Базовой предпосылкой МНК является предположение о нормальном распределении отклонений 𝜀𝑖 с нулевым математическим ожиданием и постоянной дисперсией 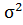 , которое является теоретически и практически обоснованным: 𝜀𝑖~𝑁(0; ).
, которое является теоретически и практически обоснованным: 𝜀𝑖~𝑁(0; ).
Согласно модельному уравнению линейной парной регрессии 𝑦𝑖 = 𝛽0 + 𝛽1 𝑥𝑖 + 𝜀𝑖, коэффициенты 𝑏0 и 𝑏1 через 𝑦𝑖 являются линейными комбинациями 𝜀𝑖. Следовательно, 𝑏0 и 𝑏1 также имеют нормальное распределение: 𝑏1~𝑁(𝛽1; 𝑆𝑏1 2), 𝑏0~𝑁(𝛽0; 𝑆𝑏0 2).
Тогда случайные величины 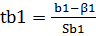 и 𝑡𝑏0 =
и 𝑡𝑏0 = 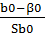 имеют распределение Стьюдента с числом степеней свободы 𝜈 = 𝑛 − 2. По заданной доверительной вероятности γ можно найти интервал:
имеют распределение Стьюдента с числом степеней свободы 𝜈 = 𝑛 − 2. По заданной доверительной вероятности γ можно найти интервал:
−𝑡кр < 𝑡 < 𝑡кр или 𝑡 < 𝑡кр внутри которого находятся значения 𝑡 с вероятностью γ: 𝑃(|𝑡| < 𝑡кр) = 𝛾.
Критическое значение 𝑡кр при доверительной вероятности 𝛾 = 1 − 𝛼 находятся по таблицам двусторонних квантилей распределения Стьюдента 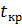 =
= 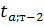 .
.
Таким образом: 𝑃(−𝑡кр < 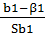 < 𝑡кр) = 𝛾, 𝑃(−𝑡кр < < 𝑡кр) = 𝛾
< 𝑡кр) = 𝛾, 𝑃(−𝑡кр < < 𝑡кр) = 𝛾
Доверительные интервалы для коэффициентов парной линейной регрессии с доверительной вероятностью 𝛾 = 1 − 𝛼 имеют вид:
𝑏1 − 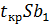 < 𝛽1 < 𝑏1 + ,
< 𝛽1 < 𝑏1 + ,
𝑏0 − 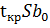 < 𝛽0 < 𝑏0 + .
< 𝛽0 < 𝑏0 + .
9. Проверка общего качества уравнения регрессии. Коэффициент детерминации R2.
Коэффициент детерминации (R 2)— это доля дисперсии отклонений зависимой переменной от её среднего значения, объясняемая рассматриваемой моделью связи. Модель связи обычно задается как явная функция от объясняющих переменных. 
Коэффициент детерминации является случайной переменной. Он характеризует долю результативного признака у, объясняемую регрессией, в общей дисперсии результативного признака: 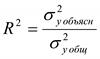 0≤ R2≤1. причем если R2= 1 то переменная yt полностью объясняется регрессором xt. В множественной регрессионной модели добавление дополнительных регрессоров увеличивает значение коэффициента детерминации, поэтому его корректируют с учетом числа независимых переменных:
0≤ R2≤1. причем если R2= 1 то переменная yt полностью объясняется регрессором xt. В множественной регрессионной модели добавление дополнительных регрессоров увеличивает значение коэффициента детерминации, поэтому его корректируют с учетом числа независимых переменных: 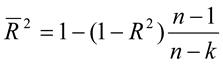
10. Множественная линейная регрессия. Определение параметров уравнения регрессии.
Обычно на любой экономический показатель влияет не один, а несколько факторов. Например, спрос на некоторый товар определяется не только его ценой, но и ценами на замещающие и дополняющие товары, доходом потребителей и другими факторами. В этом случае вместо функции парной регрессии 𝑀(𝑌|𝑋 = 𝑥) = 𝑓(𝑥) рассматривается функция множественной регрессии: 𝑀(𝑌|𝑋1 = 𝑥1; 𝑋2 = 𝑥2; …; 𝑋𝑚 = 𝑥𝑚) = 𝑓(𝑥1; 𝑥2; …; 𝑥𝑚).
Теоретическая модель множественной линейной регрессии имеет вид: 𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑚 𝑋𝑚 + 𝜀 (5.2) или для индивидуальных наблюдений: 𝑦𝑖 = 𝛽0 + 𝛽1 𝑥𝑖1 + 𝛽2 𝑥𝑖2 + ⋯ + 𝛽𝑚 𝑥𝑖𝑚 + 𝜀, (5.3) 𝑖 = 1, 2, … 𝑁, где N – объем генеральной совокупности.
