Сжатие данных
Сжатие данных (англ. data compression) —преобразование данных, производимое с целью уменьшения их объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы — упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией).
Компрессия и декомпрессия могут быть как без потери качества (когда передаваемая/хранимая информация в сжатом виде после декомпрессии абсолютно идентична исходной), так и с потерей качества (когда данные после декомпрессии отличаются от оригинальных). Например, текстовые документы, базы данных, программы могут быть сжаты только способом без потери качества, в то время как картинки, видеоролики и аудиофайлы сжимаются именно за счёт потери качества исходных данных (характерный пример алгоритмов - JPEG, MPEG, ADPCM) порой при незаметной потере качества даже при сжатии 1:4 или 1:10.
Выделяются основные виды упаковки:
- Десятичная упаковка предназначена для упаковки символьных данных, состоящих только из чисел. Вместо используемых 8 бит под символ можно вполне рационально использовать всего лишь 4 бита для десятичных и шестнадцатеричных цифр, 3 бита для восьмеричных и т.д. При подобном подходе уже ощущается сжатие минимум 1:2.
- Относительное кодирование является кодированием с потерей качества. Оно основано на том, что последующий элемент данных отличается от предыдущего на величину, занимающую в памяти меньше места, чем сам элемент. Характерным примером является аудиосжатие ADPCM (Adaptive Differencial Pulse Code Modulation), широко применяемое в цифровой телефонии и позволяющее сжимать звуковые данные в соотношении 1:2 с практически незаметной потерей качества.
- Символьное подавление - способ сжатия информации, при котором длинные последовательности из идентичных данных заменяются более короткими.
- Статистическое кодирование основано на том, что не все элементы данных встречаются с одинаковой частотой (или вероятностью). Коды выбираются так, чтобы наиболее часто встречающемуся элементу соответствовал код с наименьшей длиной, а наименее частому - с наибольшей. Кроме этого, коды подбираются таким образом, чтобы при декодировании можно было однозначно определить элемент исходных данных. При таком подходе возможно только бит-ориентированное кодирование, при котором выделяются разрешённые и запрещённые коды. Если при декодировании битовой последовательности код оказался запрещённым, то к нему необходимо добавить ещё один бит исходной последовательности и повторить операцию декодирования. Примерами такого кодирования являются алгоритмы Шеннона и Хафмана.
Технология, позволяющая сократить размер обрабатываемых данных, называется сжатием данных. Сжатие данных особенно важно при передаче и хранении данных. Существует множество методов сжатия и чаще всего каждый из них применяется в своей специфической области применения.
Упомянем наиболее универсальные методы.
Метод кодирования длины серий
http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%B4%D0%BB%D0%B8%D0%BD_%D1%81%D0%B5%D1%80%D0%B8%D0%B9
Кодирование длин серий (англ. Run-length encoding, RLE) или Кодирование повторов — простой алгоритм сжатия данных, который оперирует сериями данных, то есть последовательностями, в которых один и тот же символ встречается несколько раз подряд. При кодировании строка одинаковых символов, составляющих серию, заменяется строкой, которая содержит сам повторяющийся символ и количество его повторов. Это метод из группы символьного подавления.
Пример использования
Рассмотрим изображение, содержащее простой чёрный текст на сплошном белом фоне. Здесь будет много серий белых пикселей в пустых местах, и много коротких серий чёрных пикселей в тексте. В качестве примера приведена некая произвольная строка изображения в черно-белом варианте. Здесь B представляет чёрный пиксель, а W обозначает белый:
WWWWWWWWWWWWBWWWWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW
Если мы применим простое кодирование длин серий к этой строке, то получим следующее:
12W1B12W3B24W1B14W
Последняя запись интерпретируется как «двенадцать W», «одна B», «двенадцать W», «три B» и т. д. Таким образом, код представляет исходные 67 символов в виде всего лишь 18.
Однако, в случае, если строка состоит из большого количества неповторяющихся символов, её объем может вырасти.
