Архитектура простых многопроцессорных систем выполняется по схеме с общей шиной рис 2.6. Два или более процессоров и один или несколько модулей памяти размещены на общей шине. Каждый процессор, для обмена с памятью, проверяет, свободна ли шина, и, если она свободна, он занимает её. Если шина занята, процессор ждёт, пока она освободится. При увеличении числа процессоров производительность системы будет ограничена пропускной способностью шины. Чтобы решить эту проблему каждый процессор снабжается собственной локальной памятью рис. 2.6., куда помещаются тексты исполняемых программ и локальные переменные, обрабатываемые данным процессором.
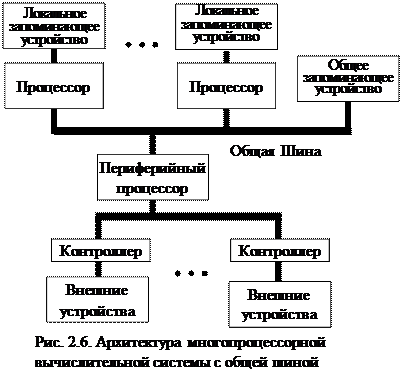
Общее запоминающее устройство используется для хранения общих переменных и общего системного программного обеспечения. При такой организации нагрузка на общую шину значительно снижается.
Один из процессоров выделяется для управления всей системой. Он распределяет задания на исполнение программ между процессорами и управляет работой общей шины.
Периферийный процессор осуществляет обслуживание внешних устройств при вводе и выводе информации из общей памяти. Он может быть того же типа что и остальные процессоры, но обычно устанавливается специализированный процессор, предназначенный для выполнения операций управления внешними устройствами.
Магистральные архитектуры.
Архитектура магистрального суперкомпьютера приведена на рис.2.7. Магистральный принцип является самым распространённым при построении высокопроизводительных вычислительных систем. Компьютер такой системы имеет несколько функциональных обрабатывающих устройств, выполняющих арифметические и логические операции, и быструю регистровую память для хранения обрабатываемых данных. Данные, считанные из памяти, размещаются в регистрах и из них загружаются в обрабатывающие устройства. Результаты вычислений помещаются в регистры и используются, как исходные данные, для дальнейших вычислений. Таким образом, получается конвейер преобразования данных: регистры – обрабатывающие устройства – регистры – ….

Число функциональных устройств, показанных на рисунке, равно шести, "Сложение", "Умножение" и т.д., однако, в реальных системах их количество может быть иным. Устройство планирования последовательности выполнения команд распределяет данные, хранящиеся в регистрах, на функциональные устройства и производит запись результатов снова в регистры. Конечные результаты вычислений записываются в общее запоминающее устройство.
Матричные архитектуры.
В матричной вычислительной системе процессоры объединяются в матрицу процессорных элементов. В качестве процессорных элементов могут использоваться универсальные процессоры, имеющие собственное устройство управления, или вычислители, содержащие только АЛУ и выполняющие команды внешнего устройства управления. Каждый процессорный элемент снабжён локальной памятью, хранящей обрабатываемые процессором данные, но при необходимости процессорный элемент может производить обмен со своими соседями или с общим запоминающим устройством. В первом случае, программы и данные нескольких задач или независимых частей одной задачи загружаются в локальную память процессоров и выполняются параллельно. Во втором варианте все процессорные элементы одновременно выполняют одну и ту же команду, поступающую от устройства обработки команд на все процессорные элементы, но над разными данными, хранящимися в локальной памяти каждого процессорного элемента. Вариант архитектуры с общим управлением показан на рис. 2.8.

Обмен данными с периферийными устройствами выполняется через периферийный процессор, подключённый к общему запоминающему устройству.

Процессор
В ПК имеется одно арифметико-логическое устройство (АЛУ), через которое проходит поток данных, и одно устройство управления (УУ), через которое проходит поток команд — программа. Это однопроцессорный компьютер. АЛУ и УУ в нем объединены в одной сверхбольшой интегральной микросхеме (СБИС) – процессоре, дополнительно в процессоре размещается кэш память (о ней будет сказано позже) и схемы управления процессором и магистралью ввода вывода.
Процессор более полно называется Центральный Микро Процессор – ЦМП (CPU в англ абравеатуре), таким названием мы сразу отличаем его от других устройств обрабатывающих данные, например, видеопроцессор – обрабатывает только видеоданные (при создании изображения на экране монитора) или контроллеры – управляют переферийными устройствами.
