Основы вариационной статистики
Вариационная статистика - раздел математической статистики, изучающий распределение количественных признаков в статистических совокупностях. В однородных совокупностях имеются признаки, изменяющиеся от одной единицы к другой (диаметр отдельных деревьев в древостое, прирост высоты саженцев в лесных культурах одного года посадки и т.д.).
Группировка единиц по величине варьируемого признака дает вариационные ряды, которые составляют предмет вариационной статистики. Для этих рядов вычисляются: средняя величина, среднее квадратическое отклонение, показатели меры косости и крутости, мода, медиана и др.
Вариационная статистика рассматривает вопросы построения теоретических распределений, измерения связи между варьирующими признаками, количественные критерии оценки достоверности полученных показателей. В целом вариационная статистика применяется при математической обработке результатов наблюдений и дает методы объективной обработки информации для лесоводства, лесной таксации и др.
Основные понятия статистики
Одно из основных понятий статистики - переменные - это то, что можно измерять, контролировать или что можно изменять в исследованиях. Переменные отличаются многими аспектами, особенно той ролью, которую они играют в исследованиях, шкалой измерения и т.д.
Независимыми переменными называются переменные, которые варьируются исследователем, тогда как зависимые переменные - это переменные, которые измеряются или регистрируются. Другими словами, зависимость проявляется в ответной реакции исследуемого объекта на посланное на него воздействие.
В исследовании корреляций (зависимостей, связей) вы не влияете (или, по крайней мере, пытаетесь не влиять) на переменные, а только измеряете их и хотите найти взаимосвязь между некоторыми измеренными переменными, например, между высотой и диаметром дерева. В экспериментальных исследованиях, напротив, вы варьируете некоторыми переменными и измеряете воздействия этих изменений на другие переменные. Например, исследователь может искусственно отбирает деревья определенной высоты, а затем для определенных уровней высот измерить диаметр деревьев. Анализ данных в экспериментальном исследовании также приходит к вычислению "корреляций" (зависимостей) между переменными, а именно, между переменными, на которые воздействуют, и переменными, на которые влияет это воздействие. Тем не менее, экспериментальные данные потенциально снабжают нас более качественной информацией. Только экспериментально можно убедительно доказать причинную связь между переменными. Например, если обнаружено, что всякий раз, когда изменяется переменная x, изменяется и переменная y, то можно сделать вывод - "переменная x оказывает влияние на переменную y ", т.е. между переменными x и y имеется причинно-следственная связь.
Переменные различаются также тем "насколько хорошо" они могут быть измерены или, другими словами, как много измеряемой информации обеспечивает шкала их измерений. Очевидно, в каждом измерении присутствует некоторая ошибка, определяющая границы "количества информации", которое можно получить в данном измерении. Другим фактором, определяющим количество информации, содержащейся в переменной, является тип шкалы, в которой проведено измерение. Различают следующие типы шкал:
· номинальная;
· порядковая (ординальная);
· интервальная;
· относительная (шкала отношения).
Соответственно, имеем четыре типа переменных:
· Номинальные переменные используются только для качественной классификации. Это означает, что данные переменные могут быть измерены только в терминах принадлежности к некоторым, существенно различным классам; при этом вы не сможете определить количество или упорядочить эти классы. Типичные примеры номинальных переменных - порода, тип почвы, цвет, и т.д.
· Порядковые переменные позволяют ранжировать (упорядочить) объекты, указав какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако они не позволяют сказать "насколько больше" или "насколько меньше". Типичный пример порядковой переменной - бонитет древостоя.
· Интервальные переменные позволяют не только упорядочивать объекты измерения, но и численно выразить и сравнить различия между ними. Например, диаметр деревьев, измеренный в сантиметрах или метрах (от 20 до 40 см), образует интервальную шкалу. Здесь можно сказать, что дерево диаметром 40 см больше, чем диаметром 30 см, но и что увеличение диаметра с 20 до 40 см вдвое больше увеличения диаметра от 30 до 40 см.
