

Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Топ:
Марксистская теория происхождения государства: По мнению Маркса и Энгельса, в основе развития общества, происходящих в нем изменений лежит...
Устройство и оснащение процедурного кабинета: Решающая роль в обеспечении правильного лечения пациентов отводится процедурной медсестре...
Эволюция кровеносной системы позвоночных животных: Биологическая эволюция – необратимый процесс исторического развития живой природы...
Интересное:
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Национальное богатство страны и его составляющие: для оценки элементов национального богатства используются...
Инженерная защита территорий, зданий и сооружений от опасных геологических процессов: Изучение оползневых явлений, оценка устойчивости склонов и проектирование противооползневых сооружений — актуальнейшие задачи, стоящие перед отечественными...
Дисциплины:
|
из
5.00
|
Заказать работу |
Содержание книги
Поиск на нашем сайте
|
|
|
|
Механизмы синхронизации: семафор, мьютекс, монитор, критическая секция
Семафоры
В 1965 году Дейкстра (E.W. Dijkstra) предложил использовать целую переменную для подсчета
сигналов запуска, сохраненных на будущее. Им был предложен новый тип переменных, так
называемые семафоры, значение которых может быть или некоторым положительным числом, соответствующим количеству отложенных активизирующих сигналов.
Семафор может управлять количеством процессов, которые имеют к нему доступ. Он
устанавливается на предельное количество процессов, которым доступ разрешен. Когда это число
достигнуто, последующие процессы будут приостановлены, пока один или более процессов не отсоединятся от семафора и не освободят доступ.
Мьютексы
Иногда используется упрощенная версия семафора, называемая мьютексом (mutex, сокращение
от mutual exclusion – взаимное исключение). Мьютекс не способен считать, он может лишь
управлять взаимным исключением доступа к совместно используемым ресурсам или кодам.
Реализация мьютекса проста и эффективна, что делает использование мьютексов особенно
полезным в случае потоков, действующих только в пространстве пользователя.
Мьютекс – переменная, которая может находиться в одном из двух состояний: блокированном
или неблокированном. Поэтому для описания мьютекса требуется всего один бит, хотя чаще
используется целая переменная, у которой 0 означает неблокированное состояние, а все
остальные значения соответствуют блокированному состоянию. Значение мьютекса
устанавливается двумя процедурами. Если поток (или процесс) собирается войти в критическую
область, он вызывает процедуру mutex_lock.
Критические секции (critical section) подобны мьютексам, однако между ними существуют два
важных отличия:
мьютексы могут быть совместно использованы в различных процессах;
если критическая секция принадлежит другому процессу, ожидающий процесс
блокируется вплоть до освобождения критической секции; в отличие от этого, мьютекс
разрешает продолжение по истечении тайм-аута.
Критические секции и мьютексы очень схожи. На первый взгляд, выигрыш от использования
критической секции вместо мьютекса не очевиден. Критические секции, однако, более
эффективны, чем мьютексы, так как используют меньше системных ресурсов. Мьютексы могут
быть установлены на определенный интервал времени, по истечении которого выполнение
продолжается; критическая секция всегда ждет столько, сколько потребуется.
Способы организации межпроцессного взаимодействия (IPC), их достоинства и недостатки
Межпроцессное взаимодействие (англ. inter-process communication, IPC) — обмен данными между потоками одного или разных процессов. Реализуется посредством механизмов, предоставляемых ядром ОС или процессом, использующим механизмы ОС и реализующим новые возможности IPC. Может осуществляться как на одном компьютере, так и между несколькими компьютерами сети.