После выбора в качестве модели линейной функции множественной регрессии необходимо оценить коэффициенты регрессии.
Пусть имеется n наблюдений вектора объясняющих переменных 𝑋 = (𝑋1; 𝑋2;.. 𝑋𝑚) и зависимой переменной Y: (𝑥𝑖1; 𝑥𝑖2; …; 𝑥𝑖𝑚; 𝑦𝑖), 𝑖 = 1, 2, …, 𝑛. Если 𝑛 = 𝑚 + 1, то оценки коэффициентов рассчитываются единственным образом. Здесь 𝑚 – число объясняющих переменных. Если 𝑛 < 𝑚 + 1, то система будет иметь бесконечное множество решений. Если 𝑛 > 𝑚 + 1, то нельзя подобрать линейную функцию, точно удовлетворяющую всем наблюдениям, и возникает необходимость оптимизации, т.е. нахождения оценок параметров модели, при которых линейная функция дает наилучшее приближение для имеющихся наблюдений.
Самым распространенным методом оценки параметров модели множественной линейной регрессии является метод наименьших квадратов (МНК). Для применения МНК необходима выполнимость ряда предпосылок, которые позволят проводить анализ в рамках классической линейной модели множественной регрессии (КЛММР).
Предпосылки МНК
1) Математическое ожидание случайных отклонений 𝜀𝑖 равно нулю: 𝑀 𝜀𝑖 = 0 для всех наблюдений. Это означает, что случайное отклонение не должно иметь систематического смещения.
2) Дисперсия случайных отклонений постоянна для всех наблюдений: 𝐷 𝜀𝑖 = 𝑀 𝜀𝑖 2 = 𝜎 2, 𝑖 = 1, 2, …, 𝑛. Выполнимость данной предпосылки называется гомоскедастичностью, а невыполнимость ее называется гетероскедастичнстью.
3) Случайные отклонения 𝜀𝑖 и 𝜀𝑗 (i ≠ j) не коррелируют (отсутствует автокорреляция): 𝑀 𝜀𝑖, 𝜀𝑗 = 0, 𝑖 ≠ 𝑗.
4) Случайные отклонения должны быть статистически независимы (некоррелированы) от объясняющих переменных.
5) Отсутствие мультиколлинеарности. Между объясняющими переменными отсутствует строгая (сильная) линейная зависимость.
6) Отклонения 𝜀𝑖, 𝑖 = 1, 2, …, 𝑛 имеют нормальные распределения 𝜀𝑖 ≅ 𝑁(0; 𝜎 2)Выполнимость данной предпосылки важна для проверки статистических гипотез и построения интервальных оценок. Замечание: При построении классических линейных регрессионных моделей считается также, что объясняющие переменные не являются случайными величинами.
(Расчет см в вопросе 11!)
11. Расчет коэффициентов уравнения множественной линейной регрессии.
Истинные значения коэффициентов bj по выборке получить невозможно. Вместо теоретического уравнения оценивается эмпирическое уравнение регрессии для индивидуальных наблюдений: 𝑦𝑖 = 𝑏0 + 𝑏1 𝑥𝑖1 + 𝑏2 𝑥𝑖2 + ⋯ + 𝑏𝑚 𝑥𝑖𝑚 + 𝑒𝑖. Здесь 𝑏0, 𝑏1, 𝑏2, …, 𝑏𝑚 - эмпирические коэффициенты регрессии (оценки теоретических коэффициентов (𝛽0, 𝛽1, 𝛽2, …, 𝛽𝑚). 𝑒𝑖 - остатки (оценки отклонений 𝜀𝑖).
Согласно МНК, для нахождения оценок 𝑏0; 𝑏1; …; 𝑏𝑚 минимизируется сумма квадратов остатков:
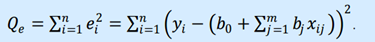
Данная функция является квадратичной относительно неизвестных коэффициентов. Она ограничена снизу, следовательно, имеет минимум. Необходимым условием минимума Qe является равенство нулю частных производных
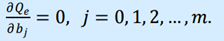
Приравнивая их к нулю, получаем систему m + 1 линейных уравнений с m + 1 неизвестными:
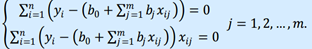
Эта система называется системой нормальных уравнений. Данные реальных статистических наблюдений всегда приводят к единственному решению этой системы. В случае множественной линейной регрессии удобнее искать коэффициенты уравнения регрессии, используя матричный метод решения.