· Относительные переменные очень похожи на интервальные переменные. В дополнение ко всем свойствам переменных, измеренных в интервальной шкале, их характерной чертой является наличие определенной точки абсолютного нуля, таким образом, для этих переменных являются обоснованными предложения типа: x в два раза больше, чем y. Типичными примерами шкал отношений являются измерения времени или пространства. Например, температура по Кельвину образует шкалу отношения, и вы можете не только утверждать, что температура 200 градусов выше, чем 100 градусов, но и что она вдвое выше. Интервальные шкалы (например, шкала Цельсия) не обладают данным свойством шкалы отношения.
Независимо от типа, две или более переменных связаны (зависимы) между собой, если наблюдаемые значения этих переменных распределены согласованным образом. Например, переменная высота дерева связана с его диаметром, потому что обычно высокие особи толще низких и т.д.
Конечная цель всякого исследования или научного анализа состоит в нахождение связей (зависимостей) между переменными. Философия науки учит, что не существует иного способа представления знания, кроме как в терминах зависимостей между количествами или качествами, выраженными какими-либо переменными. Таким образом, развитие науки всегда заключается в нахождении новых связей между переменными. Исследование корреляций по существу состоит в измерении таких зависимостей непосредственным образом. Назначение статистики состоит в том, чтобы помочь объективно оценить зависимости между переменными.
· Величина зависимости. Например, если любая сосна в вашей выборке имеет значение высоты выше чем любая ель, то вы можете сказать, что зависимость между двумя переменными (порода и высота) очень высокая. Другими словами, вы могли бы предсказать значения одной переменной по значениям другой.
· Надежность ("истинность"). Надежность говорит нам о том, насколько вероятно, что зависимость, подобная найденной вами, будет вновь обнаружена (иными словами, подтвердится) на данных другой выборки, извлеченной из той же самой генеральной совокупности. Следует помнить, что конечной целью почти никогда не является изучение данной конкретной выборки; выборка представляет интерес лишь постольку, поскольку она дает информацию обо всей генеральной совокупности.
1.1. Предмет и задачи математической статистики.
В научных исследованиях при проведении экспериментов, при анализе результатов технических измерений и т.п. мы часто сталкиваемся с явлениями, многократно повторяющимися в неизменных условиях. При этом несмотря на постоянство основного комплекса условий результаты опытов отличаются друг от друга, т.е. они испытывают случайное рассеяние. Классическим примером может служить измерение какой-либо величины (например, массы дерева). Если даже исключить систематические погрешности, то все равно окажется, что на результаты опытов будут влиять различные факторы, не поддающиеся контролю. К таковым можно отнести случайные вибрации частей прибора, физиологические изменения в организме, изменения внешней среды.
Хотя результат отдельного измерения при наличии рассеяния невозможно предсказать, это еще не означает, что повторные измерения не обнаруживают никакой закономерности. Установление таких закономерностей, которым подчинены массовые случайные явления как раз и основано на изучении методами математической статистики результатов наблюдений - статистических данных.
· первая задача математической статистики - указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.
· вторая задача математической статистики - разработать методы анализа статистических данных в зависимости от целей исследования. Сюда относятся:
n оценка неизвестной вероятности события; оценка неизвестной функции распределения; оценка параметров распределения, вид которого известен; оценка зависимости между величинами, каждая из которых испытывает вариации под действием случайных факторов (этот раздел носит название теории корреляции);
n проверка статистических гипотез о виде неизвестного распределения и о величине параметров распределения;
n задачи анализа влияния различных факторов на поведение интересующей нас величины рассматриваются в дисперсионном анализе.
Современная математическая статистика разрабатывает способы определения числа необходимых испытаний до начала исследования (планирование эксперимента), в ходе исследования (последовательный анализ) и решает другие задачи, связанные с принятием решений в условиях неопределенности.
Итак, основная задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводов.
1.2.Генеральная и выборочная совокупности.
