Аннотация
Выбор действия между исследованием и эксплуатацией (exploration and exploitation problem) является важной темой при обучении с подкреплением (RL). Наиболее успешные подходы к решению этой проблемы склонны использовать некоторую информацию о неопределенности значений, оценённых в процессе обучения. С другой стороны, масштабируемость, известная проблема алгоритмов RL, и аппроксимация функции ценности стали основными темами исследования. Обе проблемы возникают в реальных приложениях, однако немногие подходы позволяют аппроксимировать функцию ценности при сохранении информации о неопределенности оценок. Еще меньше используют эту информацию в целях решения дилеммы выбора действия исследования/эксплуатации. В этой статье мы покажем, как такая информация о неопределенности может быть получена из структуры Kalman- based Temporal Differences (KTD) (метод временных разностей, основанных на фильтре Калмана), и как она может использоваться.
Введение
Обучение с подкреплением (RL) (Саттон и Барто, 1996) является ответом известной задачи оптимального управления динамическими системами методами машинного обучения. В этой парадигме агент учится управлять своей средой (т.е. динамической системой) на примерах реальных взаимодействий. С каждым из этих взаимодействий связана немедленная награда, которая является локальной подсказкой (hint) о качестве текущей политики управления. Более формально, на каждом шаге дискретного времени i управляемая динамическая система находится в состоянии si. Агент выбирает действие ai, и динамическая система затем переводится в новое состояние, скажем, si+1, следуя своей собственной динамике. Агент получает награду ri, связанную с переходом (si, ai, si+1). Задача агента – максимизировать ожидаемое совокупное вознаграждение, которое он внутренне моделирует как так называемое функцию ценности или Q- функцию (см. далее). В наиболее сложных случаях обучение должно проводиться в режиме онлайн, и агент должен контролировать систему, пытаясь при этом выучить оптимальную политику. Основная проблема заключается в выборе политики поведения и связанной с этим дилеммы между исследованием и эксплуатацией (что может быть связано с активным обучением). Действительно, на каждом временном шаге агент может выбрать оптимальное действие в соответствии со своими (возможно) несовершенными знаниями об окружающей среде (эксплуатация) или действием, которое считается субоптимальным, чтобы улучшить свои знания (исследование) и впоследствии свою политику. Е - greedy (E-жадный) выбор действия является популярной политикой, которая состоит в выборе жадного действия с вероятностью 1- E и равномерно распределенного случайного действия с вероятностью E. Другой популярной политикой является выбор действия softmax (Sutton & Barto, 1996), извлекающий поведенческое действие из распределения Гиббса. Наиболее успешные подходы, как правило, используют информацию о неопределенности в выборе между исследованием и эксплуатацией, но также в проведении эксплуатации. Dearden и ко. (1998) поддерживают распределение добротности (Q- value distribution). Они предполагают 2 схемы. Первый состоит в выборке (sampling) действий согласно распределению добротности. Второй использует недальновидную ценность несовершенной информации (myopic value of imperfect information), которая аппроксимирует полезность действия по сбору информации с точки зрения ожидаемого улучшения качества решения. Strehl и Littman (2006) поддерживают доверительный интервал для каждого Q-значения, и жадную политику, соответствующую верхней границе этого интервала. Этот подход позволяет получить вероятностно приблизительно правильные (PAC) (probably- approximately- correct) границы. Sakaguchi и Takano (2004) используют политику Гиббса (Gibbs policy). Однако вместо более классического температурного параметра используется индекс надёжности (фактически форма неопределенности). Большинство из этих подходов предназначены для задач, где возможно табличное (точное) представление функции ценности. Тем не менее, аппроксимация ценности в случае больших пространств состояний является ещё одной важной темой в RL. Существуют некоторые алгоритмы, основанные на модели (model-based), которые решают эту проблему (Kakade et al., 2003; Jong & Stone, 2007; Li et al., 2009b). Они подразумевают аппроксимацию модели в дополнение к функции ценности. Однако здесь мы сфокусируемся на чисто безмодельных (model-free) подходах (оценивается только функция ценности). К сожалению, довольно немного аппроксиматоров функций ценности позволяют получить информацию о неопределенности оценённых значений. Engel (2005) предлагает такой алгоритм без модели, но фактическое использование неопределенности значений остаётся в качестве перспективы. В этой статье мы покажем, как некоторая информация о неопределенности оценённых значений может быть получена из структуры временных разностей, основанных на фильтре Калмана (KTD), представленном в Geist et al. (2009a,b). Мы также вводим форму активного обучения, которая использует эту информацию о неопределенности для ускорения обучения, а также некоторые адаптации существующих схем, разработанных для решения дилеммы исследования/эксплуатации. Примеры иллюстрируется, проводятся эксперименты, в том числе на проблеме реальной мира – задаче управления диалогом.