Представим данные наблюдений и соответствующие коэффициенты в
матричной форме:

Х – матрица объясняющих переменных размера n × (m+1), в которой xij – значение переменной Xj в i-м наблюдении; 1 (единица в первом столбце) соответствует переменной при b0.
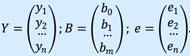
Здесь Y – матрица размера n × 1 наблюдаемых значений зависимой переменной Y; B - матрица размера (m+1) × 1 оценок коэффициентов модели; е – матрица остатков размера n × 1 (отклонений наблюдаемых значений 𝑦𝑖 от расчетных значений 𝑦 𝑖 = 𝑏0 + 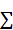 𝑏𝑗 *𝑥𝑖𝑗, получаемых по линии регрессии).
𝑏𝑗 *𝑥𝑖𝑗, получаемых по линии регрессии).
Уравнение регрессии в матричной форме: 𝑌 = 𝑋𝐵 + 𝑒.; 𝑒 = 𝑌 − 𝑋𝐵.
Функция, которая минимизируется 𝑄𝑒 = ∑𝑒𝑖^2.
Общая формула вычисления вектора B оценок коэффициентов модели множественной линейной регрессии: 𝐵 = (( 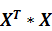 )^ (−1)) *
)^ (−1)) * 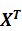 *Y
*Y
ПОЛЕСЛЕ ЭТОГО ПОЛУЧЕННАЯ МАТРИЦА «В» И ЕСТЬ КОЭФФИЦИЕНТЫ Т.Е. ЭТО 𝑦𝑖 = 𝑏0 + 𝑏1 𝑥𝑖1 + 𝑏2 𝑥𝑖2 + ⋯ + 𝑏𝑚 𝑥𝑖𝑚
Здесь 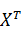 – транспонированная матрица 𝑋;
– транспонированная матрица 𝑋; 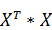 - произведение матриц, матрица ()^ (−1) - обратная к матрице .
- произведение матриц, матрица ()^ (−1) - обратная к матрице .
Вывод: Полученные общие соотношения справедливы для уравнений регрессии с произвольным количеством m объясняющих переменных.
12. Множественная линейная регрессия. Дисперсии и стандартные ошибки коэффициентов. Коэффициенты R 2 и Ṝ 2.
Обычно на любой экономический показатель влияет не один, а несколько факторов. В этом случае вместо функции парной регрессии 𝑀(𝑌|𝑋 = 𝑥) = 𝑓(𝑥) рассматривается функция множественной регрессии: 𝑀(𝑌|𝑋1 = 𝑥1; 𝑋2 = 𝑥2; …; 𝑋𝑚 = 𝑥𝑚) = 𝑓(𝑥1; 𝑥2; …; 𝑥𝑚).
Теоретическая модель множественной линейной регрессии имеет вид: 𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑚 𝑋𝑚 + 𝜀 (5.2) или для индивидуальных наблюдений: 𝑦𝑖 = 𝛽0 + 𝛽1 𝑥𝑖1 + 𝛽2 𝑥𝑖2 + ⋯ + 𝛽𝑚 𝑥𝑖𝑚 + 𝜀, (5.3) 𝑖 = 1, 2, … 𝑁, где N – объем генеральной совокупности. (ИЛИ 𝑦𝑖 = 𝑏0 + 𝑏1 𝑥𝑖1 + 𝑏2 𝑥𝑖2 + ⋯ + 𝑏𝑚 𝑥𝑖𝑚)

Для проверки качества уравнения регрессии в целом используется коэффициент детерминации R^2, который в общем случае рассчитывается по формуле:
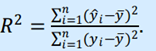
Величина R^2 является мерой объясняющего качества уравнения регрессии по сравнению с горизонтальной линией y= 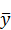 .
.
Справедливо соотношение 0<=R2<=1. Чем ближе этот коэффициент к единице, тем больше уравнение множественной регрессии объясняет поведение Y.
Для множественной регрессии коэффициент детерминации является неубывающей функциейчисла объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R2, так как каждая последующая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной.
Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы, т.е. вводится так называемый скорректированный (исправленный) коэффициент детерминации:
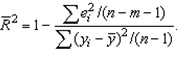
Соотношение может быть представлено в следующем виде:

13. Множественная линейная регрессия. Предпосылки метода наименьших квадратов.
Обычно на любой экономический показатель влияет не один, а несколько факторов. В этом случае вместо функции парной регрессии 𝑀(𝑌|𝑋 = 𝑥) = 𝑓(𝑥) рассматривается функция множественной регрессии: 𝑀(𝑌|𝑋1 = 𝑥1; 𝑋2 = 𝑥2; …; 𝑋𝑚 = 𝑥𝑚) = 𝑓(𝑥1; 𝑥2; …; 𝑥𝑚).