Пусть мы располагаем каким-то статистическим материалом, например, результатами испытаний плотности древесины. Эти данные представляют интерес для оценки конкретной партии образцов. Если мы на основе этой информации пожелаем сделать выводы относительно более широкого круга явлений - в этом случае могут возникать статистические проблемы. Надо иметь ввиду, что выводы и оценки, основанные на ограниченном материале наблюдений, отражают случайный состав нашей пробной группы и поэтому должны считаться приближенными оценками вероятностного характера. Теория математической статистики указывает, однако, во многих случаях, как наилучшим способом использовать имеющуюся у нас информацию для получения более точных и надежных характеристик, указывая при этом степень надежности наших выводов, объясняющаяся ограниченностью запаса сведений. Возможность такого рода оценок и придает научную ценность нашим заключениям.
Как уже отмечалось, на практике приходится иметь дело с ограниченным числом объектов, т.к. сплошное обследование (исследуется каждый объект) не имеет смысла если связано с большими материальными затратами или с уничтожением объекта. В этих случаях из всей совокупности случайно отбирают ограниченное число объектов и подвергают их изучению.
Выборочной совокупностью или просто выборкой называют совокупность случайно отобранных объектов.
Генеральной совокупностью называют совокупность объектов, из которых производится выборка.
Объемом совокупности называют число объектов этой совокупности.
Например, исследуется прирост древесины на пробной площади, включающей 1000 деревьев. Для обследования из них отобрано 100 шт. В этом случае объем Генеральной совокупности = 1000, объем выборки = 100.
1.3.Способы отбора
При составлении выборки можно поступать 2 способами: после того как объект отобран и над ним произведено наблюдение он может быть возвращен в генеральную совокупность (повторная выборка) или не возвращен (бесповторная выборка).
На практике обычно используется бесповторный случайный отбор.
Чтобы по данным выборки можно было уверенно судить об интересующем признаке генеральной совокупности, необходимо чтобы объекты выборки ее правильно представляли, т.е. выборка должна правильно представлять пропорции генеральной совокупности. Другими словами выборка д.б. репрезентативной (представительной).
В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если ее осуществить случайно (при условии, что все объекты имеют одинаковую вероятность попасть в выборку).
На практике применяют различные способы отбора:
1. Отбор, не требующий деления генеральной совокупности на части
· простой случайный бесповторный отбор;
· простой случайный повторный отбор;
2. Отбор, при котором генеральная совокупность разбивается на части:
· типический отбор;
· механический отбор;
· серийный отбор.
Простым случайным (бесповторным, повторным) называют отбор, при котором объекты извлекаются по одному из генеральной совокупности. При большом объеме генеральной совокупности используют таблицы “случайных чисел” или датчик “случайных чисел”.
Типическим называют отбор, при котором объекты отбираются не из всей генеральной совокупности, а из каждой ее типической части. Например, проба на механические свойства древесины производится не из всей совокупности древесины, а отдельно по районам произрастания.
Механическим называется отбор, при котором генеральную совокупность “механически” делят на столько групп, сколько объектов должно войти в выборку, а из каждой группы отбирают один объект. Например, если нужно отобрать 10% деревьев на пробной площади, то отбирают каждое 10 дерево. Следует указать, что механический отбор иногда не может обеспечить репрезентативности выборки.
Серийным называется отбор, при котором объекты отбираются из генеральной совокупности не по одному, а сериями, которые подвергаются сплошному обследованию. Серийным отбором пользуются тогда, когда обследуемый признак колеблется в различных сериях незначительно.
На практике часто применяется комбинированный отбор.
1.4. Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка, причем x1 наблюдалось n1 раз, x2 - n2 раз, xk - nk и Sni = n объем выборки.
Наблюдаемые значения ni называют вариантами, а последовательность вариант, записанных в возрастающем порядке - вариационным рядом. Числа наблюдений называются частотами, а их отношения к объему выборки ni/n = w - относительными частотами.
Статистическим распределением выборки называют перечень вариант и соответствующих им частот или относительных частот. Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (в качестве частоты, соответствующей интервалу, принимают сумму частот, попавших в этот интервал.
Пример: задано распределение частот выборки объема n = 20
xi 2 4 5
ni 3 10 6
Найти относительные частоты. Сумма относительных частот д.б. равна 1.
