"Clojure для науки о данных", 2015
Статистика, большие данные и
машинное обучение
для программистов на Python
Об авторе оригинала книги
Генри Гарнер —выпускник Оксфордского университета и опытный разработчик, технический директор и инструктор.
Он начал свою карьеру на техническом поприще в крупнейшем в Великобритании операторе телекоммуникационных услуг BT, работая с традиционной инфраструктурой хранилищ данных. В составе малочисленной команды за 3 года он разработал сложные модели данных с целью извлечения ценных сведений из необработанных данных и использовал веб-приложения, чтобы представить результаты. Эти приложения были использованы внутри организации руководителями и операторами высшего звена для отслеживания работы бизнеса и производительности системы.
Затем он продолжил карьеру, уже в качестве со-основателя социально-медийного аналитического стартапаLikely. В качестве технического директора он возглавил техническое направление, приведя к внедрению событийного конвейера данных "только с добавлением", смоделированного по архитектуре Lambda. В 2011 г. он перешел на Clojure и возглавил гибридную команду, состоящую из программистов и аналитиков данных, которая разрабатывает механизмы рекомендательных систем на основе методов коллаборативной фильтрации и кластерного анализа. Он разработал учебный курс и состоял сопредседателем серии вечерних занятий, проводимых служащими Likely для профессиональных разработчиков, которые хотели изучать Clojure.
Сегодня Генри работает с развивающимися компаниями, консультируя относительно разработки и лидерского потенциала в технической области. Он регулярно выступает на семинарах и встречах разработчиков на Clojure в Лондоне и округе.
Содержание
Предисловие автора к оригиналу книги на Clojure 15
1 17
Статистика 17
Скачивание исходного кода примеров 18
Выполнение примеров 18
Скачивание данных 19
Обследование данных 19
Исправление данных 24
Описательные статистики 26
Среднее значение 27
Интерпретация математических обозначений 27
Медиана 29
Дисперсия 30
Квантили 31
Образование статистических групп 32
Гистограммы 34
Нормальное распределение 36
Центральная предельная теорема 37
Булочник господина Пуанкаре 40
Генерирование распределений 41
Асимметрия 43
Графики нормального распределения 44
Способы сопоставительной визуализации 46
Коробчатые диаграммы 46
Интегральные функции распределения 47
Важность визуализации 49
Визуализация данных об электорате 51
Добавление столбцов 54
Добавление производных столбцов 55
Сопоставительная визуализация электоральных данных 57
Визуализация данных о выборах в России 59
Сравнительная визуализация 61
Функции массы вероятности 62
Точечные графики 64
Настройка прозрачности разброса 67
Резюме 68
Предисловие авторак оригиналу книги на Clojure
"Статистические мышление однажды станет необходимым атрибутом действенного гражданского сознания в той же степени, что и способность читать и писать."
— Х. Г. Уэллс
"У меня для написания есть отличная тема [статистика], но остро чувствую свою литературную неспособность сделать ее доступной для понимания, не жертвуя точностью и скрупулезностью."
— Сэр ФрэнсисГэлтон
Веб-поиск по запросу "наука о данных диаграмма Венна" возвращает многочисленные толкования навыков, которые требуются для того, чтобы стать эффективным аналитиком данных (создается впечатление, что обозреватели науки о данных обожают диаграммы Венна). Автор и аналитик данных Дрю Конвей еще в 2010 г. создал классическую диаграмму, поместив науку о данных на пересечение между хакерскими навыками (назовем их навыками алгоритмизации), знанием предметной области и осведомленностью в области математики и статистики. Причем между хакерскими навыками и знанием предметной области лежит "опасная зона", обозначающая тех, кто занимается наукой о данных без прочного фундамента в области математики и статистики,
В то время как вот уже 5 лет все возрастающее число разработчиков претендует на то, чтобы ликвидировать нехватку знаний в области науки о данных, потребность в статистическом и математическом образовании, помогающее разработчикам выбраться из этой опасной зоны, становится все больше, как никогда. Поэтому, когда издательство PacktPublishing пригласило меня написать книгу о науке о данных, предназначенную для программистов на языке Clojure, я с удовольствием согласился. Наряду с осознанием необходимости такой книги, я рассматривал это как возможность собрать воедино подавляющую часть того, что я узнал, будучи директором собственной компании, работающей в области анализа данных на языке Clojure. В результате получилась книга, которую мне следовало бы прочитать, прежде чем начинать дело.