Предпосылка
Обучение с подкреплением
Эта статья основана на структуре процессе принятия решений Маркова (ППР) (MDP) (Markov decision process). MDP есть набор { S, A, P, R, γ}, где
S – пространство состояний,
A – пространство действий,
P: s, a ∈ S × A → p(.| s, a) ∈ P(S) – семейство вероятностей перехода,
R: S× A× S → R – ограниченная функция награды и
γ – дисконтирующий множитель.
Политика π ассоциирует каждое состояние с вероятностью действий,
π: s ∈ S → π(.| s) ∈ P(A)
Функция ценности данной политики определяется
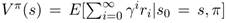
где ri – непосредственная награда, полученная путём наблюдения на каждом временном шаге i. Математическое ожидание E берётся по всем возможным траекториям, начинающимся с заданной динамики системы s, следуя политике π.
Q-функция допускает дополнительную степень свободы для первого действия и определяется

Цель RL в поиске (через итерации) политики π ∗, которая максимизирует функцию ценности на каждом состоянии:
π ∗ = argmaxπ(Vπ)
2 схемы среди остальных могут привести к оптимальной политике.
Первая схема – итерация политики, включает в себя обучение функции ценности данной политики и затем совершенствование политики, новая политика будет жадной относительно обученной функции ценности. Требуется решить уравнение оценки Беллмана, которое приведено здесь для функции ценности:
Vπ(s) = E s0,a|π,s [R(s,a,s0)+γVπ(s0)]
и Q-функций:
Qπ(s,a) = E s0,a0|π,s,a [R(s,a,s0)+γQπ(s0,a0)]
Вторая схема – итерация функции ценности, её целью является непосредственное нахождение оптимальной политики. Она требует решения уравнения оптимальности Беллмана:
Q ∗(s, a) = E s0| s, a [ R(s, a, s0) + γ max b ∈ A Q ∗(s0, b)]
Для больших пространств состояний и действий сложно получить явные решения, и требуется аппроксимация функций ценности или Q−функций.
Рис.1. Вычисление неопределённости. Рис.2. Результаты задачи управления диалогом.
Первооснова
Будет показано, как доступная информация о неопределённости может быть использована для активного обучения (active learning). Алгоритм KTD, полученный из уравнения оптимальности Беллмана, т.е. алг.1 с третьим уравнением (1) называется KTD- Q. Это алгоритм вне-политики (off-policy): он изучает оптимальную политику π ∗ в то время, как следует другой политике поведения b. Естественный вопрос: какую политику поведения выбрать, чтобы ускорить обучение? Пусть i – текущий временной индекс. Система в состоянии si, и агент должен выбрать действие ai. Предсказания ˆθ i| i−1 и Pi| i−1 доступны и могут быть использованы для аппроксимации неопределённости Q-функции, параметризованной θ i| i-1, в состоянии si и для любого действия a. Пусть ˆσ2 Qi| i-1(si, a) будет соответствующая дисперсия. Действие ai выбрано согласно следующей эвристике:
 (4)
(4)
Эта полностью исследовательская политика способствует неопределенным действиям. Соответствующий алгоритм, который называется активный - KTD- Q (алг.1 с 3-м уравнением (1) и политикой (4)).
