

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Топ:
Оснащения врачебно-сестринской бригады.
Характеристика АТП и сварочно-жестяницкого участка: Транспорт в настоящее время является одной из важнейших отраслей народного...
Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда...
Интересное:
Инженерная защита территорий, зданий и сооружений от опасных геологических процессов: Изучение оползневых явлений, оценка устойчивости склонов и проектирование противооползневых сооружений — актуальнейшие задачи, стоящие перед отечественными...
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
ТЕОРИЯ КОДИРОВАНИЯ
Теория информации — раздел прикладной математики, радиотехники (теория обработки сигналов) и информатики, относящийся к измерению количества информации, её свойств и устанавливающий предельные соотношения для систем передачи данных. Как и любая математическая теория, теория оперирует математическими моделями, а не реальными физическими объектами (источниками и каналами связи). Использует, главным образом, математический аппарат теории вероятностей и математической статистики.
Отцом теории информации принято считать Клода Шеннона1948, который, начав с углубленного изучения математической статистики, предоставил инженерам полное определение ёмкости коммуникационного канала. Его теория не рассматривает содержание передаваемого сообщения и не обращает особого внимания на процессы передачи информации, но старается оптимизировать процессы сжатия сообщения с небольшими потерями, что требует применения критерия точности. Задача перекодировки информации - как можно больше уменьшить первоначальный объём предоставленных данных. Цель таких усилий – оптимизация режимов эксплуатации устройств, предназначенных для хранения и передачи информации.
Основные разделы теории информации — Информация и ее свойства, Системы счисления, Измерение информации, алгоритмы кодирования, Основы передачи данных, алгоритмы сжатия и архивации информации.
Область действия теории кодирования распространяется на передачу данных по реальным (или зашумленным) каналам, а предметом является обеспечение корректности переданной информации. Иными словами, она изучает, как лучше упаковать данные, чтобы после передачи сигнала из данных можно было надежно и просто выделить полезную информацию.
|
|
Иногда теорию кодирования путают с шифрованием, но это неверно: криптография решает обратную задачу, ее цель – затруднить получение информации из данных.