Основы теории вероятностей
Понятие случайной величины
Специалист лесного хозяйства имеет дело со случайными величинами. Любой биометрический признак деревьев в пределах древостоя (диаметр, высота, объем и т.д.) - случайные величины, меняющие свое значение от объекта к объекту в пределах однородной совокупности. Причем заранее предсказать каждое из этих значений случайной величины невозможно. Случайные величины, возможные значения которых можно заранее перечислить, называются дискретными. Если же возможные значения случайных величин непрерывно заполняют некоторый промежуток, то они называются непрерывными.
Все значения, которые может принимать случайная величина, составляют генеральную совокупность. Она может состоять из конечного числа случайной величины или быть бесконечной. Во всех случаях в одну генеральную совокупность объединяются случайные величины, сходные по своей внутренней природе. Они должны представлять собой биологическое единство, которое сформировалось под воздействием одинаковых внешних и внутренних факторов среды. Нельзя, например, объединять в одну генеральную совокупность древостои двух разных поколений леса, хотя и произрастающих совместно.
1.3.2. Классическое и статистическое определения вероятности события
Вероятностью появления какого-либо события называется отношение числа случаев, благоприятствующих появлению этого события (M), к общему числу всех возможных случаев (N):
P=M/N. (1.1)
Пример 1.1. На пробной площади 300 деревьев. Из них 100 поражены грибом. Вероятность того, что наудачу взятое дерево окажется пораженным, равна P=100/300=1/3, а здоровым (300-100)/300=2/3.
Событие достоверно, если его вероятность равна 1, т.е. все шансы благоприятны. Событие вероятно, если вероятность его более 0,5. Событие маловероятно, если его вероятность меньше 0,5. Сумма вероятностей всех событий, взаимоисключающих друг друга, в пределах совокупности равна 1.
Понятие вероятности относят только к генеральной совокупности. Так как в практике можно установить только значения частот и частостей, то вероятность можно оценить только с некоторой долей надежности. На основе теории вероятностей разработан метод оценки результатов наблюдений, т.е. оценки степени надежности вывода - коэффициент достоверности t.
Глава 2.
Постановка задачи
Результаты наблюдения над лесохозяйственными объектами обычно фиксируются в журналах, бланках, анкетах и других документах учета или заносятся непосредственно в соответствующие файлы портативных компьютеров. Зафиксированные сведения об изучаемом объекте представляют первичный фактический материал, который нуждается в соответствующей обработке с целью исследования генеральной совокупности. На практике инженер лесного хозяйства имеет дело только с выборочной совокупностью (выборкой), т.е. частью генеральной совокупности, поэтому возникает потребность по результатам сравнительно небольшой выборки сделать предположение о поведении всей генеральной совокупности. В других случаях необходимо какой-либо совокупности величин поставить в соответствие другую совокупность и выяснить, имеется ли между ними различия, какая-либо взаимосвязь или нет.
Для того, чтобы сделать статистическое заключение о рассматриваемом объекте, следует выполнить ряд взаимосвязанных операций:
1. Грамотно обеспечить отбор единиц выборочной совокупности;
2. Систематизировать и сгруппировать результаты наблюдений;
3. Графически представить эмпирические совокупности;
4. Получить статистические показатели для эмпирических совокупностей;
5. Получить статистические параметры для генеральной совокупности.
Единицы выборочной совокупности (варианты) должны быть отобраны так, чтобы по ним с достаточной точностью можно было судить о свойствах генеральной совокупности.
2.2. Классификация и группировка вариант
Первичные данные наблюдений представляют собой ряд значений, записанных (или занесенных непосредственно в файл компьютера) в последовательности получения. Такой ряд называется статистической совокупностью, а каждый член этой совокупности - вариантой. Число вариант в совокупности представляет объем совокупности N.