Эксперимент
Вторым экспериментом является критерий (benchmark) удерживания перевёрнутого маятника (inverted pendulum). Эта задача требует поддержания маятника неизвестной длины и массы в вертикальном положении, прикладывая усилия к тележке, к которой он прикреплён. Полностью задача описана у Lagoudakis & Parr (2003) и мы используем ту же параметризацию (смесь гауссовых ядер – mixture of Gaussian kernels). Цель в том, чтобы сравнить 2 алгоритма ценностной-итерации (value- iteration- like), а именно KTD- Q и Q- learning, цель которых обучение непосредственно оптимальной политики из суб-оптимальных траекторий (обучение вне-политики – off- policy learning). Как мы знаем, KTD- Q – первый алгоритм второго порядка для аппроксимации Q-функции в схеме итерации ценностей, сложность состоит в обработке оператора max (Yu & Bertsekas (2007) предложили также такой алгоритм, однако для ограниченного класса MDP). Поэтому мы сравниваем данный алгоритм с алгоритмом первого порядка. Схема активного обучения также исследуется в экспериментах: используется неопределённость, вычисляемая KTD, чтобы ускорить сходимость.
Для Q- learning, скорость обучения установлена в  с α0=0.5 и n0=200,
с α0=0.5 и n0=200,
согласно Lagoudakis & Parr (2003).
Для KTD- Q, параметры устанавливаются в P0|0=10 I, Pni=1 и Pvi= 0 I.
Для обоих алгоритмов вектор начальных параметров установлены в ноль.
Учебные примеры сначала собираются в реальном времени (online) с политикой случайного поведения. Агент начинается в случайно возмущенном состоянии, близком к равновесию. Производительность измеряется как среднее количество шагов тестового эпизода (допустимо максимум 3000 шагов). Результаты усреднены за 100 испытаний.


Рис.3. Оптимальная политика обучения. Рис.4. Случайное и активное обучение.
На рис.3 сравниваются KTD- Q и Q- learning (одни и те же случайные выборки используются для обучения обоих алгоритмов). На рис.4 добавлен активный- KTD- Q, для которого выбираются действия в соответствии с (4).
Средняя продолжительность эпизодов с абсолютно случайной политикой составляет 10, тогда как для политики (4) оно равно 11. Следовательно, увеличение длины может лишь незначительно помочь улучшить скорость сходимости (не более 10%, что намного меньше, чем реальное улучшение, которое составляет около 100%, по крайней мере, в начале).
Согласно рис.3, KTD- Q изучает оптимальную политику (которая балансирует шест (pole) на максимальное число шагов) асимптотически, и почти оптимальные политики изучаются только после нескольких десятков эпизодов (обратите внимание, что эти результаты сопоставимы с алгоритмом LSPI). При одинаковом количестве эпизодов обучения Q- learning с той же самой линейной параметризацией не позволяет выучить политику, которая уравновешивает шест более чем на несколько десятков временных шагов. Аналогичные результаты для Q- learning получены Lagoudakis и Parr (2003). Согласно рис.4 ясно, что выборка действий в соответствии с неопределенностью ускоряет сходимость. Он почти удвоился на первых 100 эпизодах. Обратите внимание, что эту схему активного обучения нельзя было использовать для Q- learning с аппроксимацией функции ценности, т.к. этот алгоритм не может предоставить информацию о неопределенности.