ABCABCABCABCDDEFFFFFFFF
1A1B1C1A1B1C1A1B1C1A1B1C2D1E8F
Проблема решается достаточно просто. Алфавит, в котором записаны длины серий, разделяется на две (обычно равные) части. Алфавит целых чисел можно, например, разделить на две части: положительные и отрицательные. Положительные используют для записи количества повторяющихся одинаковых символов, а отрицательные — для записи количества неодинаковых.
-12ABCABCABCABC2D1E8F
Так как численные типы данных на компьютере всегда имеют некоторый предел, возникает еще одна проблема. Предположим, мы используем signed char для записи длин серий. Тогда мы не можем записать серию длиннее 127 символов одной парой "длина-символ". Если подряд записано 256 символов A, их разделяют на минимальное количество групп:
127A127A2A
Запись на некотором языке программирования алгоритма RLE с учетом этих ограничений нетривиальна.
Конечно, кодирование, которое используется для хранения изображений, оперирует с двоичными данными, а не с символами ASCII, как в рассмотренном примере, однако принцип остаётся тот же.
Применение
Очевидно, что такое кодирование эффективно для данных, содержащих большое количество серий, например, для простых графических изображений, таких как иконки и графические рисунки. Однако это кодирование плохо подходит для изображений с плавным переходом тонов, таких как фотографии.
Методом кодирования длин серий могут быть сжаты произвольные файлы с двоичными данными, поскольку спецификации на форматы файлов часто включают в себя повторяющиеся байты в области выравнивания данных.
Звуковые данные, которые имеют длинные последовательные серии байт (такие как низкокачественные звуковые семплы) могут быть сжаты с помощью RLE после того, как к ним будет применено Дельта-кодирование.
Алгоритм на Паскале (Delphi) для практического занятия
function encode(s:string):string;var i,j:integer; newS:string;begin i:=1; while i <= length(s) do begin j:=i; while (s[i] = s[j+1]) do inc(j); if (j-i = 0) or (j-i = 1) or (j-i =2) then begin newS:= newS + s[i]; if (s[i]='0') then newS:=newS+'0'; inc(i); end else begin newS:= newS + inttostr(j-i+1) + s[i]; inc(i,j-i+1); end; end; result:= newS;end; function decode(s:string):string;var i,j,c:integer; newS:string; dp: string;begini:=1;while i <= length(s) do begin j:=i; while s[j] in ['0'..'9'] do inc(j); if j-i > 0 then begin dp:= copy(s,i,j-i); for c:=1 to strtoint(dp) do newS:= newS + s[j]; delete(s,i,j-i+1); end else begin newS:= newS + s[i]; inc(i); end; end; result:= newS; end;
Относительное кодирование
В некоторых случаях информация может состоять из блоков данных, каждый из которых лишь немного отличается от соседнего, как, например, последовательные кадры видеоизображения. Тогда кодированию подлежат только отличия.
Относительное кодирование имеет очень интересную историю, и впервые было предложено и опробовано на практике отечественными исследователями при кодировании звука.
До относительного кодирования, использовалось исключительно абсолютное, и абсолютному значения фазы соответствовал тот или иной конкретный символ.
С позиций сегодняшнего времени узкие моменты видны сразу же, достаточно в демодуляторе "потерять" правильную привязку к начальной фазе, и ни о какой правильной демодуляции речи идти не может. Фазовая манипуляция в целом очень долго считалась совершенно бесперспективной для передачи информации.
Громом среди ясного неба(примерно в середине 50-х годов), прозвучало предложение отечественного ученого Петровича Н. Т. кодировать при фазовой манипуляции символ не абсолютным значением, а разностью значений соседних символов.
Решение оказалось настолько гениальным, изящным и неожиданным, что верить в его работоспособность многие просто отказывались. Сравнительные испытания продемонстрировали перспективность метода относительного кодирования. Замена битового потока из абсолютных значений бит на относительные позволяет игнорировать конкретную фазу текущего символа, и ориентироваться на разность фаз соседних символов.
