

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...
Топ:
Устройство и оснащение процедурного кабинета: Решающая роль в обеспечении правильного лечения пациентов отводится процедурной медсестре...
Теоретическая значимость работы: Описание теоретической значимости (ценности) результатов исследования должно присутствовать во введении...
Оценка эффективности инструментов коммуникационной политики: Внешние коммуникации - обмен информацией между организацией и её внешней средой...
Интересное:
Мероприятия для защиты от морозного пучения грунтов: Инженерная защита от морозного (криогенного) пучения грунтов необходима для легких малоэтажных зданий и других сооружений...
Как мы говорим и как мы слушаем: общение можно сравнить с огромным зонтиком, под которым скрыто все...
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
В общем плане под параллельными вычислениями понимаются процессы обработки данных, в которых одновременно могут выполняться несколько операций компьютерной системы. Классификация вычислительных систем.
Одним из наиболее распространенных способов классификации ЭВМ является систематика Флинна:
SISD (Single Instruction, Single Data) - системы, в которых существует одиночный поток команд и одиночный поток данных; к данному типу систем можно отнести обычные последовательные ЭВМ;
SIMD (Single Instruction, Multiple Data) - системы c одиночным потоком команд и множественным потоком данных; подобный класс систем составляют МВС, в которых в каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов;
MISD (Multiple Instruction, Single Data) - системы, в которых существует множественный поток команд и одиночный поток данных; примеров конкретных ЭВМ, соответствующих данному типу вычислительных систем, не существует; введение подобного класса предпринимается для полноты системы классификации;
MIMD (Multiple Instruction, Multiple Data) - системы c множественным потоком команд и множественным потоком данных; к подобному классу систем относится большинство параллельных многопроцессорных вычислительных систем.

Мультипроцессоры (системы с общей разделяемой памятью)

Рассмотрим способы построения общей памяти. Возможный подход – использование единой (централизованной) общей памяти (shared memory). Такой подход обеспечивает однородный доступ к памяти (uniform memory access or UMA) и служит основой для построения векторных параллельных процессоров (parallel vector processor or PVP) и симметричных мультипроцессоров (symmetric multiprocessor or SMP).
Одной из основных проблем, которые возникают при организации параллельных вычислений на такого типа системах, является доступ с разных процессоров к общим данным и обеспечение, в этой связи, однозначности (когерентности) содержимого разных кэшей (cache coherence problem). Дело в том, что при наличии общих данных копии значений одних и тех же переменных могут оказаться в кэшах разных процессоров. Если в такой ситуации (при наличии копий общих данных) один из процессоров выполнит изменение значения разделяемой переменной, то значения копий в кэшах других процессорах окажутся не соответствующими действительности и их использование приведет к некорректности вычислений. Обеспечение однозначности кэшей обычно реализуется на аппаратном уровне – для этого после изменения значения общей переменной все копии этой переменной в кэшах отмечаются как недействительные и последующий доступ к переменной потребует обязательного обращения к основной памяти. Следует отметить, что необходимость обеспечения когерентности приводит к некоторому снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров.
|
|
Наличие общих данных при выполнении параллельных вычислений приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так, например, если изменение общих данных требует для своего выполнения некоторой последовательности действий, то необходимо обеспечить взаимоисключение (mutual exclusion) с тем, чтобы эти изменения в любой момент времени мог выполнять только один командный поток. Задачи взаимоисключения и синхронизации относятся к числу классических проблем, и их рассмотрение при разработке параллельных программ является одним из основных вопросов параллельного программирования.
Общий доступ к данным может быть обеспечен и при физически распределенной памяти (при этом, естественно, длительность доступа уже не будет одинаковой для всех элементов памяти). Такой подход именуется как неоднородный доступ к памяти (non-uniform memory access or NUMA).
|
|
Среди систем с таким типом памяти выделяют:
− Системы, в которых для представления данных используется только локальная кэш-память имеющихся процессоров (cache-only memory architecture or COMA);
− Системы, в которых обеспечивается когерентность локальных кэшей разных процессоров (cache-coherent NUMA or CC-NUMA);
− Системы, в которых обеспечивается общий доступ к локальной памяти разных процессоров без поддержки на аппаратном уровне когерентности кэша (non-cache coherent NUMA or NCC-NUMA).
Использование распределенной общей памяти (distributed shared memory or DSM) упрощает проблемы создания мультипроцессоров (известны примеры систем с несколькими тысячами процессоров), однако, возникающие при этом проблемы эффективного использования распределенной памяти (время доступа к локальной и удаленной памяти может различаться на несколько порядков) приводят к существенному повышению сложности параллельного программирования.
Мультикомпьютеры.