Круг задач теории информации представляется с помощью структурной схемы, типичной системы передачи или хранения информации.
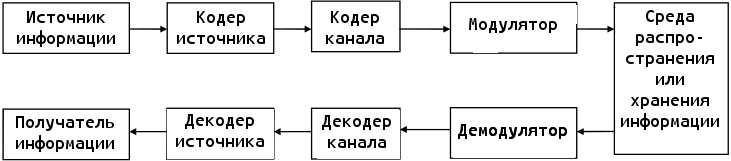
Схема системы связи
Информация поступает в систему в форме сообщений. Под сообщением понимают совокупность знаков или первичных сигналов, содержащих информацию. Источник сообщений в общем случае образует совокупность источника информации (ИИ) (исследуемого или наблюдаемого объекта) и первичного преобразователя (ПП) (датчика, человека-оператора и т.д.), воспринимающего информацию о протекающем в нем процессе.
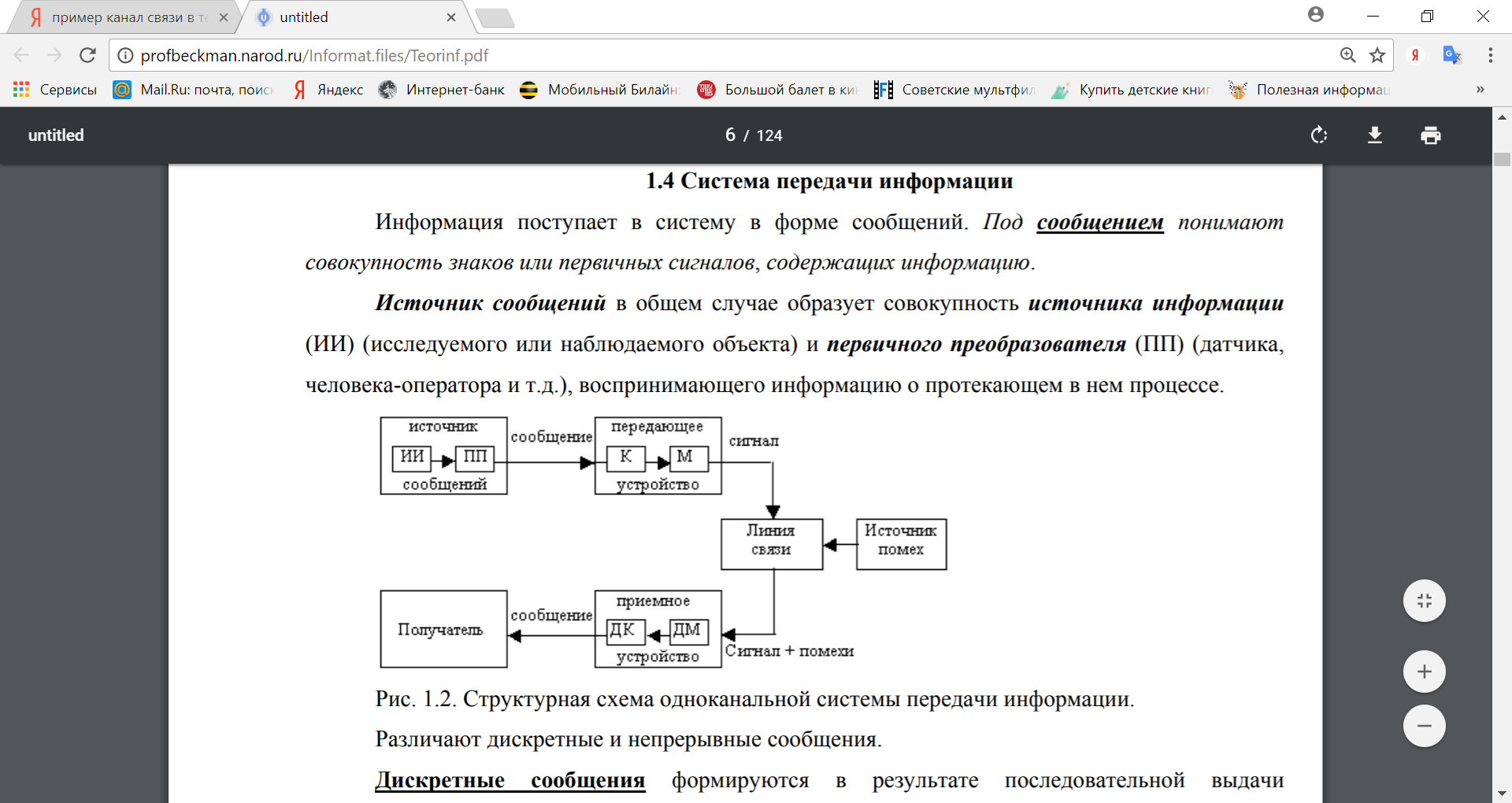
В схеме источником является любой объект вселенной, порождающий сообщения, которые должны быть перемещены в пространстве и времени. Независимо от изначальной физической природы, все подлежащие передаче сообщения обычно преобразуются в форму электрических сигналов.
Кодер источника представляет информацию в наиболее компактной форме.
Кодер канала обрабатывает информацию для защиты сообщений от помех при передаче по каналу связи или возможных искажений при хранении информации.
Модулятор преобразовывает сообщения, формируемые кодером канала, в сигналы, согласованные с физической природой канала связи или средой накопителя информации.
Среда распространения информации (канал связи) вносит в процесс передачи информации случайный шум, который искажает сообщение и тем самым затрудняет его прочтение.
Блоки, расположенные на приёмной стороне, выполняют обратные операции и предоставляют получателю информацию в удобном для восприятия виде.
Трудность передачи сообщения не зависит от его содержания, так передавать бессмысленные сообщения не менее трудно, чем осмысленные.
Основные разделы «Теория кодирования» — кодирование источника (сжимающее кодирование) и канальное (помехоустойчивое) кодирование.
|
|
В общем случае кодирование информации источника имеет две цели: сжатие информации (в том числе - архивация), чтобы передать большее количество информации за единицу времени; шифрование информации с целью защиты информации от несанкционированного доступа к ней. Первоначально рассмотрим сжатие информации, которое будем называть далее кодированием информации источника. Шифрование, которое будем называть криптографией, рассмотрим позднее.
Сжатие данных (англ. data compression) — алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма. Применяется для более рационального использования устройств хранения и передачи данных. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией).