Относительное кодирование, ценой всего лишь одного символа(!) гарантирует в целом безошибочную демодуляцию при любых начальных фазовых углах в демодуляторе. Или, по другому, при случайной смене/скачке фазы будет потерян/иметь неопределенное значение, всего один символ, все сообщение будет принято в целом верно. Кроме того, относительное кодирование использует все возможности текущей размерности фазовой манипуляции полностью.
Кодирование Хаффмана
Идея алгоритма состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (т.е. ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
- Выбираются два свободных узла дерева с наименьшими весами.
- Создается их родитель с весом, равным их суммарному весу.
- Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая таблица частот:
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т. д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от листа дерева, соответствующего этому символу, до корня дерева, накапливая биты при перемещении по ветвям дерева. Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Для данной таблицы символов коды Хаффмана будут выглядеть следующим образом.
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока. Кроме того, наиболее частый символ сообщения А закодирован наименьшим количеством бит, а наиболее редкий символ Д — наибольшим.
Классический алгоритм Хаффмана имеет ряд существенных недостатков. Во-первых, для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для собственно кодирования. Во-вторых, избыточность кодирования обращается в ноль лишь в тех случаях, когда вероятности кодируемых символов являются обратными степенями числа 2. В-третьих, для источника с энтропией, не превышающей 1 (например, для двоичного источника), непосредственное применение кода Хаффмана бессмысленно.
Биты четности
Использование битов четности (контрольных битов) является типовым решением для основной памяти. Принцип состоит в том, что если каждая обрабатываемая битовая комбинация будет содержать нечетное количество единиц, то обнаружение комбинации с четным количеством единиц будет свидетельствовать об ошибке. Реализация принципа достигается добавлением к уже существующему коду дополнительного бита, который устанавливается либо в 1, либо в 0 так, чтобы общее количество единиц в комбинации стало нечетным. Обычно этот бит четности является старшим битом. В результате, например, 8-ми разрядный код ASCII становится 9-ти разрядным и символ ‘A’ будет представлен как 1 01000001, а символ ‘F’ как 0 01000110, так что в обоих случаях количество единиц нечетно. При записи информации схема управления памятью автоматически добавляет контрольный бит. При считывании информации схема управления памятью подсчитывает количество единиц. Если ошибка не обнаружена, контрольный бит удаляется и образуется исходная комбинация. В противном случае считанное значение возвращается с указанием, что оно искажено.
Длинные битовые комбинации могут дополняться группой контрольных битов, образующих контрольный байт. На этой основе создаются схемы контроля, называемые методом контрольных сумм и методом использования кода циклического контроля избыточности. Эти методы позволяют обнаружить ошибку, но не могут ее исправить.
Коды с исправлением ошибок
Принцип действия основан на применении кодировок с достаточно длинными дистанциями Хэмминга (R.W. Hamming ‑ первый исследователь в области разработки кодов с исправлением ошибок). Дистанция Хэмминга между двумя битовыми комбинациями равна количеству битов, отличающихся в этих комбинациях. Пусть, например,
| Символ
| Код
| Дистанция Хэмминга
|
| A
|
|
|
|
|
|
|
| B
|
|
|
|
|
|
|
| C
|
|
|
|
|
|
|
| D
|
|
|
|
|
|
|
| E
|
|
|
|
|
|
|
| F
|
|
|
|
|
|
|
| G
|
|
|
|
|
|
|
| H
|
|
|
Если в результате сбоя в одиночном бите появится ошибка, она легко будет установлена, так как получившаяся комбинация не будет допустимой. В любой комбинации надо будет «испортить» не меньше трех битов. Кроме того, исправить ошибку будет нетрудно. Надо только просмотреть допустимые комбинации и найти ту из них, которая находится на дистанции, равной единице от имеющейся комбинации. Например, недопустимый код 101111 находится на единичной дистанции от 001111, кодирующей символ B. Значит, можно сделать вывод, что 101111 – это ошибочный код для B и исправить ошибку. Чем больше дистанция Хэмминга, тем больше ошибок можно обнаружить и исправить. Разработка эффективных кодов с достаточно длинными дистанциями Хэмминга невозможна без знания алгебраической теории кодирования, которая является частью линейной алгебры и теории матриц.
