

Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Топ:
Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда...
История развития методов оптимизации: теорема Куна-Таккера, метод Лагранжа, роль выпуклости в оптимизации...
Интересное:
Искусственное повышение поверхности территории: Варианты искусственного повышения поверхности территории необходимо выбирать на основе анализа следующих характеристик защищаемой территории...
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
● Понятие кодирования и определение позиционной системы счисления.
Установление взаимной однозначности состояний источника и сигнала называется кодированием.
Процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
При кодирование любому дискретному сообщению или букве сообщения можно приписывать порядковый номер. Далее числа выражают в какой-либо системе счисления. Таким образом, получают один из кодов, основанных на данной системе счисления.
В позиционной системе счисления значение каждого символа (цифры) зависит от его положения – позиции в ряде символов, представляющих число.
Единица каждого следующего разряда больше единицы предыдущего разряда в m раз, где m – основание системы счисления. Полное число получаем, суммируя значения по разрядам:
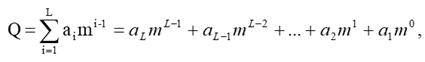
где i – номер разряда данного числа; L – количество разрядов; ai – множитель, принимающий любые целочисленные значения в пределах от 0 до m-1 и показывающий, сколько единиц i-го разряда содержится в числе.
● Двоичный код
Логические элементы, соответствующие двоичной системе, должны иметь всего два устойчивых состояния. В двоичной системе основание m = 2.
● Код Грея
Большое практическое значение имеют также коды, у которых при переходе от одного числа к другому изменение происходит только в одном разряде. Наибольшее распространение получил код Грея, часто называемый циклическим или рефлексно-двоичным. Правила перевода числа из кода Грея в обычный двоичный сводится к следующему: первая единица со стороны старших разрядов остаётся без изменения, последующие цифры (0 и 1) остаются без изменения, если число единиц им предшествовавших, чётно, и инвертируются, если число единиц нечётно.
|
|
Комбинации кода Грея:
| Число в десятичном коде | Код Грея |
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0011 |
| 3 | 0010 |
| 4 | 0110 |
| 5 | 0111 |
| 6 | 0101 |
| 7 | 0100 |
| 8 | 1100 |
| 9 | 1101 |
| 10 | 1111 |
| 11 | 1110 |
| 12 | 1010 |
| 13 | 1011 |
| 14 | 1001 |
| 15 | 1000 |
● Понятие оптимального кодирования
Оптимальное кодирование – это кодирование, когда каждая буква алфавита несёт максимально возможное количество информации, равное логарифму числа букв в алфавите.
● Формула для расчета минимальной средней длины кодового слова
Минимальная средняя длина кодового слова не может быть меньше, чем частное от деления среднего количества информации H(U), приходящегося на одно состояние источника, на максимальное количество информации, приходящееся на одну букву алфавита log m, то есть:
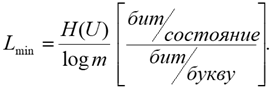
Так:

Оптимальный код Шеннона – Фано.
● Теорема Шеннона о существовании оптимальных кодов.
Теорема Шеннона.
При кодировании множества состояний дискретного источника с энтропией H(U) в алфавите из m букв средняя длина кодового слова не может быть меньше, чем  Если вероятность состояний источника представляет собой целочисленные степени числа букв m (при m = 2, то есть, 2-2, 2-2, 2-3 2-4, и т.д.), то длина кодового слова равна нижней границе.
Если вероятность состояний источника представляет собой целочисленные степени числа букв m (при m = 2, то есть, 2-2, 2-2, 2-3 2-4, и т.д.), то длина кодового слова равна нижней границе.
Если вероятности состояний источника не являются целочисленными степенями числа m, то точное достижение указанной нижней границы в общем случае оказывается невозможным. Однако, при кодировании достаточно длинных последовательностей – блоков, можно приблизить длину кодового слова, приходящегося в среднем на одно состояние, к нижней границе с любой, наперед заданной точностью.
● Алгоритм оптимального кодирования Шеннона – Фано
1. Множество состояний разбивается на две группы, причем, суммарные вероятности групп должны быть равны.
2. Если кодируемое состояние относится к первой группе, то в качестве первой буквы кодового слова берем 0, а для второй группы – 1.
|
|
3. Затем каждая группа разбивается на 2 равные по суммарной вероятности подгруппы и символ 0 берется для первой подгруппы, а символ 1 – для второй подгруппы.
4. Разбиения проводятся до тех пор, пока в подгруппе не останется единственное из кодируемых состояний.
● Расчет минимальной средней длины кодового слова
Минимальная средняя длина кодового слова равна:
● Расчет средней длины кодового слова
Средняя длина кодового слова равна математическому ожиданию индивидуальных длин кодовых слов:
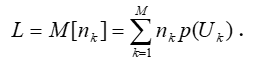
● Расчет избыточности
Избыточность (показывает, на сколько средняя длина кодового слова превышает теоретический минимум) определяется по формуле:

Блочное кодирование.
● Теорема Шеннона о существовании оптимальных кодов(см. 8)
При кодировании множества состояний дискретного источника с энтропией H(U) в алфавите из m букв средняя длина кодового слова не может быть меньше, чем .
Если вероятность состояний источника представляет собой целочисленные степени числа букв m (при m = 2, то есть, 2-2, 2-2, 2-3 2-4, и т.д.), то длина кодового слова равна нижней границе.
Если вероятности состояний источника не являются целочисленными степенями числа m, то точное достижение указанной нижней границы в общем случае оказывается невозможным. Однако, при кодировании достаточно длинных последовательностей – блоков, можно приблизить длину кодового слова, приходящегося в среднем на одно состояние, к нижней границе с любой, наперед заданной точностью.
● Алгоритм кодирования блоками
При кодировании блоками сообщение передается блоками по n сообщений. Число кодовых слов будет равно числу комбинаций из 2-х по n (2 в степени n). Расписываются все возможные блоки и их вероятность рассчитывается как перемножение вероятностей каждого сообщения в блоке. Далее алгоритм аналогичен описанному в п. 9 для кодирования отдельных сообщений.
● Энтропия ансамбля блоков и энтропия, приходящаяся на букву
Энтропия ансамбля блоков (n - число сообщений в блоке):

Тогда энтропия, приходящаяся на одну букву:
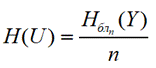
● Средняя длина кодового слова и часть кодового слова, приходящаяся на букву
Средняя длина кодового слова для блока из n сообщений:
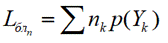
Длина части кодового слова, приходящаяся на одно состояние источника:
|
|
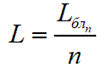
● Расчет избыточности
Избыточность рассчитывается по формуле:
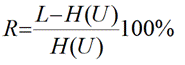
|
|
|

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!