Рис.5. Политики
E-жадная политика
Ипользуя E-жадную политику (Саттон и Барто, 1996), агент выбирает жадное действие, соответствующее оценённой Q-функции в текущий момент с
 (5)
(5)
Эта политика возможно наиболее простая и не использует никакую информацию о неопределённости. Произвольная Q-функция для данного состояния с 4мя разными действиями показаны на рис.6. Для каждого действия она даёт оценку Q-значения также, как политики, связанные с неопределённостью (т.е. ± оценённая стандартное отклонение (estimated standard deviation)). Например, действие 3 имеет наивысшую ценность и минимальную неопределённость, а действие 1 имеет наименьшую ценность и наибольшую неопределённость. Иллюстрация распределения вероятностей, ассоциированное с Е-жадной политикой, показана на рис.5. a. Наивысшая вероятность связана с действием 3, а остальные действия имеют одинаковую (низкую) вероятность, несмотря на их разные оценки ценности и стандартные отклонения.
Бонус-жадная политика
Третий подход вдохновлён методом Kolter and Ng (2009). Политика, которую они использовали является жадной относительно оценённой Q-функции плюс бонус, причём этот бонус пропорционален обратному числу посещений интересующей пары состояние-действие (которая может быть интерпретирована как дисперсия вместо квадратного корня этой величины для подходов, основанных на оценке интервалов, которые можно интерпретировать как стандартное отклонение).
Бонус-жадная политика использует дисперсию вместо стандартного отклонения и определятся, как (β0 и β являются двумя свободными параметрами):
 (7)
(7)
Бонус-жадная политика демонстрируется на рис.5 c, всё ещё используются произвольные Q-значения и соответствующие стандартные отклонения из рис.6. Действие 2 имеет наивысшую оценку, поэтому оно выбрано. Обратите внимание, что 3 других действия имеют примерно одинаковую оценку, несмотря на то, что они имеют совершенно разные Q-значения.
Политика Томпсона
Напомним, что алгоритм KTD поддерживает следующие параметры: вектор средних значений и матрица дисперсий. Предполагая, что распределение параметров является гауссовским, мы предлагаем выбрать набор параметров из этого распределения, а затем действовать жадно в соответствии с полученной выборочной (sampled) Q-функцией. Этот тип схемы впервые предложен у Thompson (1933) для задачи бандита, которая недавно была представлена сообществу обучения с подкреплением для случая табличного представления (Dearden et al., 1998; Strens, 2000). Пусть политика Томпсона является:
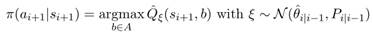 (8)
(8)
Политика демонстрируется на рис.5. d, показывая распределение жадного действия (напомним, что параметры случайные, и, следовательно, жадное действие тоже). Наибольшая вероятность связана с действием 3. Однако, обратите внимание, что вероятность, связанная с действием 1 больше, чем с действием 4: 1я имеет более низкое оценённое Q-значение, но она менее определена.


Рис.6. Q-значения и связанная неопределённость. Рис.7. Результаты задачи о бандите.
Эксперимент
Задача о многоруком бандите есть MDP с 1м состоянием и N действиями. Каждое действие a предполагает награду = 1 с вероятностью pa, и награду = 0 с вероятностью 1− pa. Для действия a ∗ (случайно выбранного в начале каждого эксперимента), вероятность установлена pa ∗=0.6. Для всех остальных действий, соответствующая вероятность случайно и равномерно выбирается между 0 и 0.5: pa ∼ U[0, 0.5], ∀ a≠ a ∗. Представлены результаты, усреднённые по 1000 экспериментам. Производительность метода измерена в процентах от времени, когда выбирается оптимальное действие, учитывая число взаимодействий между агентом и бандитом. Табличное представление адаптировано для KTD- SARSA, и следующие параметры были использованы[3]: N=10, P0|0=0.1 I, θ0|0= I, Pni=1, Е=0.1, α=0.3, β0=1 и β=10. Рассмотренный бандит имеет N=10 рук, случайная политика имеет производительность равную 0.1. Обратите внимание, чисто жадная политика будет систематически выбирать первое действие, в котором агент наблюдал награду.