Методы коррекции ошибок широко используются в драйверах магнитных дисков большой емкости, чтобы снизить вероятность искажения хранимой информации в результате дефектов поверхности диска. Формат CD-ROM (и прочие) также имеет средства, позволяющие снизить вероятность появления ошибок (до одной на 20000 компакт-дисков).
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух слов одинаковой длины различны. В более общем случае расстояние Хэмминга применяется для строк одинаковой длины любых q -ичных алфавитов и служит метрикой различия (функцией, определяющей расстояние в метрическом пространстве) объектов одинаковой размерности.
Первоначально метрика была сформулирована Ричардом Хэммингом во время его работы в Bell Labs для определения меры различия между кодовыми комбинациями (двоичными векторами) в векторном пространстве кодовых последовательностей, в этом случае расстоянием Хэмминга  между двумя двоичными последовательностями (векторами)
между двумя двоичными последовательностями (векторами)  и
и 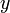 длины
длины 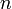 называется число позиций, в которых они различны — в такой формулировке расстояние Хэмминга вошло в словарь алгоритмов и структур данных национального института стандартов и технологий США (англ. NIST Dictionary of Algorithms and Data Structures). Расстояние Хэмминга является частным случаем метрики Минковского:
называется число позиций, в которых они различны — в такой формулировке расстояние Хэмминга вошло в словарь алгоритмов и структур данных национального института стандартов и технологий США (англ. NIST Dictionary of Algorithms and Data Structures). Расстояние Хэмминга является частным случаем метрики Минковского:
 .
.
Примеры
Свойства
Расстояние Хэмминга обладает свойствами метрики, удовлетворяя следующим условиям:
Упаковка звука
Из всех видов информации звук хуже всего поддается сжатию, так как звуковые сигналы обладают малой избыточностью. Упаковка основывается на том факте, что если интенсивность раздражителя меняется в геометрической прогрессии, то интенсивность человеческого восприятия меняется в арифметической прогрессии.
Применительно к звуку это означает, что если повышать громкость звука в 2, 4, 8 и т.д. раз, то человеческое ухо будет воспринимать это как линейное увеличение интенсивности. Т.е. изменение громкости от 1 до 2 столь же заметно человеку, как и изменение громкости от 100 до 200. А изменение от 100 до 101 практически не ощущается. Заметим, что log 2 – log 1 = log 200 – log 100 = log 2. Поэтому при упаковке звука значение амплитуды звука заменяют логарифмом этого значения, округляют и упаковывают полученные значения, что позволяет сжать информацию в два раза. Действительно, при 8-ми битном кодировании звука амплитуда не превосходит 27, значит, log2 A не превосходит 7 и может быть закодирован тремя двоичными разрядами. Еще один разряд на знак амплитуды и получается четыре разряда.
Ассоциация Motion Picture Expert Group (MPEG), входящая в состав ISO, разработала методы сжатия звуковой информации, позволяющие сжимать данные в 12 раз (формат MP3) http://www.n-audio.com/articles/format-2.htm
Нотная запись
Описанный способ кодирования звуковой информации универсален, он позволяет представить любой звук, преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки ‑ нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. А вы уже знаете, что для "перевода" символьной информации в понятную компьютеру форму достаточно иметь таблицу соответствия между символами этого языка и их двоичными кодами.
В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии. А, кроме того, качество звучания зависит исключительно от возможностей синтезатора или звуковой платы компьютера, с помощью которых это происходит.
Форматы звуковых файлов
Формат AU. Этот простой и распространенный формат на системах Sun и NeXT (в последнем случае, правда, файл будет иметь расширение SND). Файл состоит из короткого служебного заголовка (минимум 28 байт), за которым непосредственно следуют звуковые данные. Широко используется в Unix-подобных системах и служит базовым для Java-машины.