Каналы (pipes): виды, особенности реализации в ОС семейства Windows и в ОС семейства Linux
В программировании именованный канал или именованный конвейер (англ. named pipe) — один из методов межпроцессного взаимодействия, расширение понятия конвейера в Unix и подобных ОС. Именованный канал позволяет различным процессам обмениваться данными, даже если программы, выполняющиеся в этих процессах, изначально не были написаны для взаимодействия с другими программами. Это понятие также существует и в Microsoft Windows, хотя там его семантика существенно отличается. Традиционный канал — «безымянен», потому что существует анонимно и только во время выполнения процесса. Именованный канал — существует в системе и после завершения процесса. Он должен быть «отсоединён» или удалён, когда уже не используется. Процессы обычно подсоединяются к каналу для осуществления взаимодействия между ними.
Именованные каналы
В Windows дизайн именованных каналов смещён к взаимодействию «клиент-сервер», и они работают во многом как сокеты: помимо обычных операций чтения и записи, именованные каналы в Windows поддерживают явный «пассивный» режим для серверных приложений (для сравнения: сокет домена UNIX). Windows 95 поддерживает клиенты именованных каналов, а системы ветви Windows NT могут служить также и серверами.
К именованному каналу можно обращаться в значительной степени как к файлу. Можно использовать функции Windows API CreateFile, CloseHandle, ReadFile, WriteFile, чтобы открывать и закрывать канал, выполнять чтение и запись. Функции стандартной библиотеки Си, такие, как fopen, fread, fwrite и fclose, тоже можно использовать, в отличие от сокетов Windows (англ.), которые не реализуют использование стандартных файловых операций в сети. Интерфейс командной строки (как в Unix) отсутствует.
Именованные каналы — не существуют постоянно и не могут, в отличие от Unix, быть созданы как специальные файлы в произвольной доступной для записи файловой системе, но имеют временные имена (освобождаемые после закрытия последней ссылки на них), которые выделяются в корне файловой системы именованных каналов (англ. named pipe filesystem, NPFS) и монтируются по специальному пути «\\.\pipe\» (то есть у канала под названием «foo» полное имя будет «\\.\pipe\foo»). Анонимные каналы, использующиеся в конвейерах, — это на самом деле именованные каналы со случайным именем.
Прикладной уровень
На прикладном уровне (Application layer) работает большинство сетевых приложений.
Эти программы имеют свои собственные протоколы обмена информацией, например, HTTP для WWW, FTP (передача файлов), SMTP (электронная почта), SSH (безопасное соединение с удалённой машиной), DNS (преобразование символьных имён в IP-адреса) и многие другие.
В массе своей эти протоколы работают поверх TCP или UDP и привязаны к определённому порту, например:
· HTTP на TCP-порт 80 или 8080,
· FTP на TCP-порт 20 (для передачи данных) и 21 (для управляющих команд),
· SSH на TCP-порт 22,
· запросы DNS на порт UDP (реже TCP) 53,
· обновление маршрутов по протоколу RIP на UDP-порт 520.
Эти порты определены Агентством по выделению имен и уникальных параметров протоколов (IANA).
К этому уровню относятся: DHCP[1], Echo, Finger, Gopher, HTTP, HTTPS, IMAP, IMAPS, IRC, NNTP, NTP, POP3, POPS, QOTD, RTSP, SNMP, SSH, Telnet, XDMCP.
Транспортный уровень[править | править вики-текст]
Протоколы транспортного уровня (Transport layer) могут решать проблему негарантированной доставки сообщений («дошло ли сообщение до адресата?»), а также гарантировать правильную последовательность прихода данных. В стеке TCP/IP транспортные протоколы определяют, для какого именно приложения предназначены эти данные.