В современных компьютерах единицей адресуемой памяти является байт (8 бит - мало), поэтому команды и данные занимают не один байт, группу последовательных байтов, а длина команд переменная (обычно от двух до четырех байтов).
Способы указания адресов переменных весьма разнообразные.
В адресной части команды может быть указан, например:
-сам операнд (число или символ);
-адрес операнда (номер байта, начиная с которого расположен операнд);
-адрес адреса операнда (номер байта, начиная с которого расположен адрес операнда), и др.
В зависимости от количества операндов, команды бывают: одноадресные; двухадресные; трехадресные; нольадресные.
ПРИМЕР. Рассмотрим несколько возможных вариантов команды сложения (англ. add — сложение), при этом вместо цифровых кодов и адресов будем пользоваться условными обозначениями:
-одноадресная команда add x (содержимое ячейки x сложить с содержимым сумматора, а результат оставить в сумматоре);
-двухадресная команда add x, y (сложить содержимое ячеек x и y, а результат поместить в ячейку y);
-трехадресная команда add x, y, z (содержимое ячейки x сложить с содержимым ячейки y, сумму поместить в ячейку z).
Системная магистраль.
В начале 70-х годов фирмой DEC (Digital Equipment Corporation) был предложен принцип модульности в архитектуре СВТ. Он позволял свободно подключать любые периферийные устройства, любое числа датчиков и исполнительных механизмов. Суть его заключалась в том, что все устройства, независимо от их назначения подключались, к общей шине передачи информации (другие ее названия – системная шина, системная магистраль).. Подключение осуществлялось в соответствии со стандартом шины.
К общей шине подключается процессор и все функциональные блоки тоже.
Системная шина конструктивно является набором параллельных проводников, функционально состоит из 3 шин:
-ШД по которой передаются данные;
-ША оперделяет направления данных;
-ШУ сигналы управляющие процессом обмены данными.
Общее управление всей системой осуществляет ЦМП. Он выделяет время другим устройствам для обмена информацией.
Внешние устройства подключаются к шине через– контроллер. Это специальное устройство сходное с ЦПМ, выполняющее (в отличии от ЦМП) очень не большое число команд по управлению данным ПУ. Например, раньше, чтобы распечатать какой либо участок памяти ЦМП проверял готовность принтера, устанавливал пишущий узел в начало строки, изымал из памяти первый символ, печатал, второй, печатал и т.д. Сейчас ЦМП дает контроллеру задание распечатать область в памяти. А контроллер сам проверяет готовность устройства, сам по каналам прямого доступа к памяти обращается к памяти, сам пересылает распечатываемые ячейки к себе в буферную память, сам управляет печатью. ЦМП в это время продолжает работать дальше по прежней программе или по другой, тем повышая эффективность всей системы.


| |
| |  |
Контроллер подключается к шине специальными устройствами – портами ввода-вывода. Каждый порт имеет свой номер, и обращения к нему процессора происходит, так же как и к ячейке памяти, по этому номеру. Процессор имеет специальные линии управления, сигнал на которых определяет, обращается ли процессор к ячейке памяти или к порту ввода-вывода контроллера внешнего устройства.
Принцип открытой архитектуры.
Стандарт шины являлся свободно распространяемым документом, что позволяло фирмам производителям периферийного оборудования разрабатывать контроллеры для подключения своих устройств к шине. Архитектура в дальнейшем стала называться открытой.
Открытая архитектура предоставила большие преимущества:
-модульность дает возможность заменять морально устаревшие блоки (upgrade);
-возможна совместимость устройств выпущенных раньше и позже (хотя и недолгое время, т.е. очень уж старое устройство и не подключишь);
-нелицензированность шины привела к конкуренции, как следствие улучшение соотношения цена-качество, (цена упала – качество улучшилось).
-повысилась эффективность компьютера как системы, т.е. одновременно работают несколько ПУ;
Несмотря на преимущества, предоставляемые архитектурой с общей шиной, она имеет и серьёзный недостаток, который проявлялся всё больше при повышении производительности внешних устройств и возрастании потоков обмена информацией между ними. К общей шине подключены устройства с разными объёмами и скоростью обмена, в связи с чем "медленные" устройства задерживали работу. Вся система работала как самое медленное устройство.
Дальнейшее повышение производительности компьютера было найдено во введении дополнительной локальной шины, к которой подключались "быстрые" устройства.