Теоретическая модель множественной линейной регрессии имеет вид: 𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + ⋯ + 𝛽𝑚 𝑋𝑚 + 𝜀 (5.2) или для индивидуальных наблюдений: 𝑦𝑖 = 𝛽0 + 𝛽1 𝑥𝑖1 + 𝛽2 𝑥𝑖2 + ⋯ + 𝛽𝑚 𝑥𝑖𝑚 + 𝜀, (5.3) 𝑖 = 1, 2, … 𝑁, где N – объем генеральной совокупности. (ИЛИ 𝑦𝑖 = 𝑏0 + 𝑏1 𝑥𝑖1 + 𝑏2 𝑥𝑖2 + ⋯ + 𝑏𝑚 𝑥𝑖𝑚)
Предпосылки МНК
1) Математическое ожидание случайных отклонений 𝜀𝑖 равно нулю: 𝑀 𝜀𝑖 = 0 для всех наблюдений. Это означает, что случайное отклонение не должно иметь систематического смещения.
2) Дисперсия случайных отклонений постоянна для всех наблюдений: 𝐷 𝜀𝑖 = 𝑀 𝜀𝑖 2 = 𝜎 2, 𝑖 = 1, 2, …, 𝑛. Выполнимость данной предпосылки называется гомоскедастичностью, а невыполнимость ее называется гетероскедастичнстью.
3) Случайные отклонения 𝜀𝑖 и 𝜀𝑗 (i ≠ j) не коррелируют (отсутствует автокорреляция): 𝑀 𝜀𝑖, 𝜀𝑗 = 0, 𝑖 ≠ 𝑗. 4 3) Случайные отклонения должны быть статистически независимы (некоррелированы) от объясняющих переменных.
4) Отсутствие мультиколлинеарности. Между объясняющими переменными отсутствует строгая (сильная) линейная зависимость.
5) Отклонения 𝜀𝑖, 𝑖 = 1, 2, …, 𝑛 имеют нормальные распределения 𝜀𝑖 ≅ 𝑁(0; 𝜎 2)Выполнимость данной предпосылки важна для проверки статистических гипотез и построения интервальных оценок.
Замечание: При построении классических линейных регрессионных моделей считается также, что объясняющие переменные не являются случайными величинами.
14. Множественная линейная модель. Проблема мультиколлинеарности.
Мультиколлинеарностью называется высокая степень коррелированности двух или нескольких объясняющих переменных в уравнении множественной регрессии. Крайним случаем мультиколлинеарности является линейная зависимость между объясняющими переменными. Считается, что две переменные 𝑋𝑖 и 𝑋𝑗 сильно коррелированны, если выборочный коэффициент корреляции двух объясняющих переменных 𝑟𝑥𝑖 𝑥𝑗 > 0,7
Поясним. Пусть имеется m объясняющих факторов:𝑋1, 𝑋2, …., 𝑋𝑚. Матрица межфакторной корреляции состоит из парных коэффициентов корреляции и имеет вид:

Наличие мультиколлинеарности можно подтвердить, найдя определитель матрицы межфакторной корреляции. Если 𝑅𝑥𝑥 ≈ 1, то мультиколлинеарность отсутствует, а если 𝑅𝑥𝑥 ≈ 0, то - присутствует. Совершенная мультиколлинеарность является скорее в теории, а практически между некоторыми объясняющими переменными существует очень сильная коореляционная зависимость 𝑟𝑥𝑖 𝑥𝑗 > 0,7, а не функциональная 𝑟𝑥𝑖 𝑥𝑗 = 1.
Последствия мультиколлинеарности:
1. Большие дисперсии (стандартные ошибки) оценок коэффициентов уравнения множественной регрессии. Это расширяет интервальные оценки, ухудшая их точность. Последнее затрудняет нахождение истинных значений оценок коэффициентов.
2. Уменьшаются t-статистики оценок. Оценки имеют малую статистическую значимость, в то время как модель в целом является значимой (имеет высокое значение коэффициент детерминации 𝑅^2).
3. Оценки коэффициентов уравнения по МНК и их стандартные ошибки становятся очень чувствительными к малейшим изменениям данных. Оценки коэффициентов становятся неустойчивыми.
4. Затрудняется определение доли вклада каждой из объясняющих переменных в объясняемую уравнением регрессии дисперсию зависимой переменной.
5. Возможно получение неверного знака у коэффициента регрессии.