Результаты, представленные на рис.7, сравнивают 4 схемы. Е-жадная политика служит базовым уровнем, и все предлагаемые схемы, использующие имеющуюся неопределенность, работают лучше. Политика Томпсона и доверительно-жадная политика работают примерно одинаково хорошо, а наилучшие результаты достигаются политикой бонус-жадности. Разумеется, эти довольно предварительные результаты не позволяют сделать вывод о гарантиях сходимости предложенных схем. Тем не менее, они, как правило, показывают, что вычисленная информация о неопределенности имеет смысл и может быть полезной для решения дилеммы исследования и эксплуатации.
Приложение управление диалогами
В этом разделе предложено приложение для задачи из реального мира: речевые диалоговые системы (spoken dialog system [4]) (SDS), направленные на предоставление информации пользователю посредством взаимодействия на естественном языке. SDS имеет примерно 3 модуля: компонент понимания речи (распознаватель речи и семантический анализатор), менеджер диалога и компонент генерации речи (генератор естественного языка и синтез речи). Управление диалогами – это задача последовательного принятия решений, при которой менеджер диалога должен выбрать, какую информацию следует запрашивать или предоставлять пользователю в данной ситуации. Таким образом, задача может быть преобразована в схему MDP (Levin et al., 2000; Singh et al., 1999; Pietquin and Dutoit, 2006). Набор действий, из которых менеджер диалогов может выбирать, определяется так называемыми диалоговыми действиями (dialog acts). Бывают разные диалоговые действия: приветствие пользователя, запрос части информации, предоставление части информации, запрос подтверждения части информации, завершение диалога и т.д. Состояние диалога обычно эффективно представляется парадигма Информационного Состояния (Larsson and Traum, 2000). В этой парадигме состояние диалога содержит компактное представление истории диалога в терминах диалоговых действий и ответов пользователя. Состояние обобщает информацию, которой обмениваются пользователь и система, пока не будет достигнуто рассматриваемое состояние. Следовательно, политика управления диалогом π является отображением между состояниями диалога и диалоговыми действиями. Согласно схеме MDP должна быть определена функция награды. Непосредственная награда обычно моделируется, как вклад каждого действия в удовлетворение пользователя (Singh et al., 1999). Это субъективная награда, которая обычно приближена линейной комбинацией объективных измерений.
Рассматриваемая система является речевой диалоговой системой с заполнением форм (form-filling). Она ориентирована на туристическую информацию, аналогично описанной Lemon et al. (2006). Её цель – предоставить информацию о ресторанах, основанную на специфичных предпочтениях пользователя. У данной задачи о диалоге 3 пункта, а именно расположение ресторана, тип кухни (cuisine) ресторана и его ценовой-диапазон. Учитывая прошлые взаимодействия с пользователем, агент спрашивает вопрос, чтобы предоставить лучший выбор, согласно предпочтениям пользователя. Цель предоставить корректную информацию пользователю за наименьшее число взаимодействий с ним, которое возможно.
Советующее состояние MDP имеет 3 непрерывные компоненты в диапазоне от 0 до 1, каждое из которых представляет усреднённую оценку достоверности заполненной и подтверждённой информации (представленные автоматической системой распознавания речи) в соответствующие места-пункты. Всего 13 возможных действий: попросить заполнить 1 пункт (3 действия), явное подтверждение 1 пункта формы (3 действия), неявное подтверждение 1 пункта формы и запрос на заполнение другого пункта (6 действий), наконец завершение диалога предложением ресторана (1 действие). Соответствующая награда всегда 0, кроме моментов, когда диалог завершён. В этом случае агент награждается 25 за 1 корректно заполненный пункт, -75 на 1 некорректно заполненный пункт формы, наконец -300 за 1 пустой пункт. Дисконтирующий множитель установлен γ=0.95. Хотя конечной целью является реализация RL в реальной задаче управления диалогом, в этом эксперименте для генерации данных использовалась техника имитации пользователя (Pietquin and Dutoit, 2006). Симулятор пользователя был подключен к системе управления диалогами (Lemon et al., 2006) для генерации примеров диалога. Q-функция представлена, как 1 RBF -нейросеть на 1 действие. Каждая RBF -нейросеть имеет 3 равномерно-распределённые (equispaced) функций Гаусса на 1 размерность, каждая со стандартным отклонением σ = 1/3 (переменные состояния в диапазоне от 0 до 1). Поэтому там 351 (т.е., 33×13) параметр.