Книга Clojure для Науки о данных стремится быть намного больше, чем просто книгой по статистике для программистов на Clojure. Одной из главных причин проникновения науки о данных в очень большое количество разнообразных сфер деятельности является огромная мощь методов машинного обучения. В этой книге я покажу, как использовать чистые функции языка Clojureи сторонние библиотеки для построения машинно-обучаемых моделей в целях решения основных задач регрессии, классификации, кластеризации и рекомендации данных.
Для аналитиков данных особенно интересны подходы, которые масштабируются до очень больших наборов данных, так называемых "больших данных", потому что они способны обнаруживать тонкости, которые затеряны в выборках меньших объемов. Эта книга показывает способы использования языка Clojureдля краткого выражения поставленных задач, предназначенных для решения на платформах распределенного вычисления Hadoop и Spark, и способы внедрения методов машинного обучения с помощью специализированных внешних библиотек и универсальных методов оптимизации.
Прежде всего, эта книга стремится способствовать пониманию не только того, как выполнять определенные типы анализа, но и почему такие методы работают. Наряду с предоставлением практических знаний (почти каждое понятие в этой книге воплощено в форме выполнимого примера), я стремлюсь объяснять теорию, которая позволит Вам брать принцип и применять его к аналогичным задачам. Я надеюсь, что этот подход позволит Вам эффективно применять статистическое мышление в разнообразных ситуациях и в будущем, независимо от того, продолжите Вы карьеру в области науки о данных или нет.
1
Статистика
"Важно не кто голосует, а кто подсчитывает голоса."
— Иосиф Сталин
В течение следующих десяти глав книги Python для науки о данных мы попытаемся проложить широкуюмагистральпопрактической научной дисциплине—науке о данных. Правда, надо сказать, по мере продвижения мы обнаружим, что дорога эта не совсем прямая, и внимательный читатель по ходу должен заметить много тем, которые возникают повторно.
Описательные статистики используются для обобщения последовательностей чисел, и они будут в определенной мере встречаться в каждой главе этой книги. В данной главе мы заложим фундамент для последующего материала путем реализации функций на языке Pythonдля вычисления среднегозначения,медианы, дисперсии и стандартного отклонения числовой последовательности. При этом мы попытаемся избавиться отбоязни интерпретации математических формул.
Как только перед нами стоит задача проанализировать данные, которые состоят из двух и более чисел, становится содержательным вопрос о том, каким образом эти числа распределены. Вы, наверное, уже слыхали такие выражения, как "длинный хвост" и "правило 80/20". Они касаются разброса чисел по диапазону. В этой главе мы продемонстрируем смысл распределений и познакомим с наиболее полезным из них: нормальным распределением.
При изучении распределений чрезвычайную важность играет наглядная и удобнаявизуализация данных, и для этого мы воспользуемся библиотекойPythonPandas. Мы покажем, как пользоваться еюдля загрузки, преобразования и разведочного анализа реальных данных, а такженачнем работать с фундаментальной библиотекойnumpyдля научных вычислений. Мы проведем сопоставительный анализ результатов двух общенациональных выборов—всеобщих выборов в Великобритании 2010 г. и российских выборов депутатов Государственной Думы Федерального Собрания РФ шестого созыва 2011 г.—и увидим, каким образом даже элементарный анализ может предъявитьподтверждающие данные о потенциальныхфальсификациях.
Скачиваниеисходного кода примеров
Все прилагаемые к книге примерыисходного кодаразмещены на веб-сайте издательства ДМК-Пресс по адресу http://www.dmk-press.ru/ либо на GitHub по адресу https://capissimo.github.io/pythonfordatascience/. Примеры исходного кодадля каждой главы находится в своем собственном репозитории.
Исходный код для Главы 1, Статистика,можно скачать с https://capissimo.github.io/pythonfordatascience/ch1-statistics.