15. Множественная линейная модель. Методы определения мультиколлинеарности.
Уравнение линейной множественной регрессии имеет вид 𝑦 = 𝑏0 + 𝑏1 𝑥1 + 𝑏n 𝑥n
Существует несколько признаков, по которым может быть установлено наличие мультиколлинеарности.
1. Коэффициент детерминации R^2 достаточно высок, но некоторые из коэффициентов уравнения множественной линейной регрессии статистически незначимы (имеют низкие t-статистики).
2. Высокая корреляция в уравнении регрессии с двумя объясняющими переменными. Если объясняющих переменных больше двух целесообразнее использовать частные коэффициенты корреляции.
Частным коэффициентом корреляции называется коэффициент корреляции между двумя объясняющими переменными, очищенный от влияния других переменных. Например, при трех объясняющих переменных Х1, Х2, Х3 частный коэффициент корреляции между Х1 и Х3, очищенный от Х2, рассчитывается по формуле:
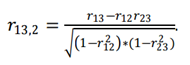
Замечание: частный коэффициент корреляции может существенно отличаться от «обычного» коэффициента корреляции. Для более обоснованного вывода о корреляции между парами объясняющих переменных необходимо рассчитывать все частные коэффициенты корреляции.
Парные коэффициенты корреляции, рассчитанные по формуле:
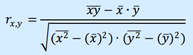
3. Сильная регрессия между объясняющими переменными. Какая- либо из объясняющих переменных является комбинацией других объясняющих переменных (линейной или близкой к линейной).
16. Множественная линейная модель. Методы уменьшения мультиколлинеарности.
Мультиколлинеарность является серьезной проблемой если целью исследования является определение степени влияния каждой из объясняющих переменных на зависимую переменную. Наличие мультиколлинеарности, приводит к увеличению стандартных ошибок, искажая истинные зависимости между переменными. При прогнозировании будущих значений зависимой переменной при высоком коэффициенте детерминации (R 2 >0,9) наличие мультиколлинеарности обычно не сказывается на прогнозных качествах модели.
Единого метода устранения мультиколлинеарности не существует. Это связано с тем, что причины и последствия мультиколлинеарности неоднозначны и во многом зависят от результатов выборки. Перечислим наиболее употребительные методы.
1) Исключение переменной из модели. Простейшим методом устранения мультиколлинеарности является исключение из модели одной или ряда коррелированных переменных. Однако необходима определенная осмотрительность при применении данного метода. В этой ситуации возможны ошибки спецификации. В эконометрических моделях, применяемых в прикладных целях, желательно не исключать объясняющую переменную до тех пор, пока мультиколлинеарность не станет серьезной проблемой.
2) Получение дополнительных данных или новой выборки. Возможно, для уменьшения мультиколлинеарности достаточно увеличить объем выборки. Это сократит дисперсии коэффициентов регрессии и тем самым увеличит их статистическую значимость.
3) Изменение спецификации модели. Иногда проблема мультиколлинеарности может быть решена путем изменения спецификации модели.
4 ) Использование предварительной информации о некоторых параметрах. Возможно, что значения коэффициентов, рассчитанные для каких- либо предварительных моделей, или для аналогичной модели по ранее полученной выборке, могут быть использованы для исследуемой в данный момент модели.
5) Преобразование переменных. Иногда минимизировать либо вообще устранить проблему мультиколлинеарности можно с помощью преобразования переменных: разделив все переменные уравнения множественной регрессии на одну из коррелирующих переменных.
17. Нелинейная регрессия. Виды моделей. Примеры.
Нелинейная регрессия – моделирование экономических зависимостей линейными уравнениями во многих практических случаях дает вполне удовлетворительный результат и может использоваться для анализа и прогнозирования. Из-за многообразия и сложности экономических процессов ограничиться рассмотрением одних лишь линейных регрессионных моделей невозможно. Большинство экономических процессов и, следовательно, отражающих их экономических зависимостей, не являются линейными по своей сути. Моделирование таких процессов линейными уравнениями регрессии не дает положительного результата.
Например, при рассмотрении производственных функций линейная модель не является реалистичной. Обычно при моделировании таких процессов используются степенные модели. Наиболее широкую известность имеет производственная функция Кобба-Дугласа
𝑌 = 𝐴 ∙ 𝐾𝛼∙ 𝐿𝛽
(здесь 𝑌 — объем выпуска; К и L — затраты капитала и труда
соответственно; А, 𝛼 и 𝛽 — параметры модели).
В современном эконометрическом анализе применяются и многие
другие нелинейные модели.