KTD- SARSA с E-жадной и бонус-жадной политиками сравниваются на рис.2 (результаты усреднены на 8ми независимых попытках и каждая точка усреднена на 100 последних эпизодах: стабильная кривая означает нижнее стандартное отклонение). LSPI – это алгоритм вне-политики (off-policy) пакетного обучения методом приблизительной итерацией-политики (policy iteration) (Lagoudakis and Parr, 2003), служит базовым уровнем сравнения. Он был обучен вне-политики пакетным образом с использование случайных траекторий и предоставляет конкурентные результаты на текущее положение дел (Li et al., 2009a; Chandramohan et al., 2010). Оба алгоритма KTD представляют хорошие результаты (положительную совокупную награду, что значит, что пользователь в общем удовлетворяется после нескольких итераций). Однако, можно наблюдать, что бонус-жадная политика представляет более быструю сходимость, как и лучшую, и более стабильную политику, чем неинформированная Е-жадная политика. Более того, результаты для информированного KTD- SARSA очень близки к LSPI после немногих эпизодов обучения. Таким образом, KTD- SARSA является эффективным по выборке (sample efficient) (предоставляет хорошие политики, в то время, как неудовлетворительное число переходов препятствует использованию LSPI, из-за проблем с численной стабильностью), и предоставляет информацию о неопределённости, полезную для задачи управления диалогом.
Conclusion
В данной статьи мы показываем, как неопределённость информации о оценённых значения может быть извлечена из KTD. Мы имеем также представленную как активное обучение схему, нацеленную на улучшение скорости выбора движений согласно их относительной неопределённости, как адаптации существующих схем исследования/эксплуатации. 3 эксперимента предложены: первый показывает, что KTD- Q – алгоритм второго порядка итерации ценностей эффективен по образцам. Улучшения, полученные с использованием предложенной схемы активного обучения также демонстрированы. Над предложенными схемами исследования/эксплуатации были проведены успешные эксперименты на задаче бандита и задаче из реального мира с использованием политики бонус-жадной. Этот первый шаг в комбинировании дилеммы исследования и эксплуатации с аппроксимацией функции ценности.
Следующим шагом будет адаптация больше существующих подходов, работающих с дилеммой исследования/эксплуатации, разработанных для табличного представления функции ценности, к структуре KTD, а также предоставление некоторых теоретических гарантий для озвученных подходов. Эта статья сфокусирована на безмодельном обучении с подкреплением, мы планируем сравнить этот подход с RL, основанными на модели.
[1] https://habr.com/ru/post/121904/
https://ru.wikipedia.org/wiki/Фильтр_Калмана
http://ais.informatik.uni-freiburg.de/teaching/ws13/mapping/pdf/slam06-ukf-4.pdf
[2] https://en.wikipedia.org/wiki/Propagation_of_uncertainty
[3] Чтобы увидеть эмпирические данные о влиянии на производительность указанных политик, как функций от параметров, см Geist (2009).
[4] https://en.wikipedia.org/wiki/Spoken_dialog_systems
https://www.speech.kth.se/~gabriel/thesis/chapter2.pdf
Аннотация
Выбор действия между исследованием и эксплуатацией (exploration and exploitation problem) является важной темой при обучении с подкреплением (RL). Наиболее успешные подходы к решению этой проблемы склонны использовать некоторую информацию о неопределенности значений, оценённых в процессе обучения. С другой стороны, масштабируемость, известная проблема алгоритмов RL, и аппроксимация функции ценности стали основными темами исследования. Обе проблемы возникают в реальных приложениях, однако немногие подходы позволяют аппроксимировать функцию ценности при сохранении информации о неопределенности оценок. Еще меньше используют эту информацию в целях решения дилеммы выбора действия исследования/эксплуатации. В этой статье мы покажем, как такая информация о неопределенности может быть получена из структуры Kalman- based Temporal Differences (KTD) (метод временных разностей, основанных на фильтре Калмана), и как она может использоваться.