Конструктивно, контроллер каждого устройства размещается на общей (материнской) плате с ЦМП и ОЗУ. Если устройство не входит стандартно в состав компьютера, контроллер располагается на дочерней плате, вставляемой в разъёмы на материнской плате (слоты расширения).
Дальнейшее развитие микроэлектроники позволило размещать несколько функциональных узлов компьютера и контроллеры стандартных устройств в одной микросхеме СБИС. Это сократило количество микросхем на материнской плате и дало возможность ввести две дополнительные локальные шины для подключения ОЗУ и устройства отображения (они имеют наибольший объём обмена с ЦМП).2.7. Функциональная организация персонального компьютера.
2.7.1. Центральный процессор
Центральный процессор (ЦП, или центральное процессорное устройство — ЦПУ; в английской версии CPU central processing unit) — часть аппаратного обеспечения компьютера, выполняющая операций по заданным программам, управляющая всеми прочими устройствами компьютера. После того как центральный процессор стал выпускаться на одной сверхбольшой интегральной микросхеме, он стал называться – центральным микропроцессором или ЦМП.
Более сорока лет, с появления микросхем, развитие аппаратного обеспечения шло в соответствии с законом технологического прогресса (эмпирическим законом Мура), гласящим, что количество транзисторов на одной микросхеме удваивается каждые 18 месяцев, все эти годы постоянно шла работа над увеличением быстродействия, снижением размеров и энергопотребления.
Миниатюризация и повышение быстродействия не противоречащие требования, поэтому прогресс в этой области так значителен. Наиболее хорошо видно это на примере компьютерных процессоров. Чем меньше размеры проводников в микросхеме, тем меньше они излучают и принимают наведенные электромагнитные колебания. К настоящему времени широко применяются процессоры по 45 нанометровой технологии, вступают 32нм технологии. При уменьшении толщины напыления элементов электронных схем в очень маленьком объеме размещаются десятки и сотни миллионов транзисторов (уже достигнуто значение 1 миллиард), длина проводников уменьшается, что позволяет увеличивать тактовую частоту, а, значит, и быстродействие. Уменьшение сечения проводников приводит к необходимости понижения напряжения, что снижает удельное энергопотребление схемы.


Рис 2.9. Микропроцессоры 8086 (4.77Мгц 29 000 транзисторов) 1978 года и Core i7 2008г (2.66 ГГц – 3.2 ГГц, 45 нм, 731 млн транзисторов).
Рост тактовой частоты сопровождается повышением выделения тепла и превышение тактовой частоты свыше 4ггц требует более эффективных способов охлаждения, чем воздушное, поэтому этот параметр замедлил свой рост. Тактовая частота 3 ггц была достигнута в 2003 году к 2010 году на ПК она не превышает 3.8 ггц.
Системная шина физически представляющая серию параллельных проводников конечно же имеет довольно большую длину и, стало быть, на ней может присутствовать частота ниже чем в процессоре. Частота на шине сейчас держится в рамках 1ггц, а именно по шине происходит обмен процессора (данными адресами и управляющими командами) с ОЗУ и другими устройствами.
Как мы увидели, экстенсивный путь повышения производительности путем увеличения тактовой частоты имеет физические ограничения. Выход из этой ситуации в улучшении организации процесса обработки информации. Например, известно, что обращение к ОЗУ посредством шины довольно длительный процесс. Для ускорения можно вызывать из памяти не одну а несколько команд заранее и хранить их в специальном наборе регистров (буфере выборки команд с упреждением). Таким образом, когда требуется определенная команда, она вызывается прямо из буфера на частоте процессора, а обращения к памяти не происходит.
Далее мы рассмотрим некоторые организационные способы повышения быстродействия.
Конвейерная архитектура.
При выборке с упреждением команда обрабатывается за два шага: сначала происходит вызов команды, а затем — ее выполнение. Еще больше продвинула эту стратегию идея конвейера. Суть конвейера в следующем - в ыполнение каждой команды сопровождается рядом однотипных действий:
1. выборка команды из ОЗУ;
2. дешифровка команды;
3. адресация операнда в ОЗУ;
4. выборка операнда из ОЗУ;
5. выполнение команды;
6. запись результата в ОЗУ.