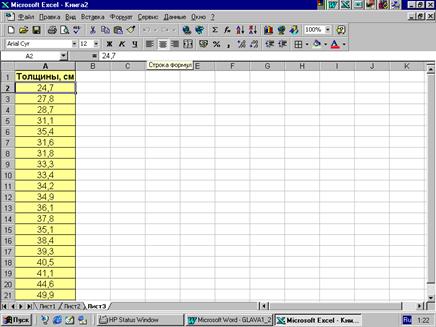
Пример 2.1. Пусть получена статистическая совокупность диаметров (см) деревьев сосны обыкновенной на пробной площади. Объем совокупности
N =20: 28,7; 31,1; 38,1; 35,4; 38,0; 49,9; 37,8; 34,9; 39,3; 41,0; 33,4; 36,1; 34,2; 44,6; 40,5; 24,7; 31,8; 27,8; 31,6; 33,0. Файл данных в среде программы MSExcel может выглядеть следующим образом (рис. 2.1):
Рис. 2.1.
Статистическая обработка первичных данных начинается с расположения вариант в определенной последовательности, зависящей от характера варьирования изучаемого признака:
- Количественное:
· непрерывное;
· дискретное.
2. Качественное:
· атрибутивное.
При непрерывном варьировании отдельные значения признака могут иметь любое значение меры (протяженности, объема, веса и т.д.) в определенных пределах. Например, толщина деревьев в древостое принимает различные значения меры протяженности от самого тонкого до самого толстого.
При дискретном варьировании отдельные значения признака выражаются отвлеченными числами (чаще всего целыми). Например, число деревьев на пробной площади, диаметр деревьев в ступенях (классах) толщины и т.д.
При атрибутивном варьировании значения признака классифицируют по градациям этого признака. Например, цвет, повреждаемость, класс бонитета и т.д.
При количественном варьировании первоначальное упорядочивание совокупности проводят в порядке возрастания или убывания. При малом числе вариант (до 20) строится непосредственный ряд значений.
Пример 2.2. Упорядоченный ряд значений толщины деревьев по данным примера 2.1 может быть получен в программе MSExcel с помощью процедуры "Сортировка", которая находится в меню "Данные" (рис. 2.2).
При большем объеме выборки (N >20) ранжированный ряд не обладает свойством наглядности. Поэтому значение признака размещают с указанием числа их повторяемости в виде двойного ряда. В первой строке (столбце) заносят значение признака, а во второй строке (столбце) указывают число повторяющихся значений.
Пример 2.3. Двойной ряд значений толщины деревьев в примере 2.1 может быть получен в программе MSExcel с помощью статистической функции "ЧАСТОТА" (рис. 2.3).
Размещение значений признака в порядке их возрастания (убывания) с указанием числа их повторяемости называют вариационным рядом. В вариационном ряду значения признака, разнесенные по классам, называют распределением частот. Очевидно, что сумма частот равна объему выборки N (см. рис. 2.3).
Величина классового промежутка, на которую разбивается ряд варьирующих значений признака определяется по формуле:
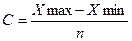 ,
,
где
X max, X min – максимальное и минимальное значения признака;
n – число классовых промежутков.
Число классовых промежутков зависит от объема выборки и ориентировочно равно корню квадратному из числа наблюдений.
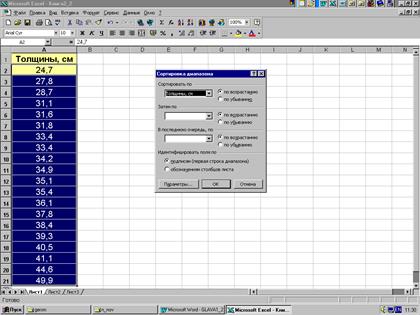
Рис. 2.2.
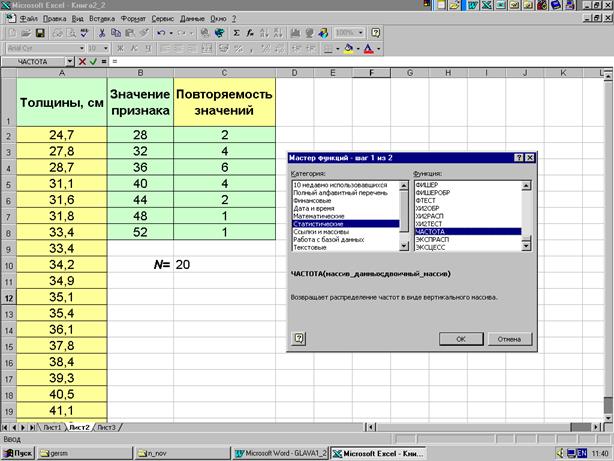
Рис. 2.3.