Мультикомпьютеры (многопроцессорные системы с распределенной памятью) уже не обеспечивают общий доступ ко всей имеющейся в системах памяти (no-remote memory access or NORMA). При всей схожести подобной архитектуры с системами с распределенной общей памятью, мультикомпьютеры имеют принципиальное отличие – каждый процессор системы может использовать только свою локальную память, в то время как для доступа к данным, располагаемых на других процессорах, необходимо явно выполнить операции передачи сообщений (message passing operations). Данный подход используется при построении двух важных типов многопроцессорных вычислительных систем - массивно-параллельных систем (massively parallel processor or MPP) и кластеров (clusters).
Под кластером обычно понимается множество отдельных компьютеров, объединенных в сеть, для которых при помощи специальных аппаратно-программных средств обеспечивается возможность унифицированного управления (single system image), надежного функционирования (availability) и эффективного использования (performance). Кластеры могут быть образованы на базе уже существующих у потребителей отдельных компьютеров, либо же сконструированы из типовых компьютерных элементов, что обычно не требует значительных финансовых затрат. Применение кластеров может также в некоторой степени снизить проблемы, связанные с разработкой параллельных алгоритмов и программ, поскольку повышение вычислительной мощности отдельных процессоров позволяет строить кластеры из сравнительно небольшого количества (несколько десятков) отдельных компьютеров (lowly parallel processing). Это приводит к тому, что для параллельного выполнения в алгоритмах решения вычислительных задач достаточно выделять только крупные независимые части расчетов (coarse granularity), что, в свою очередь, снижает сложность построения параллельных методов вычислений и уменьшает потоки передаваемых данных между компьютерами кластера. Вместе с этим следует отметить, что организация взаимодействия вычислительных узлов кластера при помощи передачи сообщений обычно приводит к значительным временным задержкам, что накладывает дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ.
|
|
Топология сети передачи данных – это структура линий коммутации между процессорами вычислительной системы. К числу типовых топологий обычно относят следующие схемы коммуникации процессоров:
1. Полный граф. Система, в которой между любой парой процессоров существует прямая линия связи; как результат, данная топология обеспечивает минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессоров;
2. Линейка. Система, в которой все процессоры перенумерованы по порядку и каждый процессор, кроме первого и последнего, имеет линии связи только с двумя соседними (с предыдущим и последующим) процессорами. Такая схема является, с одной стороны, просто реализуемой, а с другой стороны, соответствует структуре передачи данных при решении многих вычислительных задач (например, при организации конвейерных вычислений);
3. Кольцо. Данная топология получается из линейки процессоров соединением первого и последнего процессоров линейки;
4. Звезда. Система, в которой все процессоры имеют линии связи с некоторым управляющим процессором; данная топология является эффективной, например, при организации централизованных схем параллельных вычислений;
5. Решетка. Система, в которой граф линий связи образует прямоугольную сетку (обычно двух - или трехмерную); подобная топология может быть достаточно просто реализована и, кроме того, может быть эффективно использована при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных);
|
|
6. Гиперкуб. Данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора (т.е. гиперкуб содержит  процессоров при размерности N). Данный вариант организации сети передачи данных достаточно широко распространен в практике.
процессоров при размерности N). Данный вариант организации сети передачи данных достаточно широко распространен в практике.
Основные характеристики топологий сети:
1. диаметр – показатель, определяемый как максимальное расстояние между двумя процессорами сети (под расстоянием обычно понимается величина кратчайшего пути между процессорами). Эта величина может характеризовать максимально необходимое время для передачи данных между процессорами, поскольку время передачи обычно прямо пропорционально длине пути;
2. связность (connectivity) – показатель, характеризующий наличие разных маршрутов передачи данных между процессорами сети. Конкретный вид данного показателя может быть определен, например, как минимальное количество дуг, которое надо удалить для разделения сети передачи данных на две несвязные области;
3. ширина бинарного деления (bisection width) – показатель, определяемый как минимальное количество дуг, которое надо удалить для разделения сети передачи данных на две несвязные области одинакового размера;
4. стоимость – показатель, который может быть определен, например, как общее количество линий передачи данных в многопроцессорной вычислительной системе.

