Получение наиболее достоверного результата измерения и оценка его погрешности - основная цель обработки данных, полученных в ходе эксперимента. Выбор метода обработки зависит от числа экспериментальных данных (многократные, однократные измерения), вида измерений, вида распределения погрешностей измерений, требований к быстроте получения результатов, трудоемкости обработки.
Для оценки результата однократного измерения используют результаты специально поставленного эксперимента или данные предварительных исследований условий измерений, погрешности использованных средств и методов измерений, субъективных погрешностей.
При определении результата многократных измерений обычно используются различные вероятностные методы оценки. Наибольшее распространение нашли статистические методы обработки (при условии, что распределение полученного ряда экспериментальных данных не противоречит нормальному закону распределения).
В ряде случаев получить весь массив экспериментальных данных сразу невозможно, но их можно получить в разное время, т.е. выполнить измерения в различных условиях. Поэтому в результате получается несколько групп данных, которые требуют совместной обработки.
Немаловажное значение при обработке результатов имеют быстрота получения результата и трудоемкость метода обработки. Чаще всего в качестве результата используют среднее арифметическое значение, а в качестве характеристики его погрешности - среднее квадратическое отклонение.
Для того чтобы погрешности вычислений не могли исказить последнюю значащую цифру результата, при проведении обработки сохраняют необходимое число значащих цифр. Обычно при вычислениях удерживают на одну - две цифры больше, чем требуется в окончательном результате.
До начала обработки экспериментальные данные тщательно анализируются. Сначала выявляют отдельные результаты измерений, значения которых резко отличаются от остальных. Этот результат исключают из последующей обработки только в том случае, если имеется твердая уверенность, что допущено неверное действие экспериментатора. Во всех других случаях используются статистические методы определения наличия грубых погрешностей в серии измерений.
Существенное значение при выборе метода обработки имеет число измерений, особенно, если обработка выполняется вручную. Большое число измерений усложняет расчеты, создает дополнительные источники ошибок при вычислениях. Для упрощения расчетов в случаях большого числа измерений принято группировать данные (при n >50), т. е. проводится разделение ряда экспериментальных данных от наименьшего хтin до наибольшего хтax на k интервалов. Количество интервалов может быть следующее:
Количество измерений п Количество интервалов k
40-100 1-9
100-500 8-12
500-1000 10-16
1000-10000 12-22
Количество интервалов можно подсчитать также по формуле Старджесса
l=1+3,3lgn,
где п - число наблюдений (измерений).
Например, для n =100 получим l= 8.
Затем выбирают ширину интервала h, которая должна быть больше ошибок округления при вычислениях 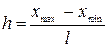 . Вычисленное значение ширины интервала округляют. Например, при xmin = 11, х max = 24, п = 100, h = (24-11)/8 = 1,63 ≈ 2.
. Вычисленное значение ширины интервала округляют. Например, при xmin = 11, х max = 24, п = 100, h = (24-11)/8 = 1,63 ≈ 2.
Установив границы интервалов, подсчитывают число результатов измерений ni, попавших и каждый интервал.
Для предварительной оценки вида распределения по полученным данным строят гистограмму распределения, представляющую собой ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат отрезки, изображающие интервалы ряда, а их высоты равны количеству данных ni, попавших в каждый интервал.
Иногда строят также полигон распределения для изображения дискретного статистического ряда, который представляет собой ломаную линию, показанную на рисунке 2.1.
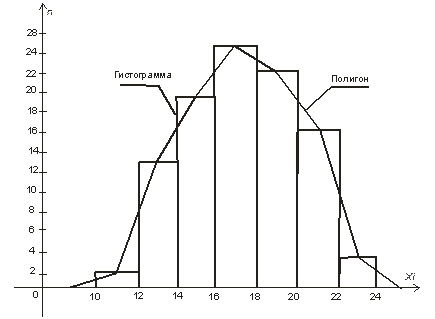 Рисунок 2.1
Рисунок 2.1
| |
Далее проводится проверка гипотезы о том, что распределение данных не противоречит теоретическому распределению, которая проводится по методике, описанной ниже.








