Алгоритм сортировки с прямыми включениями легко можно улучшить, пользуясь тем, что готовая последовательность a[1], a[2],.., a[i-1], в которую нужно включить новый элемент, уже упорядочена. Поэтому место включения можно найти значительно быстрее. Очевидно, что здесь можно применить бинарный поиск, который исследует средний элемент готовой последовательности и продолжает деление пополам, пока не будет найдено место включения. То есть при поиске места вставки очередного элемента просматриваем не все элементы, а только "средние".
Рассмотрим пример сортировки по возрастанию восьми случайно выбранных чисел 44 55 12 42 18 19 06 67. При i=6 отсортированная последовательность состоит из пяти чисел 12 18 42 44 55. Очередной элемент 19 необходимо вставить в последовательность. Поиск места будет проходить следующим образом: находим средний элемент отсортированной последовательности. Это 42. Если он больше вставляемого элемента, то находим средний элемент для левой части последовательности относительно элемента 42, иначе находим средний элемент правой части последовательности относительно 42. Следующий средний - 18. Повторяем сравнения и т.д.
Такой модифицированный алгоритм сортировки называется методом с двоичным включением.
Он реализуется следующей процедурой:
{ Двоичного включения }
procedure bin_insert(var a:mass; n:integer);
var i,j,m,R,L,x:integer;
Begin
for i:=2 to n do
begin x:=a[i]; L:=1; R:=i;
While L<R do
begin
m:=(L+R) div 2; { Находим индекс среднего элемента }
if a[m]<=x then L:=m+1 else R:=m;
end;
{ Дальше сдвигаем массив с позиции R +1 до i a [ R +1],…, a [ i ] на одну позицию вправо, начиная с места i }
for j:=i downto (R+1) do a[j]:=a[j-1];
a[R]:=x;
end; { Цикла по i }
end; { bin_insert }
Место включения элемента x в последовательность обнаружено когда l=r. Здесь улучшения, порожденные введением двоичного поиска, касаются лишь числа сравнений, а не числа необходимых продвижек (перестановок) чисел.
Поскольку движение элемента занимает значительно больше времени, чем сравнение двух чисел, то фактически улучшения не столь уж существенны, ведь число пересылок (присваиваний) М так и продолжает оставаться порядка n2. И на самом деле, сортировка уже отсортированного массива потребует больше времени, чем в случае последовательной сортировки с прямыми включениями. Таким образом, очевидные улучшения часто дают не столь уж большой выигрыш, как это кажется на первый взгляд. Сортировка с помощью включений не кажется столь удобным методом, так как включение одного элемента с последующим сдвигом на одну позицию целой группы элементов не экономно. Лучшие результаты дают методы, где передвижка, пусть на большие расстояния, будет связана лишь с одним единственным элементом.
Лексикографическая сортировка
Топологическая сортировка
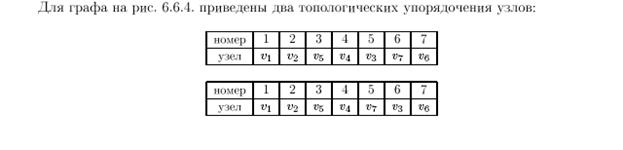
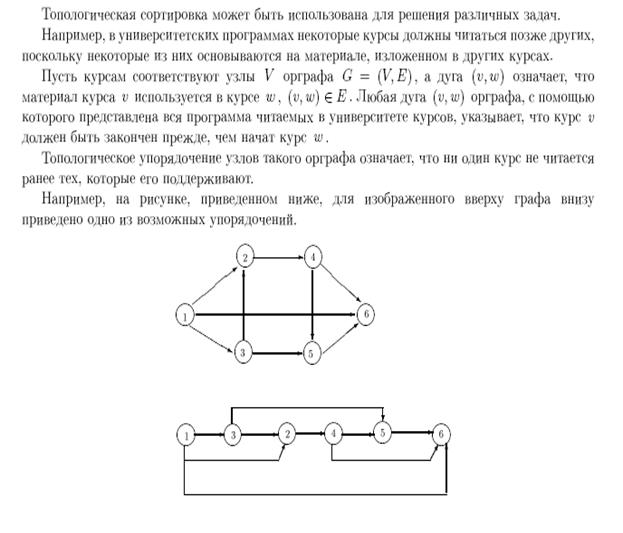
Топологическая сортировка применяется для элементов, для которых определен частичный порядок, то есть упорядочение задано не на всех, а только на некоторых парах.
Например:
1. В словаре термин определен через другие термины. Обозначим отношением U í V, если слово U определено через слово V. Топологическая сортировка означает, что в словаре все слова, участвующие в определении данного слова, находятся раньше его.
2. В программе процедура может содержать вызов других процедур. Обозначим отношением U í V, если процедура U вызывает процедуру V. Топологическая сортировка означает, что в программе описание всех вызываемых процедур находятся раньше описания вызывающей процедуры (понятие рекурсии здесь не рассматривается).
Определим частичный порядок на множестве S как отношение частичного порядка между элементами множества. Обозначим отношение порядка символом í (читается «предшествует»).
Отношение порядка удовлетворяет следующим трем свойствам:
1. Если x í y и у í z, то x í z (транзитивность).
2. Если x í y, то не у í х (ассимметричность).
3. Не выполняется x í x (иррефлексивность).
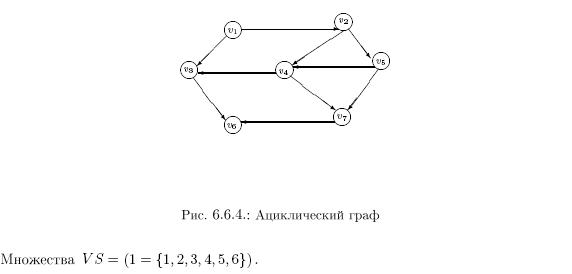
Частичную упорядоченность множества S можно представить в виде ориентированного графа, вершины которого соответствуют элементам множества S, а дуги — отношению порядка между соответствующими вершинами (элементами).
Свойства 1 и 2 частичного порядка элементов множества гарантируют отсутствие циклов в ортографе.
Цель топологической сортировки преобразовать частичный порядок в линейный. Свойства (1) и (2) частичного порядка обеспечивают отсутствие циклов. Это и есть то необходимое условие, при котором возможно преобразование к линейному порядку.
Чтобы найти одно из возможных линейных упорядочений, надо выбрать элемент, которому не предшествует никакой другой. Этот элемент помещается в начало списка и исключается из множества S. Оставшееся множество по-прежнему частично упорядочено, применим тот же алгоритм, пока множество S не станет пустым.
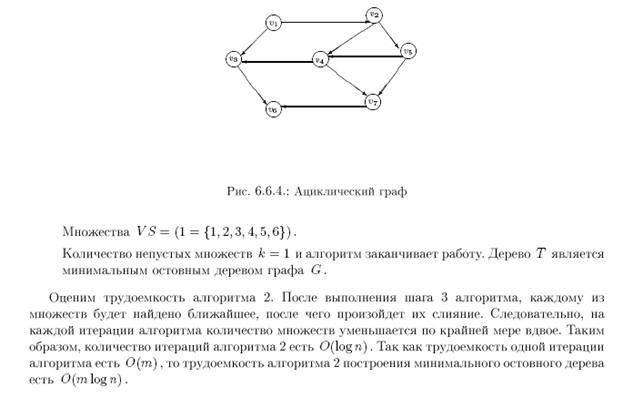
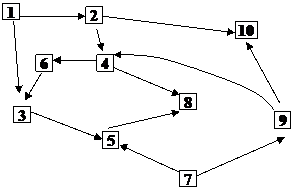
Рассмотрим пример топологической сортировки на множестве чисел: S={1, 2, 3, 4, 5, 6, 7, 8, 9, 10}.
Пусть отношение частичного порядка на множестве S задано следующими отношениями элементов:
1) 1<2
2) 2<4
3) 4<6
4) 2<10
5) 4<8
6) 6<3
7) 1<3
8) 3<5
9) 5<8
10) 7<5
11) 7<9
12) 9<4
13) 9<10
Удобно проиллюстрировать отношение частичного порядка с помощью графа, где вершины – это элементы множества, а стрелки – отношение порядка.
На графе отсутствуют циклы, что является необходимым условием частично упорядоченного множества.
Выберем элемент, которому не предшествует никакой другой – 7. Исключим его из множества. Выберем следующий элемент, которому не предшествует никакой другой – 9. И т.д.
В результате получим линейное упорядочение вида:
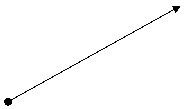
Представим каждый элемент множества тремя характеристиками: идентифицирующим ключом, счетчиком предшествующих элементов, множеством последующих элементов. Удобно организовать данные в виде связного списка. Тогда тип выбранных данных можно описать следующим образом:
Type lref = ^ leader; указатель на элемент
tref = ^ trailer; указатель на последующий элемент
leader = record
key: integer; идентифицирующий ключ
count: integer; счетчик предшествующих элементов
trail: tref; указатель на список последующих элементов
next: lref; указатель на следующий элемент списка
end;
trailer = record
id: lref; указатель на элемент, являющийся последователем
next: tref; указатель на следующий элемент списка
end;
В результате чтения исходных данных, в памяти будет хранится структура данных, представленная на рисунке:
Head
Tail
1
key
2
4
6
10
8
3
5
7
9
0
count
1
2
1
2
2
2
2
0
1
Для создания структуры данных нам понадобится функция, которая для каждого элемента w ищет его в списке и устанавливает на него указатель, а если не находит то добавляет в конец списка.
Будем считать, что список имеем голову (head) и хвост (tail):
function L(w: integer): lref;
var h: lref;
begin
h:= head; tail^.key:=w;
while h^.key <> w do h:= h^.next;
if h = tail then
begin
new(tail);
h^.count:= 0;
h^.trail:= nil;
h^.next:= tail;
end;
L:=h
End;
Введем переменную Z, определяющую число элементов в исходном множестве. При выполнении алгоритма Z уменьшается на 1 каждый раз, когда найден и выведен элемент, не имеющий предшественников. В результате работы Z должно стать равным 0, если выведены все элементы. В противном случае множество не является частично упорядоченным.
В программе использован еще один прием: исходное множество реорганизовано таким образом, чтобы в основном списке остались лишь элементы, у которых нет предшественников. Для удобства элементы в этот списка добавляются с головы.
После реорганизации списка, выполненной следующим образом, список будет выглядеть так:
p:= head; head:= nil;
while p<>tail do
begin
q:= p;
p:=p^.next;
if q^.count= 0 then
begin
q^.next:= head; head:= q;
end
end;
1
7
HEAD
0
0
Program Toposort;
Type
lref = ^leader;
tref = ^trailer;
leader = record
key, count: integer;
trail: tref;
next: lref;
end;
trailer = record
id: lref;
next: tref;
end;
Var
head, tail, p, q: lref;
t: tref;
z, x, y: integer;
function L(w: integer): lref;
var h: lref;
begin
h:= head; tail^.key:=w;
while h^.key <> w do
h:= h^.next;
if h = tail then
begin
new(tail);
inc(z);
h^.count:= 0;
h^.trail:= nil;
h^.next:= tail;
end;
L:=h
end;
Begin
new(head); tail:= head;
z:= 0;
{создание структуры данных}
read(x);
while x <> 0 do
begin
read(y);
p:=L(x); q:=L(y);
new(t); t^.id:=q;
t^.next:= p^.trail;
p^.trail:= t;
inc(q^.count);
read(x);
end;
{реорганизация списка}
p:= head; head:= nil;
while p<>tail do
begin
q:= p;
p:=p^.next;
if q^.count= 0 then
begin
q^.next:= head;
head:= q;
end
end;
{проход по списку и вывод элементов, с изменением поля Count у последователей и добавлением новых элементов в список}
q:= head;
while q <> nil do
begin
writeln(q^.key);
dec(z);
t:= q^.trail;
q:= q^.next;
while t <> nil do
begin
p:= t^.id;
dec(p^.count);
if p^.count = 0
then
begin
p^.next:=q;
q:= p;
end;
t:= t^.next
end;
end;
if z <> 0 then writeln('Множество не является частично упорядоченным');
end.
Поразрядная сортировка
Обменную поразрядную сортировку открыли П.Хильдебрандт, Г.Исбитц Х.Райзинг и Ж.Шварц, примерно за год до открытия быстрой сортировки.
Этот метод отличен от всех, рассмотренных выше. В нем используются двоичные представления ключей и сравниваются не сами ключи, а отдельные биты. Метод обладает характеристиками обменной сортировки и очень напоминает быструю сортировку.
Массив сортируется сначала по старшему значащему биту, так что вначале идут элементы, начинающиеся с 0, а затем с 1. Будем просматривать массив с двух сторон, и как только слева встретится элемент со старшим битом равным 1, а справа – со старшим битом равным 0, поменяем их местами. После чего продолжим просмотр, до тех пор пока не встретимся в каком-то месте массива.
Таким образом, мы разделили массив на две части F0 (элементы со старшим битом равным 0) и F1 (элементы со старшим битом равным 1). Теперь применим к F0 алгоритм поразрядной сортировки, начиная уже со второго бита слева, и т.д. пока полностью не отсортируем массив F0, затем то же проделаем с F1.
Первый проход закончен. Теперь будут сортироваться массивы:
11 32 и 76 90 69 81 85 66 75 90
Рассмотрим рекурсивный алгоритм поразрядной сортировки. Для выделения k-го бита будем использовать операции битовой арифметики Shr и and.. Например, старший бит десятибитового числа извлекаются посредством сдвига числа на 9 позиций вправо и его побитового "and" с 0000000001. Cтаршие два бита десятибитового числа извлекаются посредством сдвига числа на 8 позиций вправо и его побитового "and" с 0000000011. Далее мы будем считать, что у нас есть такая функция bits(x, b, k:integer) для извлечения k бит с позиции b из числа х.
Type
vector= array[1..n] of word;
function Bits(x,b,k: integer): integer;
begin
Bits:=(x shr b) and (2k-1);
end;
procedure Radix (var x: vector);
procedure Sort(l,r,b: integer);
var i,j,t: integer;
begin
If (r>1) and (b>=0) then
begin
I:=l; j:=r;
Repeat
While (bits(x[i], b,1)=0) and (i<j) do i:=i+1;
While (bits(x[j], b,1)=1)and (i<j) do j:=j-1;
T:=x[i]; x[i]:=x[j];
x[j]:=t;
Until i=j;
if (bit(x[r], b, 1)=0
then j:=j+1;
Sort (l, j-1, b-1);
Sort(j, r, b-1);
End;
End;
Begin
Sort(1,n, Sizeof(x[1])*8)
End;
Поразрядная сортировка использует в среднем около N lg N битовых сравнений. Заметим, что поразрядная сортировка занимает почти столько же времени, сколько и быстрая сортировка, а ряде случаев является даже более эффективной.
Исключение рекурсии выполним как обычно, используя стек:
Procedure Radix (var x: vector);
Var i,j.l,r,b,t: integer;
S:Stack;
Begin
Push(s, l); Push(S,n);
Push(S,16);
Repeat
B:=pop(S);R:=pop(s);L:=pop(s);
repeat
I:=l; j:=r;
Repeat
While (bits(x[i],b,1)=0) and (i<j) do i:=i+1;
While (bits(x[j],b,1)=1)and (i<j) do j:=j-1;
T:=x[i];x[i]:=x[j]; x[j]:=t;
Until i=j;
if (bit(x[r],b,1)=0
then j:=j+1;
if j<r then
begin
Push(S,j); Push(s,r);
Push(s, b-1);
end;
R:=j-1;
B:=b-1;
Until (l>=r) or (b<0);
Until Empty(S);
End;
Другой метод поразрядной сортировки исследует биты справа налево. Этот метод использовался старыми машинами для сортировки карт: колода карт проходила сквозь машину 80 раз, по разу для каждой колонки, исследуя их справа налево.
Поверить в то, что этот метод на самом деле работает - нелегко. На самом же деле его легко проиллюстрировать на примере сортировки колоды карт. Предположим, что нам нужно отсортировать колоду из 52 карт в порядке:
Эту задачу можно решить двумя способами. Естественно отсортировать колоду сначала по масти, разложив на четыре стопки. А затем внутри каждой колоды отсортировать карты по достоинству. Этот способ является аналогом обменной поразрядной сортировки.
Второй способ не так очевиден, но более быстр. Он заключается в следующем: разложим карты на 13 стопок по достоинству (тузы, двойки, тройки и т.д.). Соберем стопки так, чтобы внизу были тузы, затем двойки и т.д. Перевернем колоду (тузы окажутся сверху) и разложим на четыре стопки по мастям (трефы, бубны, черви, пики). При втором раскладе в каждой стопке карты окажутся уже отсортированными по достоинству. Сложим все вместе и получим отсортированную колоду карт.
Таким образом, мы отсортировали колоду, двигаясь в записи карты (масть-достоинство) справа – налево. Тот же способ годится для сортировки числовых или буквенных данных.
Для чисел поразрядную сортировку можно выполнить следующим образом: произвести сортировку по младшим цифрам (в системе счисления M), затем по следующей цифре и т.д., то есть, двигаясь справа-налево. Например, при M=10 имеем:
X 503 087 512 061 908 170 897 271
Y 170 061 271 512 503 087 897 908
X 503 908 512 061 170 271 087 897
Y 061 087 170 271 503 512 897 908
При реализации этого метода на компьютерах необходимо решить, как хранить стопки. Очевидно, для них нужно выделять память. Допустим, мы ожидаем, что должно быть M стопок, в каждой из них могут оказаться все N элементов. Поэтому необходимо выделить дополнительную память M*N элементов, что слишком расточительно. Такая потребность в памяти заставляла программистов отказываться от метода поразрядной сортировки, до тех пор пока Х.Стьюворд в своей работе не показал, что проблему можно решить, выделив дополнительно лишь N элементов памяти и M счетчиков.
Для большого числа ситуаций мы знаем, что значения ключей в файле лежат в каких либо пределах. В этих ситуациях применим алгоритм, именуемый подсчетом распределения. Впервые подсчет распределения разработал Х.Стьюворд в 1954 году и использовал его в поразрядной сортировке.
Проиллюстрируем суть метода распределения на конкретном примере. Пусть значения массива X лежат в интервале от 0 до 9. Подсчитаем, сколько раз в массиве встречается каждое значение, а затем распределим соответствующим образом память под элементы массивы с учетом их частоты.
X 4 6 3 8 4 6 4 1 0 9
Счетчик 0 1 2 3 4 5 6 7 8 9
1 1 0 1 3 0 2 0 1 1
Распределение
Памяти 1 2 2 3 6 6 8 8 9 10
Y 0 1 3 4 4 4 6 6 8 9
Ниже приведена программа для этого простого алгоритма.
Procedure Sort(var x: vector);
Const M=10;
Var
y: vector;
I, j: integer;
Count: array[0..M] of integer;
begin
for j:=0 to M-1 do count[j]:=0;
for i:=1 to N do inc(count[x[i]]);
for j:=1 to M-1 do
count[j]:=count[j-1] + count[j];
for i:=N downto 1 do
begin
y[count[x[i]]]:= x[i];
dec(count[x[i]]);
end;
x:= y;
end;
Применим теперь эту идею распределения к поразрядной сортировке для двоичного основания ключей. Тогда цифры имеют только два значения, и метод подсчета распределения полностью здесь подходит. Если мы предположим М=2, то в программе подсчета распределения мы заменим x[i] на bits(x[i],b,1). На самом же деле, нет никакой необходимости в том, чтобы М было равно 2. Нам наоборот необходимо брать М=2m настолько большое, насколько это возможно. Таким образом, прямая поразрядная сортировка становится улучшенной сортировкой подсчетом распределения для w правых бит:
procedure StrightRadix (var x: vector);
Const m=4; Mp=16; W=16;
var
i, pass: integer;
count: array [0..Mp] of integer;
y: vector;
begin
for pass:= 0 to (w div m)-1 do
begin
for i:=0 to Mp-1 do count[i]:=0;
for i:=1 to N do inc(count[bits(x[i],pass*m,m)]);
for i:=1 to Mp-1 do inc(count[i],count[i-1]);
for i:=N downto 1 do
begin
y[count[bits(x[i],pass*m,m)]]:= x[i];
dec(count[bits(x[i],pass*m,m)]);
end;
x:= y;
end;
end;
Пирамидальная сортировка
Принципы пирамидальной сортировки будет проще понять, если рассмотреть два жизненных примера: организацию турнирной таблицы и корпоративную систему выдвижения.
1. Организация турнирной таблицы происходит следующим образом: в первом туре участники разбиты на пары и играют между собой, победители проходят в следующий тур и играют между собой и т.д. В полуфинале участвует 4 участника, в финале 2 и определяется победитель.
Теперь, чтобы определить второго по силе участника, надо вывести из турнира сильнейшего и разыграть турнир заново. Продолжая эту процедуру, найдем третьего по силе, четвертого и т.д.
Рассмотрим организацию турнира на примере «участников» - элементов массива (5, 2, 8, 9, 3, 1, 7. 2).
9
9
7
5
9
3
7
5
2
8
9
3
1
7
2
Победителем является «участник» 9. Выведем его из турнира, заменив на «чрезвычайно слабого игрока» -¥.
8
8
7
5
8
3
7
5
2
8
-¥
3
1
7
2
Победителем является «участник» 8. Выведем его из турнира, заменив на «чрезвычайно слабого игрока» -¥.
7
5
7
5
-¥
3
7
5
2
-¥
-¥
3
1
7
2
5
5
3
5
-¥
3
2
5
2
-¥
-¥
3
1
-¥
2
И т.д. Таким образом, происходит сортировка посредством выбора из дерева – выбирается максимальный элемент, находящийся в корне дерева.
2. Корпоративная система выдвижения заключается в следующем: из группы простых исполнителей на верхний уровень поднимаются лучшие (например, из группы программистов выдвигаются старшие программисты). Среди старших программистов отбирают руководителей лаборатории. Среди руководителей лаборатории отбирают руководителей отделов и т.д. При этом, когда участник поднимается с самого нижнего уровня, его заменяют «человеком с улицы» (-¥), а если выдвижение идет с очередного уровня, то его заменяют на лучшего из его подчиненных.
9
9
8
7
5
9
8
-¥
3
7
2
5
-¥
2
8
-¥
9
-¥
3
-¥
1
7
-¥
2
-¥
В результате получим корпоративную пирамиду, где каждый стоит на своем уровне компетентности.
9
8
7
5
-¥
3
2
-¥
2
-¥
-¥
-¥
1
-¥
-¥
Интуитивно второй способ более удобен – он позволяет избежать лишних сравнений -¥ с -¥, на которые мы будет то и дело натыкаться в турнирной таблице на поздних стадиях.
Пронумеруем теперь элементы пирамиды по уровням сверху-вниз и слева-направо:
X1
X2
X3
X4
X5
X6
X7
X8
X9
X10
X11
X12
X13
X14
X15
Заметим, что отцом k-го узла является узел с номером (k div 2), а потомками - узлы с номерами 2k и 2k+1.
В пирамиде выполнено условие
Xk div 2
Xk
X2k
X2k+1
Очевидным недостатком рассмотренного метода является большое число бесполезных дыр, содержащих -¥. Было бы очень хорошо организовать пирамиду на N ячейках (в нашем случае на 8, а не на 15).
Эта цель была реализована Дж. У. Дж. Уильямсом (John William Joseph Williams) в 1964 году, разработавшим алгоритм пирамидальной сортировки (heap-sort). В дальнейшем сортировку развивал Р.Флайд.
Будем называть массив X1, X2, X3 … Xn пирамидой, если выполнено условие:
Xjdiv 2 ³ Xj, при 1 £ j div 2 < j £ N.
Тогда X1 ³ X2, X1 ³ X3, X2 ³ X4, X2 ³X5, и т.д. В частности, наибольший ключ лежит на вершине пирамиды: X1 = max (X1 , X2, … Xn).
Если удастся каким-либо образом преобразовать массив в пирамиду, то можно будет забрать корень, обменяв его с последним элементов, а затем, уменьшив размер кучи на единицу, воспользоваться нисходящей процедурой построения кучи для корня: на место корня переместить вверх наибольшего из его потомков, затем переместить вверх наибольшего из потомков последнего и т.д.
Нисходящая процедура для k-го элемента кучи, состоящей из Count элементов, выглядит следующим образом:
Procedure downheap(k: integer);
Var i, j, t: integer;
Begin
T:=x[k];
While k<=Count div 2 do
Begin
J:=k+k;
If j<Count then if x[j] < x[j+1] then j:=j+1;
If t >= x[j] then break;
X[k]:= x[j]; k:=j;
End;
X[k]:=t;
End;
Применим нисходящую процедуру ко всем элементам, начиная с N div 2. А затем, получив кучу, заберем корень, обменяв его с последним элементом, и применим нисходящую процедуру к корню.
Например, для массива 5, 2, 8, 9, 3, 1, 7, 2 алгоритм будет выглядеть следующим образом:
Историки об Елизавете Петровне: Елизавета попала между двумя встречными культурными течениями, воспитывалась среди новых европейских веяний и преданий...






 Выберем элемент, которому не предшествует никакой другой – 7. Исключим его из множества. Выберем следующий элемент, которому не предшествует никакой другой – 9. И т.д.
Выберем элемент, которому не предшествует никакой другой – 7. Исключим его из множества. Выберем следующий элемент, которому не предшествует никакой другой – 9. И т.д.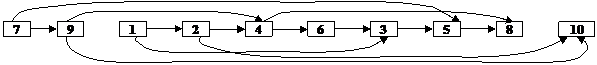
 Head
Head















 1
1