LECTURE
Средняя гармоническая — используется в тех случаях когда известны индивидуальные значения признака x и произведение  , а частоты
, а частоты 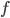 неизвестны.
неизвестны.
Среднегармоническую величину можно определить по следующей формуле:
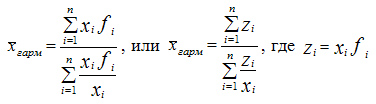
В примере ниже 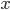 — прирост древесины на гектар известен, — площадь выдела неизвестна, — прирост древесины с выдела.
— прирост древесины на гектар известен, — площадь выдела неизвестна, — прирост древесины с выдела.
Пример. Вычислить прирост древесины по трем выделам
| Выдел
| прирост древесины м3/га (х)
| прирост древесины с выдела П (z = x*f)
|
|
| 18,2
|
|
|
| 20,4
|
|
|
| 23,5
|
|
| Итого
|
|
|
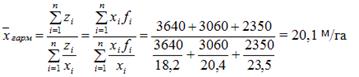
Ответ: 20,1 м3/га
Мода и медиана.
Мода (Мо) это наиболее часто встречающийся вариант ряда. Модой для дискретного ряда является варианта, обладающая наибольшей частотой.
В ряду:
Mo =28 см.
При вычислении моды для интервального вариационного ряда необходимо сначала определить модальный интервал (по максимальной частоте), а затем — значение модальной величины признака по формуле:
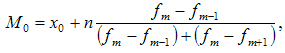
где:
-
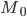 — значение моды
— значение моды -
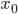 — нижняя граница модального интервала
— нижняя граница модального интервала -
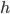 — величина интервала
— величина интервала -
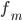 — частота модального интервала
— частота модального интервала -
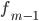 — частота интервала, предшествующего модальному
— частота интервала, предшествующего модальному -
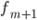 — частота интервала, следующего за модальным
— частота интервала, следующего за модальным
.
Медианой (Mе) называют возможное значение признака, которое делит вариационный ряд выборки на две равные части: 50 % «нижних» единиц ряда данных будут иметь значение признака не больше, чем медиана, а «верхние» 50 % — значения признака не меньше, чем медиана..
Среди значений 5; 6; 7; 8; 9 Mе = 7.
Для определения медианы в дискретном ряду при наличии частот сначала вычисляют полусумму частот 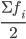 , а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
, а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
Ме = (n(число признаков в совокупности) + 1)/2,
в случае четного числа признаков медиана будет равна средней из двух признаков находящихся в середине ряда).
При вычислении медианы для интервального вариационного ряда сначала определяют медианный интервал, в пределах которого находится медиана, а затем — значение медианы по формуле:
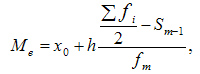
где:
-
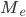 — искомая медиана
— искомая медиана -
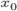 — нижняя граница интервала, который содержит медиану
— нижняя граница интервала, который содержит медиану - — величина интервала
-
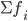 — сумма частот или число членов ряда
— сумма частот или число членов ряда -
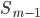 - сумма накопленных частот интервалов, предшествующих медианному
- сумма накопленных частот интервалов, предшествующих медианному - — частота медианного интервала
Пример 1. Найти моду и медиану.
| Возраст
| Число деревьев
| Сумма накопленных частот
|
| До 20 лет
|
|
|
| 20 — 25
|
|
|
| 25 — 30
|
|
|
| 30 — 35
|
|
|
| 35 — 40
|
|
|
| 40 — 45
|
|
|
| 45 лет и более
|
|
|
| Итого
|
|
|
Решение:
В данном примере модальный интервал находится в пределах возрастной группы 25-30 лет, так как на этот интервал приходится наибольшая частота (1054).
Рассчитаем величину моды:
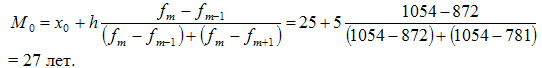
Это значит что модальный возраст древостоя равен 27 годам.
Вычислим медиану. Медианный интервал находится в возрастной группе 25-30 лет, так как в пределах этого интервала расположена варианта, которая делит совокупность на две равные части (∑fi/2 = 3462/2 = 1731). Далее подставляем в формулу необходимые числовые данные и получаем значение медианы:
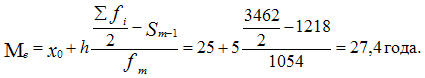
Это значит что одна половина деревьев имеет возраст до 27,4 года, а другая свыше 27,4 года.
Пример 2.
Для ряда распределения 94 деревьев по ступеням толщины Ме = 30
Me = 26 + 4 [(47 - 19)/28] = 30 см.
Использование функции МОДА() и МЕДИАНА() в MSExcel
Функция МОДА() возвращает наиболее часто встречающееся значение в массиве или интервале данных. Синтаксис: МОДА (число1;число2;...), где число1, число2,... - это от 1 до 30 аргументов, для которых вычисляется мода. Можно использовать один массив или одну ссылку на массив вместо аргументов, разделяемых точкой с запятой. МОДА ({5,6; 4; 4; 3; 2; 4}) равняется 4.
Функция МЕДИАНА() возвращает число, которое является серединой множества заданных чисел. Синтаксис: МЕДИАНА (число1;число2;...), где число1, число2,... - это от 1 до 30 чисел, для которых определяется медиана. МЕДИАНА (1; 2; 3; 4; 5) равняется 3. МЕДИАНА (1; 2; 3; 4; 5; 6) равняется 3,5, среднее 3 и 4.
Показатели вариации
Средняя величина не дает полного представления о свойствах изучаемой совокупности. Являясь показателем центральной тенденции, т. е. наиболее представительной характеристикой изучаемого объекта, она не характеризует степени изменчивости, варьирования составляющих его единиц. Действительно, ряды из вариант 1, 3, 4, 5, 7 и 3, 4, 4, 4, 5 характеризуются одинаковой средней арифметической х =4, но отличаются по степени вариации значений признака.
Доверие к средней величине может быть определено лишь постольку, поскольку дана оценка варьированию величин в рассматриваемой совокупности вариант. Одной из целей статистических методов является выявление вариации, которая характеризуется рядом показателей:
· размах варьирования;
· дисперсия;
· среднее квадратическое отклонение;
· коэффициент вариации.
Размах варьирования. Разность между наибольшим и наименьшим значением признака называется размахом, который является грубым показателем варьирования признака. Опираясь лишь на два крайних члена ряда, величина размаха не учитывает внутреннего, между этими крайними значениями, рассеяния вариант. Кроме того, крайние значения как редко встречающиеся члены ряда весьма неустойчивы по своему размеру и сильно зависят от объема выборочных наблюдений. Несмотря на это, при малых выборках, повторяемых несколько раз, размах варьирования нашел широкое применение.
Среднее квадратическое отклонение и дисперсия. Основным показателем вариации (изменчивости) считается среднее квадратическое отклонение, которое определяется как корень квадратный из средней арифметической квадратов отклонений вариант от их средней арифметической величины.
Среднее квадратическое отклонение для выборки обозначают через s, а для генеральной совокупности -s. Согласно определению:
s = 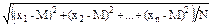 =
= 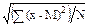 , (2.11)
, (2.11)
В математической статистике оперируют средним квадратом отклонений (s2 для выборки и s2 для генеральной совокупности), называемым дисперсией, которая рассчитывается по формуле (2.12).
s2 = 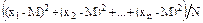 =
= 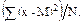 (2.12)
(2.12)
Для расчетов по вариационному ряду среднее квадратическое отклонение выразится формулой:
s = 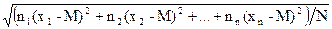 =
=
= 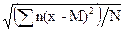 , (2.13)
, (2.13)
а дисперсия
s2 = 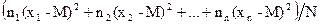 =
=
= 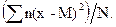 (2.14)
(2.14)
В уравнениях (2.11-2.14)
x1, x2,..., xn - варианты ряда (средние значения классов);
M - средняя арифметическая;
n1, n2,...,nn - частоты в классах;
N - общий объем ряда.
Оценивая величину s по выборочному значению s, при обработке выборки с числом наблюдений N меньше 30 в качестве делителя в формулах (2.11) - (2.14) принимают не N, а N -1. (Это связано с тем, что матожидание выборки не равно матожиданию генеральной совокупности).
Таким образом, общей формулой для нахождения среднего квадратического отклонения будет:
s = 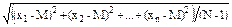 =
= 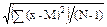 , (2.15)
, (2.15)
а для дисперсии
s2 = 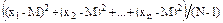 =
= 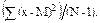 (2.16)
(2.16)
При обработке вариационных рядов формулы принимают вид:
s = 
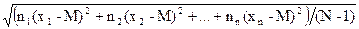 =
=
= 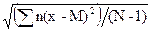 , (2.17)
, (2.17)
s2 = 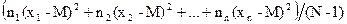 =
=
= 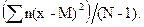 (2.18)
(2.18)
И спользования функции ДИСП () MSExcel для оценивания дисперсии по выборке.
Синтаксис: ДИСП (число1;число2;...), где число1, число2,... - это от 1 до 30 числовых аргументов, соответствующих выборке из генеральной совокупности.
Коэффициент вариации. Коэффициент вариации является показателем изменчивости признака, выражая ее в относительных единицах. Он представляет собой среднее квадратическое отклонение отдельных вариант ряда в долях средней величины, выраженное в процентах:
v = (s / M) 100%. (2.19)
Являясь показателем, не зависящим от принятых единиц измерения вариант, коэффициент вариации может применяться для сравнительной оценки величины варьирования различных призна к ов
Асимметрия. Эксцесс.
Приведем краткий обзор характеристик, которые наряду с уже рассмотренными применяются для анализа статистических рядов и являются аналогами соответствующих числовых характеристик случайной величины.
Среднее выборочное и выборочная дисперсия являются частным случаем более общего понятия – момента статистического ряда.
Определение. Начальным выборочным моментом порядка 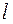 называется среднее арифметическое
называется среднее арифметическое 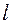 - х степеней всех значений выборки:
- х степеней всех значений выборки:
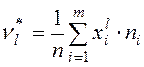 или
или 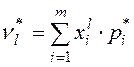 .
.
Из определения следует, что начальный выборочный момент первого порядка: 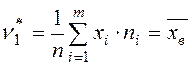 .
.
Определение. Центральным выборочным моментом порядка называется среднее арифметическое - х степеней отклонений наблюдаемых значений выборки от выборочного среднего 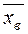 :
:
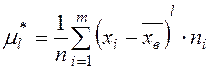 или
или 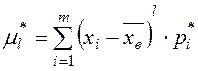 .
.
Из определения следует, что центральный выборочный момент второго порядка:
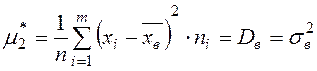 .
.
Определение. Выборочным коэффициентом асимметрии называется число 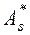 , определяемое формулой:
, определяемое формулой: 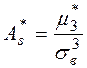 .
.
Выборочный коэффициент асимметрии служит для характеристики асимметрии полигона вариационного ряда. Если полигон асимметричен, то одна из ветвей его, начиная с вершины, имеет более пологий «спуск», чем другая.
Если 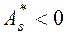 , то более пологий «спуск» полигона наблюдается слева; если
, то более пологий «спуск» полигона наблюдается слева; если 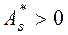 - справа. В первом случае асимметрию называют левосторонней, а во втором - правосторонней.
- справа. В первом случае асимметрию называют левосторонней, а во втором - правосторонней.
Пример 2.10 использования функции СКОС() MSExcel для расчета асимметрии распределения. Асимметрия характеризует степен