Интегральные функции распределения (ИФР), также известные как кумулятивные функции распределения, от англ. CumulativeDistributionFunction (CDF), описывают вероятность, что значение, взятое из распределения, будет меньше x. Как и все распределения вероятностей, их значения лежат в диапазоне между 0 и 1, где 0—это невозможность, а 1—полнаяопределенность. Например, представьте, что я собираюсь бросить шестигранный кубик. Какова вероятность, что выпадет значение меньше 6?
Для уравновешенного кубика вероятность выпадения пятерки или меньшего значения равна  . И наоборот, вероятность, что выпадет единица, равна всего
. И наоборот, вероятность, что выпадет единица, равна всего  . Тройка или меньше соответствуют равным шансам—то есть вероятности 50%.
. Тройка или меньше соответствуют равным шансам—то есть вероятности 50%.
ИФР выпадениячисел на кубике следует той же схеме, что и все ИФР—для чисел на нижнем краю диапазона ИФР близка к нулю, что соответствует низкой вероятности выбора чисел в этом диапазоне или ниже. На верхнем краю диапазона ИФР близка к единице, поскольку большинство значений, взятых из последовательности, будет ниже.
ИФР и квантили тесно друг с другом связаны—ИФР является инверсией квантильнойфункции. Если 0.5-квантиль соответствует значению 1000, тогда ИФР для 1000 составляет 0.5.
Подобно тому, как функцияPandasquantile позволяет нам отбирать значения из распределения в конкретных точках, эмпирическаяИФР empirical_cdfпозволяет нам внести значение из последовательности и вернуть значение в диапазоне между 0 и 1. Это функция более высокого порядка,т.е. она принимает значение (в данном случае последовательность значений) и возвращает функцию, которую потом можно вызывать, сколько угодно, с различными значениями на входе, и возвращая ИФР для каждого из них.
Функции более высокого порядка—это функции, которые принимают или возвращают функции.
Построим график ИФР одновременно для честного и нечестного булочников. Для этих целей можно воспользоваться функцией построениядвумерного графика библиотеки Pandasplot для визуализации ИФР, изобразив на графике исходные данные—то есть выборки из распределений честного и нечестного булочников—в сопоставлении с вероятностями, вычисленными относительно эмпирическойИФР. Функция plot ожидает, что значения x и значения y будут переданы в виде двух раздельных последовательностей значений. Для этих целе мы воспользуемся конструктором таблицы данных PandasDataFrame.
Чтобы изобразить оба распределения на одном графике, мы должны передать функции plot несколько серий. Для многих своих графиковPandasпредоставляет функции, которые позволяют добавлять дополнительные серии. В случае сфункциейplot мы можем присвоить указатель на создаваемый график, присвоив временной переменной (ax) результат первого вызова функции plot, и затем при повторных вызовах указывать эту переменную в именованном аргументе функции (ax=ax). Можно также передать необязательную метку серии. Мы выполним это в следующемнижепримере, чтобы на готовом графике отличить две серии друг от друга. Сначала определим универсальную функцию построения эмпирической ИФР против теоретической, которая получает на вход кортеж из двух серий (tp[1]иtp[3]) и их названий и метки осей, и затем вызовем ее:
defempirical_cdf(x):
"""Вернуть эмпирическую ИФРдляx"""
sx = sorted(x)
return pd.DataFrame({0: sx, 1:sp.arange(len(sx))/len(sx)})
defex_1_23():
'''Показать графики эмпирической ИФР
честного булочника в сопоставлении с нечестным'''
df =empirical_cdf(honest_baker(1000, 30))
df2 = empirical_cdf(dishonest_baker(950, 30))
ax =df.plot(0, 1, label='Честныйбулочник')
df2.plot(0, 1, label='Нечестныйбулочник', grid=True, ax=ax)
plt.xlabel('Весбуханки')
plt.ylabel('Вероятность')
plt.legend(loc='best')
plt.show()
Приведенный выше примерсгенерирует следующий график:
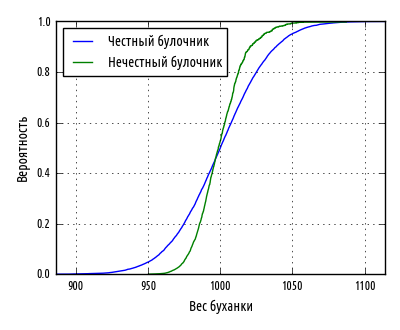
Несмотря на то, что этот график выглядит совсем по-другому, он в сущности показывает ту же самую информацию, что и коробчатая диаграмма. Мы видим, что две линии пересекаются примерно в медиане 0.5, соответствующей 1000 гр. Линия нечестного булочника обрезается в нижнем хвосте и удлиняется на верхнем хвосте, что соответствует асимметричному распределению.