Сжатие основано на устранении избыточности, содержащейся в исходных данных. Простейшим примером избыточности является повторение в тексте фрагментов (например, слов естественного или машинного языка). Подобная избыточность обычно устраняется заменой повторяющейся последовательности ссылкой на уже закодированный фрагмент с указанием его длины. Другой вид избыточности связан с тем, что некоторые значения в сжимаемых данных встречаются чаще других. Сокращение объёма данных достигается за счёт замены часто встречающихся данных короткими кодовыми словами, а редких — длинными (энтропийное кодирование).
Примерами кодирования источников могут служить передача связанного текста кодом Морзе, оцифровка аудио сигнала при записи на компакт диски. При кодировании источников избыточность сообщения снижается и такое кодирование часто называют сжатием данных.
Кодирование каналов, наоборот, увеличивает избыточность сообщений. Внесение дополнительных проверочных символов позволяет обнаруживать и даже исправлять ошибки, возникающие при передаче информации по каналу.
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
|
|
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Кодирование канала называют помехоустойчивым кодированием. Без помехоустойчивого кодирования было бы невозможным создание накопителей огромной емкости, таких, как CD-ROM, DVD ил жестких дисков. Дополнительные затраты на помехоустойчивое кодирование, которое обеспечивает приемлемые вероятности ошибок записи/чтения, становятся пренебрежимо малыми по сравнению с выигрышем от достигаемой при этом плотности записи. Рассмотренные примеры показывают, что информация и кодирование являются центральным понятиями, без которых современная информационная техника просто не существовала бы.
Необходимость кодирования информации возникла задолго до появления компьютеров. Речь, азбука и цифры – есть не что иное, как система моделирования мыслей, речевых звуков и числовой информации. В технике потребность кодирования возникла сразу после создания телеграфа более 150 лет назад, но особенно важной она стала с изобретением компьютеров.
Каналы были дороги и ненадежны, что сделало актуальной задачу минимизации стоимости и повышения надёжности передачи телеграмм. Проблема ещё более обострилась в связи с прокладкой трансатлантических кабелей. С 1845 вошли в употребление специальные кодовые книги; с их помощью телеграфисты вручную выполняли «компрессию» сообщений, заменяя распространенные последовательности слов более короткими кодами. Тогда же для проверки правильности передачи стали использовать контроль чётности, метод, который применялся для проверки правильности ввода перфокарт ещё и в компьютерах первых поколений. Для этого во вводимую колоду последней вкладывали специально подготовленную карту с контрольной суммой. Если устройство ввода было не слишком надежным (или колода – слишком большой), то могла возникнуть ошибка. Чтобы исправить её, процедуру ввода повторяли до тех пор, пока подсчитанная контрольная сумма не совпадала с суммой, сохраненной на карте. Эта схема неудобна, и к тому же пропускает двойные ошибки. С развитием каналов связи потребовался более эффективный механизм контроля.
|
|
Первым теоретическое решение проблемы передачи данных по зашумленным каналам предложил Клод Шеннон, основоположник статистической теории информации. Работая в Bell Labs, Шеннон написал работу «Математическая теория передачи сообщений» (1948), где показал, что если пропускная способность канала выше энтропии источника сообщений, то сообщение можно закодировать так, что оно будет передано без излишних задержек. В одной из теорем Шеннон доказал, что при наличии канала с достаточной пропускной способностью сообщение может быть передано с некоторыми временными задержками. Кроме того, он показал возможность достоверной передачи при наличии шума в канале.
Формула C = W log ((P+N)/N), высечена на памятнике Шеннону, установленном в его родном городе в штате Мичиган.
Труды Шеннона дали пищу для множества дальнейших исследований в области теории информации, но практического инженерного приложения они не имели.
Переход от теории к практике стал возможен благодаря усилиям Ричарда Хэмминга, коллеги Шеннона по Bell Labs, получившего известность за открытие класса кодов «коды Хэмминга». Существует легенда, что к изобретению своих кодов Хэмминга подтолкнуло неудобство в работе с перфокартами на релейной счетной машине Bell Model V в середине 40-х годов. Ему давали время для работы на машине в выходные дни, когда не было операторов, и ему самому приходилось возиться с вводом. Хэмминг предложил коды, способные корректировать ошибки в каналах связи, в том числе и в магистралях передачи данных в компьютерах, прежде всего между процессором и памятью. Коды Хэмминга показали, как можно практически реализовать возможности теоремы Шеннона. Хэмминг опубликовал свою статью в 1950, хотя во внутренних отчетах его теория кодирования датируется 1947. Поэтому некоторые считают, что отцом теории кодирования следует считать Хэмминга, а не Шеннона.
