Если в программе есть участки, в которых присутствуют подвыражения, состоящие из констант, то эти подвыражения можно просчитать на этапе компиляции. Например, вполне возможно заранее вычислить правую часть выражения вида
A:= 1,5 * 2/3
III. Оптимизация булевых выражений
Метод основан на использовании свойств булевых выражений. Например, вместо
if (a and b and c) then <операторы> endif
надо сгенерировать команды таким образом, чтобы исключались лишние проверки. Суть метода состоит в том, что мы строим разветвление условия оператора if. Таким образом, вместо "if (a and b and c) then <операторы> endif" получим:
if not a then goto Label
if not b then goto Label
if not c then goto Label
<операторы>
Label: //метка перехода
Проблемы, связанные с использованием этого метода, заключаются в том, что, во-первых, могут проявиться побочные эффекты в тех случаях, когда аргументами являются функции, а во-вторых, "оптимизированный" код может получиться более громоздким по сравнению с оригиналом.
IV. Вынесение инвариантных вычислений за пределы цикла
Это – один из наиболее эффективных методов оптимизации, дающий весьма ощутимые результаты.
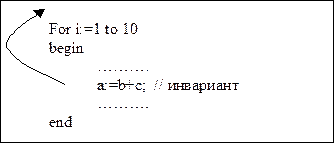
Для реализации метода необходимо:
(14) распознать инвариант;
(15) определить место переноса;
(16) перенести инвариант.
Неудобства метода:
(17) отследить инвариант нелегко, т.к. аргументы могут косвенно зависеть от переменной цикла;
(18) не учитываются побочные эффекты, если аргументы инварианта являются функциями (или зависимыми от них).
Проблемы, связанные с оптимизацией
Итак, очевидно, что необходимо сопоставлять ожидаемый выигрыш от повышения эффективности объектной программы с дополнительными накладными расходами, связанными с увеличением времени компиляции, надежности и сложности самого компилятора. Во-вторых, с оптимизаций зачастую связаны такие "неприятности", как даже ухудшение кода, сложность трассировки оптимизированных программ. Кроме того, бывает очень сложно выявить и/или устранить возникающие "побочные" эффекты.
Например, пусть мы работаем со стеком, используя функции push() для записи числа в стек и pop() для извлечения числа. Если нам надо извлечь пару чисел из стека и поместить обратно в стек их логическую сумму, то мы можем написать что-то вроде
A:= pop();
B:= pop();
C:= A || B;
Push(C);
Причем этот вариант является обычно более предпочтительным перед компактным вида
Push(pop() || pop()),
ибо скорее всего оптимизирующий компилятор превратит это выражение в Push(pop()), сочтя второй pop() лишним (он честно будет использовать логическую парадигму A || A º A). Это типичный пример побочных эффектов оптимизации.
Выводы
Необходимо сопоставлять затраты на оптимизацию с ожидаемым эффектом.
Оптимизация не всегда приводит к улучшению кода – могут появиться побочные эффекты. Либо после оптимизации получается более громоздкий код.
Чем больше вычислительной работы перекладывается на этап компиляции, тем эффективнее будет выполняться программа.
Более предпочтительной для МНЗО является внутренняя форма представления программы в виде тетрад.
Лучший прием оптимизации - писать хорошие программы.
ИНТЕРПРЕТАТОРЫ
По большому счету все то, что изучалось выше, предназначалось для того, чтобы дать необходимый теоретический базис и практические навыки и приемы, необходимые для построения интерпретатора - простейшего в ряду транслятор-компилятор-интерпретатор. Итак, мы уже знаем, что интерпретатор - это программа, которая
(19) транслирует исходную программу на языке высокого уровня во внутреннее представление;
(20) выполняет (интерпретирует) программу, представленную на этом внутреннем языке.
Интерпретатор прост. Его логическая структура напоминает урезанный компилятор. Интерпретаторы хороши для обучения (когда большая часть времени уходит на отладку) и для тех языков, в которых много времени уходит на работу системных программ (работа с матрицами, базами данных и т.п.).
Достоинства интерпретаторов
(21) простота (не надо реализовывать генерацию объектного кода);
(22) удобство и простота отладки программ - все внутренние структуры нам доступны (прежде всего – это доступ к таблице символов в любой момент времени), легки трассировка, отслеживание обращений к меткам и переменным (например, при установке флага проверки обращения в той же таблице символов) и т.п.;
(23) возможность включения интерпретируемых выражений в процессе выполнения программы (самомодификация программы).
Именно поэтому интерпретаторы наиболее часто применяются при разработке новых (не случайно сначала был создан именно интерпретатор языка С) и сложных языков – скажем, Пролог и Смолток в классическом варианте являются интерпретируемыми языками.
Недостатки интерпретаторов
Основным недостатком интерпретатора является малая, "по определению", скорость выполнения программы, т.к. при запуске нам необходимо выполнить все фазы анализа. Для устранения этого недостатка приходится платить упрощением синтаксиса языка, т.е. его грамматики. (Львиная доля времени работы интерпретатора приходится на анализ - лексический и синтаксический). В связи с этим наиболее простыми для реализации являются языки командного типа. В таких языках каждое предложение - это команда (императив) вида "<команда> [<аргументы>]".
Наиболее эффективной формой внутреннего представления программы для интерпретатора является польская форма записи. Тогда основной частью интерпретатора является переключатель CASE:
while TRUE do
begin
case gettype(P[n]) of
operand: Push(S,P[n]);
operator: arg1:= Pop(); arg2:= Pop(); Push(arg1 @ arg2);
else: error();
endcase
n:= n+1
end
Выше уже говорилось о том, что при реализации интерпретатора возникает проблема представления в стеке аргументов различных типов данных. На практике существуют 4 типа аргументов:
константы,
имена,
адреса переменных (адрес значения, номер элемента таблицы),
указатели (поле "Значение" содержит номер (адрес) элемента в таблице символов).
Зачастую между этими понятиями существует некоторая путаница. Обычно это касается понятий адреса и указателя. Для наглядности их можно изобразить на следующем рисунке:
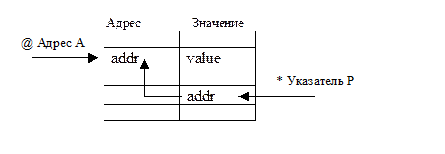
Существуют два основных способа хранения типа операнда (напомним, что в массиве польской формы записи операнды представляют собой положительные числа – адреса элементов в таблице имен). Во-первых, различать типы данных можно, используя аналогию с байт-кодом. Либо можно хранить аргумент, предваряя его элементом, указывающим тип (о теговом стеке говорилось выше). Во-вторых, тип элемента можно держать в таблице имен, и тогда в польской форме мы будем хранить лишь адреса. Если первый метод обеспечивает максимальное быстродействие (можно сразу определить тип аргумента, не обращаясь к таблице имен), то второй способ хранения более компактен. Как всегда, за все надо платить. Тем не менее, второй способ является более предпочтительным – он "красивее" и естественней.
Кроме того, очевидна необходимость наличия механизма проверки типов и соответствующих функций конвертирования. Вроде следующих:
cvPV (pointer to value) – конвертация указателя в значение;
cvPA (pointer to address) – конвертация указателя в адрес;
cvAV (address to value) – конвертация адреса в значение.
Для увеличения эффективности выполнения программы можно заранее вставлять в польскую форму записи процедуры конверсии типов (напомним основной принцип - не оставлять на время выполнения программы то, что можно сделать на этапе компиляции).
И последние замечания по поводу возможной реализации интерпретатора.
Трассировка. Можно легко и просто включить режим трассировки значений переменных. Например, установить флаг в таблице переменных и в соответствии с ним выводить значение переменной при обращении к ней по чтению и/или записи. Аналогично можно поступать и с метками, и с подпрограммами.
Для диагностики ошибок можно вставлять в польскую форму записи нумерацию строк исходной программы – некоторые фиктивные операторы, нужные только для отладки.
При реализации языка, в котором существуют подпрограммы, необходимо четко представлять себе механизм их вызова. Хороший сканер поместит в таблицу имен не только имя самой подпрограммы, но и ее тип, и количество и типы аргументов. Эта информация нужна будет для того, чтобы, выполняя оператор передачи управления $CALL, система взяла бы из стека необходимое количество операндов и могла бы поместить обратно значение, возвращаемое функцией. Кроме того, следует помнить и о локальных переменных, определенных внутри подпрограммы. Наиболее приемлемым способом избавиться от "засорения" таблицы имен локальными переменными является помещение их в стек. Тогда естественным образом будет решена и проблема их видимости.
Обычно интерпретатор – это самостоятельная программа, что зачастую создает некоторые проблемы, связанные с мобильностью программного обеспечения (в том смысле, что один исполняемый файл удобнее пары - исходный текст программы плюс интерпретатор). Однако существуют т.н. "скрытые" или "неявные" интерпретаторы. Реализация неявного интерпретатора заключается в том, что формируется исполняемый файл, содержащий в себе как непосредственно интерпретатор, так и исходный текст программы (почти в явном виде). Это приводит к тому, что внешне мы имеем исполняемый модуль, который, однако, занимается не чем иным, как интерпретацией со всеми вытекающими отсюда последствиями – достоинствами и недостатками. Типичным примером подобных систем является старая система программирования Clipper.
Пишутся интерпретаторы обычно на языках высокого уровня. И особенно полезными являются здесь принципы объектно-ориентированного программирования. Однако зачастую эффективнее бывает технология, при которой сначала создается макетный интерпретатор, реализованный, скажем, на Прологе. Макетный интерпретатор является полигоном для отладки структуры языка, он, естественно, прост, но малоэффективен с точки зрения скорости интерпретации. Однако для отладки структуры языка Пролог – незаменимое средство. Интерпретатор языка, среднего между Бейсиком и Паскалем, можно написать за 2-3 дня, и занимать он будет 400-500 строк (личный рекорд автора – это интерпретатор языка, в котором есть циклы, условные операторы, операторные скобки и полная арифметика с набором математических функций, который был написан за два вечера и занимал чуть более 400 строк). После отладки структуры языка можно браться за реализацию интерпретатора и на более эффективных с вычислительной точки зрения языках.
КОМПИЛЯТОРЫ КОМПИЛЯТОРОВ
Выше мы уже упоминали о компиляторах компиляторов (КК) – системах, позволяющих создавать компиляторы. На самом деле КК – это некий инструментарий программиста, помогающий создавать компиляторы (или интерпретаторы). Создавая множество компиляторов или постоянно модифицируя грамматику разрабатываемого языка (к сожалению, далеко не всегда можно заранее ясно определить структуру и синтаксис), разработчик, естественно, желает некоторым образом автоматизировать некие рутинные процедуры. Не случайно все рассмотренные нами методы анализа по возможности представлялись в формальном виде. Все они могли быть автоматизированы. Имея регулярную грамматику лексической структуры можно, автоматически сгенерировать сканер в виде конечного автомата. Имея грамматику синтаксической структуры, можно написать универсальную процедуру синтаксически управляемого перевода (или создать универсальный МП-автомат).
Следовательно, по крайней мере эти две наименее творческие и наиболее сложные и рутинные составляющие компилятора можно сгенерировать автоматически.
Для этого потребуется некоторое описание двух наших грамматик – грамматики для сканера и грамматики для реализации синтаксического анализатора. Это описание вполне можно хранить в некотором файле. И тогда мы получим своего рода специальный входной язык – язык описания компилятора.
Разумеется, получить на выходе готовый компилятор мы не сможем. В лучшем случае на выходе будут некоторые фрагменты компилятора:
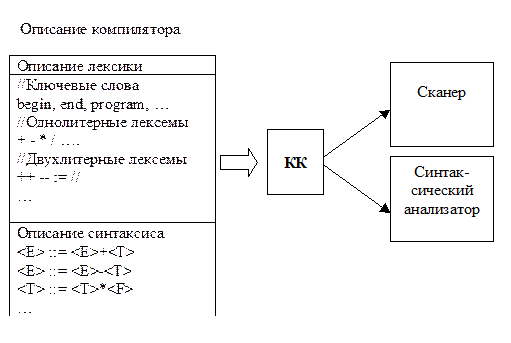
А дальше разработчику все равно необходимо будет самостоятельно добавлять семантические процедуры. С семантикой без него все равно ни один КК не справится. И еще пара замечаний.
Во-первых, при описании синтаксиса желательно правила грамматики записывать как можно в более естественной форме, при этом отделяя синтаксические категории от терминальных символов (скажем, заключая синтаксические категории в угловые скобки). С одной стороны, это сделает описание более удобочитаемым, а с другой – позволит КК легко разделять символы обоих словарей (терминального и нетерминального).
Во-вторых, нельзя забывать про наличие в схеме СУ-перевода (если КК реализует именно этот метод) еще двух составляющих – условия применимости правила грамматики и семантической процедуры. Все это тоже должно быть описано. Если описать семантическую процедуру достаточно просто, то с условием применения все гораздо сложнее. Ведь условие, в общем случае, может быть представлено произвольным логическим выражением. Дабы не заниматься его анализом с последующим вычислением, можно посоветовать сразу записывать это выражение в польской форме. Получится хоть не совсем красиво, зато удобно и очень просто.
И последнее. Познакомиться с описанием одного из наиболее почтенных КК можно в замечательной книге Кернигана и Пайка (см.библиографию). Описанный там КК YACC (Yet Another C Compiler – еще один компилятор С или Yet Another Compiler Compiler – еще один компилятор компиляторов) представляет весьма мощный инструмент, хотя использование его – занятие весьма утомительное. На самом же деле пользоваться надо своим собственным инструментарием. КК – это один из немногих продуктов, ценность которого определяется его "эксклюзивностью".
ПРИЛОЖЕНИЕ. ВВЕДЕНИЕ В ПРОЛОГ
Перед нами стоит одна из наиболее сложных задач изучаемого курса – познакомиться с совершенно новым и необычным языком программирования – языком Пролог. Этот язык интересует нас с точки зрения его применимости для построения важнейшей части любого компилятора – синтаксического анализатора. Как мы убедимся далее, Пролог для этой цели подходит более всех других языков.
Пролог – это достаточно "древний" язык. Он был создан в 1973 Алэном Колмеро во Франции, в Марсельском университете. Особенно популярен Пролог в Европе и в Японии. В 1981 г., анонсируя проект создания ЭВМ пятого поколения, японцы выбрали именно Пролог в качестве базового языка программирования. Пролог считается одним из языков искусственного интеллекта. Его название происходит от аббревиатуры PROgramming in LOGic (ПРОграммирование ЛОГики) – ПРОЛОГ. Действительно, основа языка Пролог - математическая логика. Пролог знаменует собой важный этап в эволюции языков программирования: движение от языков низкого уровня, пользуясь которыми программисты описывают, как что-либо следует делать (традиционные процедурно-ориентированные), к языкам высокого уровня, в которых указывается, что необходимо делать (декларативные языки).
Пролог - язык программирования, предназначенный для обработки символьной (нечисловой) информации. Особенно хорошо он приспособлен для решения задач, в которых фигурируют объекты и отношения между ними. Язык этот весьма прост. Его реализация содержит ограниченный набор механизмов: сопоставление образцов, древовидное представление структур данных и автоматический поиск с возвратом.
Классический Пролог относится к интерпретируемым языкам. Первый интерпретатор Пролога был написан на Фортране. Впоследствии было создано множество версий языка для разнообразнейших программно-аппаратных платформ, были даже созданы компиляторы Пролога, однако, несмотря даже на отсутствие стандартов Пролога (де факто таковым считается "марсельская" версия), его идеология, внутренние механизмы остаются неизменными.