Формат WAVE (WAV). Стандартный формат файлов для хранения звука в системе Windows. Является специальным типом другого, более общего формата RIFF (Resource Interchange File Format); другой разновидностью RIFF служат видеофайлы AVI. Файл RIFF составлен из блоков, некоторые из которых могут, в свою очередь, содержать другие вложенные блоки; перед каждым блоком данных помещается четырехсимвольный идентификатор и длина. Звуковые файлы WAV, как правило, более просты и имеют только один блок формата и один блок данных. В первом содержится общая информация об оцифрованном звуке (число каналов, частота дискретизации, характер зависимости громкости и т.д.), а во втором — сами числовые данные. Каждый отсчет занимает целое количество байт (например, 2 байта в случае 12-битовых чисел, старшие разряды содержат нули). При стереозаписи числа группируются парами для левого и правого канала соответственно, причем каждая пара образует законченный блок — для нашего примера его длина составит 4 байта. Такая, казалось бы, излишняя структурированность позволяет программному обеспечению оптимизировать процесс передачи данных при воспроизведении, но, как в подобных случаях всегда бывает, выигрыш во времени приводит к существенному увеличению размера файла.
Формат MP3 (MPEG Layer3). Это один из форматов хранения аудиосигнала, позднее утвержденный как часть стандартов сжатого видео. Природа получения данного формата во многом аналогична уже рассмотренному нами ранее сжатию графических данных по технологии JPEG. Поскольку произвольные звуковые данные обратимыми методами сжимаются недостаточно хорошо, приходится переходить к методам необратимым: иными словами, базируясь на знаниях о свойствах человеческого слуха, звуковая информация “подправляется” так, чтобы возникшие искажения на слух были незаметны, но полученные данные лучше сжимались традиционными способами. Это называется адаптивным кодированием и позволяет экономить на наименее значимых с точки зрения восприятия человека деталях звучания. Приемы, применяемые в MP3, непросты для понимания и опираются на достаточно сложную математику, но зато обеспечивают очень значительный эффект сжатия звуковой информации. Успехи технологии MP3 привели к тому, что ее применяют сейчас и во многих бытовых звуковых устройствах, например, плеерах и сотовых телефонах.
Формат MIDI. Название MIDI есть сокращение от Musical Instrument Digital Interface, т.е. цифровой интерфейс для музыкальных инструментов. Это довольно старый (1983 г.) стандарт, объединяющий разнообразное музыкальное оборудование (синтезаторы, ударные, освещение). MIDI базируется на пакетах данных, каждый из которых соответствует некоторому событию, в частности, нажатию клавиши или установке режима звучания. Любое событие может одновременно управлять несколькими каналами, каждый из которых относится к определенному оборудованию. Несмотря на свое изначальное предназначение, формат файла стал стандартным для музыкальных данных, которые при желании можно проигрывать с помощью звуковой карты компьютера безо всякого внешнего MIDI-оборудования. Главным преимуществом файлов MIDI является их очень небольшой размер, поскольку это не детальная запись звука, а фактически некоторый расширенный электронный эквивалент традиционной нотной записи. Но это же свойство одновременно является и недостатком: поскольку звук не детализирован, то разное оборудование будет воспроизводить его по-разному, что в принципе может даже заметно исказить авторский музыкальный замысел.
Формат MOD. Представляет собой дальнейшее развитие идеологии MIDI-файлов. Известные как “модули программ воспроизведения”, они хранят в себе не только “электронные ноты”, но и образцы оцифрованного звука, которые используются как шаблоны индивидуальных нот. Таким способом достигается однозначность воспроизведения звука. К недостаткам формата следует отнести большие затраты времени при наложении друг на друга шаблонов одновременно звучащих нот.
Темы для докладов
- Алгоритм сжатия RLE.
- Алгоритм сжатия Хаффмана.
- Алгоритмы сжатия с применением адаптивного словаря.
- Передача информации. Коды с исправлением ошибок.
- Форматы звуковых файлов.
- ФорматJPEG графических файлов.
Сжатие данных
Сжатие данных (англ. data compression) —преобразование данных, производимое с целью уменьшения их объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы — упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией).