Ричард Хэмминг (1915- 1998) получил степень бакалавра в Чикагском университете в 1937. В 1939 он получил степень магистра в Университете Небраски, а степень доктора по математике – в Университете Иллинойса. В 1945 Хэмминг начал работать в рамках Манхэттенского проекта. В1946 поступил на работу в Bell Telephone Laboratories, где работал с Шенноном. В 1976 получил кафедру в военно-морской аспирантуре в Монтерей в Калифорнии. Труд, сделавший его знаменитым, фундаментальное исследование кодов обнаружения и исправления ошибок, Хэмминг опубликовал в 1950. В 1956 он принимал участие в работе над IBM 650. Его работы заложили основу языка программирования, который позднее эволюционировал в языки программирования высокого уровня. В знак признания заслуг Хэмминга в области информатики институт IEEE учредил медаль за выдающиеся заслуги в развитии информатики и теории систем, которую назвал его именем.
|
|
Хэмминг первым предложил «коды с исправлением ошибок» (Error-Correcting Code, ECC). Современные модификации этих кодов используются во всех системах хранения данных и для обмена между процессором и оперативной памятью. Один из их вариантов, коды Рида-Соломона применяются в компакт-дисках, позволяя воспроизводить записи без скрипов и шумов, вызванных царапинами и пылинками. Существует множество версий кодов, построенных «по мотивам» Хэмминга, они различаются алгоритмами кодирования и количеством проверочных битов. Особое значение подобные коды приобрели в cвязи с развитием дальней космической связи с межпланетными станциями.
Среди новейших кодов ECC следует назвать коды LDPC (Low-Density Parity-check Code). Вообще-то они известны лет тридцать, но особый интерес к ним обнаружился именно в последние годы, когда стало развиваться телевидение высокой чёткости. Коды LDPC не обладают 100-процентной достоверностью, но вероятность ошибки может быть доведена до желаемой, и при этом с максимальной полнотой используется пропускная способность канала. К ним близки «турбокоды» (Turbo Code), они эффективны при работе с объектами, находящимися в условиях далекого космоса и ограниченной пропускной способности канала.
В историю теории кодирования прочно вписано имя Владимир Александрович Котельникова ( 1908-2005 ). В 1933 в «Материалах по радиосвязи к I Всесоюзному съезду по вопросам технической реконструкции связи» он опубликовал работу «О пропускной способности «эфира» и «проволоки». Имя Котельникова входит в название одной из важнейших теорем теории кодирования, определяющей условия, при которых переданный сигнал может быть восстановлен без потери информации. Эту теорему называют по-разному, в том числе «теоремой WKS» (аббревиатура WKS взята от Whittaker, Kotelnikov, Shannon). В некоторых источниках используют и Nyquist-Shannon sampling theorem, и Whittaker-Shannon sampling theorem, а в отечественных вузовских учебниках чаще всего встречается просто «теорема Котельникова». На самом же деле теорема имеет более долгую историю. Ее первую часть в 1897 доказал французский математик Э. Борель. Свой вклад в 1915 внес Э. Уиттекер. В 1920 японец К. Огура опубликовал поправки к исследованиям Уиттекера, в 1928 американец Гарри Найквист уточнил принципы оцифровки и восстановления аналогового сигнала.
ТЕОРИЯ КОДИРОВАНИЯ
К основным задачам, решаемым в данном разделе, необходимо отнести следующие:
· разработка принципов наиболее экономичного кодирования информации;
· согласование параметров передаваемой информации с особенностями канала связи;
· разработка приемов, обеспечивающих надежность передачи информации по каналам связи, т.е. отсутствие потерь информации.
Две последние задачи связаны с процессами передачи информации. Первая же задача – кодирование информации – касается не только передачи, но и обработки, и хранения информации, т.е. охватывает широкий круг проблем; частным их решением будет представление информации в компьютере. С обсуждения этих вопросов и начнем освоение теории кодирования.
Основные определения
Хотя естественной для органов чувств человека является аналоговая форма, универсальной все же следует считать дискретную форму представления информации с помощью некоторого набора знаков.