Введение
Обучение с подкреплением (RL) (Саттон и Барто, 1996) является ответом известной задачи оптимального управления динамическими системами методами машинного обучения. В этой парадигме агент учится управлять своей средой (т.е. динамической системой) на примерах реальных взаимодействий. С каждым из этих взаимодействий связана немедленная награда, которая является локальной подсказкой (hint) о качестве текущей политики управления. Более формально, на каждом шаге дискретного времени i управляемая динамическая система находится в состоянии si. Агент выбирает действие ai, и динамическая система затем переводится в новое состояние, скажем, si+1, следуя своей собственной динамике. Агент получает награду ri, связанную с переходом (si, ai, si+1). Задача агента – максимизировать ожидаемое совокупное вознаграждение, которое он внутренне моделирует как так называемое функцию ценности или Q- функцию (см. далее). В наиболее сложных случаях обучение должно проводиться в режиме онлайн, и агент должен контролировать систему, пытаясь при этом выучить оптимальную политику. Основная проблема заключается в выборе политики поведения и связанной с этим дилеммы между исследованием и эксплуатацией (что может быть связано с активным обучением). Действительно, на каждом временном шаге агент может выбрать оптимальное действие в соответствии со своими (возможно) несовершенными знаниями об окружающей среде (эксплуатация) или действием, которое считается субоптимальным, чтобы улучшить свои знания (исследование) и впоследствии свою политику. Е - greedy (E-жадный) выбор действия является популярной политикой, которая состоит в выборе жадного действия с вероятностью 1- E и равномерно распределенного случайного действия с вероятностью E. Другой популярной политикой является выбор действия softmax (Sutton & Barto, 1996), извлекающий поведенческое действие из распределения Гиббса. Наиболее успешные подходы, как правило, используют информацию о неопределенности в выборе между исследованием и эксплуатацией, но также в проведении эксплуатации. Dearden и ко. (1998) поддерживают распределение добротности (Q- value distribution). Они предполагают 2 схемы. Первый состоит в выборке (sampling) действий согласно распределению добротности. Второй использует недальновидную ценность несовершенной информации (myopic value of imperfect information), которая аппроксимирует полезность действия по сбору информации с точки зрения ожидаемого улучшения качества решения. Strehl и Littman (2006) поддерживают доверительный интервал для каждого Q-значения, и жадную политику, соответствующую верхней границе этого интервала. Этот подход позволяет получить вероятностно приблизительно правильные (PAC) (probably- approximately- correct) границы. Sakaguchi и Takano (2004) используют политику Гиббса (Gibbs policy). Однако вместо более классического температурного параметра используется индекс надёжности (фактически форма неопределенности). Большинство из этих подходов предназначены для задач, где возможно табличное (точное) представление функции ценности. Тем не менее, аппроксимация ценности в случае больших пространств состояний является ещё одной важной темой в RL. Существуют некоторые алгоритмы, основанные на модели (model-based), которые решают эту проблему (Kakade et al., 2003; Jong & Stone, 2007; Li et al., 2009b). Они подразумевают аппроксимацию модели в дополнение к функции ценности. Однако здесь мы сфокусируемся на чисто безмодельных (model-free) подходах (оценивается только функция ценности). К сожалению, довольно немного аппроксиматоров функций ценности позволяют получить информацию о неопределенности оценённых значений. Engel (2005) предлагает такой алгоритм без модели, но фактическое использование неопределенности значений остаётся в качестве перспективы. В этой статье мы покажем, как некоторая информация о неопределенности оценённых значений может быть получена из структуры временных разностей, основанных на фильтре Калмана (KTD), представленном в Geist et al. (2009a,b). Мы также вводим форму активного обучения, которая использует эту информацию о неопределенности для ускорения обучения, а также некоторые адаптации существующих схем, разработанных для решения дилеммы исследования/эксплуатации. Примеры иллюстрируется, проводятся эксперименты, в том числе на проблеме реальной мира – задаче управления диалогом.