Важность визуализации
Простые приемы визуализации, подобные тем, которые были показаны ранее, позволяют лаконично передать большое количество информации. Они дополняют сводные статистики, которые мы рассчитали ранее в этой главе, и поэтому очень важно уметь ими пользоваться. Такие статистики, как среднее значение и стандартное отклонение, неизбежно скрывают много информации по той причине, чтосворачиваютпоследовательностьв одно единственное число.
Английский математик ФрэнсисЭнскомб составил коллекцию из четырех точечных графиков, ныне известную как квартет Энскомба, которые обладают практически идентичными статистическими свойствами (включая среднее, дисперсию и стандартное отклонение). Несмотря на это, они четко показывают, что распределение значений последовательностей 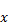 и
и  сильно расходится:
сильно расходится:
При этом наборы данныхне должны быть подстроенными, потому как ценные аналитические выводы будут непременно выявлены при построении графиков. Возьмем для примера гистограмму оценок, полученных выпускниками по национальному экзамену на аттестат зрелости в Польше в 2013 г.:
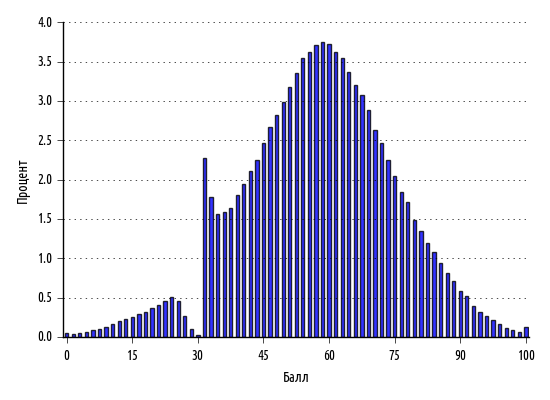
Способности учащихся вполне ожидаемодолжны быть нормально распределены, и действительно—за исключением крутого всплеска вокруг 30%—так и есть. То, что мы ясно наблюдаем—это результат по-человечески понятного натягивания экзаменаторами оценок учащегося на проходной балл.
На самом деле статистические распределения для последовательностей, взятых из крупных выборок, могут быть настолько надежными, что даже незначительное отклонение от них может являться свидетельством противоправной деятельности. Закон Бенфорда, или закон первой цифры, показывает любопытную особенность случайных чисел, которые генерируются в широком диапазоне. Единица появляется в качестве ведущей цифры примерно в 30% случаев, в то время как цифры крупнее появляется все реже и реже. Например, девятка появляется в виде первой цифры менее чем в 5% случаев.
Закон Бенфорда назван в честь физика Фрэнка Бенфорда (FrankBenford), который сформулировал его в 1938 г., показав его состоятельность на различных источниках данных. Проявление этого закона было ранее отмечено американским астрономом СаймономНьюкомом (SimonNewcomb), который еще более 50 лет назад до него обратил внимание на страницы своих логарифмических справочников: страницы с номерами, начинавшихся с цифры 1, имели более потрепанный вид.
Бенфорд показал, что его закон применяется к самым разнообразным данным, таким как счета за электричество, адреса домов, цены на акции, численность населения, уровень смертности и длины рек. Для наборов данных, которые охватывают большие диапазоны значений, закон настолько состоятелен, что случаи отклонения от него стали принимать в качестве подтверждающих данных в судебной практике по финансовым махинациям.