Знак - соглашение (явное или неявное) о приписывании чему-либо (означающему) какого-либо определённого смысла (означаемого), это материально выраженная замена предметов, явлений, понятий в процессе обмена информацией. Знак может быть составным, то есть состоять из нескольких других знаков. Буквы человеческого языка, цифры и числа являются знаками. Наука о знаковых системах называется семиотикой.
Алфавит - совокупность графических знаков — букв (латинский, русский), расположенных в традиционно установленном порядке.
Сообщение – последовательность знаков алфавита.
Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем, называются шенноновскими, а порождающий их отправитель – шенноновским источником. Если сообщение является шенноновским, то набор знаков (алфавит) и вероятности их появления в сообщении могут считаться известными заранее. В этом случае, с одной стороны, можно предложить оптимальные способы кодирования, уменьшающие суммарную длину сообщения при передаче по каналу связи. С другой стороны, интерпретация сообщения, представляющего собой последовательность сигналов, сводится к задаче распознавания знака, т.е. выявлению, какой именно знак находится в данном месте сообщения.
Сообщения (а также источники, их порождающие), в которых существуют статистические связи (корреляции) между знаками или их сочетаниями, называются сообщениями (источниками) с памятью или марковскими сообщениями (источниками).
Учёт в английских словах двух буквенных сочетаний понижает среднюю информацию на знак до значения I2(e)=3,32 бит, учёт трехбуквенных – до I3(e)=3,10 бит. Шеннон сумел приблизительно оценить I5(e)=2,1 бит, I8(e)=1,9 бит. Аналогичные исследования для русского языка дают: I2(r) = 3,52 бит; I3(r)= 3,01 бит.
Последовательность I0,I1, I2... является убывающей в любом языке. Экстраполируя её на учёт бесконечного числа корреляций, можно оценить предельную информацию на знак в данном языке I∞, которая будет отражать минимальную неопределенность, связанную с выбором знака алфавита без учета семантических особенностей языка, в то время как I0 является другим предельным случаем, поскольку характеризует наибольшую информацию, которая может содержаться в знаке данного алфавита. Шеннон ввел величину, которую назвал относительной избыточностью языка:
I∞
R =1 - --- (1.18)
I0
Избыточность является мерой бесполезно совершаемых альтернативных выборов при чтении текста, эта величина показывает, какую долю лишней информации содержат тексты данного языка.
Исследования Шеннона для английского языка дали значение I∞≈1,4÷1,5 бит, что по отношению к I0=4,755 бит создает избыточность 0,68. Подобные оценки показывают, что и для других европейских языков, в том числе русского, избыточность составляет 60 – 70%. Это означает, что возможно почти трехкратное (!) сокращение текстов без ущерба для их содержательной стороны и выразительности.
Например, телеграфные тексты делаются короче за счёт отбрасывания союзов и предлогов без ущерба для смысла; в них же используются однозначно интерпретируемые сокращения «ЗПТ» и «ТЧК» вместо полных слов (эти сокращения приходится использовать, поскольку знаки «.» и «,» не входят в телеграфный алфавит).
Однако такое «экономичное» представление слов снижает разборчивость языка, уменьшает возможность понимания речи при наличии шума (а это одна из проблем передачи информации по реальным линиям связи), а также исключает возможность локализации и исправления ошибки (написания или передачи) при её возникновении. Именно избыточность языка позволяет легко восстановить текст, даже если он содержит большое число ошибок или не полон. В этом смысле избыточность есть определенная страховка и гарантия разборчивости.
На практике учёт корреляций в сочетаниях знаков сообщения весьма затруднителен, поскольку требует объемных статистических исследований текстов. Кроме того, корреляционные вероятности зависят от характера текстов и целого ряда иных их особенностей.
По этим причинам в дальнейшем мы ограничим себя рассмотрением только шенноновских сообщений, т.е. будем учитывать различную (априорную) вероятность появления знаков в тексте, но не их корреляции.
Кодирование сигнала – это его представление в определенной форме, удобной для последующего использования сигнала, т.е. это правило, описывающее отображение одного набора знаков в другой набор знаков.