Сетевой уровень[править | править вики-текст]
Сетевой уровень (Internet layer) изначально разработан для передачи данных из одной сети в другую. Примерами такого протокола является X.25 и IPC в сети ARPANET.
С развитием концепции глобальной сети в уровень были внесены дополнительные возможности по передаче из любой сети в любую сеть, независимо от протоколов нижнего уровня, а также возможность запрашивать данные от удалённой стороны, например в протоколе ICMP (используется для передачи диагностической информации IP-соединения) и IGMP (используется для управления multicast-потоками).
ICMP и IGMP расположены над IP и должны попасть на следующий — транспортный — уровень, но функционально являются протоколами сетевого уровня, и поэтому их невозможно вписать в модель OSI.
Канальный уровень
Канальный уровень (Link layer) описывает, каким образом передаются пакеты данных через физический уровень, включая кодирование (то есть специальные последовательности бит, определяющих начало и конец пакета данных). Ethernet, например, в полях заголовка пакета содержит указание того, какой машине или машинам в сети предназначен этот пакет.
Кроме того, канальный уровень описывает среду передачи данных (будь то коаксиальный кабель, витая пара, оптическое волокно или радиоканал), физические характеристики такой среды и принцип передачи данных (разделение каналов, модуляцию, амплитуду сигналов, частоту сигналов, способ синхронизации передачи, время ожидания ответа и максимальное расстояние).
Кэширование
Блочный кэш (буферный кэш) - набор блоков хранящиеся в памяти, но логически принадлежащие диску.
Перехватываются все запросы чтения к диску, и проверяется наличие требуемых блоков в кэше.
Ситуация схожа со страничной организацией памяти, можно применять те же алгоритмы.
Нужно чтобы измененные блоки периодически записывались на диск.
В UNIX это выполняет демон update (вызывая системный вызов sync).
В MS-DOS модифицированные блоки сразу записываются на диск (сквозное кэширование).
Опережающее чтение блока
Если файлы считываются последовательно, и когда получен к-блок, можно считать блок к+1 (если его нет в памяти). Что увеличивает быстродействие.
RAID 2
Массивы такого типа основаны на использовании кода Хэмминга. Диски делятся на две группы: для данных и для кодов коррекции ошибок, причём если данные хранятся на {\displaystyle 2^{n}-n-1}дисках, то для хранения кодов коррекции необходимо {\displaystyle n} дисков (в сумме {\displaystyle 2^{n}-1} дисков). Данные распределяются по дискам, предназначенным для хранения информации, так же, как и в RAID 0, то есть они разбиваются на небольшие блоки по числу дисков. Оставшиеся диски хранят коды коррекции ошибок.
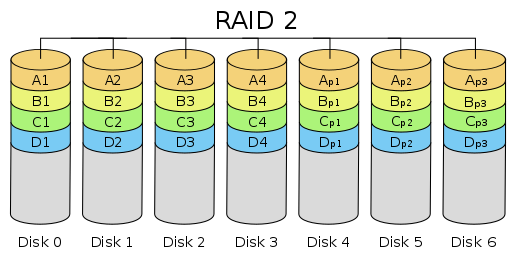
RAID 3
В массиве RAID 3 из {\displaystyle n}дисков данные разбиваются на куски размером меньше сектора (разбиваются на байты или блоки) и распределяются по {\displaystyle n-1} дискам. Ещё один диск используется для хранения блоков чётности.
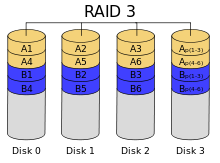
RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты. Таким образом, удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объёма. Запись же производится медленно из-за того, что чётность для блока генерируется при записи и записывается на единственный диск.
Под RAID 0+1 может подразумеваться в основном два варианта:
два RAID 0 объединяются в RAID 1;
в массив объединяются четыре и более диска, и каждый блок данных записывается на два диска данного массива[3]; таким образом, при таком подходе, как и в «чистом» RAID 1, полезный объём массива составляет половину от суммарного объёма всех дисков (если это диски одинаковой ёмкости).

