

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...
Топ:
Теоретическая значимость работы: Описание теоретической значимости (ценности) результатов исследования должно присутствовать во введении...
Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Интересное:
Распространение рака на другие отдаленные от желудка органы: Характерных симптомов рака желудка не существует. Выраженные симптомы появляются, когда опухоль...
Инженерная защита территорий, зданий и сооружений от опасных геологических процессов: Изучение оползневых явлений, оценка устойчивости склонов и проектирование противооползневых сооружений — актуальнейшие задачи, стоящие перед отечественными...
Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Математическая запись, возможно, поначалу покажется непонятной и отталкивающей, однако на самом деле в используемых в этой книге формулах достаточно часто будут появляться всего несколько символов.
Знак  произносится как сигма иобозначает сумму. В математической записи он означает, что элементы последовательности складываются. Символы сверху и снизу сигмы указывают диапазон, по которому мы будем выполнять суммирование. Они скорее похожи на цикл for в C-подобном языке, и в предыдущей формуле показывают, что мы будем суммировать, начиная с
произносится как сигма иобозначает сумму. В математической записи он означает, что элементы последовательности складываются. Символы сверху и снизу сигмы указывают диапазон, по которому мы будем выполнять суммирование. Они скорее похожи на цикл for в C-подобном языке, и в предыдущей формуле показывают, что мы будем суммировать, начиная с  вплоть до
вплоть до  По традиции
По традиции  —это длина последовательности, а последовательности в математической записи индексируются, начиная с единицы, а не с нуля, поэтому суммирование от 1до означает, что мы выполняем суммирование по всей длине последовательности.
—это длина последовательности, а последовательности в математической записи индексируются, начиная с единицы, а не с нуля, поэтому суммирование от 1до означает, что мы выполняем суммирование по всей длине последовательности.
Выражение непосредственно после сигмы —это последовательность, которую нужно просуммировать. В нашей предыдущей формуле  непосредственно следует за сигмой. Поскольку каждый индекс будет представлен в диапазоне от 1 до , то переменная будет обозначать любой элемент в последовательности
непосредственно следует за сигмой. Поскольку каждый индекс будет представлен в диапазоне от 1 до , то переменная будет обозначать любой элемент в последовательности 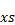 .
.
Наконец, прямо перед сигмой стоит  , показывая, что все выражение должно быть помножено на 1 деленое на (так называемое обратное число к ). Эту запись можно упростить, попросту разделив выражение на .
, показывая, что все выражение должно быть помножено на 1 деленое на (так называемое обратное число к ). Эту запись можно упростить, попросту разделив выражение на .
| Название | Математический символ | Эквивалент наPython | Эквивалент вPandas |

| len(xs) | df.count() | |
| Обозначение со знаком суммы | 
| sum(xs) | df.sum() |
| Обозначение со знаком произведения | 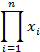
| from functools import reduce from operator import mul reduce(mul, xs) | df.mul() |
Собрав все вместе, мы получим формулу, которая читается так: "сложить элементы последовательности от первого до последнего и поделить на их количество". НаPython это можно записать так:
|
|
defmean(xs):
'''Среднее значение числового ряда'''
returnsum(xs) / len(xs)
где расшифровывается как "последовательность ". Мы можем воспользоваться нашей новой функцией mean для вычисления среднего числа избирателей в Великобритании:
defex_1_7():
'''Вернуть среднее значение поля "Электорат"'''
return mean(load_uk_scrubbed()['Electorate'])
# 70149.94
На самом деле, библиотека Pandas уже содержит функцию mean, которая очень эффективно вычисляет среднее значение последовательности. В нашем случае ее можно применить следующим образом:
load_uk_scrubbed()['Electorate'].mean()
Медиана
Медиана—это еще одна распространенная описательная статистика для измерения центра распределения последовательности. Если Вы упорядочили все данные от меньшего до наибольшего, то медиана—это значение, которое находится ровно по середине. Если в последовательности число точек данных четное, то медиана определяется, как полусуммадвух срединных значений.
В математических формулах медиана обозначается символом  , произносится х-тильда. Один из недостатков математической записи в данном случае заключается в том, что нет какого-то стандартного способа записи формулы для медианного значения, и тем не менее наPythonмедиана вычисляется довольно просто:
, произносится х-тильда. Один из недостатков математической записи в данном случае заключается в том, что нет какого-то стандартного способа записи формулы для медианного значения, и тем не менее наPythonмедиана вычисляется довольно просто:
defmedian(xs):
'''Медиана числового ряда'''
n = len(xs)
mid = n // 2
if n % 2 == 1:
return sorted(xs)[mid]
else:
return mean(sorted(xs)[mid-1:][:2])
Медианное значение электората Великобритании составляет:
defex_1_8():
'''Вернуть медиану поля "Электорат"'''
return median(load_uk_scrubbed()['Electorate'])
# 70813.5
Библиотека Pandas тоже располагает встроенной функцией для вычисления медианного значения, которая так и называется median.
Дисперсия
Среднее арифметическое и медиана являются двумя альтернативными способами описания срединногозначения последовательности, но сами по себе они мало что говорят о содержащихся в ней значениях. Например, если известно, что среднее последовательности из девяноста девяти значений равно 50, то мы почти ничегоне скажем о том, какого рода значения последовательность содержит.
|
|
Она может содержатьцелые числа от 1 до 99 илидва ряда чисел, состоящих из 49 нулейи 50 девяносто-девяток, а может быть и так, что она содержитряд из 98 чисел, равных -1 и одно единственное значение 5048, или же вообщевсе значения могут быть равны 50.
Дисперсия последовательности чисел показывает "разброс" данных вокруг среднего значения. К примеру, данные, приведенные выше, имели бы разную дисперсию. На языке математики дисперсия обозначаетсяследующим образом:

где  —это математический символ, который часто используют для обозначения дисперсии.
—это математический символ, который часто используют для обозначения дисперсии.
Это уравнение имеет ряд общих черт с вычисленным ранее уравнением для среднего значения. Вместо суммирования индивидуальных значений , мы суммируем результаты функции 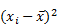 . Напомним, что символ
. Напомним, что символ 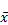 означает среднее значение, т.е. функция вычисляет квадрат отклонения индивидуального значения от среднего значения всей последовательности xs.
означает среднее значение, т.е. функция вычисляет квадрат отклонения индивидуального значения от среднего значения всей последовательности xs.
Выражение можно преобразовать в функцию квадрата отклонения, square_deviation, которую можноприменить ккаждому элементу последовательности xs. При этом мы также воспользуемсясозданной ранее функцией вычисления среднего значенияmean, которая суммирует значения последовательности и делит полученную сумму на их количество.
defvariance(xs):
'''Дисперсия числового ряда,
несмещенная дисперсия при n<= 30'''
mu = mean(xs)
n = len(xs)
n = n-1 if n in range(1, 30) else n
square_deviation = lambda x: (x - mu) ** 2
return sum(map(square_deviation, xs)) / n
Для вычисления квадрата выражения используетсяоператорвозведения в степень**языка Python.
| |
Приведенная выше функция variance вычисляет несмещенную оценку выборочной дисперсии (n -1 в знаменателе). Поскольку соотношение между выборочной и генеральной дисперсией составляет n / n -1, то с ростом n данное соотношение стремится к 1, т.е. разница между значениями дисперсии генеральной совокупности и дисперсии выборки из нее уменьшается. На практике при n >30 уже нет разницы, какое число стоит в знаменателе: n или n -1.
Поскольку мы взяли средний квадрат отклонения, т.е.получили квадрат отклонения и затемего среднее, то единицы измерения дисперсии тоже будут в квадрате, т.е.дисперсияэлектората Великобритании будет измеряться "людьми в квадрате". Несколько неестественно рассуждать об избирателях в таком виде. Единицу измеренияможно привести к более естественному виду, снова обозначающему "людей", путем извлечения квадратного корня из дисперсии. В результате получим так называемое стандартное отклонение (СКО), или среднеквадратичное отклонение:
|
|
defstandard_deviation(xs):
'''Стандартное отклонение числового ряда'''
returnsp.sqrt(variance(xs))
defex_1_9():
'''Стандартное отклонение поля "Электорат"'''
return standard_deviation(load_uk_scrubbed()['Electorate'])
# 7672.77
В библиотеке Pandas функции для вычисления дисперсии и стандартного отклонения реализованы соответственно, как var иstd.При этом последняя по умолчанию вычисляет несмещенное значение, поэтому, чтобы получить тот же самый результат, нужно применить именованный аргумент ddof=0, который сообщает, что требуетсявычислить смещенное значение стандартного отклонения:
load_uk_scrubbed()['Electorate'].std(ddof=0)
Квантили
Медиана—это один из способов вычислить из списка срединное значение, т.е. находящееся ровно по середине, дисперсия же предоставляет способ измерить разброс данных вокруг среднего значения. Если весь разброс данных представить на шкале от 0 до 1, то значение 0.5 будет медианным.
Для примера рассмотрим следующую последовательность чисел:
[10 11 15 21 22.5 28 30]
Отсортированная последовательность состоит из семи чисел, поэтому медианой является число 21 четвертое в ряду. Его также называют 0.5-квантилем. Мы можем получить более полную картину последовательности чисел, взглянув на 0.0 (нулевой), 0.25, 0.5, 0.75 и 1.0квантили. Все вместе эти цифры не только показывают медиану, но также обобщаютдиапазон данных и сообщат о характере распределения чисел внутри него. Они иногда упоминаются в связи с пятичисловой сводкой.
Один из способов составления пятичисловой сводки для данных об электорате Великобритании показан ниже. Квантили можно вычислить непосредственно в Pandas при помощи функции quantile. Последовательность требующихся квантилей передается в виде списка.
defex_1_10():
'''Вычислить квантили:
возвращает значение в последовательности xs,
соответствующее p-ому проценту'''
q = [0, 1/4, 1/2, 3/4, 1]
return load_uk_scrubbed()['Electorate'].quantile(q=q)
# 0.00 21780.00
|
|
# 0.25 65929.25
# 0.50 70813.50
# 0.75 74948.50
# 1.00 109922.00
# Name: Electorate, dtype: float64
Когда квантили делят диапазон на четыре равных диапазона, как показано выше, то они называются квартилями. Разница между нижним (0.25) и верхним (0.75) квартилями называется межквартильным размахом, или иногда сокращенно МКР. Аналогично дисперсии вокруг среднего значения, МКР измеряет разброс данных вокруг медианы.
Дискретизацияданных
Чтобы развить интуитивное понимание в отношении того, что именно измеряют все эти калькуляцииразброса значений, мы можем применить метод под названием дискретизации. Когда данные имеют непрерывный характер, использование специальногословаря для подсчета частот Counter (подобно тому, как он использовался при подсчете количества пустых значений в наборе данных об электорате) становится нецелесообразным, поскольку никакие два значения не могут быть одинаковыми. Между тем, общее представление о структуре данных можно все-равно получить, сгруппировав для этого данные встатистические группы, или так называемые корзины, от англ.bins,или дискретные интервалы.
Процедураобразования статистических групп заключается в разбиении диапазона значений на ряд последовательных, равноразмерныхи меньших интервалов. Каждое значение в исходном ряду попадает строго в однустатистическую (интервальную) группу. Подсчитавколичества точек, попадающих в каждую группу,мы можем получить представление о разбросе данных:

На приведенном выше рисунке показано 15 значений x, разбитых на 5равноразмерныхинтервальных групп. Подсчитав количество точек, попадающих в каждую группу, мы можем четко увидеть, что большинство точек попадают в группу по середине, а меньшинство—в группы по краям. Следующая ниже функция Pythonnbinпозволяет добиться того же самого результата:
defnbin(n, xs):
'''Разбивка данных на частотные интервалы'''
min_x, max_x = min(xs), max(xs)
range_x = max_x - min_x
fn = lambda x: min(int((abs(x) - min_x) / range_x * n), n-1)
returnmap(fn,xs)
Например, мы можем разбить диапазон 0-14 на 5 интервальных групп следующим образом:
list(nbin(5, range(15)))
# [0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4]
После того, как мы разбили значения на интервальные группы, мы можем в очередной раз воспользоватьсясловарем Counter, чтобы подсчитать количество точек в каждой группе. В следующем ниже примере мы воспользуемсяэтим словаремдля разбиения данных об электорате Великобритании на пять интервальных групп:
defex_1_11():
'''Разбиmь электорат Великобритании
на 5 статистических (интервальных) групп'''
series = load_uk_scrubbed()['Electorate']
return Counter(nbin(5, series))
# Counter({2: 450, 3: 171, 1: 26, 0: 2, 4: 1})
Количество точек в крайних интервальных группах (0 и 4) значительно ниже, чем в группах в середине—количества, судя по всему, растут по направлению к медиане, а затем снова снижаются. В следующем разделе мы займемся визуализацией формы этих количеств.
|
|
Гистограммы
Гистограмма—это один из способов визуализациираспределения одиночной последовательности значений. Гистограммы попросту берут непрерывное распределение, разбивают его на интервальные группы, и изображают частоты точек, попадающих в каждую группу, в виде столбцов. Высота каждого столбца гистограммы показывает количество точек данных, которые содержатся в этой группе.
Мы уже увидели, каким образом можно выполнитьразбиение данных на интервальные группысамостоятельно, однако в библиотеке Pandasуже содержится функция hist, которая разбивает данные и визуализирует их в виде гистограммы.
defex_1_12():
'''Построить гистограмму интервальных групп
электората Великобритании'''
load_uk_scrubbed()['Electorate'].hist()
plt.xlabel('Электорат Великобритании')
plt.ylabel('Частота')
plt.show()
Приведенный выше примерсгенерирует следующийграфик:

Число интервальных групп, на которые данные разбиваются, можно сконфигурировать, передав в функцию при построении гистограммы именованный аргументbins:
defex_1_13():
'''Построить гистограмму интервальных групп
электората Великобритании с 200 интервальными группами'''
load_uk_scrubbed()['Electorate'].hist(bins=200)
plt.xlabel('Электорат Великобритании')
plt.ylabel('Частота')
plt.show()
Приведенный выше график показывает единственный высокий пик, однако он выражает форму данных довольно грубо. Следующий ниже график показывает мелкие детали, но величина столбцов делает неясной форму распределения, в особенности в хвостах:

При выборе количества интервальных групп для представления данных следует найти точку равновесия—с малымколичествомгрупп форма данных будет представлена лишь приблизительно, а слишком большое их число приведет к тому, что шумовые признаки могут заслонить лежащую в основании структуру.
defex_1_14():
'''Построить гистограмму интервальных групп
электората Великобритании с 20 интервальными группами'''
load_uk_scrubbed()['Electorate'].hist(bins=20)
plt.xlabel('Электорат Великобритании')
plt.ylabel('Частота')
plt.show()
Ниже показана гистограмма теперь уже из 20 интервальных групп:

Окончательный график, состоящий из 20интервальных групп, судя по всему, пока лучше всего представляет эти данные.
Наряду со средним значением и медианой,есть еще один способ измерить среднюю величину последовательности.Это мода. Мода— это значение, встречающееся в последовательности наиболее часто. Она определена исключительно только для последовательностей, имеющих по меньшей мере одно дублирующееся значение; во многих статистических распределениях это не так, и поэтому для них мода не определена. Тем не менее, пик гистограммы часто называют модой, поскольку он соответствует наиболее распространеннойинтервальной группе.
Из графика ясно видно, что распределение вполне симметрично относительно моды, и его значения резко падают по обе стороны от нее вдоль тонких хвостов. Эти данные приближенно подчиняются нормальному распределению.
Нормальное распределение
Гистограмма дает приблизительное представление о том, каким образом данные распределены по всему диапазону, и является визуальным средством, которое позволяетквалифицировать данныекак относящиеся к одному из немногих популярных распределений. В анализе данных многие распределения встречаются часто, но ни одно не встречается также часто, как нормальное распределение, именуемое также гауссовым распределением.
| |
Распределение названо нормальным распределением из-за того, что оно очень часто встречается в природе. Галилей заметил, что ошибки в его астрономических измерениях подчинялись распределению, где малые отклонения от среднего значения встречались чаще, чем большие. Вклад великого математика Гаусса в описание математической формы этих ошибок привел к тому, что это распределение стали называть в его честь распределением Гаусса.
Любое распределение похоже на алгоритм сжатия: оно позволяет очень эффективно резюмировать потенциально большой объем данных. Нормальное распределение требует только два параметра, исходя из которых можно аппроксимировать остальные данные. Этосреднее значение и стандартное отклонение.
| |
В англоязычной литературе термин mean может трактоваться как измеренное среднее арифметическое и как среднее (ожидаемое) значение, т.е. математическое ожидание.Далее везде используется термин"среднее значение".
|
|
|

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰)...

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого...

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...

Наброски и зарисовки растений, плодов, цветов: Освоить конструктивное построение структуры дерева через зарисовки отдельных деревьев, группы деревьев...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!