Исполнимые примеры приводятся регулярно по ходу изложения материала в каждой главе книги с целью продемонстрировать результатвыполненияисходного кода, который был только что объяснен, либо с целью показать статистические принципы, которые были представлены. Все имена функций примеров начинаются с префикса ex- и нумеруются последовательно на протяжении каждой главы. Таким образом, первый выполнимый пример Главы 1, Статистика называется ex_1_1, второй — ex_1_2 и т. д.
Обследование данных
В этой главе и во многих других главах этой книги, мы будем пользоваться тремя главными библиотеками экосистемы SciPy:одноименной библиотекой SciPyLibraryдля выполнения сложных математико-статистических расчетов, библиотекойPandas (http://pandas.pydata.org/) для загрузки данных из разнообразных источников, управления ими и их визуализации, а также библиотекой NumPy (http://www.numpy.org/) в основном для работы с массивами и матрицами.
Все три библиотекипризванывыполненятьконкретные функциональныезадачи. Библиотека SciPyпредоставляет пользователю фундаментальный математический функционал, NumPy предлагает большой набор функций для выполнения разнообразных математических операций намногомерныхчисловыхмассивах, тогда как библиотека Pandas предлагает удобные одно-, двух- и многомерные структуры для выполнения статистического анализа гетерогенных данных. Эта библиотека создана по образцу чрезвычайно популярной среды для анализа данных на языке R и объединяет мощь языка Python, его интерактивную оболочку REPL, и набор мощных абстракций для работы с данными. Кроме того, она позволяет оформить результаты вычислений в изображения типографского качества.
Каждая библиотека может быть отдельно включена в ваш собственный исходный код. Чтобы получить доступ к математико-статистическому функционалу, функциям для построения графиков и обработки файлов, в Ваш проект программы следует включить следующие строки:
import numpy as np
import scipy as sp
importpandasaspd
Кроме того, мы будем пользоваться встроенными в Pythonмодулями. Так, например, модульrandomпозволяет генерировать случайные числа и извлекать выборки, и модульcollections содержит дополнительные структуры данных, из которых мы воспользуемся специальным словарем Counter.
В основе библиотеки Pandas лежит понятие таблицы данных, от англ. DataFrame, т.е. структуры, состоящей из строки столбцов, или записей и полей. Если у Вас есть опыт работы с реляционными базами данных, то таблицы Pandasпожно представить, как таблицы базы данных. Каждый столбец в табличном наборе данных поименован, а каждая строка имеет одинаковое число столбцов, как и любая другая. Загрузить данные в структуру DataFrame библиотеки Pandas можно несколькими способами, и тот, которым мы воспользуемся, будет зависеть от того, в каком виде наши данные хранятся:
· Если данные представлены текстовым файлом с разделением полей данных запятыми (.csv) илисимволами табуляции (.tsv), то мы будем использовать функцию чтения данных read_csv
· Если данные представлены файлом Excel (например, файл.xls или.xlsx), то мы воспользуемся функцией чтения данных read_excel
· Для любого другого источника данных (внешняя база данных, веб-сайт, буфер обмена данными, JSON-файлы, HTML-файлы и т. д.) предусмотрен ряд других функций
(REM) Помимо табличных наборов данных в библиотеке Pandas имеется еще одна популярнаяструтура–Series, т.е. ряд данных. Этоодномерный массив данных, необязательно числовых, которую мы тоже будем использовать. Есть еще одна реже используемая структура – Panel, т.е. панель данных, для представления трехмерных данных, однако в этой книге мы будем по большей части работать с двумерными таблицами и одномерными рядами данных.
В этой части главы в качестве источника данных используетсяфайлExcel, поэтому для чтения данных мы воспользуемся функциейread_excel. Эта функция принимает один обязательный аргумент—файл для загрузки—и ряд необязательных аргументов, в т.ч., номер либо название листа в виде именованного аргумента. Все наши примеры имеют всего один лист, и поэтому мы будем предоставлятьлишь один файловый аргумент в виде следующей строкиисходного кода:
pd.read_excel('data/ch01/UK2010.xls')
Как Вы заметили выше,ради краткости мы назначили импортируемым библиотекам короткие псевдонимы. Например, в этой книге мы всегда будем обращаться к библиотеке Pandasкак pd,к библиотеке NumPyкак npи к библиотеке SciPyкак sp.