26. Системы хранения данных. RAID 5, 6, 10 (1+0), 50, 51
RAID 5 Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чётности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков.

RAID 6 — похож на RAID 5, но имеет более высокую степень надёжности — три диска данных и два диска контроля чётности. Основан на кодах Рида — Соломона и обеспечивает работоспособность после одновременного выхода из строя любых двух дисков.

RAID 10 (1+0)
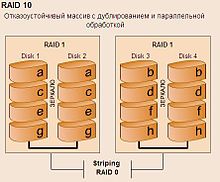
Схема архитектуры RAID 10
RAID 10 — зеркалированный массив, данные в котором записываются последовательно на несколько дисков, как в RAID 0. Эта архитектура представляет собой массив типа RAID 0, сегментами которого вместо отдельных дисков являются массивы RAID 1. Соответственно, массив этого уровня должен содержать как минимум 4 диска (и всегда чётное количество). RAID 10 объединяет в себе высокую отказоустойчивость и производительность.
Например:
· RAID 51 — RAID 1, зеркалирующий два RAID 5.
Комбинированные уровни наследуют как преимущества, так и недостатки своих «родителей»: появление чередования в уровне RAID 5+0 нисколько не добавляет ему надёжности, но зато положительно отражается на производительности. Уровень RAID 1+5, наверное, очень надёжный, но не самый быстрый и, к тому же, крайне неэкономичный: полезная ёмкость тома меньше половины суммарной ёмкости дисков.
Выход из взаимоблокировки
Восстановление при помощи принудительной выгрузки ресурса
Как правило, требует ручного вмешательства (например: принтер).
Восстановление через откат
Состояние процессов записывается в контрольных точках, и в случае тупика можно сделать откат процесса на более раннее состояние, после чего он продолжит работу снова с этой точки.
С принтером опять будут проблемы.
Восстановление путем уничтожения процесса
Самый простой способ.
Мобильные ОС
Мобильная операционная система (мобильная ОС) — операционная система для смартфонов, планшетов, КПК или других мобильных устройств. Хотя ноутбуки и можно отнести к мобильным устройствам, однако операционные системы, обычно используемые на них, мобильными не считаются, так как изначально разрабатывались для крупных стационарных настольных компьютеров, которые традиционно не имели специальных «мобильных» функций, да и не нуждались в них. Это различие размыто в некоторых новых операционных системах, представляющих гибрид того и другого.
Мобильные операционные системы сочетают в себе функциональность ОС для ПК с функциями для мобильных и карманных устройств: сенсорный экран, сотовая связь, Bluetooth, Wi-Fi, GPS-навигация, камера, видеокамера, распознавание речи, диктофон, музыкальный плеер, NFC и инфракрасное дистанционное управление.
Портативные устройства мобильной связи (например, смартфоны) содержат две операционные системы. Основную программную платформу взаимодействия с пользователем дополняет вторая, низкоуровневая проприетарная операционная система реального времени, обслуживающая радиооборудование. Исследования показали, что такие низкоуровневые операционные системы уязвимы перед вредоносными базовыми станциями, способными получить контроль над мобильным устройством.
Версии
Win16 — первая версия WinAPI для 16-разрядных версий Windows. Изначально назывался Windows API, позднее был ретроспективно переименован в Win16 для отличия от Win32. Описан в стандарте ECMA-234.
Win32 — 32-разрядный API для современных версий Windows. Самая популярная ныне версия. Базовые функции реализованы в динамически подключаемых библиотеках kernel32.dll и advapi32.dll; базовые модули графического интерфейса пользователя — в user32.dll и gdi32.dll. Win32 появился вместе с Windows NT и затем был перенесён в несколько ограниченном виде в системы серии Windows 9x. В современных версиях Windows, происходящих от Windows NT, работу Win32 GUI обеспечивают два модуля: csrss.exe (процесс исполнения клиент-сервер), работающий в пользовательском режиме, и win32k.sys в режиме ядра. Работу же системы обеспечивает ядро — ntoskrnl.exe.
Win32s — подмножество Win32, устанавливаемое на семейство 16-разрядных систем Windows 3.x и реализующее ограниченный набор функций Win32 для этих систем.
Win64 — 64-разрядная версия Win32, содержащая дополнительные функции Windows на платформах x86-64 и IA-64.
Linux. Стандарт POSIX
Linux — семейство Unix-подобных операционных систем на базе ядра Linux, включающих тот или иной набор утилит и программ проекта GNU, и, возможно, другие компоненты. Как и ядро Linux, системы на его основе как правило создаются и распространяются в соответствии с моделью разработки свободного и открытого программного обеспечения.
POSIX — набор стандартов, описывающих интерфейсы между операционной системой и прикладной программой (системный API), библиотеку языка C и набор приложений и их интерфейсов. Стандарт создан для обеспечения совместимости различных UNIX-подобных операционных систем и переносимости прикладных программ на уровне исходного кода, но может быть использован и для не-Unix систем.
Реализация потоков в пpостpанстве пользователя.
Есть 2 основных способа реализации потоков: в пространстве пользователя и ядре. 1-й метод состоит в размещении пакета потоков целиком в пространстве пользователя. При этом ядро о потоках ничего не знает и управляет обычными, однопоточными процессами. Преимущество: пакет потоков на уровне пользователя можно реализовать даже в ОС, не поддерживающей потоки.
Общая схема:

Потоки работают поверх СПИП - системы поддержки исполнения программ(набор процедур, управляющих потоками). Кажд процессу необходима собственная таблица потоков для отслеживания потоков в процессе. Эта таблица отслеживает характеристики потоков (счетчик команд, указатель вершины стека, регистры, состояние и т. п.) Когда поток переходит в сост готов-и или блокир-и, вся информ, необход для повторного запуска, хранится в таблице потоков подобному тому, как в ядре хранится информация о процессах в таблице процессов.
Когда поток, ожидая окончания действия другого потока в том же процессе, делает нечто, что может привести к локальной блокировке, он вызывает процедуру СПИП, которая проверяет необходимость блокирования потока. Если блокирован, то переход к другому потоку.
Реализация потоков в ядре. Активация планировщика.
Ядро знает о существовании потоков и управляет ими.

Нет системы поддержки команд, нет необходимости и в наличии таблицы потоков в каждом процессе, вместо этого есть единая таблица потоков, отслеживающая все потоки системы. Если потоку необходимо создать новый поток или завершить имеющийся, он выполняет запрос ядра, который создает или завершает поток, внося изменения в таблицу потоков. Таблица потоков, находящаяся в ядре, содержит регистры, состояние и другую информацию о каждом потоке. Информация о потоке расположена в ядре. Дополнительно ядро содержит обычную таблицу процессов, отслеживающую все процессы системы.
Все запросы, которые могут блокировать поток, реализуются как системные запросы, что требует ↑временных затрат, чем вызов процедуры системы поддержки исполнения программ. Когда поток блокируется, ядро по желанию запускает другой поток из этого же процесса (если есть поток в состоянии готовности) либо поток из другого процесса.
7. Алгоритмы планирования: первым пришел – первым обслужен (FCFS), самая короткая задача первой (SJF), циклическое планирование (Round Robin, RR)
Простейшим алгоритмом планирования является алгоритм, который принято обозначать аббревиатурой FCFS по первым буквам его английского названия – First-Come, First-Served (первым пришел, первым обслужен). Представим себе, что процессы, находящиеся в состоянии готовность, выстроены в очередь. Когда процесс переходит в состояние готовность, он, а точнее, ссылка на его PCB помещается в конец этой очереди. Выбор нового процесса для исполнения осуществляется из начала очереди с удалением оттуда ссылки на его PCB. Очередь подобного типа имеет в программировании специальное наименование – FIFO1, сокращение от First In, First Out (первым вошел, первым вышел).
Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение процессор, занимает его до истечения текущего CPU burst. После этого для выполнения выбирается новый процесс из начала очереди.
Round Robin (RR)
Модификацией алгоритма FCFS является алгоритм, получивший название Round Robin (Round Robin – это вид детской карусели в США) или сокращенно RR. По сути дела, это тот же самый алгоритм, только реализованный в режиме вытесняющего планирования. Можно представить себе все множество готовых процессов организованным циклически – процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора небольшой фиксированный квант времени, обычно 10 – 100миллисекунд (см. рис. 3.4.). Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться.