Суперкомпьютеры.
Попытки дать определение термину суперкомпьютер, опираясь только на производительность, неизбежно приводят к необходимости постоянно поднимать планку, отделяющую его от рабочей станции или даже обычного настольного компьютера. Так по определению Оксфордского словаря вычислительной техники 1986 года, для того, чтобы получить это гордое название, нужно было иметь производительность в 10 MFlops (миллион операций над числами с плавающей точкой в секунду). Сегодня, как известно, производительность настольных систем на два порядка выше. Из альтернативных определений наиболее интересны два:
1. Суперкомпьютер – это система, цена которой выше 1-2 млн. долларов (Экономическое определение).
2. Суперкомпьютер – это компьютер, мощность которого всего на порядок меньше необходимой для решения современных задач (Философское определение).
Кластеры. Это группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС) и способных работать в качестве единого вычислительного ресурса. Предполагает более высокую надежность и эффективность, нежели ЛВС, и существенно более низкую стоимость в сравнении с другими типами параллельных вычислительных систем (за счет использования типовых аппаратных и программных решений).
|
|
Кластер Beowulf.
В настоящее время под кластером типа “Beowulf” понимается система, состоящая из одного серверного узла и одного или более клиентских узлов, соединенных при помощи Ethernet или некоторой другой сети. Это система, построенная из готовых серийно выпускающихся промышленных компонент, на которых может работать ОС Linux или ОС Windows, стандартных адаптеров Ethernet и коммутаторов. Процессоры узлов кластера слишком быстрым по сравнению с пропускной способностью обычной сети Ethernet, поэтому для балансировки системы переписали драйверы Ethernet под Linux для создания дублированных каналов и распределения сетевого трафика.
Она не содержит специфических аппаратных компонент и легко воспроизводима.
22) Общая характеристика MPI. Режимы передачи данных, коллективные операции.
Параллельное программирование для вычислительных систем с распределенной памятью использует MPI. Для организации параллельных вычислений в таких условиях необходимо иметь возможность
распределять вычислительную нагрузку и организовать передачу данных между процессорами.
MPI – это:
1. стандарт, которому должны удовлетворять средства организации передачи сообщений;
2. программные средства, которые обеспечивают возможность передачи сообщений и при этом соответствуют всем требованиям стандарта MPI.
Преимущества MPI:
• MPI позволяет в значительной степени снизить остроту проблемы переносимости параллельных программ между разными компьютерными системами – параллельная программа, разработанная на алгоритмическом языке C или Fortran с использованием библиотеки MPI, как правило, будет работать на разных вычислительных платформах,
• MPI содействует повышению эффективности параллельных вычислений, поскольку в настоящее время практически для каждого типа вычислительных систем существуют реализации библиотек MPI, в максимальной степени учитывающие возможности используемого компьютерного оборудования,
• MPI уменьшает, в определенном плане, сложность разработки параллельных программ, т.к., с одной стороны, большая часть основных операций передачи данных предусматривается стандартом MPI, а с другой стороны, уже имеется большое количество библиотек параллельных методов, созданных с использованием MPI.
Под параллельной программой в рамках MPI понимается множество одновременно выполняемых процессов. Процессы могут выполняться на разных процессорах, но на одном процессоре могут располагаться и несколько процессов (в этом случае их исполнение осуществляется в режиме разделения времени). В предельном случае для выполнения параллельной программы может использоваться один процессор - как правило, такой способ применяется для начальной проверки правильности параллельной программы.
Количество процессов и число используемых процессоров определяется в момент запуска параллельной программы средствами среды исполнения MPI-программ и в ходе вычислений меняться не может. Все процессы программы последовательно перенумерованы от 0 до p -1, где p есть общее количество процессов. Номер процесса именуется рангом процесса.
Понятие коммуникаторов.
Процессы параллельной программы объединяются в группы. Под коммуникатором в MPI понимается объект, объединяющий в своем составе группу процессов и ряд дополнительных параметров (контекст), используемых при выполнении операций передачи данных.
Как правило, парные операции передачи данных выполняются для процессов, принадлежащих одному и тому же коммуникатору. Коллективные операции применяются одновременно для всех процессов коммуникатора.
Типы данных
MPI содержит большой набор базовых типов данных, во многом совпадающих с типами данных в алгоритмических языках C и Fortran. Кроме того, в MPI имеются возможности для создания новых производных типов данных для более точного и краткого описания содержимого пересылаемых сообщений.
Виртуальные топологии
Логическая топология линий связи между процессами имеет структуру полного графа (независимо от наличия реальных физических каналов связи между процессорами).
Кроме того, в MPI имеются средства и для формирования логических (виртуальных) топологий любого требуемого типа.
Операции передачи данных. Среди предусмотренных в составе MPI функций различаются парные (point-to-point) операции между двумя процессами и коллективные (collective) коммуникационные действия для одновременного взаимодействия нескольких процессов.
Парные операции.
Для передачи сообщений процесс-отправитель должен выполнить функцию:
int MPI_Send(void *buf, int count, MPI_Datatype, int dest, int tag, MPI_Comm comm)
-buf – адрес буфера памяти, в котором располагаются данные отправляемого сообщения.
-count – количество элементов данных в сообщении.
-type – тип элементов данных пересылаемого сообщения.
-dest – ранг процесса, которому отправляется сообщение.
-tag - значение-тег, используемое для идентификации сообщений.
-comm - коммуникатор, в рамках которого выполняется передача данных.
Для приема сообщений процесс-получатель должен выполнить функцию:
int MPI_Recv(void *buf, int count, MPI_Datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
-buf – адрес буфера памяти, в котором располагаются данные принимаемого сообщения.
-count – количество элементов данных в сообщении.
-type – тип элементов данных принимаемого сообщения.
-source – ранг процесса, от которого должен быть выполнен прем сообщения.
-tag - значение-тег, используемое для идентификации сообщений.
-comm - коммуникатор, в рамках которого выполняется передача данных.
-status – указатель на структуру данных с информацией о результате выполнения операции приема данных.
Основные виды коллективных операций:
1. операции передачи от одного процесса всем процессам коммуникатора (широковещательная рассылка) - MPI_Bcast;
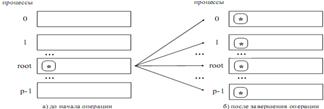
2. операции обработки данных, полученных на одном процессе от всех процессов (редукция данных) - MPI_Reduce;

3. Обобщенная операция передачи данных от одного процесса всем процессам (распределение данных) отличается от широковещательной рассылки тем, что процесс передает процессам различающиеся данные. Выполнение данной операции может быть обеспечено при помощи функции:
MPI_Scatter

4. Операция обобщенной передачи данных от всех процессоров одному процессу (сбор данных) является обратной к процедуре распределения данных. Для выполнения этой операции в MPI предназначена функция: MPI_Gather

Для выполнения парных операций могут использоваться разные режимы передачи, среди которых:
• Синхронный режим (MPI_Ssend) состоит в том, что завершение функции отправки сообщения происходит только при получении от процесса-получателя подтверждения о начале приема отправленного сообщения, отправленное сообщение или полностью принято процессом-получателем или находится в состоянии приема,
• Буферизованный режим (MPI_Bsend) предполагает использование дополнительных системных буферов для копирования в них отправляемых сообщений; как результат, функция отправки сообщения завершается сразу же после копирования сообщения в системный буфер,
• Режим передачи по готовности (MPI_Rsend) может быть использован только, если операция приема сообщения уже инициирована. Буфер сообщения после завершения функции отправки сообщения может быть повторно использован.
Все рассмотренные ранее функции отправки и приема сообщений являются блокирующими, т.е. приостанавливающими выполнение процессов до момента завершения работы вызванных функций. В то же время при выполнении параллельных вычислений часть сообщений может быть отправлена и принята заранее до момента реальной потребности в пересылаемых данных. В таких ситуациях было бы крайне желательным иметь возможность выполнения функций обмена данными без блокировки процессов для совмещения процессов передачи сообщений и вычислений. Наименование неблокирующих аналогов образуется из названий соответствующих функций путем добавления префикса I (Immediate).
Компьютерная графика:
|
|
|

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰)...

Историки об Елизавете Петровне: Елизавета попала между двумя встречными культурными течениями, воспитывалась среди новых европейских веяний и преданий...

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!