В этой главе мы выполним загрузкуданных из нескольких источников, поэтому мы создадим несколько вариантовзагрузки данных.В приведенном нижефрагменте кода мы определяем функцию загрузки данных load_uk:
defload_uk():
'''Загрузить данные по Великобритании'''
return pd.read_excel('data/ch01/UK2010.xls')
Эта функция вернет табличный набор данныхDataFrameбиблиотеки Pandas, содержащий данные по Великобритании. Далее в этой главе, мы определим дополнительные реализациизагрузки этого же и еще одного набора данных.
Первая строка электронной таблицы UK2010.xls содержит имена столбцов. Функция библиотеки Pandasread_excelрезервирует их в качестве имен столбцов возвращаемого табличного набора данных. Начнем обследование данных с их проверки—атрибут табличного набора данныхcolumns возвращает имена столбцов в виде списка, при этом адресация атрибутов осуществляется при помощи оператора точки (.):
defex_1_1():
'''Получить имена полей таблицы данных'''
returnload_uk().columns
Результатом выполнения приведенной вышефункции должен быть следующий ниже списокполей таблицы данных Pandas:
Index(['Press Association Reference', 'Constituency Name', 'Region',
'Election Year', 'Electorate', 'Votes', 'AC', 'AD', 'AGS', 'APNI',
...
'UKIP', 'UPS', 'UV', 'VCCA', 'Vote', 'WessexReg', 'WRP', 'You',
'Youth', 'YRDPL'],
dtype='object', length=144)
Это очень широкий набор данных, состоящий из 144 полей. Первые шесть столбцов в файле данных описываются следующим образом; последующие столбцы лишьраспределяют число голосов по партиям:
• Информация для Ассоциации прессы: число, идентифицирующее избирательный округ (представленный одним депутатом)
• Название избирательного округа: стандартное название, данное избирательному округу
• Регион: географический район Великобритании, где округ расположен
• Год выборов: год, в котором выборы состоялись
• Электорат: общее число граждан, имеющих право голоса в избирательном округе
• Голосование: общее число проголосовавших
Всякий раз, когда мы сталкиваемся с новыми данными, важно потратить некоторое время на то, чтобы в них разобраться. В отсутствии подробного описания данных лучше всего начать с подтверждения наших предположений по поводу данных. Например, мы ожидаем, что этот набор данных содержит информацию о выборах 2010 г., поэтому проверим содержимое столбца года выборов ElectionYear.
В Pandas предусмотрен обширный функционал для горизонтального (построчного) и вертикального (постолбцового) отбора и фильтрации данных. В элементарном случае нужный столбец можно выбрать, указав его номер или имя.В этой главе мы часто будем таким способом отбирать столбцы данных из различных представлений данных:
defex_1_2():
'''Получить значения поля "Год выборов"'''
returnload_uk()['ElectionYear']
В результате будет выведен следующий список:
0 2010.0
1 2010.0
2 2010.0
...
646 2010.0
647 2010.0
648 2010.0
649 2010.0
650 NaN
Name: Election Year, dtype: float64
Столбец года выборов возвращается в виде последовательности значений. Полученный результат, возможно, будет нелегко интерпретировать, поскольку табличный набор данных содержит слишком много строк. Учитывая, что мы хотели бы узнать, какие уникальные значенияесть в этом столбце, можно воспользоваться методомuniqueтабличного набора данных. Одно из преимуществ использования библиотеки Pandasсостоит в том, что ее полезные функции управления данными дополняют те, которые уже встроены в Python. Следующийниже примерэтопоказывает:
defex_1_3():
'''Получить значения в поле "Год выборов" без дубликатов'''
returnload_uk()['ElectionYear'].unique()
# [ 2010. nan]
Значение 2010еще больше подкрепляет наши ожидания в отношении того, что эти данные относятся к 2010 году. Впрочем, наличие специального значенияnan, от англ. notanumber, т.е. не число, которое сигнализирует о пропущенных данных, является неожиданным и может свидетельствовать о проблеме с данными.
