СЛОВА ПАМЯТИ
@ВЫХОД = ХРАНИМЫЕ ЗНАЧЕНИЯ
@СПЕЦПРОЦ
Для всех СЛОВ ПАМЯТИ выполнить: