Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Топ:
Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда...
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Интересное:
Аура как энергетическое поле: многослойную ауру человека можно представить себе подобным...
Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
МИНИСТЕРСТВО ОБЩЕГО
И ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
РОССИЙСКОЙ ФЕДЕРАЦИИ
 |
ПЕНЗЕНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
 |
РАБОТА С БАЗАМИ ДАННЫХ
В АРХИТЕКТУРЕ КЛИЕНТ-СЕРВЕР
Методические указания
к выполнению лабораторных работ
Пенза 1999
УДК 681.3.06
Р
Дано описание пяти лабораторных работ, связанных с доступом к SQL-ориентированным базам данных в архитектуре клиент-сервер. Первые две работы ориентированы на изучение языка баз данных SQL, последние три – программного интерфейса ODBC для разработки клиентских приложений баз данных. Для каждой лабораторной работы приводятся необходимые теоретические сведения, порядок выполнения, методические указания и варианты заданий.
При выполнении лабораторных работ используется CУБД MS SQL Server 6.5, хотя может использоваться любая другая SQL-ориентированная СУБД.
Методические указания подготовлены на кафедре “Вычислительная техника” и предназначены для студентов специальности 22.01, изучающих дисциплину “Базы данных”.
Ил. 1, табл. 13, библиогр. 16 назв.
С о с т а в и т е л ь В.Н.Дубинин
Р е ц е н з е н т В.Д.Былкин, канд. техн. наук, доц. кафедры “Периферийные средства вычислительной техники” Пензенского технологического института
Введение
В настоящее время все большее распространение получают информационные системы с архитектурой клиент-сервер [6, 15-16]. Основой таких систем являются SQL-ориентированные СУБД, выполняемые на выделенных серверах (SQL-серверах). Причинами роста популярности клиент-серверных систем являются успехи в области телекоммуникаций, высокая производительность систем данного класса, их большая информационная емкость, высокая надежность, безопасность, возможность одновременной работы с одним и тем же источником данных нескольких пользователей, легкость реконфигурации системы, позволяющая возможность поэтапного наращивания ресурсов базы данных и подключения новых пользователей, возможность распределенной обработки и работа с разнородными источниками данных. Последнее свойство определяется использованием в системе единого языкового стандарта для работы с базами данных – языка SQL [2,4-5,8-9]. Многие компьютерные фирмы производят программное обеспечение, “превращающее” обычный компьютер в SQL-сервер. К наиболее известным и распространенным SQL-серверам относятся: Microsoft SQL Server [7,10-14], Oracle Server, Sybase SQL Server, Informix Online, Watcom SQL Network Server, XDB-Enterprise, Gupta SQLBase Server, DB2, Borland InterBase Workgroup Server, Progress и другие.
|
|
Стандарт SQL определяет подъязык данных, который используется в контексте другого языка, называемого включающим, для того, чтобы выполнять специализированные задачи управления базами данных. Такая взаимосвязь между включающим языком и подъязыком данных SQL называется стилем связывания. SQL-92 определяет три типа связывания: встроенный SQL, модульный язык и непосредственный вызов. В 1995 году американские и международные комитеты, ответственные за стандарт языка SQL, завершили работу над спецификацией нового стиля связывания, названного Call Level Interface (SQL/CLI – интерфейс уровня вызовов) [3,16]. SQL/CLI был одобрен как международный стандарт официально названный “ISO/IEC 9075-3:1995, Information Technology – Database Languages – SQL – Part 3, Call Level Interface (SQL/CLI)”.
Преимущества SQL/CLI: независимость клиентских приложений от СУБД, возможность выполнения параллельных операций над базой данных, возможность параллельной обработки множества транзакций. SQL/CLI представляет собой множество функций, которые может использовать приложение для доступа к базам данных SQL. Оно содержит функции для запроса на выделение и на отказ от выделения ресурсов, функции для подключения к SQL-серверам и отключения от них, функции для исполнения операторов языка SQL, а также функции получения диагностической информации, управления завершением транзакций и получения информации о данной реализации. Системная модель SQL/CLI состоит из трех компонентов – приложения, реализации CLI и SQL-сервера. Приложение производит вызовы функций, определяемых SQL/CLI. Реализация SQL/CLI – это библиотека стадии исполнения, которая реализует функции CLI и связывается с данным приложением. Реализация CLI обращается к SQL-серверу, который обрабатывает операторы SQL.
|
|
Компания Microsoft Corp. разработала инструментарий для разработки программного обеспечения, основанный на расширенной версии SQL/CLI и получивший название Open DataBase Connectivity (ODBC) [1,6,14,16]. ODBC обеспечивает общий API-интерфейс для доступа к самым разнообразным базам данных. Архитектура ODBC имеет четыре основных компонента:приложение, менеджер драйверов, драйвер и источник или источники данных. Центральным компонентом является менеджер драйверов. Механизм ODBC может работать практически в любой операционной системе. Несмотря на наличие других, более высокоуровневых методов доступа к базам данных, таких как DAO и RDO, а также стремительное развитие и внедрение новых методов (ADO, OLE DB), ODBC прочно занимает свою нишу в общем ряду методов доступа к базам данных. “Фундаментальность” ODBC заключается в том, что он опирается на международный стандарт SQL/CLI. Программирование с помощью ODBC значительно сложнее, но выигрыш в скорости может быть существенным.
Методические указания включают описание пяти лабораторных работ. Первые две работы ориентированы на изучение языка баз данных SQL, последние три – программного интерфейса ODBC для разработки клиентских приложений баз данных. Для каждой лабораторной работы приводятся необходимые теоретические сведения, порядок выполнения, методические указания и варианты заданий.
Целью первой лабораторной работы является изучение спецификации запроса языка SQL, приобретение практических навыков составления и содержательной интерпретации запросов выборки данных, а также их выполнения на SQL-сервере с использованием клиентских утилит. В данной лабораторной работе используется готовая база данных, отражающая деятельность некоторой книготорговой компании. Используемая база данных состоит из четырех таблиц, структура и семантика которых представлена в описании работы. Содержимое таблиц приведено в приложении. Приведено 96 вариантов SQL-запросов и 96 вариантов запросов на естественном языке к данной базе данных. Запросы к базе данных имеют различную степень сложности и покрывают большинство возможностей языка SQL.
|
|
Целью второй работы является изучение языков описания данных и манипулирования данными, входящими в SQL, приобретение навыков составления SQL-запросов для создания, удаления и модификации объектов базы данных, включая таблицы, представления и индексы, изучение операторов манипулирования данными, в том числе позиционных, основанных на использовании курсоров. В данной работе также изучаются ограничения целостности таблицы, а именно ограничения уникальности и проверочные ограничения. При выполнении первых двух лабораторных работ рекомендуется использовать клиентские утилиты ISQL/w и SQL Enterprise Manager (SQL-EM), входящими в состав MS SQL Server 6.5.
Последние три лабораторные работы нацелены на изучение ODBC API для создания клиентских приложений баз данных. Особенностью данных работ является их тесная взаимоподчиненность: следующая работа строится на результатах предыдущей. При выполнении лабораторных работ, связанных с доступом к базе данных с использованием ODBC, для разработки клиентских приложений рекомендуется использовать систему программирования Visual C++, хотя возможно использование и других систем, например, Visual Basic.
Лабораторная работа N 1
Порядок выполнения работы
1. Изучить структуру и элементы SQL-запроса выборки, в том числе разделы FROM, WHERE, GROUP BY, HAVING, ORDER BY, а также предикаты условия поиска и агрегатные функции.
2. Изучить операции реляционной алгебры (соединение, пересечение, объединение, разность и др.).
3. Изучить утилиту ISQL/w, входящую в набор клиентских утилит для СУБД SQL Server.
4. Изучить состав базы данных книготорговой компании (база данных pubs), структуру и семантику ее таблиц.
5. Получить у преподавателя номер варианта задания.
6. В соответствии с вариантом задания типа А произвести содержательную интерпретацию заданных SQL-запросов, выполнить их на SQL-сервере с использованием клиентских утилит ISQL/w или SQL Enterprise Manager (SQL-EM), проинтерпретировать результаты выполнения запросов.
|
|
7. В соответствии с вариантом задания В составить SQL-запросы по их заданному содержательному описанию, выполнить SQL-запросы на SQL-сервере с использованием клиентских утилит ISQL/w или SQL-EM, проинтерпретировать результаты выполнения запросов.
8. Оформить отчет.
Содержание отчета
1) Титульный лист; 2) цель работы; 3) тексты SQL-запросов и их содержательная интерпретация; 4) результаты выполнения запросов по заданиям типа А и В и их интерпретация; 5) выводы.
Основные сведения
Язык SQL
Первый международный стандарт языка SQL был принят в 1989 г. (SQL/89). В конце 1992 г. Был принят новый международный стандарт SQL/92. “Родным” языком Microsoft SQL Server является язык Transact-SQL (T-SQL), являющийся диалектом стандартного языка SQL. T-SQL поддерживает большинство возможностей языков SQL/89 и SQL/92, а также ряд расширений, увеличивающих возможность программирования и гибкость языка. В частности, в язык T-SQL добавлены конструкции для задания последовательности операций управления в программе (например, if и while), локальных переменных и других конструкций, позволяющих писать более сложные запросы и строить программные объекты, хранящиеся на сервере, в том числе процедуры и триггеры.
Язык SQL включает следующие языки:
* язык определения данных (Data Definition Language или DDL), предназначенный для добавления, модификации и удаления данных в таблицах;
* язык модификации данных (Data Modification Language или DML), предназначенный для добавления, модификации и удаления данных в таблицах.
В синтаксических конструкциях при описании языка будут использоваться следующие соглашения. Нетерминальные элементы заключаются в угловые скобки <>. Необязательная конструкция заключается в квадратные скобки []. Запись вида {A}… означает повторение конструкции А произвольное число раз (включая нулевое). Вертикальные разделители | читаются как “ИЛИ” и служат для выбора одной из конструкций, заключенных в скобки.
Оператор SELECT
Оператор SELECT используется для запросов к базе данных и выборки результатов. Синтаксис оператора SELECT следующий:
< оператор SELECT>::=
SELECT [ALL | DISTINCT] < список выборки >
< табличное выражение >
ORDER BY < спецификация сортировки >]
< табличное выражение >::=
FROM < имя таблицы >[{, < имя таблицы >}…]
[WHERE < условие поиска >]
[GROUP BY < имя столбца > [{,< имя столбца >}…]
[HAVING < условие поиска >]
Если задано ключевое слово DISTINCT, то из результирующей таблицы удаляются повторяющиеся строки. Список выборки определяет, какие столбцы должны быть возвращены в результирующую таблицу. Данный список представляет список арифметических выражений над значениями столбцов таблиц из раздела FROM и констант. В простейшем случае он может быть, например, списком имен некоторых столбцов таблиц из раздела FROM. В случае, если вместо списка выборки стоит звездочка (*), то выбираются все столбцы таблиц из раздела FROM.
|
|
В разделе FROM определяются таблицы, из которых будут извлекаться данные. Следует отметить, что рядом с именем таблицы можно указывать еще одно имя - синоним имени таблицы, который можно использовать в других разделах табличного выражения.
Раздел WHERE служит своего рода фильтром при отборе данных.
Выполнение раздела GROUP BY оператора выборки сводится к разбиению результирующей таблицы на множество групп строк, которое состоит из минимального числа таких групп, в которых для каждого столбца из списка столбцов раздела GROUP BY во всех строках каждой группы, включающей более одной строки, значения этого столбца совпадают.
Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия поиска является истинным. Условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные строки, поэтому в данном случае прямо можно использовать только столбцы, указанные в качестве столбцов группирования в разделе GROUP BY.
Раздел ORDER BY позволяет установить желаемый порядок просмотра результирующей таблицы. Спецификация сортировки имеет следующий синтаксис:
< спецификация сортировки >::= {< целое без знака > | < имя столбца >} [ASC | DESC]
Как видно, фактически задается список столбцов, и для каждого столбца указывается порядок просмотра строк результирующей таблицы в зависимости от значений этого столбца (ASC - по возрастанию (умолчание), DESC - по убыванию). Указывать сортируемый столбец можно по имени или по порядковому номеру в результирующей таблице.
Предикаты условия поиска
В условии поиска могут использоваться следующие предикаты: предикат сравнения, предикат BETWEEN, предикат IN, предикат LIKE, предикат NULL, предикат с квантором и предикат EXISTS.
Предикат IN определяется следующим образом:
< предикат IN>::= < выражение > [NOT] IN (< значение > [,< значение >... ] |.< подзапрос >)
Значение предиката является истинным, когда значение левого операнда совпадает хотя бы с одним значением списка правого операнда. Использование ключевого слова NOT осуществляет отрицание результата.
Подзапрос- это запрос, используемый в предикате условия поиска. Результатом выполнения подзапроса является единственный столбец.
Предикат BETWEEN определяется следующим образом:
< предикат BETWEEN>::= < выражение > [NOT] BETWEEN < выражение > AND < выражение >
По определению результат x BETWEEN y AND z тот же самый, что результат логического выражения x>=y AND x<=z.
Предикат LIKE имеет следующий синтаксис:
< предикат LIKE>::= < имя столбца > [NOT] LIKE < шаблон >[ESCAPE <escape- символ >]
Значение предиката LIKE является истинным, если шаблон является подстрокой заданного столбца. При этом, если раздел ESCAPE отсутствует, то при составлении шаблона со строкой производится специальная интерпретация символов-заместителей шаблона: символ подчеркивания (“_”) обозначает любой одиночный символ, символ процента (“%”) обозначает последовательность произвольных символов произвольной длины (может быть нулевой), парные квадратные скобки представляют любой символ, записанный в скобках. Если же раздел ESCAPE присутствует и специфицирует некоторый одиночный символ x, то пары символов “x_” и “x%” представляют одиночные символы “_” и “%” соответственно.
Предикат NULL описывается синтаксическим правилом:
< предикат NULL>::= < имя столбца > IS [NOT] NULL
Значение “x IS NULL” является истинным, когда значение x неопределено.
Предикат EXISTS имеет следующий синтаксис:
< предикат EXISTS>::= EXISTS < подзапрос >
Значение предиката является истинным, когда результат вычисления подзапроса не пуст.
Агрегатные функции
Агрегатные функции (функции множества) в запросе предназначены для вычисления некоторого значения для заданного множества строк. Таким множеством строк может быть группа строк, если агрегатная функция применяется к сгруппированной таблице, или вся таблица. В языке SQL определены следующие агрегатные функции:
* AVG - функция определения среднего значения;
* MAX - функция определения максимального значения;
* MIN - функция определения минимального значения;
* SUM - функция суммирования значений;
* COUNT - функция для подсчета числа строк или значений.
Грамматика агрегатных функций следующая:
< агрегатная функция >::= COUNT(*) | <distinct- функция > | <all- функция >
<distinct- функция >::= {AVG | COUNT | MAX | MIN | SUM} (DISTINCT < имя столбца >)
<all- функция >::= {AVG | MAX | MIN | SUM} ([ALL]< выражение >)
Вычисление функции COUNT(*) производится путем подсчета числа строк в заданном множестве. Функция типа distinct выполняет вычисления только над одним столбцом, а в вычислениях используются только уникальные значения столбца. При использовании функции типа all список значений формируется из значений арифметического выражения, вычисляемого для каждой строки заданного множества.
Работа с утилитой ISQL/w
Клиентская утилита ISQL/w используется для тестирования SQL-запросов. После запуска данной утилиты необходимо подключиться к серверу. При этом в диалоговом окне подсоединения (connect dialog box) необходимо указать имя сервера, идентификатор пользователя и пароль. После регистрации окно ISQL/w отображает в заголовке информацию о сервере, пользователе и текущей базе данных. Окно запросов при этом открыто.
Пункты меню File управляют сохранением, чтением и печатью запросов, а также подключениями к серверам. Меню Edit позволяет копировать и искать строки. Меню Query управляет выполнением запросов и предлагает доступ к некоторым общим установкам подключения. Пункты меню Help и Window работают практически так же, как и в любом приложении Windows.
Кнопки панели инструментов (toolbar) дают те же возможности, что и пункты меню, но при однократном нажатии отдельные кнопки особенно удобны. Первая кнопка слева (кнопка Новый запрос) позволяет создать новое окно запросов и новое подключение к данному серверу с использованием того же идентификатора пользователя и пароля. Кроме того, оно позволяет автоматически использовать ту же базу данных, что и текущее подсоединение. Одновременные подсоединения удобны, поскольку они позволяют работать как два отдельных пользователя, тестируя блокировку и многопользовательское поведение, или дают возможность быстро посмотреть значение, необходимое для написания сложного запроса в другом окне.
Другие полезные кнопки находятся справа от окна запросов. Крайняя левая кнопка из трех (перечеркнутая крестиком пиктограмма запроса) закрывает текущий запрос и подсоединение. Именно таким образом отменяется действие кнопки “Новый запрос”.
Вторая кнопка с указывающей направо стрелкой становится зеленой, когда вводится любой текст в текстовой области окна запросов. Эта кнопка выполнения. При нажатии ее по окончании ввода запроса, текст запроса будет передан на сервер. Кнопка будет серой, когда в окне нет или когда запрос уже выполняется.
Третья кнопка - это квадрат, имеющий красный цвет, когда запрос выполняется. Это кнопка отмены запроса.
Текстовая область может использоваться для ввода запроса, просмотра результата выполнения запроса, просмотра статистики ввода-вывода при выполнении запроса, а также для просмотра плана запроса (?). Для перехода к указанным режимам использования текстовой области необходимо выбрать закладки Query, Results, Statistics I/O и Showplan, соответственно.
Вызвать утилиту ISQL/w можно запустив загрузочный модуль isqlw.exe. Необходимыми динамическими библиотеками при работе утилиты являются: ntdblib.dll, sqlgui32.dll, sqlsvc32.dll и sqlqry32.dll.
Кроме того, вызвать утилиту ISQL/w можно работая с интегрированной утилитой SQL Enterprise Manager. Для этого необходимо выбрать пункт Query Tool меню Tools.
Описание задания
База данных книготорговой компании
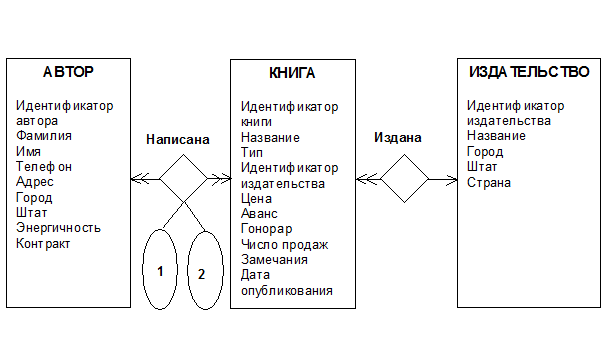
Рассмотрим простую предметную область жизнедеятельности, связанную с книгоизданием и маркетингом. В рамках данной предметной области существуют издатели, которые публикуют книги, авторы, которые книги пишут, и издания (сами книги). Разработана база данных pubs, определяющая описанную выше предметную область. Инфологическая модель предметной области с использованием диаграмм “сущность-связь” (ER-диаграмм) [1]), разработанных Ченом, представлена на рис. 1.
|
|
На данном рисунке прямоугольниками обозначены типы сущностей (объектов), а ромбами - типы связей между сущностями. Атрибуты сущностей указаны мелким шрифтом в том же прямоугольнике, который отображает типы сущностей. Имя типа сущности отмечено в верхней части прямоугольника жирным шрифтом. Атрибуты связей в данном случае обозначены овалами. Как видно из рис. 1 у связи “Написана” имеется два атрибута: первый атрибут определяет порядок автора в названии книги, второй атрибут - гонорар автора книги.
Рис. 1
База данных книготорговой компании (база данных pubs) включает три таблицы, определяющие сущности: таблица authors определяет авторов, таблица publishers - издателей, а таблица titles - сами книги. Четвертая таблица titleauthor задает отношение между таблицами titles и authors. Она показывает, какие авторы написали какие книги. Связь между таблицами titiles и publishers определяется столбцом pub_id в данных таблицах.
Ниже представлены структуры используемых таблиц.
Структура таблицы authors
| Имя столбца | Тип данных | Размерность | Возможность значений null | Содержательное описание |
| au_id | varchar | 11 | Нет | Идентификатор автора |
| au_lname | varchar | 40 | Нет | Фамилия автора |
| au_fname | varchar | 20 | Нет | Имя автора |
| phone | char | 12 | Нет | Номер телефона |
| address | varchar | 40 | Да | Адрес (улица, дом, квартира) |
| city | varchar | 20 | Да | Город проживания |
| state | char | 2 | Да | Штат проживания |
| zip | char | 5 | Да | Энергичность |
| contract | bit | 1 | Нет | Наличие контракта |
Структура таблицы publishers
| Имя столбца | Тип данных | Размерность | Возможность значений null | Содержательное описание |
| pub_id | char | 4 | Нет | Идентификатор издательства (издателя) |
| pub_name | varchar | 40 | Да | Название издательства (имя издателя) |
| city | varchar | 20 | Да | Город |
| state | char | 2 | Да | Штат |
| country | varchar | 30 | Да | Страна |
Структура таблицы titles
| Имя столбца | Тип данных | Размерность | Возможность значений null | Содержательное описание |
| title_id | varchar | 6 | Нет | Идентификатор книги |
| title | varchar | 80 | Нет | Название книги |
| type | char | 12 | Нет | Тип книги |
| pub_id | char | 4 | Да | Идентификатор издательства |
| price | money | 8 | Да | Цена |
| advance | money | 8 | Да | Аванс (стоимость предварительной продажи) |
| royalty | int | 4 | Да | Гонорар |
| ytd_sales | int | 4 | Да | Число книг, проданных в текущем году |
| notes | varchar | 200 | Да | Замечания |
| pubdate | datetime | 8 | Нет | Дата опубликования |
Структура таблицы titleauthor
| Имя столбца | Тип данных | Размерность | Возможность значений null | Содержательное описание |
| au_id | varchar | 11 | Нет | Идентификатор автора книги |
| title_id | varchar | 6 | Нет | Идентификатор книги |
| au_ord | tinyint | 1 | Да | Порядок автора в названии книги |
| royaltyper | int | 4 | Да | Авторский гонорар |
В столбце type таблицы titles используются следующие типы книг: business - книги по бизнесу, mod_cook - книги по современной кулинарии, popular_comp - книги по компьютерной тематике, psychology - книги по психологии, trad_cook - книги по традиционной кулинарии, UNDECIDED - неопределенный тип книги.
В столбцах state таблиц authors и publishers используются следующие обозначения административных единиц США: CA - штат Калифорния, DC - округ Колумбия, IL - штат Иллинойс, IN - штат Индиана, KS -штат Канзас, MD - штат Мэриленд, MA - штат Массачусетс, MI - штат Мичиган, NY - штат Нью-Йорк, OR - штат Орегон, TN - штат Теннесси, TX - штатТехас, UT - штат Юта.
В столбце country таблицы publishers используются следующие обозначения стран: France - Франция, Germany - Германия, USA - США.
Домен городов, используемый в таблицах authors и publishers, включает города Ann Arbor, Berkeley, Boston, Chicago, Corvallis, Colevo, Dallas, Gary, Lawrence, Menlo Park, Munchen, Nashville, New York, Oakland, Palo Alto, Paris, Rockville, Salt Lake City, San Francisco, San Jose, Vacaville, Walnul Creek, Washington.
В приложении 1 приведен полный пример базы данных pubs.
Лабораторные задания типа А
Дать содержательную интерпретацию SQL-запросам, выполнить их на SQL-сервере с использованием клиентских утилит ISQL/w или SQL-EM, дать содержательную интерпретацию результатам выполнения SQL-запросов.
1) SELECT au_lname, au_fname
FROM authors
2) SELECT au_lname, au_fname
FROM authors
ORDER BY au_lname
3) SELECT au_lname, au_fname
FROM authors
ORDER BY au_lname, au_fname
4) SELECT title_id, price, ytd_sales,
price*ytd_sales “ytd dollar sales”
FROM titles
ORDER BY price*ytd_sales
5) SELECT title_id, price, ytd_sales,
price*ytd_sales “ytd dollar sales”
FROM titles
ORDER BY price*ytd_sales DESC
6) SELECT title_id, type, ytd_sales
FROM titles
ORDER BY type ASC, ytd_sales DESC
7) SELECT AVG(price)
FROM titles
8) SELECT DISTINCT type
FROM titles
ORDER BY type ACS
9) SELECT DISTINCT city
FROM authors
ORDER BY city DESC
10) SELECT DISTINCT state
FROM authors
ORDER BY state
11) SELECT DISTINCT country
FROM publishers
ORDER BY country DESC
12) SELECT AVG(price), AVG(DISTINCT price)
FROM titles
13) SELECT *
FROM titles
14) SELECT au_lname, au_fname
FROM authors
WHERE state= “CA”
15) SELECT type, title_id, price
FROM titles
WHERE price*ytd_sales < advance
16) SELECT au_id, city, state
FROM authors
WHERE state= “CA” OR city= “Palo Alto”
17) SELECT title_id, price
FROM titles
WHERE price between $5 AND $15
18) SELECT title_id, price
FROM titles
WHERE type IN (“mod_cook”, “trad_cook”, “business”)
19) SELECT au_lname, au_fname, city, state
FROM authors
WHERE city like “San%”
20) SELECT type, title_id, price
FROM titles
WHERE title_id like “B_2075”
21) SELECT type, title_id, price
FROM titles
WHERE title_id like “B[AUN]7832”
22) SELECT AVG(price) “AVG”
FROM titles
WHERE type= “business”
23) SELECT AVG(price) “avg” SUM(price) “sum”
FROM titles
WHERE type IN (“business”, “mod_cook”)
24) SELECT COUNT(*)
FROM authors
WHERE state= “CA”
25) SELECT COUNT(*)
FROM titles
WHERE LIKE “Co%s”
26) SELECT title
FROM titles
WHERE ytd_sales IS NULL
27) SELECT au_lname “Фамилия”, au_fname “Имя”
FROM authors
WHERE contract=1 AND phone LIKE “408____-__2_”
28) SELECT phone
FROM authors
WHERE address LIKE “%Broadway Av.%”
29) SELECT title, pubdate
FROM titles
WHERE pubdate>= “Jun 9 1991 12:00AM”
AND pubdate< “6/16/91”
30) SELECT type, AVG(price) “avg”, SUM(price) “sum”
FROM titles
WHERE type IN (“business”, “psychology”)
GROUP BY type
31) SELECT type, pub_id, AVG(price) “avg”, SUM(price) “sum”
FROM titles
WHERE type IN (“business”, “mod_cook”)
GROUP BY type, pub_id
32) SELECT type, AVG(price)
FROM titles
WHERE price>$11
GROUP BY type
HAVING AVG(price)>$19.7
33) SELECT au_id, COUNT(*)
FROM authors
GROUP BY au_id
HAVING COUNT(*)>1
34) SELECT type, MIN(price), MAX(price)
FROM titles
GROP BY type
ORDER BY type
35) SELECT type, MIN(price), MAX(price)
FROM titles
GROUP BY type
HAVING MAX(price)-MIN(price)>=3
36) SELECT state, COUNT(DISTINCT pub_id)
FROM publishers
GROUP BY state
37) SELECT pub_name, AVG(price) “ävg”,
COUNT(DISTINCT title_id) “count”
FROM titles t JOIN publishers p ON t.pub_id=p.pub_id
GROUP BY pub_name
38) SELECT type, (MIN(price)+MIN(price))/2, AVG(price)
FROM titles
GROUP BY type
HAVING type<> “UNDECIDED”
ORDER BY 2 DESC
39) SELECT type, MIN(pubdate), MAX(pubdate)
FROM titles
GROUP BY type
40) SELECT title, pub_name
FROM titles CROSS JOIN publishers
41) SELECT *
FROM titles, publishers
42) SELECT title, pub_name
FROM titles, publishers
WHERE titles.pub_id=publishers.pub_id
43) SELECT title, pub_name
FROM titles JOIN publishers
ON titles.pub_id=publishers.pub_id
44) SELECT *
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
45) SELECT t.*, pub_name
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
46) SELECT a.city, a.state
FROM authors a, publishers p
WHERE a.city=p.city AND a.state=p.state
47) SELECT au_lname, au_fname
FROM authors a JOIN titleauthor ON a.au_id=ta.au_id
JOIN titles t ON ta.title_id=t.title_id
WHERE au_lname LIKE “R%”
AND state IN (“CA”, “TX”, “NY”, “OR”, “UT”)
AND (title LIKE “_h_ %” OR title LIKE “% _h_ %”
OR title LIKE “% _h_”)
48) SELECT title, type
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id AND p.city=a.city
49) SELECT au_lname, au_fname, title
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id
AND ((p.country= ‘USA’ AND t.type=’popular_comp’)
OR (p.country=’France’ AND t.type=’psychology’))
50) SELECT au_lname, au_fname, city
FROM authors a, titles t, titleauthor ta
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND (city LIKE “[CPR]%” OR city LIKE “%San%”)
AND (title LIKE “% the %” OR title LIKE “The %”
OR title LIKE “% a %” OR title LIKE “A %”)
51) SELECT DISTINCT au_lname, au_fname
FROM authors a JOIN titleauthor ta ON a.au_id=ta.au_id
JOIN titles t ON ta.title_id=t.title_id
JOIN publishers p ON p.pub_id=t.pub_id
WHERE p.state= “CA”
ORDER BY au_lname, au_fname
52) SELECT pub_name
FROM publishers p JOIN titles t ON p.pub_id=t.pub_id WHERE $15>price AND type= “psychology”
ORDER BY pub_name
53) SELECT pub_name, AVG(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY pub_name
54) SELECT pub_name, AVG(price)
FROM titles t JOIN publishers p ON t.pub_id=p.pub_id
GROUP BY pub_name
55) SELECT au_lname, au_fname, title
FROM authors a, titles t, titleauthor ta
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND type= “popular_comp”
56) SELECT au_lname, au_fname, title
FROM authors a JOIN titleauthor ta ON a.au_id=ta.au_id
JOIN titles t ON ta.title_id=t.title_id
WHERE type= “psychology”
57) SELECT au_lname, au_fname, pub_name, COUNT(*)
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id
GROUP BY au_lname, au_fname, pub_name
58) SELECT MIN(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY country
HAVING country=’USA’
59) SELECT pub_name, COUNT(*)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
AND (type= ‘mod_cook’ OR type=’trad_cook’)
GROUP BY pub_name
60) SELECT pub_name, COUNT(*)
FROM publishers p, titles t
WHERE p.pub_id=t.pub_id AND price>$15
GROUP BY pub_name
ORDER BY pub_name DESC
61) SELECT title, COUNT(DISTINCT a.au_id)
FROM titles t JOIN titleauthor ta ON t.title_id=ta.title_id
JOIN authors a ON ta.au_id=a.au_id
JOIN publishers p ON p.pub_id=t.pub_id
GROUP BY title
62) SELECT state, COUNT(DISTINCT p.pub_id)
FROM publishers p JOIN titles t ON p.pub_id=t.pub_id
GROUP BY state
63) SELECT title
FROM titles
WHERE pub_id=
(SELECT pub_id
FROM publishers
WHERE pub_name= “Binnet & Hardley”)
64) SELECT pub_name
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type= “business”)
65) SELECT pub_name
FROM publishers p
WHERE EXISTS
(SELECT *
FROM titles t
WHERE p.pub_id=t.pub_id
AND type=“popular_comp”)
66) SELECT pub_name
FROM publishers p
WHERE NOT EXISTS
(SELECT *
FROM titles t
WHERE p.pub_id=t.pub_id
AND type=“mod_cook”)
67) SELECT pub_name
FROM publishers
WHERE pub_id NOT IN
(SELECT pub_id
FROM titles
WHERE type=“psychology”)
68) SELECT type, price
FROM titles
WHERE price < (SELECT AVG(price) FROM titles)
69) SELECT type, AVG(price)
FROM titles
GROUP BY type
HAVING AVG(price) < (SELECT AVG(price) FROM titles)
70) SELECT DISTINCT a.city, a.state
FROM authors a
WHERE NOT EXISTS
(SELECT *
FROM publishers p
WHERE a.city=p.city AND a.state=p.state)
71) SELECT DISTINCT p.city, p.state
FROM publishers p
WHERE NOT EXISTS
(SELECT *
FROM authors a
WHERE p.city=a.city AND p.state=a.state)
72) SELECT MIN(price)
FROM titles t
WHERE t.pub_id IN
(SELECT pub_id
FROM publishers
WHERE country=’USA’)
73) SELECT title, type, price
FROM titles
WHERE price>ALL
(SELECT price
FROM titles
WHERE type= “psychology”)
74) SELECT COUNT(DISTINCT city)
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type= “psychology”)
75) SELECT pub_name
FROM publishers p
WHERE 15>SOME
(SELECT price
FROM titles t
WHERE p.pub_id=t.pub_id
AND type= “trad_cook”)
76) SELECT pub_name, state
FROM publishers
WHERE pub_id NOT IN
(SELECT pub_id
FROM titles)
77) SELECT title
FROM titles
WHERE pub_id NOT IN
(SELECT pub_id
FROM publishers)
78) SELECT title
FROM titles t
WHERE price>=
(SELECT AVG(price)
FROM titles tt, publishers pp
GROUP BY pub_id
HAVING t.pub_id=pp.pub_id)
79) SELECT au_lname, au_fname, price
FROM authors a, titles t, titleauthor ta, publishers p
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
AND t.pub_id=p.pub_id AND country=’USA’
AND price=
(SELECT MIN(price)
FROM titles tt, publishers pp
WHERE tt.pub_id=pp.pub_id
GROUP BY country
HAVING country=’USA’)
80) SELECT DISTINCT au_lname, au_fname
FROM authors a, titles t, titleauthor ta
WHERE a.au_id=ta.au_id AND ta.title_id IN
(SELECT title_id
FROM titles
WHERE ytd_sales=
(SELECT MAX(ytd_sales)
FROM titles))
81) SELECT DISTINCT a.city, a.state
FROM authors a
WHERE NOT EXISTS
(SELECT *
FROM publishers p
WHERE a.city=p.city AND a.state=p.state)
UNION SELECT DISTINCT p.city, p.state
FROM publishers p
WHERE NOT EXISTS
(SELECT *
FROM authors a
WHERE p.city=a.city AND p.state=a.state)
82) SELECT title, price
FROM titles t JOIN publishers p ON t.pub_id=p.pub_id
WHERE p.country= “USA” AND t.price=
(SELECT MAX(price)
FROM titles tt JOIN publishers pp
ON tt.pub_id=pp.pub_id
WHERE country= “USA”)
83) SELECT pub_name, COUNT(*)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY pub_name
HAVING COUNT(*)>=ALL
(SELECT COUNT(*)
FROM titles tt, publishers pp
WHERE tt.pub.id=pp.pub_id
GROUP BY pub_name)
84) SELECT pub_name, city, state, country
FROM publishers p
WHERE EXISTS
(SELECT *
FROM titles t
WHERE t.pub_id=p.pub_id)
AND 20>ALL
(SELECT price
FROM titles t
WHERE t.pub_id=p.pub_id
AND price IS NOT NULL)
85) SELECT state, SUM(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY state
HAVING state NOT IN (“TN”, “MA”, “TX”)
AND SUM(price)>
(SELECT SUM(price)
FROM titles tt, publishers pp
WHERE tt.pub.id=pp.pub_id
AND pp.city= “Boston”)
86) SELECT pub_name, MIN(price)
FROM titles t, publishers p
WHERE t.pub_id=p.pub_id
GROUP BY pub_name
HAVING MIN(price)>=ALL
(SELECT MIN(price)
FROM titles tt JOIN publishers pp
ON tt.pub_id=pp.pub_id
GROUP BY pub_name)
87) SELECT *
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type= “psychology” AND pub_id IN
(SELECT pub_id
FROM publishers
WHERE country= “USA”
AND state<> “CA”)
88) SELECT au_lname, au_fname
FROM authors a
WHERE a.au_id IN
(SELECT au_id
FROM titleauthor ta
WHERE ta.title_id IN
(SELECT title_id
FROM titles t
WHERE “CA”=SOME
(SELECT state
FROM publishers p
WHERE p.pub_id=t.pub_id)))
ORDER BY au_lname, au_fname
89) SELECT state, COUNT(*)
FROM publishers p
WHERE EXISTS
(SELECT *
FROM titles t
WHERE p.pub_id=t.pub_id)
AND $22>ALL
(SELECT price
FROM titles t
WHERE p.pub_id=t.pub_id
AND price IS NOT NULL)
GROUP BY state
ORDER BY state ASC
90) SELECT state
FROM publishers p1
GROUP BY state
HAVING COUNT(DISTINCT pub_name)=
(SELECT COUNT(*)
FROM publishers p2
WHERE EXISTS
(SELECT *
FROM titles t
WHERE p2.pub_id=t.pub_id)
AND $22.5>ALL
(SELECT price
FROM titles t
WHERE p2.pub_id=t.pub_id
AND price IS NOT NULL)
GROUP BY state
HAVING p1.state=p2.state)
91) SELECT p1.pub_id
FROM titles t1, publishers p1
WHERE t1.pub_id=p1.pub_id
GROUP BY p1.pub_id
HAVING COUNT(DISTINCT title)=
(SELECT COUNT(*)
FROM titles t2
WHERE t2.pub_id=p1.pub_id
AND EXISTS
(SELECT *
FROM titleauthor ta3, authors a3
WHERE ta3.au_id=a3.au_id
AND ta3.title_id=t2.title_id
AND a3.state IN
(SELECT state
FROM publishers p4
WHERE “business”=SOME
(SELECT type
FROM titles t5
WHERE p4.pub_id=
t5.pub_id))))
92) SELECT city, state
FROM authors
UNION SELECT city, state
FROM publishers
ORDER BY state, sity
93) SELECT city
FROM authors
UNION SELECT city
FROM publishers
94) SELECT state
FROM authors
UNION SELECT state
FROM publishers
95) SELECT city, state
FROM authors
WHERE state IS NOT NULL
UNION SELECT city, state
FROM publishers
WHERE state IS NOT NULL
ORDER BY city DESC, state ASC
96) SELECT state, MIN(price), MAX(price), AVG(price)
FROM authors a, titles t, titleauthor ta
WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id
GROUP BY state
HAVING state<> “CA”
Лабораторные задания типа B
Составить SQL-запросы по их заданному содержательному описанию, выполнить SQL-запросы на SQL-сервере с использованием клиентских утилит ISQL/w или SQL-EM, проинтерпретировать результаты выполнения запросов.
1) Выбрать имена и фамилии авторов книг.
2) Выбрать имена и фамилии авторов, проживающих в Калифорнии.
3) Выбрать информацию о книгах, объеме (стоимость) продаж которых в текущем году меньше стоимости предварительной продажи. Информация о книгах должна включать тип книги, идентификатор и цену книги.
4) Выбрать информацию об авторах, проживающих в штате Калифорния или в городе Salt Lake City. Ин
|
|
|

Наброски и зарисовки растений, плодов, цветов: Освоить конструктивное построение структуры дерева через зарисовки отдельных деревьев, группы деревьев...

Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...

История развития хранилищ для нефти: Первые склады нефти появились в XVII веке. Они представляли собой землянные ямы-амбара глубиной 4…5 м...

Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!