Мы еще не знаем, в сколькихэлементахнабора данныхпропущены значения, и установивих число, мы смогли бы решить, что делать дальше. Простой способ подсчитать такие пустые элементы состоит виспользованииподкласса словарейCounterязыкаPython из модуля collections. Этот словарь трансформирует последовательность значений в коллекцию, где ключам поставлены в соответствие количества появлений элементов данных, т.е. их частоты:
defex_1_4():
'''Рассчитать частоты в поле "Год выборов"
(количества появлений разных значений)'''
returnCounter(load_uk()['ElectionYear'])
# Counter({nan: 1, 2010.0: 650})
Словарь Python,как одна из основных структур данных, в которой элементам из одного множества поставлены в соответствие элементы из другого множества, в виде пар ключ-значение, реализует математическое понятие отображения в виде однозначного соответствия ключа своему значению. В других языках программирования такая коллекция носит название ассоциативного списка.
Нам не потребуется много времени, чтобы получить подтверждение, что в 2010 г. в Великобритании было 650 избирательных округов. Знание предметной области, как в этом случае, имеет неоценимое значение при проверке достоверности новых данных. Таким образом, весьма вероятно, что значение nan является посторонним, и его можно удалить. Мы увидим, как это сделать, в следующем разделе.
Исправление данных
Согласно неоднократно подтвержденной статистике, как минимум 80% рабочего времениисследователь-аналитик тратит наисправление данных. Эта процедура заключается в выявлении потенциально поврежденных или некорректных данных иих корректировке либо фильтрации.
Процесс исправления данных—один из важнейших (и трудоемких) аспектов работы с данными. Он является ключевым этапом, который гарантирует, что последующий анализ осуществляется на данных, которые являются состоятельными, правильными и согласованными.
Специальное значение nan в конце столбца года выборов может сигнализировать о грязных данных, которые требуется удалить. Мы уже убедились, что нужные столбцы данных в Pandasможно отобрать, указав их номера или имена. Для фильтрации записей данных можно воспользоватьсяодним из предикативныхметодов библиотеки Pandas.
Мы сообщаем библиотеке Pandas, какие записи мы хотим отфильтровать, передавая в таблицу данных в качестве аргумента логическое выражение с использованием предикативныхфункций. В результате будут сохранены только те записи, для которых все предикаты возвращают истину. Например, чтобы отобрать только пустые значения из нашего набора данных, нужно следующее:
defex_1_5():
'''Вернуть отфильтрованную по полю "Год выборов"
запись в таблице данных (в виде словаря)'''
df = load_uk()
returndf[df['Election Year'].isnull() ]
| | PressAssociationReference
| ConstituencyName
| Region
| ElectionYear
| Electorate
| Votes
| AC
| AD
| AGS
| ...
|
|
| NaN
| NaN
| NaN
| NaN
| NaN
|
| NaN
| NaN
| NaN
| ...
|
Выражение dt['ElectionYear'].isnull()вернет булевую последовательность, в которой все элементы, кроме последнего, равны false, в резульате чего будет возвращена последняя запись таблицы. Если Вы знаете язык запросов SQL, то отметите, что этот метод очень похож на условный оператор WHERE.
Сложные запросы конструируются путем комбинирования логических выражений с операциями сравнения и предикатами при помощи операторов логического И (&) и логического ИЛИ (|) и логического отрицания (~). Например:
df = pd.DataFrame(sp.random.randn(6,4), index=dates, columns=list('ABCD'))
df = pd.DataFrame({'AAA': [4,5,6,7], 'BBB': [10,20,30,40],'CCC': [100,50,-30,-50]})
df[(df.AAA<= 6) & (df.index.isin([0,2,4]))]
df[~((df.AAA<= 6) & (df.index.isin([0,2,4])))]
isnull()
notnull()
isin()
dt = dt[(df.a!= -1) & (dt.b!= -1)]
dt = dt[(df['a']!= -1) | (df['b']!= -1)]
dt[(df.AAA<= 6) & (df.index.isin([0,2,4]))]
булева индексация
df[df.A> 0]
df[df> 0]
s[(s < -1) | (s > 0.5)]
s[~(s < 0)]
df2[df2['E'].isin(['two','four'])]
булевысвертки empty, any(), all(), and bool()
(df> 0).all()
(bb.groupby(['year', 'team']).sum().loc[lambda df: df.r> 100])
criterion = df2['a'].map(lambda x: x.startswith('t'))
df2[criterion]
df2[criterion & (df2['b'] == 'x')]
Если встроенных операторов недостаточно, то последний оператор предоставляет возможность передать собственную функцию.