Отображаемый набор знаков называется исходным алфавитом, а набор знаков, который используется для отображения, - кодовым алфавитом, или алфавитом для кодирования. При этом кодированию подлежат как отдельные символы исходного алфавита, так и их комбинации. Аналогично для построения кода используются как отдельные символы кодового алфавита, так и их комбинации. Например, дана таблица соответствия между натуральными числами трёх систем счисления. Эту таблицу можно рассматривать как некоторое правило, описывающее отображение набора знаков десятичной системы счисления в двоичную и шестнадцатеричную. Тогда исходный алфавит - десятичные цифры от 0 до 9, а кодовые алфавиты - это 0 и 1 для двоичной системы; цифры от 0 до 9 и символы {A, B, C, D, E, F} - для шестнадцатеричной.
Исходным символом называется символ (или комбинация символов) исходного алфавита, которому соответствует кодовая комбинация. Например, поскольку 8 = 10002 и 8 является исходным символом, 1000 – это кодовая комбинация, или код, для числа 8.
Кодовой комбинацией называется совокупность символов кодового алфавита, применяемых для кодирования одного символа (или одной комбинации символов) исходного алфавита. При этом кодовая комбинация может содержать один символ кодового алфавита.
Совокупность кодовых комбинаций называется кодом.
Взаимосвязь символов (или комбинаций символов, если кодируются не отдельные символы) исходного алфавита с их кодовыми комбинациями составляет таблицу соответствия (таблицу кодов).
Обратная процедура получения исходных символов по кодам символов называется декодированием. Очевидно, для выполнения правильного декодирования код должен быть однозначным, т.е. одному исходному символу должен соответствовать точно один код и наоборот.
Кодирование информации распадается на этапы:
1) Определение объёма информации, подлежащей кодированию
2) Классификация и систематизация информации.
3) Выбор системы кодирования и разработка кодовых обозначений
4) Непосредственное кодирование.
В теории информации можно выделить следующие методы кодирования:
1. Кодирование дискретных источников. Это гипотетическая модель кодирования информации «без потерь», которая проходит через канал связи без шума, сжатием информации.
2. Кодирование информации при её передаче по каналу с шумом. Этот метод учитывает и защищает информацию от помех в канале связи.
3. Кодирование с заданным критерием качества. Ввиду того, что информация аналоговых источников не может быть представлена в цифровой форме без искажений, этот метод кодирования обеспечивает наилучший компромисс между качеством и затратами на передачу информации. Он используется в случае, когда кодирование источника осуществляется таким образом, что закодированные сообщения восстанавливаются с некоторой ошибкой, не большей заданного значения. Один из наиболее актуальных методов кодирования, поскольку находит широкое применение для цифровой передачи аудио- и видеоинформации.
4. Кодирование информации для систем со многими пользователями описывает оптимальное взаимодействие абонентов, использующих общий ресурс, например, канал связи.
5. Секретная связь, системы защиты информации от несанкционированного доступа. Этот тип активно используются и является актуальным. Затрагивает теорию информации, теории вычислительной мощности алгоритмов, исследования операций, теории чисел.
В зависимости от целей кодирования, различают следующие его виды:
- кодирование по образцу – используется всякий раз при вводе информации в компьютер для её внутреннего представления;
Данный вид кодирования применяется для представления дискретного сигнала на том или ином машинном носителе. Большинство кодов имеют одинаковую длину и используют двоичную систему для представления кода (и, возможно, шестнадцатеричную как средство промежуточного представления). Рассмотрим виды таких кодов: прямые; ASCII-коды; коды Грея; коды, учитывающие частоту символов; код Штибица.
- криптографическое кодирование, или шифрование, – используется для защиты сообщений от несанкционированного доступа. В качестве символов кодирования могут использоваться как символы произвольного алфавита, так и двоичные коды. Существуют различные методы, рассмотрим два из них: метод простой подстановки и метод Вижинера.
- эффективное, или оптимальное, кодирование – используется для устранения избыточности информации, т.е. снижения ее объема, например, в архиваторах;
- помехозащитное, или помехоустойчивое кодирование – применяется для обнаружения и/или исправления ошибок, которые могут возникнуть в дискретном сигнале при его передаче по каналам связи, используется для обеспечения заданной достоверности в случае, когда на сигнал накладывается помеха, например, при передаче информации по каналам связи. В качестве базового кода, который подвергается помехозащитному кодированию, используется двоичный код постоянной длины.
Эффективное кодирование
В 1940-х гг., Клод Шеннон ввёл понятие пропускной способности канала, которое базировалось на идеях Найквиста и Хартли, а затем сформулировал теорию передачи информации.
