При использовании многомерной модели данные хранятся не в виде плоских таблиц, как в реляционных БД, а в виде гиперкубов – упорядоченных многомерных массивов. Такое представление является наглядным и позволяет резко уменьшить время поиска в хранилище данных, поскольку отсутствует необходимость многократно соединять таблицы. Основные понятия многомерной модели – измерение и значение (ячейка). Измерение – это множество, образующее одну из граней гиперкуба (аналог домена в реляционной модели). Измерения играют роль индексов, используемых для идентификации конкретных значений в ячейках гиперкуба. Значения – это подвергаемые анализу количественные или качественные данные, которые находятся в ячейках гиперкуба. В многомерной модели вводятся следующие основные операции манипулирования измерениями: 1) сечение; 2) вращение; 3) детализация; 4) свертка.
При выполнении операции сечения формируется подмножество гиперкуба, в котором значение одного или более измерений фиксировано. Операция вращения изменяет порядок представления измерений. Она обычно применяется к двухмерным таблицам, обеспечивая представление их в более удобной для восприятия форме.
Для выполнения операций свертки и детализации должна существовать иерархия значений измерения, то есть некоторая подчиненность одних значений другим.
Многомерный анализ данных, часто называемый системой аналитической обработки, позволяет задавать сложные вопросы, а ответы представляют собой некие выборки данных или агрегированные показатели.
Ситуация, когда для анализа необходима вся информация, находящаяся в хранилище, возникает довольно редко. Обычно каждый аналитик или аналитический отдел обслуживает одно из направлений деятельности организации, поэтому в первую очередь ему необходимы данные, характеризующие именно это направление. Реальный объем этих данных не превосходит ограничений, присущих многомерным СУБД. Возникает идея выделить данные, которые реально нужны конкретным аналитическим
приложениям; в отдельный набор. Такой набор мог бы быть реализован в многомерной БД. Источником данных для него должно быть центральное хранилище организации.
Если проводить аналогии с производством и реализацией продукции, то многомерные БД выполняют роль мелких складов. В концепции ХД их принято именовать витринами данных. Витрина\киоск данных – этоспециализированное тематическое хранилище, обслуживающее одно их направлений деятельности организации. Логическая схема СППР, использующей центральное ХД организации и киоски данных аналитических отделов, представлена на рис. 5.3.
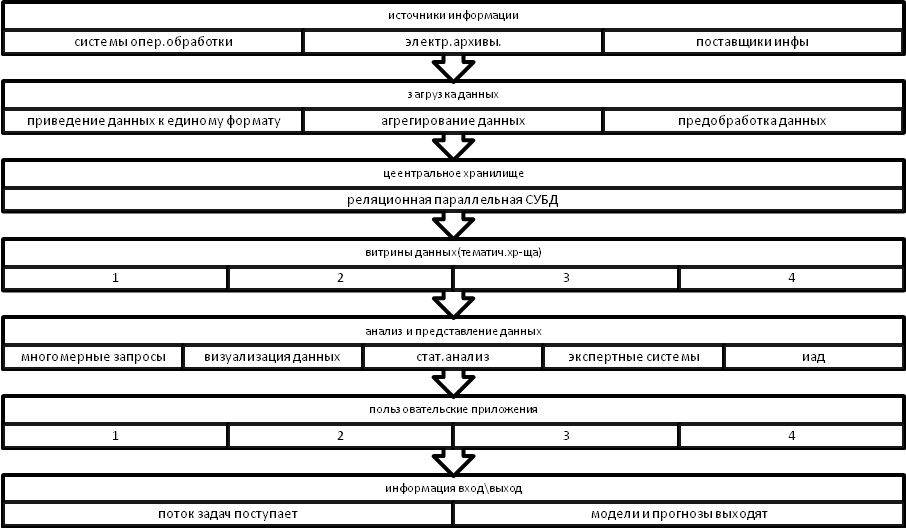
Такая схема позволяет эффективно использовать возможности реляционных СУБД по хранению огромных объемов информации и способность многомерных СУБД обеспечивать высокую скорость выполнения аналитических запросов.
Методы для аналитической обработки данных в хранилищах.
В аналитических системах для обработки данных используется очень широкая номенклатура методов. Это и традиционные статистические методы регрессионного, факторного, дисперсионного анализа, анализа временных рядов, а также методы, основанные на искусственном интеллекте. К последним, как правило, относят: нейронные сети, нечеткую логику, генетические алгоритмы, методы извлечения знаний. В большинстве случаев средства анализа данных в СППР на основе ХД используются для решения следующих задач: 1) выделение в данных групп сходных по некоторым признакам записей (кластерный анализ); 2) нахождение и аппроксимация зависимостей, связывающих анализируемые параметры или события, а также поиск параметров, наиболее значимых в терминах конкретной задачи; 3) поиск данных, существенно отклоняющихся от выявленных закономерностей (анализ аномалий); 4) прогнозирование развития объектов различной природы на основе хранящейся ретроспективной информации об их состоянии в прошлом.