Построение и анализ нелинейных моделей имеют свою специфику. Мы ограничимся рассмотрением нелинейных моделей, допускающих сведение их к линейным. Это так называемые линейные относительно параметров модели. Далее будут рассмотрены модели парной регрессии в силу их простоты, а также примеры применения нелинейных уравнений с несколькими объясняющими переменными.
Виды моделей:
1. Логарифмические модели
2. Полулогарифмические модели
3. Лог-линейная модель
4. Линейно-логарифмическая модель
5. Обратная модель
6. Степенная модель
7. Показательная модель
18. Нелинейная регрессия. Выбор формы модели.
Нелинейная регрессия – моделирование экономических зависимостей линейными уравнениями во многих практических случаях дает вполне удовлетворительный результат и может использоваться для анализа и прогнозирования. Из-за многообразия и сложности экономических процессов ограничиться рассмотрением одних лишь линейных регрессионных моделей невозможно. Большинство экономических процессов и, следовательно, отражающих их экономических зависимостей, не являются линейными по своей сути. Моделирование таких процессов линейными уравнениями регрессии не дает положительного результата.
Выбор формы модели:
Многообразие и сложность экономических процессов предопределяет многообразие моделей, используемых для эконометрического анализа. С другой стороны, это существенно усложняет процесс нахождения максимально адекватной формулы зависимости. Для случая парной регрессии подбор модели обычно осуществляется по виду расположения наблюдаемых точек на корреляционном поле. Однако нередки ситуации, когда расположение точек приблизительно соответствует нескольким функциям и необходимо из них выявить наилучшую. Например, криволинейные зависимости могут аппроксимироваться полиномиальной, показательной, степенной, логарифмической функциями. Еще более неоднозначна ситуация для множественной регрессии, так как наглядное представление статистических данных в этом случае невозможно.
Правильный выбор вида экономической модели является отправной точкой для качественного ее анализа. На практике неизвестно, какая модель является верной, и зачастую подбирают такую модель, которая наиболее точно соответствует реальным данным. Поэтому, чтобы выбрать качественную модель, необходимо ответить на ряд вопросов, возникающих при ее анализе:
1. Каковы признаки «хорошей» (качественной) модели?
2. Какие ошибки спецификации встречаются, и каковы последствия данных ошибок?
3. Как обнаружить ошибку спецификации?
4. Каким образом можно исправить ошибку спецификации и перейти к лучшей (качественной) модели?
19. Нелинейная регрессия. Проблемы спецификации.
Нелинейная регрессия – моделирование экономических зависимостей линейными уравнениями во многих практических случаях дает вполне удовлетворительный результат и может использоваться для анализа и прогнозирования. Из-за многообразия и сложности экономических процессов ограничиться рассмотрением одних лишь линейных регрессионных моделей невозможно. Большинство экономических процессов и, следовательно, отражающих их экономических зависимостей, не являются линейными по своей сути. Моделирование таких процессов линейными уравнениями регрессии не дает положительного результата.
Проблемы спецификации:
Стандартная схема анализа функциональных зависимостей состоит в осуществлении ряда последовательных процедур.
Подбор начальной модели. Он осуществляется на основе экономической теории, предыдущих знаний об объекте исследования, опыта исследователя и его интуиции.
Оценка параметров модели на основе имеющихся статистических данных.
Осуществление тестов проверки качества модели (обычно используются t-статистики для коэффициентов регрессии, F- статистика для коэффициента детерминации, статистика Дарвина- Уотсона для анализа отклонений и ряд других тестов).
При наличии хотя бы одного неудовлетворительного ответа по какому-либо тесту модель совершенствуется с целью устранения выявленного недостатка.
При положительных ответах по всем проведенным тестам модель считается качественной. Она используется для анализа и прогноза объясняемой переменной.
Несколько важных замечаний.
1. Необходимо предостеречь от абсолютизации полученного результата, поскольку даже качественная модель является подгонкой спецификации модели под имеющийся набор данных. Реальна картина, когда исследователи, обладающие разными наборами данных, строят разные модели для объяснения одной и той же переменной.
2. Проблематичным является и использование модели для прогнозирования значений объясняемой переменной. Иногда хорошие с точки зрения диагностических тестов модели обладают весьма низкими прогнозными качествами.
3. Достаточно спорным является вопрос, как строить модели:
а) начинать с самой простой и постоянно усложнять ее;
б) начинать с максимально сложной модели и упрощать ее на основе
проводимых исследований.
Оба подхода имеют как достоинства, так и недостатки. Например, если следовать схеме а), то происходит обыкновенная подгонка модели под эмпирические данные. При теоретически более оправданном подходе б) поиск возможных направлений совершенствования модели зачастую сводится к полному перебору, что делает проводимый анализ неэффективным. На этапах упрощения модели возможно также отбрасыва- ние объясняющих переменных, которые были бы весьма полезны в упрощенной модели.
Вывод: построение модели является индивидуальным в каждой конкретной ситуации и опирается на серьезные знания экономической теории и статистического анализа.
20. Суть гетероскедастичности.
Одной из ключевых предпосылок МНК является условие постоянства дисперсий случайных отклонений: дисперсия случайных отклонений 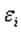 постоянна.
постоянна. 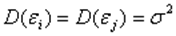 для любых наблюдений i иj.
для любых наблюдений i иj.
Выполнимость данной предпосылки называется гомоскедастичностъю (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностъю (непостоянством дисперсий отклонений).
Наличие гетероскедастичности можно наглядно видеть из поля корреляции (рис. 1).
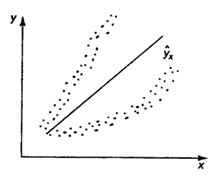
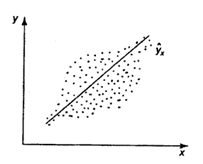
А б
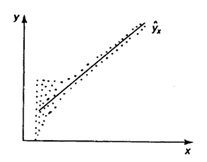
в
Рис. 1 Примеры гетероскедастичности.
На рис. 1 изображено: а – дисперсия остатков растет по мере увеличения 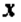 ; б – дисперсия остатков достигает максимальной величины при средних значениях переменной и уменьшается при минимальных и максимальных значениях; в – максимальная дисперсия остатков при малых значениях и дисперсия остатков однородна по мере увеличения значений.
; б – дисперсия остатков достигает максимальной величины при средних значениях переменной и уменьшается при минимальных и максимальных значениях; в – максимальная дисперсия остатков при малых значениях и дисперсия остатков однородна по мере увеличения значений.
21. Последствия гетероскедастичности.
Последствия гетероскедастичности:
– Оценки коэффициентов по-прежнему останутся несмещёнными и линейными.
– Оценки не будут эффективными (т. е, они не будут иметь наименьшую дисперсию по сравнению с другими оценками данного параметра), Они не будут даже асимптотически эффективными. Увеличение дисперсии оценок снижает вероятность получения максимально точных оценок.
– Дисперсии оценок будут рассчитываться со смещением.
Поэтому выводы, получаемые на основе соответствующих t- и F- статистик, а также интервальные оценки коэффициентов регрессии будут ненадежными. Следовательно, статистические выводы, могут быть ошибочными и приводить к неверным заключениям по построенной модели.
22. Обнаружение гетероскедастичности.
Обнаружение гетероскедастичности в каждом конкретном случае является сложной задачей. Для знания дисперсий отклонений необходимо знать распределение случайной величины Y, соответствующее выбранному значению 𝑥𝑖. Практически, для каждого конкретного значения 𝑥𝑖определяется единственное значение 𝑦𝑖, что не позволяет оценить дисперсию случайной величины Y. Поэтому, не существует какого-либо однозначного метода определения гетероскедастичности.
Наиболее популярным является тест Голдфелда-Квандта.
Данный тест используется для проверки следующего типа гетероскедастичности: когда среднее квадратическое отклонение случайной составляющей 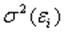 пропорционально значению признака-фактора
пропорционально значению признака-фактора 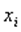 в
в 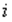 -м наблюдении. При этом делается предположение, что случайная составляющая распределена нормально.
-м наблюдении. При этом делается предположение, что случайная составляющая распределена нормально.
Алгоритм-тест Голдфелда-Квандта приведен ниже.
Все наблюдения 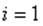 ;
; 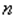 упорядочиваются по значению.
упорядочиваются по значению.
Оценивается регрессия: 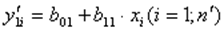 для первых
для первых 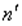 наблюдений.
наблюдений.
Оценивается регрессия: 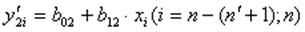 для последних наблюдений
для последних наблюдений 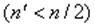 .
.
Рассчитывают суммы квадратов отклонений фактических значений признака-результата от его расчетных значений для обеих регрессий:
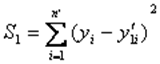 и
и 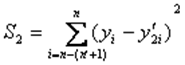 .
.
Находят отношение сумм квадратов отклонений: 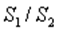 (или
(или 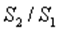 ). В числителе должна быть наибольшая из сумм квадратов отклонений. Данное отношение имеет
). В числителе должна быть наибольшая из сумм квадратов отклонений. Данное отношение имеет 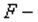 распределение со степенями свободы:
распределение со степенями свободы: 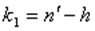 и
и  , где
, где 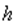 - число оцениваемых параметров в уравнении регрессии.
- число оцениваемых параметров в уравнении регрессии.
Если 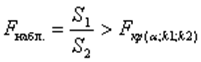 , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Если в модели более одного фактора, то наблюдения должны упорядочиваться по тому фактору, который, как предполагается, теснее связан с, и должно быть больше, чем.
23. Методы смягчения проблемы гетероскедастичности.
При наличии гетероскедастичности 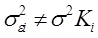 и величина Ki может меняться от одного значения фактора к другому. При наличии гетороскедастичности вместо обычного МНК используют обобщенный МНК (взвешенный). Суть метода заключается в уменьшении вклада данных наблюдений, имеющих большую дисперсию в результате расчета.
и величина Ki может меняться от одного значения фактора к другому. При наличии гетороскедастичности вместо обычного МНК используют обобщенный МНК (взвешенный). Суть метода заключается в уменьшении вклада данных наблюдений, имеющих большую дисперсию в результате расчета.
1 случай. Если дисперсии возмущений известны 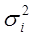 , то гетероскедастичность легко устраняется. Вводят новые переменные:
, то гетероскедастичность легко устраняется. Вводят новые переменные: 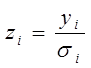 ;
; 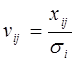 ;
;  ,
, 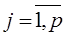 . Регрессионная модель в векторной форме
. Регрессионная модель в векторной форме
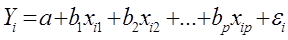 (*) /:
(*) /: 
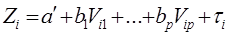 ,
, 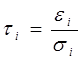 .
.
При этом 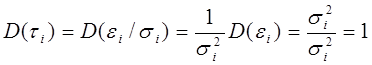 , т.е. модель гомоскедастична.
, т.е. модель гомоскедастична.
2 случай. Если дисперсии возмущений неизвестны, то делают реалистические предположения о значениях 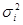 .
.
Например:
а) дисперсии 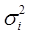 пропорциональны xi:
пропорциональны xi: 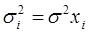 . Уравнение регрессии (*) делят
. Уравнение регрессии (*) делят
- на 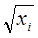 - в случае одной переменной; - на
- в случае одной переменной; - на 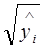 - в случае множественной регрессии.
- в случае множественной регрессии.
б) дисперсии 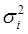 пропорциональны
пропорциональны 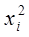 , т.е.
, т.е.
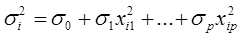 ,
,
Уравнение регрессии (*) делят на хi.
24. Временные ряды. Основные составляющие временного ряда.
Временной ряд – это набор чисел, привязанный к последовательным, обычно равноотстоящим моментам времени. Числа, составляющие временной ряд и получающиеся в результате наблюдения за ходом некоторого процесса, называются уровнями временного ряда или элементами. Под длиной временного ряда понимают количество входящих в него уровней n. Временной ряд обычно обозначают Y(t), или Yt, где t= 1,2,…, n.
В общем случае каждый уровень временного можно представить как функцию четырех компонент: f (t), S (t), U (t), E (t), отражающих закономерность и случайность развития.
Где f (t) – тренд (долговременная тенденция) развития; S (t) – сезонная компонента; U (t) –циклическая компонента; E (t)– остаточная компонента.
В модели временного ряда принято выделять две основные составляющие: детерминированную (систематическую) и случайную. Под детерминированной составляющей временного ряда y1,y2 …yn понимают числовую последовательность, элементы которой вычисляются по определенному правилу как функция времени t. Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять случайные скачки, а в другом – плавное колебательное движение.
В анализе случайного компонента экономических временных рядов важную роль играет сравнение случайной величины Et c хорошо изученной формой случайных процессов - стационарными случайными процессами.
Стационарным процессом в узком смысле называется такой случайный процесс, вероятностные свойства которого с течением времени не изменяются. Он протекает в приблизительно однородных условиях и имеет вид непрерывных случайных колебаний вокруг некоторого среднего значения. Причем ни средняя амплитуда, ни его частота не обнаруживают с течением времени существенных изменений.
Однако на практике чаще встречаются процессы, вероятностные характеристики которых подчиняются определенным закономерностям и не являются постоянными величинами. Поэтому в прикладном эконометрическом анализе используется понятие слабой стационарности (или стационарности в широком смысле), которое предполагает неизменность