SJF-меньше время выполнения- выполняется первым.
8. Алгоритмы планирования: приоритетное и гарантированное планирование, лотерейное планирование
Гарантированное планирование
При интерактивной работе N пользователей в вычислительной системе можно применить алгоритм планирования, который гарантирует, что каждый из пользователей будет иметь в своем распоряжении ~1/N часть процессорного времени. Пронумеруем всех пользователей от 1 до N. Для каждого пользователя с номером i введем две величины: Ti – время нахождения пользователя в системе или, другими словами, длительность сеанса его общения с машиной и  – суммарное процессорное время уже выделенное всем его процессам в течение сеанса. Справедливым для пользователя было бы получение Ti/N процессорного времени. Если
– суммарное процессорное время уже выделенное всем его процессам в течение сеанса. Справедливым для пользователя было бы получение Ti/N процессорного времени. Если

то i -й пользователь несправедливо обделен процессорным временем. Если же

то система явно благоволит к пользователю с номером i. Вычислим для процессов каждого пользователя значение коэффициента справедливости

и будем предоставлять очередной квант времени готовому процессу с наименьшей величиной этого отношения. Предложенный алгоритм называют алгоритмом гарантированного планирования.
Приоритетное планирование
Алгоритмы SJF и гарантированного планирования представляют собой частные случаи приоритетного планирования. При приоритетном планировании каждому процессу присваивается определенное числовое значение – приоритет, в соответствии с которым ему выделяется процессор. Процессы с одинаковыми приоритетами планируются в порядке FCFS. Для алгоритма SJF в качестве такого приоритета выступает оценка продолжительности следующего CPU burst. Чем меньше значение этой оценки, тем более высокий приоритет имеет процесс. Для алгоритма гарантированного планирования приоритетом служит вычисленный коэффициент справедливости. Чем он меньше, тем больше у процесса приоритет.
Лотерейное планирование
Процессам раздаются "лотерейные билеты" на доступ к ресурсам. Планировщик может выбрать любой билет, случайным образом. Чем больше билетов у процесса, тем больше у него шансов захватить ресурс.
9. Операционные системы реального времени: классификация, особенности планирования процессов (потоков), примеры
Операционная система реального времени — тип операционной системы, основное назначение которой — предоставление необходимого и достаточного набора функций для работы систем реального времени на конкретном аппаратном оборудовании.
Алгоритмы планирования
В настоящее время для решения задачи эффективного планирования в ОСРВ наиболее интенсивно развиваются два подхода[9]:
статические алгоритмы планирования (RMS, Rate Monotonic Scheduling) — используют приоритетное вытесняющее планирование, приоритет присваивается каждой задаче до того, как она начала выполняться, преимущество отдаётся задачам с самыми короткими периодами выполнения;
динамические алгоритмы планирования (EDF, Earliest Deadline First Scheduling) — приоритет задачам присваивается динамически, причём предпочтение отдаётся задачам с наиболее ранним предельным временем начала (завершения) выполнения.
При больших загрузках системы EDF более эффективен, нежели RMS.
FreeRTOS FreeRTOS- является популярной ядерной ОС в режиме реального времени для встраиваемых устройств, которая загружается 35 микроконтроллерами. Она распространяется под лицензией GPL с дополнительным ограничением и необязательными исключениями. Ограничение запрещает бенчмаркинг, в то время как исключение позволяет использовать собственный код пользователей вместе с закрытым исходным кодом, сохраняя при этом само ядро. Это облегчает тем самым использование FreeRTOS в собственных приложениях.
|
|
|

Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...

История развития пистолетов-пулеметов: Предпосылкой для возникновения пистолетов-пулеметов послужила давняя тенденция тяготения винтовок...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰)...
© cyberpedia.su 2017-2026 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!