Количество нужной человеку информации неуклонно растет. Объемы устройств для хранения данных и пропускная способность линий связи также растут. Однако количество информации растет быстрее. У этой проблемы есть три решения. Первое - ограничение количества информации. К сожалению, оно не всегда приемлемо. Например, для изображений это означает уменьшение разрешения, что приведет к потере мелких деталей и может сделать изображения вообще бесполезными (например, для медицинских или космических изображений). Второе — увеличение объема носителей информации и пропускной способности каналов связи. Это решение связано с материальными затратами, причем иногда весьма значительными. Третье решение - использование сжатия информации. Это решение позволяет в несколько раз сократить требования к объему устройств хранения данных и пропускной способности каналов связи без дополнительных издержек (за исключением издержек на реализацию алгоритмов сжатия). Условиями его применимости является избыточность информации и возможность установки специального программного обеспечения либо аппаратуры как вблизи источника, так и вблизи приемника информации. Как правило, оба эти условия удовлетворяются.
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и на сколько та или иная информация при этом сожмется.
Рассмотрим две фундаментальные теоремы идеального кодирования, носящие имя Шеннона. Первая из них рассматривает случай отсутствия помех в канале, вторая учитывает наличие помех, приводящих к ошибкам.
Я теорема Шеннона
Если пропускная способность канала связи без помех больше энтропии источника информации в единицу времени  , то всегда можно закодировать достаточно длинное сообщение так, чтобы оно передавалось каналом связи без задержки. Если же, напротив,
, то всегда можно закодировать достаточно длинное сообщение так, чтобы оно передавалось каналом связи без задержки. Если же, напротив,
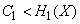 , то передача информации без задержек невозможна.
, то передача информации без задержек невозможна.
Первая теорема Шеннона: если пропускная способность канала без помех превышает производительность источника сообщений, т.е. удовлетворяется условие Ck >Vu, то существует способ кодирования и декодирования сообщений источника, обеспечивающий сколь угодно высокую надежность передачи сообщений. В противном случае, т.е. если Ck <Vu такого способа нет.
Первая теорема Шеннона утверждает, что безошибочная передача сообщений определяется соотношением Н и C.
_____________________
Очевидно, что если выполняется условие >, то канал успевает передать все сообщения, поступающие на его вход от источника, и передача будет вестись без искажений.
Что произойдет, если <? Можно ли в этом случае обеспечить передачу без искажений? Если исходить только из технических характеристик, то, очевидно, нельзя. А если учесть информационные характеристики? Ведь нам известно, что если последовательность обладает информационной избыточностью, то её можно сжать, применив методы экономного кодирования.
Таким образом, идеальное кодирование по Шеннону представляет собой экономное кодирование последовательности сообщений при безграничном укрупнении сообщений. Такой способ кодирования характеризуется задержкой сообщений, поскольку кодирование очередной типичной последовательности может начаться только после получения последовательности источника длительностью L, а декодирование — только когда принята последовательность из канала той же длительности L. Поскольку требуется t, то идеальное кодирование требует бесконечной задержки передачи информации. В этом причина технической нереализуемости идеального кодирования по Шеннону. Тем не менее, значение этого результата, устанавливающего предельные соотношения информационных характеристик источника и канала для безошибочной передачи сообщений, весьма велико. Исторически именно теорема Шеннона инициировала и определила развитие практических методов экономного кодирования. Шеннон предложил метод такого кодирования, который получил название оптимального кодирования. В дальнейшем идея такого кодирования была развита в работах Фано и Хаффмана.
При отсутствии помех ошибки при передаче могут возникать только за счет неоднозначного кодирования сообщений.
Далее ограничим себя ситуацией, когда M = 2, т.е. для представления кодов в линии связи используется лишь два типа сигналов – с практической точки зрения это наиболее просто реализуемый вариант (например, существование напряжения в проводе (будем называть это импульсом) или его отсутствие (пауза); наличие или отсутствие отверстия на перфокарте или намагниченной области на дискете); подобное кодирование называется двоичным. Знаки двоичного алфавита принято обозначать «0» и «1», но нужно воспринимать их как буквы, а не цифры. Удобство двоичных кодов и в том, что при равных длительностях и вероятностях каждый элементарный сигнал (0 или 1) несет в себе 1 бит информации (log2M=1);
тогда первая теорема Шеннона получает следующую интерпретацию:
При отсутствии помех передачи средняя длина двоичного кода может быть сколь угодно близкой к средней информации, приходящейся на знак первичного алфавита.
Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Он предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0.6 — 1.3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение.
Для кодирования символов исходного алфавита используют двоичные коды переменной длины: чем больше частота символа, тем короче его код.
Эффективность кода определяется средним числом двоичных разрядов для кодирования одного символа – I ср по формуле
к
Iср = ∑ fi ni,
i=1
где k – число символов исходного алфавита; ni – число двоичных разрядов для кодирования символа; fi частота символа; причем ∑f i= 1.
При эффективном кодировании существует предел сжатия, ниже которого не «спускается» ни один метод эффективного кодирования - иначе будет потеряна информация. Этот параметр определяется предельным значением двоичных разрядов возможного эффективного кода – Iпр:
n
Iпр = - ∑ f i log2 f i,
i =1
где n – мощность кодируемого алфавита, f i – частота i-го символа кодируемого алфавита.
Первые алгоритмы сжатия были примитивными в связи с тем, что была примитивной вычислительная техника. С развитием мощностей компьютеров стали возможными все более мощные алгоритмы. Настоящим прорывом было изобретение Лемпелем и Зивом в 1977 г. словарных алгоритмов. До этого момента сжатие сводилось к примитивному кодированию символов. Словарные алгоритмы позволяли кодировать повторяющиеся строки символов, что позволило резко повысить степень сжатия. Важную роль сыграло изобретение примерно в это же время арифметического кодирования, позволившего воплотить в жизнь идею Шеннона об оптимальном кодировании. Следующим прорывом было изобретение в 1984 г. алгоритма РРМ. Следует отметить, что это изобретение долго оставалось незамеченным. Дело в том, что алгоритм сложен и требует больших ресурсов, в первую очередь больших объемов памяти, что было серьезной проблемой в то время. Изобретенный в том же 1984 г. алгоритм LZW был чрезвычайно популярен благодаря своей простоте, хорошей рекламе и нетребовательности к ресурсам, несмотря на относительно низкую степень сжатия. На сегодняшний день алгоритм РРМ является наилучшим алгоритмом для сжатия текстовой информации, a LZW давно уже не встраивается в новые приложения (однако широко используется в старых).
Именно благодаря необходимости использования сжатия информации методы сжатия достаточно широко распространены. Однако существуют две серьезные проблемы. Во- первых, широко используемые методы сжатия, как правило, устарели и не обеспечивают достаточной степени сжатия. В то же время они встроены в большое количество программных продуктов и библиотек и поэтому будут использоваться еще достаточно долгое время. Второй проблемой является частое применение методов сжатия, не соответствующих характеру данных. Например, для сжатия графики широко используется алгоритм LZW, ориентированный на сжатие одномерной информации, например текста. Решение этих проблем позволяет резко повысить эффективность применения алгоритмов сжатия.
Таким образом, разработка и внедрение новых алгоритмов сжатия, а также правильное использование существующих позволит значительно сократить издержки на аппаратное обеспечение вычислительных систем.
Существуют два классических метода эффективного кодирования:
- метод Шеннона-Фано
- метод Хаффмена.
Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат – эффективные коды.
Принцип построения оптимальных кодов:
1. Каждый элементарный символ должен переносить максимальное количество информации, для этого необходимо, чтобы элементарные символы (0 и 1) в закодированном тексте встречались в среднем одинаково часто. Энтропия в этом случае будет максимальной.
2. Необходимо буквам первичного алфавита, имеющим большую вероятность, присваивать более короткие кодовые слова вторичного алфавита.
Метод Шеннона-Фано
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
Алгоритм Шеннона — Фано использует избыточность сообщения, заключённую в неоднородном распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов — более длинными двоичными последовательностями, образуя коды переменной длины.
Код Шеннона — Фано префиксный, то есть никакое кодовое слово не является частью любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Алгоритм относится к вероятностным методам сжатия.
Основные этапы
1. Символы первичного алфавит
|
|
|

Наброски и зарисовки растений, плодов, цветов: Освоить конструктивное построение структуры дерева через зарисовки отдельных деревьев, группы деревьев...

История развития хранилищ для нефти: Первые склады нефти появились в XVII веке. Они представляли собой землянные ямы-амбара глубиной 4…5 м...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!