Классический алгоритм Хаффмана имеет один существенный недостаток. Дня восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. При передаче закодированных данных требуется также передавать дерево или таблицу частот, чтобы можно было восстановить дерево. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для собственно кодирования.
Виды алгоритма Хаффмана
1) статический
2) динамический (адаптивный)
Динамический - таблица частот вычисляется по тексту. Позволяет строить кодовую схему в поточном режиме (без предварительного сканирования данных), не имея никаких начальных знаний из исходного распределения, что позволяет за один проход сжать данные. Преимуществом этого способа является возможность кодировать на лету.
Статический алгоритм - используется некоторая ранее вычисленная таблица.
Соответственно, для динамического алгоритма требуется два прохода по тексту, первый для построения таблицы, второй − для кодирования.
Динамическое кодиpование имеет пpеимущество по сpавнению со статическим - оно хоpошо пpиспосабливается к быстpо меняющимся данным и нет необходимости хpанить деpево вместе с запакованным тестом.
Для статического алгоритма требуется только один проход, т. к. таблица уже есть. Естественно, при использовании статического алгоритма возникает риск того, что алгоритм будет не эффективен из-за несоответствия реальных частот и значений в таблице.Тем не менее, статический алгоритм можно применять, например, известно, что в обычных текстах (художественная литература, журналы) частоты символов как правило примерно одинаковые для различных текстов.
Адаптивный алгоритм - в этом алгоритме также используется один проход, но при этом дерево постоянно перестраивается, т. е. меняются коды символов.
Пример. Закодировать сообщения по методу Хаффмана (статический алгоритм)
Решение 1. Первый шаг

Вторым шагом производим кодирование, "проходя" по таблице справа налево (обычно это проделывается в одной таблице):

Решение 2. Построение кодового дерева начинается с корня. Двум исходящим из него ребрам приписывается в качестве весов вероятности 0,6 и 0,4, стоящие в последнем столбце. Образовавшимся при этом вершинам дерева приписываются кодовые символы 0 и 1. Далее "идем" по таблице справа налево. Поскольку вероятность 0,6 является результатом сложения двух вероятностей 0,4 и 0,2, из вершины 0 исходят два ребра с весами 0,4 и 0,2 соответственно, что приводит к образованию двух новых вершин с кодовыми символами 00 и 01. Процедура продолжается до тех пор, пока в таблице остаются вероятности, получившиеся в результате суммирования. Построение кодового дерева заканчивается образованием семи листьев, соответствующих данным сообщениям с присвоенными им кодами. Дерево, полученное в результате кодирования по Хаффману, имеет следующий вид:

Листья кодового дерева представляют собой кодируемые сообщения с присвоенными им кодовыми словами. Таблица кодов имеет вид:
| Сообщение
| 1
| 2
| 3
| 4
| 5
| 6
| 7
|
| Код
| 1
| 01
| 0010
| 0011
| 0000
| 00010
| 00011
|
Цена кодирования здесь будет равна

Пример (статистический) построения кодового дерева.
Пусть задана исходная последовательность символов: aabbbbbbbbccсcdeeeee.
Ее исходный объем равен 20 байт (160 бит). В соответствии с приведенными на рис. 41.1 данными (таблица вероятности появления символов, кодовое дерево и таблица оптимальных префиксных кодов)
Следовательно, ее объем будет равен 42 бита. Коэффициент сжатия приближенно равен 3,8.
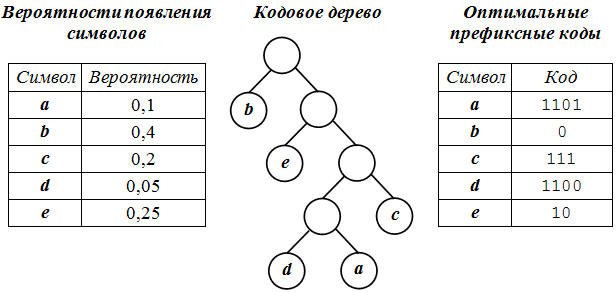
Рис. 41.1. Создание оптимальных префиксных кодов
закодированная исходная последовательность символов будет выглядеть следующим образом:
110111010000000011111111111111001010101010.
Пример: (динамический)
Закодируем строку "Сжатие Хаффмана"
Вначале нужно подсчитать количество вхождений каждого символа в тексте.
| С
| ж
| а
| т
| и
| е
| | Х
| ф
| м
| н
|
| 1
| 1
| 4
| 1
| 1
| 1
| 1
| 1
| 2
| 1
| 1
|
Эта таблица называется "таблица частот".
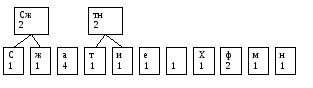
Теперь будем строить дерево
Узел дерева будет образован набором символов и числом - суммарным количеством вхождений данных символов в тексте. Назовем указанное число - весом узла.
Листьями дерева будут узлы, образованные одним символом:

Теперь будем циклически делать следующее:
1) Ищем среди узлов, не имеющих родителя, два узла, имеющих в сумме наименьший вес.
2) Создаем новый узел, его потомками будут два выбранных узла. Его весом будет сумма весов выбранных улов. Его набор символов будет образован в результате объединения наборов символов выбранных узлов.
Создаем первый узел

Создаем еще один узел
Создаем еще один узел
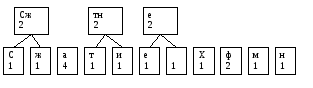
Создаем еще один узел

Создаем еще один узел

Создаем еще один узел

Создаем еще один узел
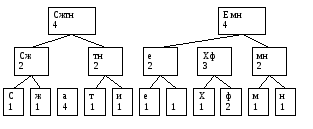
Создаем еще один узел

Создаем еще один узел

Создаем еще один узел

Теперь для каждого узла, имеющего потомков, пометим дуги, идущие вниз, на одной дуге напишем 0, на другой 1.

Теперь, чтобы получить код символа, надо, начиная с корня дерева идти вниз до листа соответствующего данному символу. При этом следует записывать те значения, которые написаны на тех дугах, которые мы проходим.
Получаются следующие коды
| С
| 0001
|
| ж
| 0000
|
| а
| 01
|
| т
| 0010
|
| и
| 0011
|
| е
| 1011
|
| | 1010
|
| Х
| 111
|
| ф
| 110
|
| м
| 1000
|
| н
| 1001
|
Заметим, что код является префиксным, т. е. ни один код символа не является префиксом кода другого символа. Также видно, что для часто встречающихся символов коды короче.
Как будет выглядеть закодированная строка:
| С
| ж
| а
| т
| и
| е
| | Х
| а
| ф
| ф
| м
| а
| н
| а
|
| 0001
| 0000
| 01
| 0010
| 0011
| 1011
| 1010
| 111
| 01
| 110
| 110
| 1000
| 01
| 1001
| 01
|
Т. е.
0001000001001000111011101011101110110100001100101
Задание
Закодируйте по алгоритму Хаффмана строку с вашим именем, отчеством, фамилией, датой и местом рождения (например, «Иванова Наталья Николаевна, 1 января 1990 года, город Тверь»). При кодировании не округляйте частоты менее, чем четыре знака после запятой – сокращение точности понижает эффективность кодирования. Подсчитайте коэффициент сжатия.
Наберите эту же строку в редакторе «Блокнот» и сохраните текст в txt-формате (количество байт в файле должно в точности соответствовать числу знаков – букв, цифр и служебных символов – в строке. Примените к файлу любой архиватор и сравните его степень сжатия с алгоритмом Хаффмана.