Компрессия и декомпрессия могут быть как без потери качества (когда передаваемая/хранимая информация в сжатом виде после декомпрессии абсолютно идентична исходной), так и с потерей качества (когда данные после декомпрессии отличаются от оригинальных). Например, текстовые документы, базы данных, программы могут быть сжаты только способом без потери качества, в то время как картинки, видеоролики и аудиофайлы сжимаются именно за счёт потери качества исходных данных (характерный пример алгоритмов - JPEG, MPEG, ADPCM) порой при незаметной потере качества даже при сжатии 1:4 или 1:10.
Выделяются основные виды упаковки:
- Десятичная упаковка предназначена для упаковки символьных данных, состоящих только из чисел. Вместо используемых 8 бит под символ можно вполне рационально использовать всего лишь 4 бита для десятичных и шестнадцатеричных цифр, 3 бита для восьмеричных и т.д. При подобном подходе уже ощущается сжатие минимум 1:2.
- Относительное кодирование является кодированием с потерей качества. Оно основано на том, что последующий элемент данных отличается от предыдущего на величину, занимающую в памяти меньше места, чем сам элемент. Характерным примером является аудиосжатие ADPCM (Adaptive Differencial Pulse Code Modulation), широко применяемое в цифровой телефонии и позволяющее сжимать звуковые данные в соотношении 1:2 с практически незаметной потерей качества.
- Символьное подавление - способ сжатия информации, при котором длинные последовательности из идентичных данных заменяются более короткими.
- Статистическое кодирование основано на том, что не все элементы данных встречаются с одинаковой частотой (или вероятностью). Коды выбираются так, чтобы наиболее часто встречающемуся элементу соответствовал код с наименьшей длиной, а наименее частому - с наибольшей. Кроме этого, коды подбираются таким образом, чтобы при декодировании можно было однозначно определить элемент исходных данных. При таком подходе возможно только бит-ориентированное кодирование, при котором выделяются разрешённые и запрещённые коды. Если при декодировании битовой последовательности код оказался запрещённым, то к нему необходимо добавить ещё один бит исходной последовательности и повторить операцию декодирования. Примерами такого кодирования являются алгоритмы Шеннона и Хафмана.
Технология, позволяющая сократить размер обрабатываемых данных, называется сжатием данных. Сжатие данных особенно важно при передаче и хранении данных. Существует множество методов сжатия и чаще всего каждый из них применяется в своей специфической области применения.
Упомянем наиболее универсальные методы.
Метод кодирования длины серий
http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%B4%D0%BB%D0%B8%D0%BD_%D1%81%D0%B5%D1%80%D0%B8%D0%B9
Кодирование длин серий (англ. Run-length encoding, RLE) или Кодирование повторов — простой алгоритм сжатия данных, который оперирует сериями данных, то есть последовательностями, в которых один и тот же символ встречается несколько раз подряд. При кодировании строка одинаковых символов, составляющих серию, заменяется строкой, которая содержит сам повторяющийся символ и количество его повторов. Это метод из группы символьного подавления.
Пример использования
Рассмотрим изображение, содержащее простой чёрный текст на сплошном белом фоне. Здесь будет много серий белых пикселей в пустых местах, и много коротких серий чёрных пикселей в тексте. В качестве примера приведена некая произвольная строка изображения в черно-белом варианте. Здесь B представляет чёрный пиксель, а W обозначает белый:
WWWWWWWWWWWWBWWWWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW
Если мы применим простое кодирование длин серий к этой строке, то получим следующее:
12W1B12W3B24W1B14W
Последняя запись интерпретируется как «двенадцать W», «одна B», «двенадцать W», «три B» и т. д. Таким образом, код представляет исходные 67 символов в виде всего лишь 18.
Однако, в случае, если строка состоит из большого количества неповторяющихся символов, её объем может вырасти.
ABCABCABCABCDDEFFFFFFFF
1A1B1C1A1B1C1A1B1C1A1B1C2D1E8F
Проблема решается достаточно просто. Алфавит, в котором записаны длины серий, разделяется на две (обычно равные) части. Алфавит целых чисел можно, например, разделить на две части: положительные и отрицательные. Положительные используют для записи количества повторяющихся одинаковых символов, а отрицательные — для записи количества неодинаковых.
