Параметры отражены в модели, как случайные переменные, параметризованная ценность для любой заданного состояния есть случайная переменная. Эта модель позволяет вычислять среднее значение и связанную неопределённость. Пусть ˆ Vθ будет аппроксимированная функция ценности, параметризованная случайным вектором θ со средним значением ¯θ и матрицей дисперсий Pθ. Пусть ¯ Vθ(s) и ˆσ2 Vθ(s) будут связанные среднее значение и дисперсия для данного состояния s.
Для распространения неопределенности (propagate the uncertainty[2]) от параметров к аппроксимации функции ценности первым шагом является вычисление сигма-точек, связанных с вектором параметров, то есть Θ={θ(j), 0≤ j≤2 p}, а также соответствующие веса, от ¯θ и Pθ, как описано ранее. Тогда образы этих sigma-points вычисляются с использованием параметризованной функции ценности:
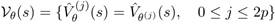
Зная эти образы и соответствующие веса, интересующая статистика вычисляется как:
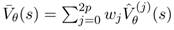
и
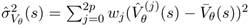
Это показано на рис.1. Расширение до Q-функции производится напрямую (straightforward). Таким образом, на каждом временном шаге информация о неопределенности может быть вычислена в структуре KTD.
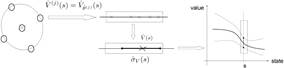

Рис.1. Вычисление неопределённости. Рис.2. Результаты задачи управления диалогом.
A Формирование Активного Обучения
Первооснова
Будет показано, как доступная информация о неопределённости может быть использована для активного обучения (active learning). Алгоритм KTD, полученный из уравнения оптимальности Беллмана, т.е. алг.1 с третьим уравнением (1) называется KTD- Q. Это алгоритм вне-политики (off-policy): он изучает оптимальную политику π ∗ в то время, как следует другой политике поведения b. Естественный вопрос: какую политику поведения выбрать, чтобы ускорить обучение? Пусть i – текущий временной индекс. Система в состоянии si, и агент должен выбрать действие ai. Предсказания ˆθ i| i−1 и Pi| i−1 доступны и могут быть использованы для аппроксимации неопределённости Q-функции, параметризованной θ i| i-1, в состоянии si и для любого действия a. Пусть ˆσ2 Qi| i-1(si, a) будет соответствующая дисперсия. Действие ai выбрано согласно следующей эвристике:
 (4)
(4)
Эта полностью исследовательская политика способствует неопределенным действиям. Соответствующий алгоритм, который называется активный - KTD- Q (алг.1 с 3-м уравнением (1) и политикой (4)).
Эксперимент
Вторым экспериментом является критерий (benchmark) удерживания перевёрнутого маятника (inverted pendulum). Эта задача требует поддержания маятника неизвестной длины и массы в вертикальном положении, прикладывая усилия к тележке, к которой он прикреплён. Полностью задача описана у Lagoudakis & Parr (2003) и мы используем ту же параметризацию (смесь гауссовых ядер – mixture of Gaussian kernels). Цель в том, чтобы сравнить 2 алгоритма ценностной-итерации (value- iteration- like), а именно KTD- Q и Q- learning, цель которых обучение непосредственно оптимальной политики из суб-оптимальных траекторий (обучение вне-политики – off- policy learning). Как мы знаем, KTD- Q – первый алгоритм второго порядка для аппроксимации Q-функции в схеме итерации ценностей, сложность состоит в обработке оператора max (Yu & Bertsekas (2007) предложили также такой алгоритм, однако для ограниченного класса MDP). Поэтому мы сравниваем данный алгоритм с алгоритмом первого порядка. Схема активного обучения также исследуется в экспериментах: используется неопределённость, вычисляемая KTD, чтобы ускорить сходимость.
Для Q- learning, скорость обучения установлена в  с α0=0.5 и n0=200,
с α0=0.5 и n0=200,
согласно Lagoudakis & Parr (2003).
Для KTD- Q, параметры устанавливаются в P0|0=10 I, Pni=1 и Pvi= 0 I.
Для обоих алгоритмов вектор начальных параметров установлены в ноль.
Учебные примеры сначала собираются в реальном времени (online) с политикой случайного поведения. Агент начинается в случайно возмущенном состоянии, близком к равновесию. Производительность измеряется как среднее количество шагов тестового эпизода (допустимо максимум 3000 шагов). Результаты усреднены за 100 испытаний.


Рис.3. Оптимальная политика обучения. Рис.4. Случайное и активное обучение.
На рис.3 сравниваются KTD- Q и Q- learning (одни и те же случайные выборки используются для обучения обоих алгоритмов). На рис.4 добавлен активный- KTD- Q, для которого выбираются действия в соответствии с (4).
Средняя продолжительность эпизодов с абсолютно случайной политикой составляет 10, тогда как для политики (4) оно равно 11. Следовательно, увеличение длины может лишь незначительно помочь улучшить скорость сходимости (не более 10%, что намного меньше, чем реальное улучшение, которое составляет около 100%, по крайней мере, в начале).
Согласно рис.3, KTD- Q изучает оптимальную политику (которая балансирует шест (pole) на максимальное число шагов) асимптотически, и почти оптимальные политики изучаются только после нескольких десятков эпизодов (обратите внимание, что эти результаты сопоставимы с алгоритмом LSPI). При одинаковом количестве эпизодов обучения Q- learning с той же самой линейной параметризацией не позволяет выучить политику, которая уравновешивает шест более чем на несколько десятков временных шагов. Аналогичные результаты для Q- learning получены Lagoudakis и Parr (2003). Согласно рис.4 ясно, что выборка действий в соответствии с неопределенностью ускоряет сходимость. Он почти удвоился на первых 100 эпизодах. Обратите внимание, что эту схему активного обучения нельзя было использовать для Q- learning с аппроксимацией функции ценности, т.к. этот алгоритм не может предоставить информацию о неопределенности.