Предпосылка
Обучение с подкреплением
Эта статья основана на структуре процессе принятия решений Маркова (ППР) (MDP) (Markov decision process). MDP есть набор { S, A, P, R, γ}, где
S – пространство состояний,
A – пространство действий,
P: s, a ∈ S × A → p(.| s, a) ∈ P(S) – семейство вероятностей перехода,
R: S× A× S → R – ограниченная функция награды и
γ – дисконтирующий множитель.
Политика π ассоциирует каждое состояние с вероятностью действий,
π: s ∈ S → π(.| s) ∈ P(A)
Функция ценности данной политики определяется
где ri – непосредственная награда, полученная путём наблюдения на каждом временном шаге i. Математическое ожидание E берётся по всем возможным траекториям, начинающимся с заданной динамики системы s, следуя политике π.
Q-функция допускает дополнительную степень свободы для первого действия и определяется
Цель RL в поиске (через итерации) политики π ∗, которая максимизирует функцию ценности на каждом состоянии:
π ∗ = argmaxπ(Vπ)
2 схемы среди остальных могут привести к оптимальной политике.
Первая схема – итерация политики, включает в себя обучение функции ценности данной политики и затем совершенствование политики, новая политика будет жадной относительно обученной функции ценности. Требуется решить уравнение оценки Беллмана, которое приведено здесь для функции ценности:
Vπ(s) = E s0,a|π,s [R(s,a,s0)+γVπ(s0)]
и Q-функций:
Qπ(s,a) = E s0,a0|π,s,a [R(s,a,s0)+γQπ(s0,a0)]
Вторая схема – итерация функции ценности, её целью является непосредственное нахождение оптимальной политики. Она требует решения уравнения оптимальности Беллмана:
Q ∗(s, a) = E s0| s, a [ R(s, a, s0) + γ max b ∈ A Q ∗(s0, b)]
Для больших пространств состояний и действий сложно получить явные решения, и требуется аппроксимация функций ценности или Q−функций.
Kalman Temporal Differences - KTD
Изначально парадигма фильтров Калмана (1960) была статистическим методом, целью которого – отслеживание в реальном времени (online tracking) скрытого состояния нестационарной динамической системы с помощью косвенных (indirect) наблюдений этого состояния.
Идея KTD лежит в преобразовании (cast) аппроксимации функции ценности в такой экземпляр фильтра: рассматривается аппроксиматор функции на основе семейства параметризованных функций, параметрами которых являются скрытые состояния, и их необходимо отслеживать, а наблюдение является наградой, связанной с параметрами через одно из классических уравнений Беллмана. Таким образом, преимуществом аппроксимации функции ценности фильтрами Калмана является частичное управление неопределенностью в следствие статистического моделирования.
Следующие обозначения приняты, учитывая, что целью являются оценки функции ценности и Q-функции или прямая оптимизация Q-функции:
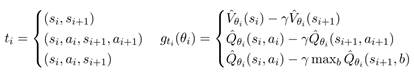 (1)
(1)
где ˆ Vθ (соотв. ˆ Qθ) есть параметрическое представление ценностной (соотв. Q-) функции, θ является вектором параметров. Принимается статистическая точка зрения, вектор параметров рассматривается как случайная величина. Задача сформулирована в так называемой формулировке пространства состояний:
 (2)
(2)
Используя терминологию фильтров Калмана, первое уравнение есть уравнение эволюции. Оно определяет, что искомый вектор параметров является следствием случайного блуждания (random walk), мат.ожидание которого соответствует оптимальной оценке функции ценности на шаге времени i. Эволюционный шум vi является центрированным, белым, независимым и ег