Присмотревшись к результатампримера ex_1_5, можно заметить, что в полученнойзаписивсе поля (кроме одного) имеют значение NaN. Дальнейший анализ данных подтверждает, что строка с непустым полем на самом деле является строкой итоговой суммы в листе файла Excel. Эту строкуследуетиз набора данных удалить. Мы можем удалять проблемные строки путем обновления коллекции предикативной функциейnotnull(), котораяв данном случае вернеттолько те строки, в которых год выборов не равен nan:
df = load_uk()
return df[df[ 'Election Year' ].notnull() ]
Приведенные выше строкинам почти всегда придется вызыватьнепосредственно перед использованием данных. Лучше всего этосделать, добавив еще одну реализацию функции загрузки данныхпо Великобританииload_uk_scrubbedс этимэтапом фильтрации:
defload_uk_scrubbed():
'''Загрузить и отфильтровать данные по Великобритании'''
df = load_uk()
return df[df[ 'Election Year' ].notnull() ]
Теперь при написании любого фрагмента кода с описанием доступа к набору данных в файле, можно выбирать вариант загрузки: обычный при помощи функции load_uk либо его аналог с очисткой данных load_uk_scrubbed.Приведенный выше пример должен вернуть список из 650 чисел, обозначающих количество избирателей в каждом избирательном округе Великобритании.
Внося исправления поверх загружаемых данных, мы сохраняем возможность проследить характервыполненных преобразований. В результате нам самим — и будущим читателям нашегоисходного кода — становится понятнее, какие были внесены изменения в источник данных. Это также означает, что, как только потребуется снова запустить наш анализ, но уже с данными из новогоисточника,мы можемпопростузагрузить новый файл, указав его вместо существующего.
Описательные статистики
Описательные статистики—это числа, которые используются для обобщения и описания данных. В следующей главе мы обратимся к более сложному анализу, так называемым инференциальным статистикам, или показателям статистического вывода,но пока мы ограничимся простым описанием того, что мы можем наблюдать в данных, содержащихся в файле.
Чтобы продемонстрировать, что мы имеем в виду, посмотрим на столбец с данными об электоратеElectorate. Он показывает общее число зарегистрированных избирателей в каждом избирательном округе:
defex_1_6():
'''Число значений в поле "Электорат"'''
return load_uk_scrubbed()['Electorate'].count()
# 650
Мы уже очистилистолбец, отфильтровав пустыми значения (nan) из набора данных, и поэтому предыдущий пример должен вернуть общее число избирательных округов.
Описательные статистики, которые также называются сводными, представляют собой способы измерения свойств последовательностей чисел. Они помогают охарактеризовать последовательность и способны выступать в качестве ориентира для дальнейшего анализа. Начнем с двух самых базовых статистик, которые мы можем вычислить из последовательности чисел—ее среднее значение и дисперсию.
Среднее значение
Наиболее распространенный способ усреднить набор данных—взять его среднее значение. Среднее значение на самом деле представляет собой один из нескольких способов измерения центра распределения данных. Среднее, или в данном случае, среднее арифметическое, берется путем прямого вычисления—надо всего лишь сложить значения и разделить сумму на их количество—правда на языке математики формуладля среднего арифметического имеет несколькоотпугивающий вид:

где 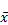 , произносится х с чертой,—это математический символ, который часто используется для обозначения среднего значения.
, произносится х с чертой,—это математический символ, который часто используется для обозначения среднего значения.
Общим видом формулы является формула средней арифметической взвешенной, где каждое значение переменной сначала умножается на свой вес. Приведенная здесь формула средней арифметической простой является ее частным случаем, когда веса для всех значений равны единице. Это свойство следует читывать, когда речь пойдет о среднем значении, или математическом ожидании.
Следующий ниже раздел предназначен для программистов, пришедших в науку о данных из областей, находящихся за пределами математики или естественных наук.






