Эту технологию использует метод кодирования Lempel-Ziv (создатели Abraham Lempel и Jacob Ziv), реализованный в универсальной системе сжатия данных zip. Под словарем здесь понимается набор блоков, из которых строится сжатое сообщение. В процессе кодирования словарь меняется и всегда состоит из тех комбинаций, которые уже были сжаты. Например, при кодировании текста на русском языке, в словарь может попасть окончание «тся». В этой части моего конспекта данное окончание встречается десять раз и выигрыш от одиночной ссылки на «тся» вместо сочетания из трех ссылок окажется заметным.
В основе алгоритма сжатия по ключевым словам положен принцип кодирования лексических единиц группами байт фиксированной длины. Примером лексической единицы может быть обычное слово. На практике, на роль лексических единиц выбираются повторяющиеся последовательности символов, которые кодируются цепочкой символов (кодом) меньшей длины. Результат кодирования помещается в таблице, образовывая так называемый словарь.
Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются алгоритм Лемпеля-Зіва (алгоритм LZ) и его модификация алгоритм Лемпеля-Зіва-Велча (алгоритм LZW). Словарем в данном алгоритме является потенциально бесконечный список фраз. Алгоритм начинает работу с почти пустым словарем, который содержит только одну закодированную строку, так называемая NULL-строка. При считывании очередного символа входной последовательности данных, он прибавляется к текущей строке. Процесс продолжается до тех пор, пока текущая строка соответствует какой-нибудь фразе из словаря. Но рано или поздно текущая строка перестает соответствовать какой-нибудь фразе словаря. В момент, когда текущая строка представляет собой последнее совпадение со словарем плюс только что прочитанный символ сообщения, кодер выдает код, который состоит из индекса совпадения и следующего за ним символа, который нарушил совпадение строк. Новая фраза, состоящая из индекса совпадения и следующего за ним символа, прибавляется в словарь. В следующий раз, если эта фраза появится в сообщении, она может быть использована для построения более длинной фразы, что повышает меру сжатия информации.
Алгоритм LZW построен вокруг таблицы фраз (словаря), которая заменяет строки символов сжимаемого сообщения в коды фиксированной длины. Таблица имеет так называемое свойством опережения, то есть для каждой фразы словаря, состоящей из некоторой фразы w и символа К, фраза w тоже заносится в словарь. Если все части словаря полностью заполнены, кодирование перестает быть адаптивным (кодирование происходит исходя из уже существующих в словаре фраз).
Алгоритмы сжатия этой группы наиболее эффективны для текстовых данных больших объемов и малоэффективны для файлов маленьких размеров (за счет необходимости сохранение словаря)
Ошибки при передаче информации
Случайные ошибки в работе электронных схем, частички пыли на магнитной поверхности диска, фоновое радиационное излучение – вот только несколько причин, по которым могут появляться ошибки при передаче, записи и чтении данных. Существующие технологии обнаружения и исправления таких ошибок используются на аппаратном уровне и для пользователей остаются незаметными. Рассмотрим некоторые такие методы.
Биты четности
Использование битов четности (контрольных битов) является типовым решением для основной памяти. Принцип состоит в том, что если каждая обрабатываемая битовая комбинация будет содержать нечетное количество единиц, то обнаружение комбинации с четным количеством единиц будет свидетельствовать об ошибке. Реализация принципа достигается добавлением к уже существующему коду дополнительного бита, который устанавливается либо в 1, либо в 0 так, чтобы общее количество единиц в комбинации стало нечетным. Обычно этот бит четности является старшим битом. В результате, например, 8-ми разрядный код ASCII становится 9-ти разрядным и символ ‘A’ будет представлен как 1 01000001, а символ ‘F’ как 0 01000110, так что в обоих случаях количество единиц нечетно. При записи информации схема управления памятью автоматически добавляет контрольный бит. При считывании информации схема управления памятью подсчитывает количество единиц. Если ошибка не обнаружена, контрольный бит удаляется и образуется исходная комбинация. В противном случае считанное значение возвращается с указанием, что оно искажено.
Длинные битовые комбинации могут дополняться группой контрольных битов, образующих контрольный байт. На этой основе создаются схемы контроля, называемые методом контрольных сумм и методом использования кода циклического контроля избыточности. Эти методы позволяют обнаружить ошибку, но не могут ее исправить.
Коды с исправлением ошибок
Принцип действия основан на применении кодировок с достаточно длинными дистанциями Хэмминга (R.W. Hamming ‑ первый исследователь в области разработки кодов с исправлением ошибок). Дистанция Хэмминга между двумя битовыми комбинациями равна количеству битов, отличающихся в этих комбинациях. Пусть, например,
| Символ
| Код
| Дистанция Хэмминга
|
| A
|
|
|
|
|
|
|
| B
|
|
|
|
|
|
|
| C
|
|
|
|
|
|
|
| D
|
|
|
|
|
|
|
| E
|
|
|
|
|
|
|
| F
|
|
|
|
|
|
|
| G
|
|
|
|
|
|
|
| H
|
|
|
Если в результате сбоя в одиночном бите появится ошибка, она легко будет установлена, так как получившаяся комбинация не будет допустимой. В любой комбинации надо будет «испортить» не меньше трех битов. Кроме того, исправить ошибку будет нетрудно. Надо только просмотреть допустимые комбинации и найти ту из них, которая находится на дистанции, равной единице от имеющейся комбинации. Например, недопустимый код 101111 находится на единичной дистанции от 001111, кодирующей символ B. Значит, можно сделать вывод, что 101111 – это ошибочный код для B и исправить ошибку. Чем больше дистанция Хэмминга, тем больше ошибок можно обнаружить и исправить. Разработка эффективных кодов с достаточно длинными дистанциями Хэмминга невозможна без знания алгебраической теории кодирования, которая является частью линейной алгебры и теории матриц.
Методы коррекции ошибок широко используются в драйверах магнитных дисков большой емкости, чтобы снизить вероятность искажения хранимой информации в результате дефектов поверхности диска. Формат CD-ROM (и прочие) также имеет средства, позволяющие снизить вероятность появления ошибок (до одной на 20000 компакт-дисков).
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух слов одинаковой длины различны. В более общем случае расстояние Хэмминга применяется для строк одинаковой длины любых q -ичных алфавитов и служит метрикой различия (функцией, определяющей расстояние в метрическом пространстве) объектов одинаковой размерности.
Первоначально метрика была сформулирована Ричардом Хэммингом во время его работы в Bell Labs для определения меры различия между кодовыми комбинациями (двоичными векторами) в векторном пространстве кодовых последовательностей, в этом случае расстоянием Хэмминга  между двумя двоичными последовательностями (векторами)
между двумя двоичными последовательностями (векторами)  и
и 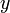 длины
длины 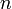 называется число позиций, в которых они различны — в такой формулировке расстояние Хэмминга вошло в словарь алгоритмов и структур данных национального института стандартов и технологий США (англ. NIST Dictionary of Algorithms and Data Structures). Расстояние Хэмминга является частным случаем метрики Минковского:
называется число позиций, в которых они различны — в такой формулировке расстояние Хэмминга вошло в словарь алгоритмов и структур данных национального института стандартов и технологий США (англ. NIST Dictionary of Algorithms and Data Structures). Расстояние Хэмминга является частным случаем метрики Минковского:
 .
.
Примеры
Свойства
Расстояние Хэмминга обладает свойствами метрики, удовлетворяя следующим условиям:













