Определение искусственного интеллекта.
Искусственный интеллект (ИИ, англ. Artificial intelligence, AI) — наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ. ИИ связан со сходной задачей использования компьютеров для понимания человеческого интеллекта, но не обязательно ограничивается биологически правдоподобными методами.
Тест Тьюринга.
Тест Тьюринга сравнивает способности предположительно разумной машины со способностями человека — лучшим и единственным стандартом разумного поведения. В тесте, который Тьюринг назвал "имитационной игрой", машину и ее человеческого соперника (следователя) помешают в разные комнаты, отделенные от комнаты, в которой находится "имитатор". Следователь не должен видеть их или говорить с ними напрямую — он сообщается с ними исключительно с помощью текстового устройства, например, компьютерного терминала. Следователь должен отличить компьютер от человека исключительно на основе их ответов на вопросы, задаваемые через это устройство. Если же следователь не может отличить машину от человека, тогда, утверждает Тьюринг, машину можно считать разумной.
Изолируя следователя от машины и другого человека, тест исключает предвзятое отношение — на решение следователя не будет влиять вид машины или ее электронный голос. Следователь волен задавать любые вопросы, не важно, насколько окольные или косвенные, пытаясь раскрыть "личность" компьютера. Например, следователь может попросить обоих подопытных осуществить довольно сложный арифметический подсчет, предполагая, что компьютер скорее даст верный ответ, чем человек. Чтобы обмануть эту стратегию, компьютер должен знать, когда ему следует выдать ошибочное число, чтобы показаться человеком. Чтобы обнаружить человеческое поведение на основе эмоциональной природы, следователь может попросить обоих субъектов высказаться по поводу стихотворения или картины. Компьютер в таком случае должен знать об эмоциональном складе человеческих существ.
Этот тест имеет следующие важные особенности.
1. Дает объективное понятие об интеллекте, т.е. реакции заведомо разумного существа на определенный набор вопросов. Таким образом, вводится стандарт для определения интеллекта, который предотвращает неминуемые дебаты об "истинности" его природы.
2. Препятствует заведению нас в тупик сбивающими с толку и пока безответными вопросами, такими как: должен ли компьютер использовать какие-то конкретные внутренние процессы, или же должна ли машина по-настоящему осознавать свои действия.
3. Исключает предвзятость в пользу живых существ, заставляя опрашивающего сфокусироваться исключительно на содержании ответов на вопросы.
Благодаря этим преимуществам, тест Тьюринга представляет собой хорошую основу для многих схем, которые используются на практике для испытания современных интеллектуальных программ. Программа, потенциально достигшая разумности в какой-либо предметной области, может быть испытана сравнением ее способностей по решению данного множества проблем со способностями человеческого эксперта. Этот метод испытания всего лишь вариация на тему теста Тьюринга, группу людей просят сравнить "вслепую" ответы компьютера и человека. Как видим, эта методика стала неотъемлемым инструментом как при разработке, так и при проверке современных экспертных систем.
Тест Тьюринга, несмотря на свою интуитивную притягательность, уязвим для многих оправданных нападок. Одно из наиболее слабых мест — пристрастие в пользу чисто символьных задач. Тест не затрагивает способностей, требующих навыков перцепции или ловкости рук, хотя подобные аспекты являются важными составляющими человеческого интеллекта. Иногда же, напротив, тест Тьюринга обвиняют в попытках втиснуть машинный интеллект в форму интеллекта человеческого. Быть может, машинный интеллект просто настолько отличается от человеческого, что проверять его человеческими критериями — фундаментальная ошибка? Нужна ли нам, в самом деле, машина, которая бы решала математические задачи так же медленно и неточно, как человек'? Не должна ли разумная машина извлекать выгоду из своих преимуществ, таких как большая, быстрая, надежная память, и не пытаться сымитировать человеческое познание? На самом деле, многие современные практики ИИ говорят, что разработка систем, которые бы выдерживали всесторонний тест Тьюринга, — это ошибка, отвлекающая нас от более важных, насущных задач: разработки универсальных теорий, объясняющих механизмы интеллекта люден и машин и применение этих теорий к проектированию инструментов для решения конкретных практических проблем. Все же тест Тьюринга представляется нам важной составляющей в тестировании и "аттестации" современных интеллектуальных программ.
Тьюринг также затронул проблему осуществимости построения интеллектуальной программы на базе цифрового компьютера Размышляя в терминах конкретной вычислительной модели (электронной цифровой машины с дискретными состояниями), он сделал несколько хорошо обоснованных предположении касательно ее объема памяти, сложности программы и основных принципов проектирования такой системы. Наконец, он рассмотрел множество моральных, философских и научных возражений возможности создания такой программы средствами современной технологии. Отсылаем читателя к статье Тьюринга за познавательным и все еще актуальным изложением сути споров о возможностях интеллектуальных машин.
Два возражения, приведенных Тьюрингом, стоит рассмотреть детально. "Возражение леди Лавлейс". впервые сформулированное Адой Лавлейс, сводится к тому, что компьютеры могут делать лишь то, что им укажут, и, следовательно, не могут выполнять оригинальные (читай: разумные) действия. Однако экспертные системы, особенно в области диагностики, могут формулировать выводы, которые не были заложены в них разработчиками. Многие исследователи считают, что творческие способности можно реализовать программно.
Другое возражение «аргумент естественности поведения», связано с невозможностью другое создания набора правил, которые бы говорили индивидууму, что в точности нужно делать при каждом возможном стечении обстоятельств. Действительно, гибкость, позволяющая биологическому разуму реагировать практически на бесконечное количество различных ситуаций приемлемым, если даже и не оптимальным образом – отличительная черта разумного поведения. Справедливо замечание, что управляющая логика, используемая в большинстве традиционных компьютерных программ, не проявляет великой гибкости или силы воображения, но неверно, что все программы должны писаться подобным образом. Большая часть работ в сфере ИИ за последние 25 лет была направлена на обработку таких языков программирования и моделей, призванных устранить упомянутый недостаток, как продукционные системы, объектные системы, сетевые представления и другие модели, обсуждаемые в этой книге.
Современные программы ИИ обычно состоят из набора модульных компонентов, или правил поведения, которые не выполняются в жестко заданном порядке, а активизируются по мере надобности в зависимости от структуры конкретной задачи. Системы обнаружения совпадений позволяют применять общие правила к целому диапазону задач. Эти системы необычайно гибки, что позволяет относительно маленьким программам проявлять разнообразное поведение в широких пределах, реагируя на различные задачи и ситуации.
Можно ли довести гибкость таких программ до уровня живых организмов, все еще предмет жарких споров. Нобелевский лауреат Герберт Саймон сказал, что большей частью своеобразие и изменчивость поведения, присущие живым существам, возникли скорее благодаря сложности их окружающей среды, чем благодаря сложности их внутренних "программ". В Саймон описывает муравья, петляющего по неровной, пересеченной поверхности. Хотя путь муравья кажется довольно сложным, Саймон утверждает, что цель муравья очень проста- вернуться как можно скорее в колонию. Изгибы и повороты его пути вызваны встречаемыми препятствиями. Саймон заключает, что:
"Муравей, рассматриваемый в качестве проявляющей разумное поведение системы, на самом деле очень прост. Кажущаяся сложность его поведения в большей степени отражает сложность среды, в которой он существует".
Эта идея, если удастся доказать применимость ее к организмам с более сложным интеллектом, составит сильный аргумент в пользу простоты, а следовательно, постижимости интеллектуальных систем. Любопытно, что, применив эту идею к человеку, мы придем к выводу об огромной значимости культуры в формировании интеллекта. Интеллект, похоже, не взращивается во тьме, как грибы. Для его развития необходимо взаимодействие с достаточно богатой окружающей средой. Культура так же необходима для создания человеческих существ, как и человеческие существа для создания культуры. Эта мысль не умаляет могущества наших интеллектов, но подчеркивает удивительное богатство и связь различных культур, сформировавших жизни отдельных людей. Фактически на идее о том, что интеллект возникает из взаимодействий индивидуальных элементов общества, основывается подход к ИИ, представленный в следующем разделе.
Данные.
В информатике Данные — это результат фиксации, отображения информации на каком-либо материальном носителе, то есть зарегистрированное на носителе представление сведений независимо от того, дошли ли эти сведения до какого-нибудь приёмника и интересуют ли они его.
Данные — это и текст книги или письма, и картина художника, и ДНК.
Данные, являющиеся результатом фиксации некоторой информации, сами могут выступать как источник информации. Информация, извлекаемая из данных, может подвергаться обработке, и результаты обработки фиксируются в виде новых данных.
Данные могут рассматриваться как записанные наблюдения, которые не используются, а пока хранятся.
Знания.
Знание — в теории искусственного интеллекта и экспертных систем — совокупность информации и правил вывода (у индивидуума, общества или системы ИИ) о мире, свойствах объектов, закономерностях процессов и явлений, а также правилах использования их для принятия решений. Главное отличие знаний от данных состоит в их структурности и активности, появление в базе новых фактов или установление новых связей может стать источником изменений в принятии решений.
Параллельно с развитием структуры компьютеров происходит развитие информационных структур для представления данных. Знания имеют более сложную структуру чем данные.
Знания
З1. Знания находятся в человеческой памяти.
З2. Знания материализованные.
З3. Совокупность З1 и З2.
З4. Знания на языке представления знаний.
З5. Базы знаний.
Данные
Д1. Результат наблюдения над объектами или данными в памяти человека.
Д2. Фиксация данных на материальном носителе.
Д3. Модель данных.
Д4. Данные на языке описания данных.
Д5. БД.
Обычно рассматривают 1,3,5.
Знания задаются двумя способами:
Экстенсионально – через набор конкретных фактов, касающихся данной предметной области.
Интенсионально – через свойства данной предметной области и систему связи между атрибутами.
Свойства знаний:
1. Внутренняя интерпретируемость знаний – каждая информационная единица (и.е.) должна иметь уникальное имя, по которому ИИС будет находить ее и отвечать на запросы, в которых упомянуто ее имя.
2. Структурируемость – и.е. должна обладать гибкой структурой, т.е. для них должен выполнятся «принцип матрешки» каждая и.е. может быть включена а состав другой и.е. и наоборот.
3. Связность – в информационной базе между и.е. должна быть предусмотренная возможность восстановления различных взаимосвязей. При этом различают следующие связи (отношения):
a. связи структуризации – задается иерархия в и.е.;
b. функциональные отношения – описывают информацию о функциях;
c. казуальные отношения – используются для задания причинно-следственной связи;
d. семантические связи – все остальное.
4. Семантическая метрика – позволяет задать отношения, которые характеризуют ситуационную близость между и.е., другими словами определяет ассоциативную связь.
5. Активность знаний – с момента появления компьютеров используемые в них и.е. разделены на данные и команды. Данные пассивны, а команды – активны.
Классификация знаний
Поверхностные – совокупность эмпирических ассоциаций и причинно-следственных отношений между понятиями предметной области.
Глубинные – абстракции, образы, аналогии в которых отражается понимание структуры предметной области, назначение и взаимосвязь отдельных понятий.
Жесткие знания позволяют получать однозначные четкие рекомендации при заданных начальных условиях. Мягкие знания допускают множественные, «размытые» решения и различные варианты рекомендаций.
Концептуальная модель.
Концептуальная модель (англ. conceptual model) — это определённое множество понятий и связей между ними, являющихся смысловой структурой рассматриваемой предметной области.
Концептуальная модель — модель предметной области, состоящей из перечня взаимосвязанных понятий, используемых для описания этой области, вместе со свойствами и характеристиками, классификацией этих понятий, по типам, ситуациям, признакам в данной области и законов протекания процессов в ней. (Толковый словарь по искусственному интеллекту)
Концептуальная (содержательная) модель — это абстрактная модель, определяющая структуру моделируемой системы, свойства её элементов и причинно-следственные связи, присущие системе и существенные для достижения цели моделирования.
Почему
Здесь пользователь задаст вопрос: "Почему вы хотите знать, вращается ли двигатель?". Система отвечает с помощью символьною представления правила, к которому относится вопрос.
Выло установлено, что:
1. топливо поступает в двигатель,
поэтому если
2. двигатель вращается,
то проблема в свечах зажигания.
Поскольку пользователь на первые два вопроса ответил "да", это дало возможность активизировать правило 1 и проверить его первую предпосылку. Отметим, что объяснением поведения системы является только вывод правила, которое находится в рассмотрении на данный момент. Однако это обеспечивает адекватное объяснение причин, почему программа хочет знать, вращается ли двигатель. В ответ на вопрос "почему" система отмечает, что, по ее данным, топливо поступает в двигатель. Предположим, пользователь далее спрашивает:
как топливо поступает м двигатель?
Ответом является последовательность рассуждений, приведшая к этому заключению.
Она восстанавливается обратным проходом от цели вдоль соответствующих правил до информации, введенной пользователем.
Из правила 4 следует:
если
в баке есть топливо и
топливо поступает о карбюратор,
то
топливо поступает в двигатель.
в баке есть топливо - указано пользователем
топливо поступает в карбюратор - указано пользователем
Таким образом, архитектура продукционной системы обеспечивает основу для этих объяснений. В каждом цикле управления выбирается и активизируется новое правило. После каждого цикла программа может быть остановлена и проинспектирована. Поскольку каждое правило представляет "глыбу" знаний по решению проблемы, текущее правило обеспечивает контекст для объяснения. Этим продукционный подход отличается от более традиционных архитектур: если программу на С или С++ остановить во время исполнения, то вряд ли текущее выражение будет иметь много смысла.
Итак, система, основанная на знаниях, отвечает на вопросы "почему?", отображая текущее правило, которое она пытается активизировать. В ответ на вопросы "как?" она предоставляет последовательность рассуждений, которая привела к цели. Хотя эти механизмы являются концептуально простыми, они обладают хорошими возможностями объяснений, если база знаний организована логически грамотно.
Поиск в глубину и ширину.
При поиске в глубину после исследования состояния сначала необходимо оценить все его потомки и их потомки, а затем исследовать любую из вершин братьев. Поиск в глубину по возможности углубляется в область поиска. Если дальнейшие потомки состояния не найдены, рассматриваются вершины-братья.
Поиск в ширину, напротив, исследует пространство состояний по уровням, один за другим. И только если состояний на данном уровне больше нет, алгоритм переходит к следующему уровню.
В отличие от поиска в ширину, поиск в глубину не гарантирует нахождение оптимального пути к состоянию, если оно встретилось впервые. Позже в процессе поиска могут быть найдены различные пути к любому состоянию. Если длина пути имеет значение в решении задачи, то в случае нахождения алгоритмом некоторого состояния повторно необходимо сохранить именно тот путь, который оказался короче.
Поиск в ширину всегда находит самый короткий путь к целевой вершине. Если в задаче существует простое решение, это решение будет найдено. К сожалению, при большом коэффициенте ветвления, если состояния имеют высокое среднее число потомков, комбинаторный взрыв может помешать алгоритму найти решения.
Поиск в глубину эффективен для областей поиска с высокой степенью связности, потому что ему не нужно помнить все узлы данного уровня. В степень использованья пространства состояний в случае поиска в глубину – это линейная функция длины пути. На каждом уровне сохраняются только дочерние вершины единственного пути.
Так что же лучше: поиск в глубину или поиск в ширину? На этот вопрос можно ответить так. Необходимо исследовать пространство состояний и проконсультироваться с экспертами в данной области. В шахматах, например, поиск в ширину просто невозможен. В более простых играх поиск в ширину не только возможен, но даже может оказаться единственным способом избежать проигрышей или потерь в игре.
Гибридные системы.
Важной областью исследований является комбинация различных моделей рассуждений. В гибридной архитектуре, объединяющей несколько парадигм, эффективность одного подхода может компенсировать слабости другого. Комбинируя различные подходы, можно обойти недостатки, присущие каждому из них в отдельности.
Например, сочетание рассуждений на основе правил и опыта может обеспечить следующие преимущества.
1. Просмотр известных случаев до начала рассуждений на основе правил позволяет снизить затраты на поиск.
2. Примеры и исключения можно сохранять в базе данных ситуаций.
3. Результаты поиска можно сохранить для будущего использования. При этом механизм рассуждений позволит избежать затрат на повторный поиск.
Комбинация рассуждений на основе правил и моделей открывает следующие возможности.
1. Объяснения дополняются функциональными знаниями. Это может быть полезно в обучающих системах.
2. Повышается устойчивость системы при отказах. При отсутствии эвристических правил, используемых в данном случае, механизм рассуждений может прибегнуть к рассуждениям от исходных принципов.
3. Поиск на основе модели дополняется эвристическим поиском. Это может помочь в сложных рассуждениях, основанных на модели, и обеспечивает возможность выбора.
Комбинация рассуждений на основе моделей и опыта дает следующие преимущества.
1. Более разумное объяснение ситуаций.
2. Проверка аналогичных случаев до начала более экстенсивного поиска посредством рассуждений на основе моделей.
3. Обеспечение записи примеров и исключений в базу данных случаев, которые могут быть использованы для управления выводом на основе модели.
4. Запись результатов вывода на основе моделей для будущего использования.
Гибридные методы заслуживают внимания как исследователей, так и разработчиков приложений. Однако построение таких систем требует решения целого ряда проблем. Необходимо определить метод рассуждения для данной ситуации, момент изменения метода рассуждения, выяснить различия между методами рассуждения, разработать представления, обеспечивающие совместное использование знаний. Далее будут рассмотрены вопросы планирования или организации частей знаний дли решения более сложных проблем.
Семантические сети.
Семантическая сеть — информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы. Таким образом, семантическая сеть является одним из способов представления знаний. В названии соединены термины из двух наук: семантика в языкознании изучает смысл единиц языка, а сеть в математике представляет собой разновидность графа — набора вершин, соединённых дугами (рёбрами). В семантической сети роль вершин выполняют понятия базы знаний, а дуги (причем направленные) задают отношения между ними. Таким образом, семантическая сеть отражает семантику предметной области в виде понятий и отношений.
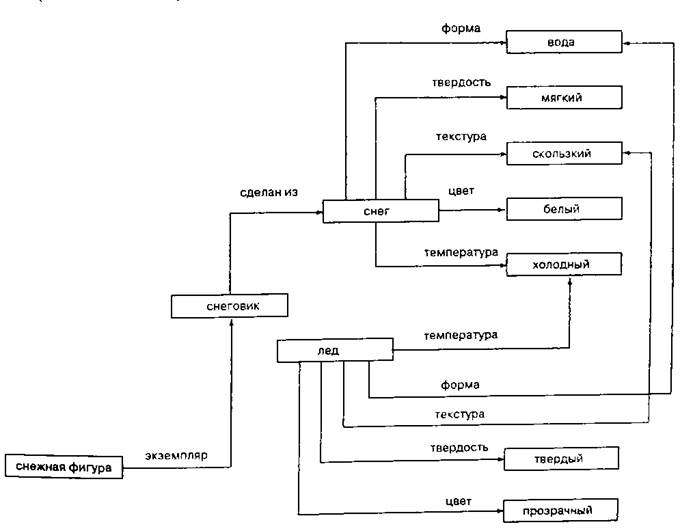
Несмотря на то, что терминология и их структура различаются, существуют сходства, присущие практически всем семантическим сетям:
1. узлы семантических сетей представляют собой концепты предметов, событий, состояний;
2. различные узлы одного концепта относятся к различным значениям, если они не помечено, что они относятся к одному концепту;
3. дуги семантических сетей создают отношения между узлами-концептами (пометки над дугами указывают на тип отношения);
4. некоторые отношения между концептами представляют собой лингвистические падежи, такие как агент, объект, реципиент и инструмент (другие означают временные, пространственные, логические отношения и отношения между отдельными предложениями;
5. концепты организованы по уровням в соответствии со степенью обобщенности так как, например, сущность, живое существо, животное, плотоядное.
Однако существуют и различия: понятие значения с точки зрения философии; методы представления кванторов общности и существования и логических операторов; способы манипулирования сетями и правила вывода, терминология. Все это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны для чтения и обработки компьютером, а также достаточно мощны, чтобы представить семантику естественного языка.
Сценарии.
Сценарий (script) – это структурированное представление, описывающее стереотипную последовательность событий в частном контексте. Сценарии первоначально были предложены, как средство для организации структур концептуальной зависимости в описаниях типовых ситуаций. Сценарии используются в системах понимания естественного языка для организации базы знаний в терминах ситуаций, которые система должна понимать.
Сценарий включает следующие компоненты:
- Начальные условия, которые должны быть истинными при вызове сценария.
- Результаты или факты, которые являются истинными, когда сценарий завершается.
- Предположения, которые поддерживают контекст сценария.
- Роли являются действиями, которые совершают отдельные участники.
- Сцены. Сценарий разбивается на последовательность сцен, каждая из которых представляет временные аспекты сценария.
Элементы сценария – основные части семантического значения – представляются отношениями концептуальной зависимости. Собранные вместе во фреймоподобной структуре, они представляют последовательность значений или событий.
Фреймы.
Фреймы – схема представления, во многом подобная сценариям и ориентированная на включение в строго организованные структуры данных неявных (подразумеваемых) информационных связей, существующих в предметной области. Это представление поддерживает организацию знаний в более сложные единицы, которые отображают структуру объектов этой области.
«Вот суть теории фреймов. Когда некто встречается с новой ситуацией (или существенно меняет свою точку зрения на проблему), он выбирает из памяти структуру, называемую фреймом. Этот сохранённый каркас при необходимости должен быть адаптирован и приведён в соответствие с реальным изменением деталей.»
Например, достаточно один раз остановиться в гостинице, чтобы составить представление о всех гостиничных номерах – там почти всегда есть кровать, ванная, место для чемодана и т.д. Но могут быть и варьируемые факторы – цвета, расположение мебели, некоторые детали интерьера. С данным фреймом так же связана информация, принимаемая по умолчанию. Если нет простыней – можно вызвать горничную и так далее. Нам не надо подстраивать сознание для каждого нового гостиничного номера, все элементы обобщенного номера организуются в концептуальную структуру, к которой мы обращаемся, когда останавливаемся в гостинице.
Понятие фрейма.
Под фреймом понимается однажды определенная единица представления знаний, которую можно изменять лишь в деталях согласно текущей ситуации. Теория фреймов предложена М. Минским в 1974 г.
В основе данной модели представления знаний лежит свойство концептуальных объектов иметь аналогии, которые позволяют строить иерархические структуры отношений типа "абстрактное-конкретное".
Каждый фрейм следует рассматривать как сеть из нескольких вершин и отношений. На самом верхнем уровне фрейма представляется фиксированная информация о состоянии моделируемого объекта, которая является истинной вне зависимости от контекста рассмотрения объекта и соответствует имени фрейма. Следующий уровень - уровень терминальных слотов (терминалов), который отражает относящуюся к моделируемому объекту конкретную информацию. В каждом слоте задается условие, которое должно выполняться при установлении соответствия между значениями (слот либо сам устанавливает соответствие, либо обычно это делает более мелкая составляющая фрейма). В одной системе различные фреймы могут иметь общие терминалы. Несколько терминалов одного фрейма обычно заранее определяются значениями по умолчанию, что позволяет представлять информацию общего характера при решении сходных задач. Среди слотов отдельного фрейма выделяют слоты, определяемые системой и определяемые пользователем. Примерами системных слотов могут служить: IS_A (указание на фрейм-родитель), слот указателей дочерних фреймов, слоты дат создания и изменения информации фрейма.
Фреймы, соответствующие описанию отдельных объектов, называются шаблонами, а фреймы верхнего уровня, используемые для представления этих шаблонов, называются фреймами классов.
Основные свойства фреймов.
1). Базовый тип (базовый фрейм) - с его помощью запоминаются наиболее важные компоненты исследуемого объекта. На основании базовых фреймов строятся фреймы для новых состояний исследуемого объекта. При этом каждый фрейм содержит слот, оснащенный указателем подструктуры, который позволяет различным фреймам совместно использовать одинаковые части.
2). Процесс сопоставления - в ходе его проверяется правильность выбора фрейма. Вначале в соответствии с текущей целью делается попытка подтверждения релевантности некоторого базового фрейма (в т.ч. с помощью подфреймов), при подтверждении процесс сопоставления завершается. В противном случае для слота, в котором возникла ошибка, делается попытка присваивания надлежащего значения с учетом наложенных слотом ограничений. В случае неуспеха управление передается другому надлежащему фрейму из рассматриваемой системы, затем - соответствующему фрейму из другой фреймовой системы и т.д. пока не произойдет успешного сопоставления. В противном случае для данной фреймовой системы рассматриваемая поисковая задача решения не имеет и требуется либо переформулировать текущую цель, либо пересмотреть содержательную часть фреймовой модели, включая накладываемые слотами ограничения.
3). Иерархическая структура. Ее особенность заключается в том, что информация об атрибутах, которую содержит фрейм верхнего уровня, совместно используется всеми фреймами нижних уровней, связанных с ним.
4). Межфреймовые сети - образуются путем соединения фреймов, описывающих объекты с небольшими различиями, с использованием указателей различия.
Основные свойства фреймов (продолжение)
5). Значение по умолчанию - под ним понимается значение слота, полученное путем распределения человеком-экспертом конкретных значений между терминальными слотами фрейма. Выводы, получаемые на основании значений по умолчанию, называются выводами по умолчанию. С их помощью можно восполнить недостатки изначально заданной информации. Как правило, когда используется подобный способ вывода, предполагается наличие эффективно действующих межфреймовых сетей и демонов.
6). Отношения "абстрактное-конкретное" и "целое-часть". Отношения "абстрактное-конкретное" (IS_A) характерны тем, что на верхних уровнях иерархии расположены более абстрактные объекты, а на нижних уровнях - более конкретные объекты, причем объекты нижних уровней наследуют атрибуты объектов верхних уровней. Отношение "целое-часть" (PART_OF) касается структурированных объектов и показывает, что объект нижнего уровня является частью объекта верхнего уровня. В отношениях этого типа нельзя использовать наследование атрибутов.
Структура данных фрейма.
1). Имя фрейма - присваиваемый фрейму идентификатор, для заданной фреймовой системы имя фрейма должно быть уникально.
2). Имя слота - присваиваемый слоту идентификатор. Слот должен иметь уникальное имя во фрейме, к которому он принадлежит.
3). Указатели наследования - с их помощью определяется, какую информацию об атрибутах слотов фрейма верхнего уровня наследуют слоты с такими же именами во фрейме нижнего уровня. Типичные указатели наследования: U (Unique, уникальный) - слот наследуется, но данные в каждом фрейме могут принимать любые значения; S (Same, такой же) - наследование тех же значений данных; R (Range) - значения слотов фрейма нижнего уровня должны находиться в пределах, указанных значениями слотов фрейма верхнего уровня; O - выполняет одновременно функции указателей U и S, при отсутствии указаний работает как S.
4). Указание типа данных: FRAME (указатель на другой фрейм), INTEGER (целый), REAL (действительный), BOOL (булевский), LISP (присоединенная процедура), TEXT (текст), LIST (список), TABLE (таблица), EXPRESSION (выражение).
5). Значение слота - должно совпадать с указанным типом данных этого слота. Кроме того, должно выполняться условие наследования.
Структура данных фрейма: демоны и присоединенные процедуры.
6). Демон - особая разновидность присоединенной процедуры, которая запускается при выполнении некоторого условия, определяемого значением соответствующего слота. Пример: демон IF-NEEDED запускается, если в момент обращения к слоту его значение не было установлено, IF-ADDED запускается при подстановке в слот значения, IF-REMOVED - при стирании значения слота.
7). Присоединенная процедура является программой процедурного типа, которая является значением слота и запускается по сообщению, переданному из другого фрейма. Демоны и присоединенные процедуры являются процедурными знаниями из представляемых фреймовой моделью.
В языке представления знаний фреймами отсутствует специальный механизм управления выводом, поэтому разработчик (в литературе, в частности, в [1] используется термин "пользователь" применительно к фреймовой модели именно как к формализму) должен реализовать данный механизм с помощью присоединенной процедуры. Достоинство: высокая универсальность языка, что позволяет писать любую программу управления выводом с помощью присоединенной процедуры (помимо иерархического и сетевого представления знаний). Недостаток: требуется высокая квалификация разработчика.
Обобщение и специализация.
Теория графов включает ряд операций для создания новых графов на основе существующих. Они позволяют генерировать новый граф путем либо специализации, либо обобщения существующего графа, и очень важны для представления семантики естественного языка.
Существуют четыре типа операций: копирование, ограничение, объединение и упрощение.
Копирование позволяет сформировать новый граф А, который является точной копией графа А1.
Ограничение позволяет заменить узлы понятий графа узлами, представляющими их специализацию. Возможно две ситуации:
1. Если понятие помечено общим маркером, то общий маркер может быть заменен индивидуальным.
2. Метка типа может быть заменена одной из меток его подтипов, если это соответствует объекту ссылки понятия.
Объединение позволяет интегрировать два графа в один. Если узел понятия С1 графа S1 идентичен узлу понятия C2 графа S2, то можно сформировать новый граф,вычеркивая C2 и связывая все его отношения с C1. Объединение – это правило специализации, так как результирующий граф является менее общим, чем любой из его компонентов.
Если граф содержит два одинаковы отношения, то одно из них может быть вычеркнуто вместе со всеми его дугами. В этом заключается правило упрощения. Дублирующиеся отношения часто возникают в результате объединения.
Обучение нейронных сетей.
Сеть должна для некоторого множества входов давать некоторое желаемое количество выходов каждый из которых рассматривается как вектор. Процесс обучения состоит в том что перебираются входные векторы и подстраиваются их весовые коэффициенты с целью получения определенных результатов.
Существует два способа обучения:
- с учителем
- без учителя
Сети, обучающиеся без учителя, просматривают выборку только один раз. Сети, обучающиеся с учителем, просматривают выборку множество раз, при этом один полный проход по выборке называется эпохой обучения. При обучении с учителем набор исходных данных делят на две части – собственно обучающую выборку и тестовые данные; принцип разделения может быть произвольным. Обучающие данные подаются сети для обучения, а проверочные используются для расчета ошибки сети (проверочные данные никогда для обучения сети не применяются). Таким образом, если на проверочных данных ошибка уменьшается, то сеть действительно выполняет обобщение. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и просто «запоминает» обучающие данные. Это явление называется переобучением сети или оверфиттингом. В таких случаях обучение обычно прекращают.
Одним из первых ученых который начал разработки в этом направлении был Кохонен. Обучающееся множество состоит из входных векторов. Обучающийся алгоритм подстраивает вес сети так, чтобы получались согласованные выходные векторы, т.е. при предъявлении достаточно близких входных векторов получались одинаковые выходные.
Нейрон Мак-Каллока-Питтса.
Первым примером нейросетевой модели является нейрон Мак-Каплока-Питтса [McCulloch и Pitts. 1943]. На вход нейрона подаются биполярные сигналы (равные +1 или -1). Активационная функция — это пороговая зависимость, результат которой вычисляется следующим образом. Если взвешенная сумма входов не меньше нуля, выход нейрона принимается равным 1, в противном случае - -1. В своей работе Мак-Калпок и Питгс показали, как на основе таких нейронов можно построить любую логическую функцию. Следовательно, система из таких нейронов обеспечивает полную вычислительную модель.
На рисунке показан пример вычисления логических функций И и ИЛИ с помощью нейр