Выполнение программы в целом пойдет быстрее, если действия будут выполняться отдельными аппаратными компонентами, а в обработке будут находиться несколько команд одновременно, например, результат работы 1-й команды после выполнения отправляется в ОЗУ шестым аппаратным компонентом, в это же время, выполняется 2-я команда пятым компонентом, в это же время, выбираются операнды 3-й команды из ОЗУ, в этоже время, адресуются операнды 4-й команды, в этоже время, дешифруется 5-я команда, в этоже время, выбирается 6-я.
Хотя конвейер может сбиваться, если следующая команда использует результат предыдущей, или команда перехода приведет к очистке конвейера, ускорение от такого приема может быть в десяток раз.
В нашем примере конвейер состоит из шести степеней, но некоторые современные процессоры имеют более 30 ступеней, что увеличивает производительность процессора, однако может приводить к увеличенным промежуткам простоя.
Суперскалярная архитектура.
Если в рамках одного процессора поместить не один конвейер, а несколько, то производительность вырастет на порядки. Общий блок выборки команд вызывает из памяти сразу по две команды и помещает каждую из них в один из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды не должны конфликтовать из-за ресурсов и зависеть от результата выполнения предыдущей, т.е. не всякая задача будет решаться быстрей.
Система команд процессора.
Из первой главы известно, что любая обработка двоичных кодов представляется системой логических функций, каждая из которых может быть реализована аппаратно в виде цифровой схемы. Так можно реализовать простые операции – конъюнкцию, дизъюнкцию, более сложные - сложение, вычитание, или еще более сложные операции по работе с медиаданными. Любую последовательность действий (алгоритм) можно реализовать аппаратно на микропрограммном уровне в виде операции, и любую операцию можно осуществить в виде алгоритма. В этом смысле большой разницы между аппаратным и программным обеспечением нет. Набор выполняемых процессором команд называется системой команд. Какие именно команды войдут в систему команд процессора определяют разработчики процессора в зависимости от задач, которые предполагается решать.
В современных персональных компьютерах разных фирм применяются процессоры двух основных архитектур:
· полный набор команд переменной длины – Complex Instruction Set Computer (CISC);
· сокращённый набор команд фиксированной длины – Reduced Instruction Set Computer (RISC).
Весь ряд процессоров фирмы Intel, устанавливаемых в персональные компьютеры IBM имеют архитектуру CISC, а процессоры Motorola, используемые фирмой Apple для своих персональных компьютеров, имеют архитектуру RISC. Обе архитектуры имеют свои преимущества и недостатки. Так CISC-процессоры имеют обширный набор команд (до 400), из которых программист может выбрать команду наиболее подходящую ему в данном случае. Недостатком этой архитектуры является то, что большой набор команд усложняет внутреннее устройство процессора, увеличивает время исполнения команды на микропрограммном уровне. Команды имеют различную длину и время исполнения.
RISC-архитектура имеет ограниченный набор команд и каждая команда выполняется за один такт работы процессора. Небольшое число команд упрощает устройство управления процессора. К недостаткам RISC архитектуры можно отнести то, что если требуемой команды в наборе нет, программист вынужден реализовать её с помощью нескольких команд из имеющегося набора, увеличивая размер программного кода.
Кэш память процессора .
Для согласования «быстрого» процессора и «медленного» ОЗУ в состав процессора вводят кэш память. Кэш-память используется процессором для хранения самых часто используемых данных, за счет чего, время очередного обращения к ним значительно сокращается. Если емкость оперативной памяти 1 Гб и выше, то кэш у них около 2-8 Мб. Объем ее не велик, кэш первого уровня находится на одном кристалле с процессором и работает на частоте процессора, это устройство значительно повышает быстродействие всей системы. Более подробно о кэш памяти будет сказано ниже в разделе «Память компьютера».
Прерывание процессора.
Основой диалогового режима работы с компьютером являются прерывания работы процессора. При этом выполнение текущей последовательности команд приостанавливается, содержимое регистров запоминается, управление передаётся программе обрабабатывающей это прерывание с возможностью последующего восстановления работы.
В зависимости от источника возникновения сигнала прерывания делятся на аппаратные, программные, внутренние.
Аппаратныепрерывания вызывают события, исходящие от внешних источников движение мыши, нажатие клавиш клавиатуры, таймера, сетевой карты и т.д.
Программные прерывания инициируются исполнением команды в коде программы.
Внутренние прерывания есть результат нарушения каких-то условий работы процессора - деление на ноль или переполнение и т.д.










