Требования к функциональным характеристикам
Программа должна обеспечивать возможность выполнения перечисленных ниже функций:
1. Создание подключения к графовой СУБД.
2. Выборка графов из графовой СУБД.
3. Анализ данных с помощью следующих методов:
- поиск в ширину;
- поиск в длину;
- ранжирование;
- кластеризация;
- поиск кратчайшего пути.
4. Разделение графов по классу решаемых задач, то есть классификация графов.
5. Сохранение результатов обработки данных в качестве источника данных.
6. Создание диаграмм или графиков по источнику данных, определяя измерения и меры.
Сравнение решений
Рассмотрим каждое решение в разрезе требований к разрабатываемому алгоритму, в таблице 1 предоставлено общее сравнение рассмотренных решений, то есть, что на «входе» и что на «выходе».
Таблица 1 – Общее сравнение решений
| Название
| Тип решения
| Источник данных
| Способ визуализации результата
|
| Gigraph
| Нативное приложение
| Excel – таблица
| RDF
|
| Gephi
| Нативное приложение
| Список вершин и ребер
| Property Graph, RDF
|
| Graph Online
| WEB – приложение
| Матрицы инцидентности, смежности и расстояний
| RDF
|
| Разрабатываемый алгоритм
| WEB –
приложение
| СУБД Neo4j
| Диаграммы
|
В данной таблице приведено сравнение решений, по:
1) типу решения, которое может быть нативным и web;
2) источнику данных, который может быть представлен в виде различных матриц, списков, таблиц и БД, последнее позволяет получать данные с помощью специального языка запросов;
3) способу визуализации, который может быть представлен в виде графов, вершины которого имеют атрибутный состав (PropertyGraph) ине имеют (RDF).
Отличия разрабатываемого решения от ранее рассмотренных заключается в получении данных непосредственно из БД Neo4j, а также отображение данных графов на диаграммах.
Отображение результатов работы алгоритмов в виде диаграмм обосновано наличием у ребер и вершин графа, свойств, отображение которых на обычном графе приведет к наложению, следовательно, процесс анализа данных на таком графе предоставит некоторые неудобства.
Графовые алгоритмы применяются для углубленного понимания и анализа связанных данных. Они уникально подходят для изучения структур и выявления шаблонов в наборах данных, которые тесно связаны между собой. Нет ничего более очевидного, чем большие данные, снабженные наглядными связями.
Сравнение существующих решений с использованием метода Саати [17] отражено в таблицах 2 и 3, где u1 - выполнение алгоритмов анализа данных на графах, u2 - выполнение алгоритмов анализа данных на каждом подграфе, u3 - группировка результатов анализа, u4 - визуализация графа.
Таблица 2 – Матрица парных сравнений критериев оценки
|
| u1
| u2
| u3
| u4
|
| u1
| 1
| 3
| 5
| 1
|
| u2
| 1/3
| 1
| 1
| 1/5
|
| u3
| 1/5
| 1
| 1
| 1/5
|
| u4
| 1
| 5
| 5
| 1
|
Для нормализации необходимо разделить элемент каждого столбца на сумму элементов данного столбца.
Таблица 3 – Нормализированная матрица парных сравнений критериев
|
| u1
| u2
| u3
| u4
|
| u1
| 0,4
| 0,3
| 0,42
| 0,42
|
| u2
| 0,13
| 0,1
| 0,08
| 0,08
|
| u3
| 0,08
| 0,1
| 0,08
| 0,08
|
| u4
| 0,4
| 0,5
| 0,42
| 0,42
|
Вычислим относительные веса критериев путём сложения значений каждой строки и делением полученной суммы на количество элементов в строке.
Веса критериев относительно «Эксперта»:


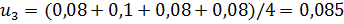
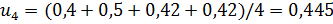
Таблица 4 – Сравнение существующих и разрабатываемого решений
| Название
| u1
| u2
| u3
| u4
| Сумма
|
| Gigraph
| -/0,385
| -/0,098
| -/0,085
| +/0,445
| 0,445
|
| Gephi
| +/0,385
| -/0,098
| +/- /0,043
| +/0,445
| 0,873
|
| Graph Online
| +/0,385
| -/0,098
| -/0,085
| +/0,445
| 0,83
|
| Разрабатываемое решение
| +/0,385
| +/0,098
| +/0,085
| +/0,445
| 1,013
|
В данной таблице обозначено наличие алгоритмов анализа и их общая оценка в виде суммы, для каждого из решений.
Самым выгодным решением по результатам оценки является разрабатываемое решение, так как поддерживает больше подходов к анализу данных на графах.
Описание каждого из методов:
1. Выполнение алгоритмов анализа данных подразумевает наличие
основных алгоритмов обработки графов, а их выполнение на каждом подграфе, которые относятся к одному классу, означает возможность выполнения алгоритма на всей выборке графов одновременно.
2. Группировка (агрегация) результатов анализа, говорит о возможности сбора результатов в одном множестве.
3. Визуализация графа, подразумевает, что в решении граф отображается в виде вершин и рёбер, и результат выполненного алгоритм отражается на множестве графа.
Таким образом, рассмотренные альтернативные решения не имеют необходимых методов для решения поставленных задач, а именно:
1. Если нет возможности выполнения одного алгоритма на нескольких подграфах соответствующего класса, которые относятся к множеству графа, то нет возможности отобразить группу результатов обработки данных.
2. При отсутствии сгруппированных данных, полученных в результате некоторого алгоритма, возможность анализа общей графовой структуры анализируемой системы отсутствует.
Проект системы
Диаграмма вариантов использования (сценариев поведения, прецедентов) является исходным концептуальным представлением системы в процессе ее проектирования и разработки. Данная диаграмма состоит из актеров, вариантов использования и отношений между ними.
Использования данной диаграммы позволяет определить субъекты, которые взаимодействуют с моделируемой системой извне, а также набор функций, которые система предоставляет субъекту в качестве варианта использования. Рассмотрим процесс взаимодействия пользователей с системой в рамках разрабатываемого алгоритма, для этого построим диаграмму вариантов использования (рисунок 5)

Рисунок 5 – Диаграмма вариантов использования
Рассмотрим данный рисунок более подробно. В роли пользователя выступает аналитик, цель которого выполнить анализ данных на графах, хранящихся в графовой СУБД.
При проектировании системы, были созданы следующие варианты использования, в качестве функционала системы, с которыми аналитик может взаимодействовать:
1. Аналитик может создать подключение к собственной графовой СУБД,для этого необходимо ввести следующие данные: имя хоста, порт, пароль и имя (логин).
2. Если существует подключение к графовой СУБД, при помощи которого, можно получить данные, а именно графы, то аналитик может выполнитьиханализ, при помощи существующих методов, но перед этим необходимо выполнить классификацию графа, то есть определить к какому виду он относится.
3. Источник данных в разрабатываемом алгоритме представляет собой таблицу, в которой хранятся результаты выполнения методов анализа данных, но для того, чтобы его создать, необходимо определить временную метку и тип данных каждого из атрибутов вершины графа.
4. Построение графиков и диаграмм осуществляется по выбранным измерениям, мерам и типе диаграммы или графика, а также при условии, что существует необходимый источник данных.
Модель потоков данных
Модель потоков данных представляет собой DFD – нотацию, которая предназначена для моделирования информационных систем с точки зрения хранения, обработки и передачи данных.
Главные задачи данной модели это:
- выяснить из чего состоит информационная система, в данном случае алгоритм;
- определить необходимые ресурсы, которые необходимы для выполнения обработки информации;
- выявить как данные передаются между внутренними и внешними объектами алгоритма, а также где они хранятся.
На рисунках 6-7 изображена модель потоков данных в разрабатываемом алгоритме.

Рисунок 6 – Общее представление модели
На данной схеме изображены основной субъект – аналитик, а также основной процесс – алгоритм анализа данных.
Аналитик задаёт параметры подключения к графовой СУБД, а в процессе анализа графов, в качестве результата получает графики.

Рисунок 7 – Модель потоков данных второго уровня
В процессе создания подключения, его параметра хранятся в локальной базе данных системы в виде метаданных.
Далее перед получением графа из БД, сперва необходимо получить название подключения и его данные из списка подключений, а после получить граф используя полученные данные. Этот список является одной из таблиц локальной базы данных.
Классификация графа производится при наличии графа в базе данных. По полученному классу, и самому графу выполняются методы обработки, которые хранятся в виде списка.
По результату обработки данных графа создаётся источник данных на основе таблицы из столбчатого хранилища ApacheDruid, также необходимо определить измерения и меры, которые необходимы для создания графиков по результатам обработки.
Методы анализа данных
В данном разделе рассматриваются используемые алгоритмы в рамках решаемойзадачи.
В рассматриваемых методах приводится подробное описание, уравнения и формулы, которыеиспользуются при работе функции, предусловие, которое необходимо выполнить для корректного выполнения и результат работы.
Поиск в ширину
Поиск в ширину (breadth first search, BFS) – один из фундаментальных алгоритмов обхода графа. Он начинается с выбранной вершины и исследует всех ее соседей на расстоянии одного перехода, а затем посещает всех соседей на расстоянии двух переходов и т. д.
BFS чаще всего используется в качестве основы для других более целенаправленных алгоритмов. Например, алгоритмы кратчайшего пути, связанных компонентов и центральности применяют алгоритм BFS. Его также можно использовать для поиска кратчайшего пути между вершинами.
На рисунке 8 изображена последовательность обхода вершин при выполнении данного метода.

Рисунок 8 – Поиск в ширину
Поиск в ширину работает путём последовательного просмотра отдельныхуровнейграфа, начиная с узла-источника  {\displaystyle u}.
{\displaystyle u}.
Рассмотрим всерёбра  {\displaystyle (u,v)}, выходящие изузла
{\displaystyle (u,v)}, выходящие изузла  {\displaystyle u}. Если очередной узел{\displaystyle v} является целевым узлом, то поиск завершается; в противном случае узел {\displaystyle v}добавляется в очередь. После того, как будут проверены все рёбра, выходящие из узла {\displaystyle u}, из очереди извлекается следующий узел {\displaystyle u}, и процесс повторяется.
{\displaystyle u}. Если очередной узел{\displaystyle v} является целевым узлом, то поиск завершается; в противном случае узел {\displaystyle v}добавляется в очередь. После того, как будут проверены все рёбра, выходящие из узла {\displaystyle u}, из очереди извлекается следующий узел {\displaystyle u}, и процесс повторяется.
Поиск в глубину
Поиск в глубину (depth first search, DFS) – это еще один фундаментальный алгоритм обхода графа. Он начинается с заданной вершины, выбирает одну из соседних вершин, а затем спускается по этому пути на максимальную глубину и возвращается.
На рисунке 9 изображена последовательность обхода вершин при выполнении данного метода.
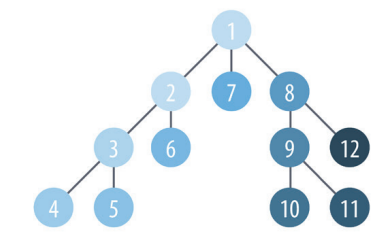
Рисунок 9 – Поиск в глубину
Пусть  – перечисление вершин V. Перечисление
– перечисление вершин V. Перечисление 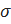 называется порядком DFS (с исходным
называется порядком DFS (с исходным  если для всех
если для всех  – это вершина
– это вершина  такая, что
такая, что  максимально.
максимально.
 – множество соседей
– множество соседей 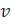 . Эквивалентно, является упорядочиванием DFS, если для всех
. Эквивалентно, является упорядочиванием DFS, если для всех  с участием
с участием  существует сосед
существует сосед 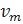 из
из 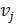 такой, что
такой, что  .
.
Ранжирование
Данная группа содержит методы для выявления узлов графа путем их упорядочения по степени важности факторов ранжирования (коммерческие, ссылочные, текстовые и другие).
В данной работе для реализации ссылочного ранжирования будет использоваться метод PageRank.
Ссылочное ранжирование используется для определения порядка согласно рейтингу популярности и релевантности.
Метод PageRankизмеряет важность каждого узла в графе на основе количества входящих связей и важности соответствующих исходных узлов. Более конкретно можно описать следующим образом: «узел важен ровно настолько, насколько важны узлы, которые на него ссылаются»
Предусловия для выполнения данного метода:
1. Граф должен быть ориентированным, допускаются мультиграфы.
2. Каждой паре вершин должен соответствовать некоторый вес (вероятность перехода).
PageRank является функцией описанной в исходном документе Google [14], которая должна решать следующее уравнение:

где
- 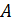 – текущий узел;
– текущий узел;
-  по
по  –узлы, которые указывают на текущий узел;
–узлы, которые указывают на текущий узел;
-  – коэффициент демпфирования (затухания), который устанавливается в промежутке
– коэффициент демпфирования (затухания), который устанавливается в промежутке  . Обычно устанавливается значение равное 0,85;
. Обычно устанавливается значение равное 0,85;
-  определяется как количество ссылок, рёбра которых инцидентны узлу , то есть выходящие из данного узла.
определяется как количество ссылок, рёбра которых инцидентны узлу , то есть выходящие из данного узла.
В результате выполнения метода выводится все атрибуты узла и его рейтинг популярности. Данный метод подсчитывает количество и качество ссылок на узлы, что определяет оценку важности каждого и узлов. Общее предположение заключается в том, что узлы, которые более важны в сети, получают больший объем ссылок.
Примеры использования алгоритма:
1. Прогнозирование транспортных потоков и движения людей в общественных местах или на улицах. Алгоритм выполняется на графе пересечений дорог, где показатель PageRank отражает тенденцию людей парковаться или заканчивать свое путешествие на определенной улице.
2. Часть систем обнаружения аномалий и мошенничества в сфере здравоохранения и страхования. PageRank помогает выявить врачей или клиентов, которые ведут себя необычным образом, и результаты затем вводятся в алгоритм машинного обучения.
Поиск кратчайшего пути
Алгоритм кратчайшего пути (shortest path algorithm) вычисляет кратчайший (взвешенный) путь между двумя вершинами. Он полезен для анализа взаимодействий между пользователями и для динамических рабочих процессов, потому что работает в режиме реального времени.
Алгоритм кратчайшего пути Дейкстры работает, сначала находя отношение наименьшего веса от начальной вершины к непосредственно связанным вершинам. Он отслеживает эти веса и перемещается к «ближайшему» узлу. Затем он выполняет те же вычисления, но теперь в виде совокупного итога от начальной вершины. Алгоритм продолжает делать это, оценивая «волну» совокупных весов и всегда выбирая наименьший взвешенный совокупный путь для продвижения вперед, пока не достигнет точки назначения.
На рисунке10 можноувидеть кратчайший путь между вершинами Aи F в неориентированном графе без весов.

Рисунок 10 – Кратчайший путь от А до F
Путь в неориентированном графе представляет собой последовательность вершин  , таких что
, таких что  смежна с
смежна с  для
для  . Такой путь
. Такой путь  называется путём длиной
называется путём длиной  из вершины в
из вершины в  (
( указывает на номер вершины пути и не имеет никакого отношения к нумерации вершин на графе).
указывает на номер вершины пути и не имеет никакого отношения к нумерации вершин на графе).
Пусть  – ребро, соединяющее две вершины: в . Дана весовая функция
– ребро, соединяющее две вершины: в . Дана весовая функция  , которая отображает ребра на их веса, значения которых выражаются действительными числами, и неориентированный граф
, которая отображает ребра на их веса, значения которых выражаются действительными числами, и неориентированный граф  .
.
Тогда кратчайшим путём из вершины в вершину  будет называться путь
будет называться путь  , где
, где  , который имеет минимальное значение суммы
, который имеет минимальное значение суммы  . Если все ребра в графе имеют единичный вес, то задача сводится к определению наименьшего количества обходимых ребер.
. Если все ребра в графе имеют единичный вес, то задача сводится к определению наименьшего количества обходимых ребер.
В результате работы выводятся все узлы, которые составляют найденный путь, а именно атрибуты и накопительная сумма ребер (или переходов), для узла, который находится в начале пути сумма будет нулевой.
Примеры использования алгоритма:
1. Поиск направлений движения между локациями. Популярные картографические веб-приложения, такие как Google Maps, используют алгоритм кратчайшего пути или его варианты для построения маршрута движения.
2. Определение степени разделения людей в социальных сетях. Например, при просмотре профиля в LinkedIn, алгоритм показывает, сколько людей разделяют пользователей на графе, а также перечисляет их взаимные связи.
Кластеризация
Алгоритм сильно связанных компонентов (strongly connected components, SCC) является одним из самых ранних алгоритмов, выполняемых на графах. SCC находит такие наборы связанных между собой вершин в ориентированном графе, где каждая вершина доступна в обоих направлениях от любой другой вершины в том же наборе. Также время выполнения данного алгоритма неплохо масштабируется пропорционально количеству вершин.
На рисунке11можноувидеть, что вершины в группе SCC могут не быть непосредственными соседями, но между всеми вершинами в наборе должны быть направленные пути.
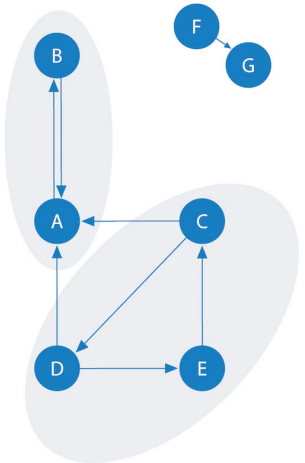
Рисунок 11 – Фрагменты сильно связанных компонентов
Компонент сильной связности представляет собой максимальное подмножество вершин  таких, что любые две вершины этого подмножества достижимы друг от друга, то есть для любых
таких, что любые две вершины этого подмножества достижимы друг от друга, то есть для любых 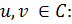

где  означает достижимость, другими словами, достижимость от одной вершины до другой.
означает достижимость, другими словами, достижимость от одной вершины до другой.
Очевидно, что сильно связные компоненты не пересекаются, т.е. это разбиение всех вершин графа.Таким образом, мы можем определить конденсационной граф 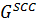 как граф, содержащий каждый сильно связный компонент как одну вершину. Между двумя вершинамиестьориентированное ребро
как граф, содержащий каждый сильно связный компонент как одну вершину. Между двумя вершинамиестьориентированное ребро  конденсационного графа тогда и только тогда, когда есть две вершины
конденсационного графа тогда и только тогда, когда есть две вершины 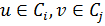 такие, что, в исходном графе есть ребро, то есть
такие, что, в исходном графе есть ребро, то есть 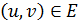 .
.
Разложение ориентированного графа на сильно связанные компоненты является классическим применением алгоритма поиска в глубину. Под капотом используется DFS как часть реализации алгоритма SCC.
2.6Уточненныетребования к работе
После изучения текущего состояния исследуемой проблемы, а также после проведения обзора существующих решений и изучению их достоинств и недостатковв главе 1, был сформирован конечный алгоритм, использующий графовые модели в качестве базы данных. В связи с этим, требования к результату работы были уточнены:
- требуется разработать алгоритм, который позволяет обрабатывать графы из графовой базы данныхNeo4j;
- обработка данных должна осуществляться различными методами для анализа данных на графах;
- должен быть реализован метод агрегирования результатов обработки данных графа;
- должна быть возможность анализа результатов работы алгоритма с помощью диаграмм.
Выводы по главе 2
В ходе аналитического анализа было произведено сравнение решений, представленных в главе 1, составлены проект и модель системы по требованиям, а также выбраны методы анализа данных.
Результаты анализа существующих решений и их сравнения, показывают, что большинство из них опираются на:
1) визуализацию графа, но в случае с графами свойств, возникают трудности в отображении свойств каждой вершины графа;
2) получение исходных данных из заранее подготовленных файлов, что приводит к временным затратам;
3) обработку данных и отображение результата только на одном рассматриваемом графе, что приводит к невозможности группировке результатов анализа данных.