-12ABCABCABCABC2D1E8F
Так как численные типы данных на компьютере всегда имеют некоторый предел, возникает еще одна проблема. Предположим, мы используем signed char для записи длин серий. Тогда мы не можем записать серию длиннее 127 символов одной парой "длина-символ". Если подряд записано 256 символов A, их разделяют на минимальное количество групп:
127A127A2A
Запись на некотором языке программирования алгоритма RLE с учетом этих ограничений нетривиальна.
Конечно, кодирование, которое используется для хранения изображений, оперирует с двоичными данными, а не с символами ASCII, как в рассмотренном примере, однако принцип остаётся тот же.
Применение
Очевидно, что такое кодирование эффективно для данных, содержащих большое количество серий, например, для простых графических изображений, таких как иконки и графические рисунки. Однако это кодирование плохо подходит для изображений с плавным переходом тонов, таких как фотографии.
Методом кодирования длин серий могут быть сжаты произвольные файлы с двоичными данными, поскольку спецификации на форматы файлов часто включают в себя повторяющиеся байты в области выравнивания данных.
Звуковые данные, которые имеют длинные последовательные серии байт (такие как низкокачественные звуковые семплы) могут быть сжаты с помощью RLE после того, как к ним будет применено Дельта-кодирование.
Алгоритм на Паскале (Delphi) для практического занятия
function encode(s:string):string;var i,j:integer; newS:string;begin i:=1; while i <= length(s) do begin j:=i; while (s[i] = s[j+1]) do inc(j); if (j-i = 0) or (j-i = 1) or (j-i =2) then begin newS:= newS + s[i]; if (s[i]='0') then newS:=newS+'0'; inc(i); end else begin newS:= newS + inttostr(j-i+1) + s[i]; inc(i,j-i+1); end; end; result:= newS;end; function decode(s:string):string;var i,j,c:integer; newS:string; dp: string;begini:=1;while i <= length(s) do begin j:=i; while s[j] in ['0'..'9'] do inc(j); if j-i > 0 then begin dp:= copy(s,i,j-i); for c:=1 to strtoint(dp) do newS:= newS + s[j]; delete(s,i,j-i+1); end else begin newS:= newS + s[i]; inc(i); end; end; result:= newS; end;
Относительное кодирование
В некоторых случаях информация может состоять из блоков данных, каждый из которых лишь немного отличается от соседнего, как, например, последовательные кадры видеоизображения. Тогда кодированию подлежат только отличия.
Относительное кодирование имеет очень интересную историю, и впервые было предложено и опробовано на практике отечественными исследователями при кодировании звука.
До относительного кодирования, использовалось исключительно абсолютное, и абсолютному значения фазы соответствовал тот или иной конкретный символ.
С позиций сегодняшнего времени узкие моменты видны сразу же, достаточно в демодуляторе "потерять" правильную привязку к начальной фазе, и ни о какой правильной демодуляции речи идти не может. Фазовая манипуляция в целом очень долго считалась совершенно бесперспективной для передачи информации.
Громом среди ясного неба(примерно в середине 50-х годов), прозвучало предложение отечественного ученого Петровича Н. Т. кодировать при фазовой манипуляции символ не абсолютным значением, а разностью значений соседних символов.
Решение оказалось настолько гениальным, изящным и неожиданным, что верить в его работоспособность многие просто отказывались. Сравнительные испытания продемонстрировали перспективность метода относительного кодирования. Замена битового потока из абсолютных значений бит на относительные позволяет игнорировать конкретную фазу текущего символа, и ориентироваться на разность фаз соседних символов.
Относительное кодирование, ценой всего лишь одного символа(!) гарантирует в целом безошибочную демодуляцию при любых начальных фазовых углах в демодуляторе. Или, по другому, при случайной смене/скачке фазы будет потерян/иметь неопределенное значение, всего один символ, все сообщение будет принято в целом верно. Кроме того, относительное кодирование использует все возможности текущей размерности фазовой манипуляции полностью.












