В настоящее время количество электронных данных растёт всё более быстрыми темпами, как по размеру, так и по возможности подключения. Как следствие – рост присутствия и интерес к взаимосвязям между данными. В связи с растущим интересом, увеличивается спрос на технологии, которые могут обрабатывать такие данные.
На сегодняшний день реляционные базы данных являются преобладающей технологией, но они плохо подходят для обработки связанных данных, поскольку оптимизированы для операций с интенсивным индексированием. Так как предполагается работа с наборами данных, реализация операции «связывания» на таких наборах может привести к непредсказуемой задержке запросов, и чрезмерному использованию памяти.
На рисунке 1 изображен рейтинг баз данных в период с 2013 по 2021 год, диаграмма предоставлена с сервиса db-engines [16].
На предоставленном графике можно наблюдать рост популярности графовой базы данных Neo4j относительно других реляционных и документарных баз
данных, что говорит об увеличении количества разрабатываемых алгоритмов,платформ и сервисов, в которых используется графовая модель данных.

Рисунок 1 – рейтинг баз данных
Рейтинг составлен по подсчету очков, которые рассчитываются по: количеству упоминаний системы на веб-сайтах, общему интересу к системе в googletrends, частоте технических обсуждений системы, количеству предложений о работе, количеству профилей в профессиональных сетях, актуальностью в социальных сетях.
Для связных данных всё чаще используют графовые модели, так как они превосходят по скорости вычисления реляционные, что является главным преимуществом базовой модели, также к ним относятся гибкость модели и оперативность доступа к данным[8].
Среди графовых СУБДNeo4jявляется самой популярной на данный момент времени. Убедиться в этом можно обратившись всё к той же статистике db-engines (рисунок 2).

Рисунок 2 – рейтинг графовыхСУБД
Neo4jявляется лидером среди графовых баз данных благодаря своей общедоступности и потому, что в ней присутствуют все необходимые характеристики баз данных, включая набор свойств, которые обеспечивают безопасную обработку транзакций (ACID).
Наличие собственного языка для написания запросов (Cypher) к базе данныхNeo4j, также поспособствовало росту популярности, так как он является SQL – подобным, что открывает путь к легкому взаимодействию между пользователем и базой данных.
Такие модели как: социальные сети, геоинформационные и банковские системы уже активно используют преимущества хранения сложно-связанныхданных в виде графов, что даёт им преимущество в анализе и прогнозировании.
Без графовой аналитики, банки и финансовые учреждения, использующие реляционные базы данных и общепринятые подходы, рискуют потерять конкурентное преимущество и понести серьезные финансовые затраты, подвергая себя рискам, которые можно было предвидеть и предотвратить заблаговременно [11].
В настоящее время наиболее популярным представлением связных данных в бизнес-аналитике является модель графа свойств или, другими словами, атрибутного графа (Propertygraphmodel).
Большое количество систем, используют модели графа свойств, так как они придают гибкости и более подробно отражают структуру каждого объекта и связей между ними.
На рисунке 3 изображен пример графа, в котором у вершин и ребер имеется атрибутный состав.

Рисунок 3 – Модель графа свойств
На данном рисунке можно наблюдать некоторые нюансы, которые присущи графам сатрибутным составом, а именно:
1) вершины могут иметь некоторый набор свойств;
2) некоторые ребра имеют свойства, которые представляют «причины» возникновения связи между вершинами;
3) граф может являться мультиграфом, так как «причины», которые описываются инцидентными ребрами, могут быть разными для каждой вершины.
Архитектура большинства предлагаемых решений для систем, общая деятельность которых это работа с пользователями, и которые предполагают наличие большого количества связей между ними или другими объектами, строятся на основе модели графа свойств.
Рассмотрим некоторые часто используемые варианты использования графов в сфере бизнес-аналитики.
В графовой модели социальной сети выявляются самые популярные пользователи, а также сообщества, которые они образуют. Также рекомендации в социальных сетях формируются на предпочтениях друзей, к примеру: поиск общих друзей, поиск сообществ, в которых состоят друзья.
В банковской сфере графы используются в качестве решения проблем для отслеживания путей транзакций, осуществляемых пользователями, что обеспечивает некоторую безопасность, и даёт возможность выявления «подозрительных» транзакций (предполагаются мошеннические переводы) [11].
В транспортных задачах на графах рассчитываются: кратчайший путь от точки отправления до места назначения, наиболее встречающиеся на пути вершины и тому подобное.
Проблемой является то, что у каждого из рассмотренных примеров данные могут храниться в разряженном множестве, то есть в виде множества графов или подграфов. Поэтому необходимо группировать или, другими словами, выполнять операцию агрегирования на множестве графов для общего анализа.
Тем не менее графы широкоприменяются в области бизнес-аналитики благодаря своей способности к хранению и анализу данных, обладающих сложной иерархической структурой, различные элементы которой по-разному могут обрабатываться в рамках аналитических операций.
ГрафовыеСУБД в своё время хорошо подходят для моделирования, хранения и обработки объектов предметной области, обладающих явной сетевой структурой.
Обзор существующих решений
Первой решенной в данной области задачей является «Семь мостов Кенигсберга». Суть задачи состояла в том, чтобы выяснить, можно ли посетить все четыре района города, соединенные семью мостами, пересекая каждый мост только один раз.
Решил данную задачу Леонард Эйлер в 1736 году. Обдумывая алгоритм решения данной задачи, Эйлер понял, что для её решения необходимо обратить внимание на связи между объектами, и представив их в виде узлов и связей между ними решил задачу, тем самым заложив основы теории графов и её математики [1].
На рисунке 4 изображена последовательность анализа данных из рассуждений Эйлера и один из его оригинальных набросков из статьи «Solutioproblematisadgeometriamsituspertinentis» [10].
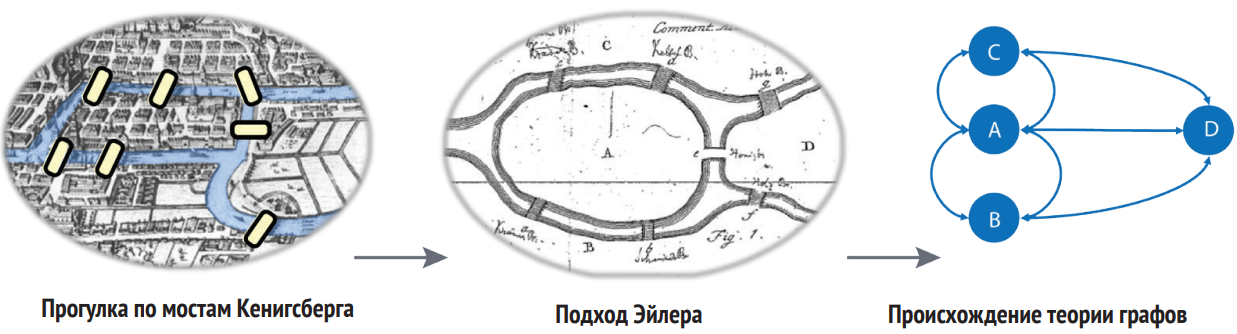
Рисунок 4 – Первая решенная задача при помощи анализа данных на графовой модели
Среди современных решений существует множество различных реализаций, которые отличаются различными способами: импортирования, обработки и визуализации данных, а также количеством рёбер и узлов, которое способен обработать тот или иной алгоритм за наименьшее время.
Gigraph
Gigraph–инструментExcel, который позволяет построить с помощью табличного from-to-value (источник-назначение-величина) представления графы,так называемые интерактивные карты взаимосвязей.
Основным недостатком этого инструмента является ограничение по объему анализируемых данных – программе не удается корректно отобразить граф,имеющий более 2000 узлов.
Таким образом, компонент GIGRAPH можно рассматривать как инструмент оперативного анализа малого объема данных или репрезентативной выборки,что позволит аналитику быстро определить ключевые тенденции, вероятнее всего присутствующие в полной выборке.
Gephi
Gephiпредставляет собой пакет программного обеспечения с открытым исходным кодом для визуализации и анализа связанных данных.
Ключевые особенности Gephi:
1) поддержка форматов входных данных: GraphViz, GDF, GEXF, GML, GraphML;
2) большое количество свойств для настройки отображения графа;
3) поддержка алгоритмов кластеризации, ранжирования и укладки (расположение графов по определенному шаблону);
4) локализация.
Графовая аналитика в Gephiтребует большой предварительной работы над исходными данными, так как перед импортомнеобходимо подготовить два специальных файла:
1. Файл вершин (вершины графа являются объектами), в котором обязательно должно быть поле ID. Этого файла достаточно, чтобы построить неориентированный граф.
2. Файл ребер (ребра являются связями), в котором должны быть поля Источника (Source – исходной, отправной точки) и Назначения (Target – цели, точки, куда направлен поток информации на графе).
Загрузка исходных данных производится в несколько шагов. На каждом шаге отрабатывает алгоритм проверки входных данных на корректность.
Импортированные данные можно фильтровать, а также есть возможность фильтрации количества узлов и рёбер при помощи регулярных выражений и логических операторов.
К недостаткам данного решения можно отнести следующее:
1) большая работа с предварительной обработкой исходных данных;
2) устаревший интерфейс;
3) нет возможности подключения собственной СУБД;
Пакетная загрузка данных приводит к тому, что при изменении хранящейся в БД информации, необходимо каждый раз снова импортировать новый набор данных, который ещё может и не соответствовать требованиям, как следствие выполнение пользователем немалой работы в направлении предобработки входных данных.
Так как решение представлено в виде нативного приложения и интерфейс написан на языке Java, в сравнении с другими современными интерфейсами он выглядит устаревшим.
Приложение не предоставляет варианта импортирования данных напрямую из графовой СУБД.
GraphOnline
Данное решение представляет собой веб-приложение по анализу данных на графах, которое позволяет визуализировать графы и применять множество алгоритмов.
В отличии от предыдущего решения, позволяет импортировать данные тремя различными способами:
1) по матрице смежности;
2) по матрице инцидентности;
3) по матрице расстояний.
Graphonlineпредоставляет множество общих алгоритмов анализа данных на графах, но из ключевых недостатков можно выделить следующие:
1. Нет поддержкиграфов типа PropertyGraph, вершины могут иметь только ID, а ребра могут быть определены только с весом, но без дополнительных таблиц свойств отношения.
2. Нет возможности выгрузить граф из собственной графовой СУБД.
1.3Термины и определения
В данной работе используются понятия из областей теории графов ибаз данных. Далее будут приведены определения наиболее важных понятий.
Теория графов
Граф – это структура, представляющая собой набор объектов, в котором некоторые пары объектов в некотором смысле «связаны»Граф  называется подграфом графа
называется подграфом графа 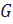 , если
, если  . Всякий подграф может быть получен из графа удалением некоторых вершин и ребер.
. Всякий подграф может быть получен из графа удалением некоторых вершин и ребер.
Вершина или узел представляют собой фундаментальную единицу,из которой формируются графы.
Ребром в неориентированном графе называют неупорядоченнуюпару вершин, а в ориентированном – упорядоченную: 
Если пара вершин соединена более чем одним ребром, то ребра являются кратными.
Петлей в графах называется ребро, концы которого совпадают, то есть  .
.
Ребра, имеющие общую конечную вершину, то есть  и
и  , называют смежными.
, называют смежными.
Степеньювершины  в неориентированном графе называют число рёбер, инцидентных
в неориентированном графе называют число рёбер, инцидентных  .
.
Смежность вершин графа – это когда две вершины 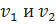 соединены ребром
соединены ребром  .
.
Инцидентность – понятие, которое используется только в отношении ребра и вершины: если – вершины, а – соединяющее их ребро, тогда вершина  и ребро
и ребро  инцидентны, вершина
инцидентны, вершина  с ребром также инцидентны.
с ребром также инцидентны.
Граф называется связным, если он содержит хотя бы одну компоненту связности, то есть существует хотя бы одна пара вершин, связанная ребром.
Ориентированный граф – это граф, в котором каждое ребро является направленным, то есть:
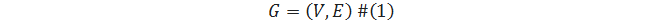
где V – множество вершин,
 – множество ребер.
– множество ребер.
Неориентированный граф – это граф, в котором каждое ребро не имеет направления:
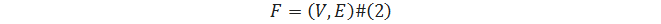
где V – множество точек, называемых вершинами,
 – множество ребер.
– множество ребер.
Смешанный граф – это граф, в котором некоторые ребра могут быть направленными и некоторые из них могут быть неориентированными.
Взвешенный граф представляет собой граф, в котором каждому ребру присваивается число (вес). Такие веса могут отражать стоимость, длину или вместимость, в зависимости от решаемой проблемы.
Конечный граф представляет собой графG, в котором множество вершин и множество ребер имеют конечные множестваV и E. Иначе граф будет называться бесконечным.
Полный граф – граф, в котором каждая пара различных вершин смежна. Полны граф с  вершинами имеет
вершинами имеет  рёбер и обозначается
рёбер и обозначается 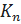 .
.
Мультиграф – граф, в котором может быть пара вершин, которая соединена более чем одним ребром (ненаправленным), либо более чем двумя дугами противоположных направлений [3].
Матрица смежности графа – матрица, значения элементов которой характеризуются смежностью вершин графа. При этом значению элемента матрицы присваивается количество ребер, которые соединяют соответствующие вершины, то есть которые инцидентны обоим вершинам.

Матрица инцидентности графа – матрица, значения элементов которой характеризуется инцидентностью соответствующих вершин графа (по вертикали) и его рёбер (по горизонтали). Для неориентированного графа элемент принимает значение1, если соответствующие ему вершина и ребро инцидентны. Дляориентированногографа элемент принимает значение1,если инцидентная вершина является началом ребра, значение-1, если инцидентная вершина является концом ребра; в остальных случаях (в том числе и дляпетель) значению элемента присваивается0.
Путь в графах определяется последовательностью вида

где  ,
,
k – длина пути.
Длина пути – количество рёбер, входящих в последовательность, задающую этот путь.
Цикл – класс эквивалентности циклических путей на отношении эквивалентности таком, что два пути эквивалентны, если

где и 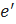 – это две последовательности рёбер в циклическом пути.
– это две последовательности рёбер в циклическом пути.
Циклический путь в ориентированном графе – это путь, в котором  , в неориентированном графе называется путь, в котором , а также
, в неориентированном графе называется путь, в котором , а также  .
.
Диаметром неориентированного графа 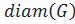 называется максимальная длина кратчайшего пути между двумя вершинами, а минимальный из эксцентриситетов вершин связного графа называетсярадиусом графа
называется максимальная длина кратчайшего пути между двумя вершинами, а минимальный из эксцентриситетов вершин связного графа называетсярадиусом графа  [4]. Другими словами:
[4]. Другими словами:

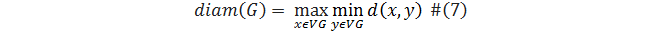
Базы данных
Данные – конкретная информация, необходимая для представления фактов и понятий для интерпретации и обработки с помощью автоматических средств для решения конкретных задач.
Модель данных представляет собой совокупность структур данных и операций их обработки. С их помощью могут быть представлены информационные объекты и взаимосвязи между ними.
Одним из основных типов моделей данных – сетевая, которая состоит из узлов, уровней и связей. В сетевом представлении каждый узел может образовывать связь с любым другим узлом.
Схема данных представляет собой набор данных с описанием содержаний, структур и ограничений целостности, которые используются при создании и поддержке баз данных.
База данных (БД) – совокупность данных, хранимых в соответствии со схемой данных, операции над которыми выполняются в соответствии с правилами средств моделирования данных.
Система управления базами данных (СУБД) – комплекс программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Графовая база данных – это одна из разновидностей баз данных, в которой реализована сетевая модель данных в виде графа и его обобщений. Соответственно графовая СУБД представляет собой систему управления графовыми базами данных.
Язык запросов–это специализированный язык, на котором выполняются запросы к базам данных и прочим информационным системам, отдельно стоит выделить информационно-поисковые системы.
ResourceDescriptionFramework (RDF) – разработанная консорциумом Всемирной паутины модель представления данных, в основном – метаданных. Структура данных в таком представлении отображается с помощью триплета «субъект – предикат – объект» [5].
PropertyGraph – это тип графовой модели, где отношения не только являются связями, но также несут имя (тип) и некоторые свойства [15]. Данный тип предоставляет более обширное представление о том, как данные могут быть смоделированы по множестве различных баз данных, а также о том, как связаны разные виде метаданных.
OLAP – это технология, которая позволяет проводить многомерный и многоуровневый анализ большого объема данных, обеспечивая визуализацию агрегированных данных с разных точек зрения [13].
Выводы по главе 1
В процессе исследования литературы было установлено, что подходы к решению поставленной задачи можно разделить на две группы – разработку универсального алгоритма, который способен обрабатывать любые типы графов, и разработку алгоритма под конкретные задачи.
Для решения поставленной задачи был выбран вариант отображения сгруппированных результатов работы алгоритмов анализа данных на диаграммах, чтобы получить более детальный результат по каждому объекту, а также в качестве источника исходных данных будет использоваться самая популярная из графовых баз данных – Neo4j.





