

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...
Топ:
Определение места расположения распределительного центра: Фирма реализует продукцию на рынках сбыта и имеет постоянных поставщиков в разных регионах. Увеличение объема продаж...
Характеристика АТП и сварочно-жестяницкого участка: Транспорт в настоящее время является одной из важнейших отраслей народного хозяйства...
Основы обеспечения единства измерений: Обеспечение единства измерений - деятельность метрологических служб, направленная на достижение...
Интересное:
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Аура как энергетическое поле: многослойную ауру человека можно представить себе подобным...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Алгоритмы поиска в STL
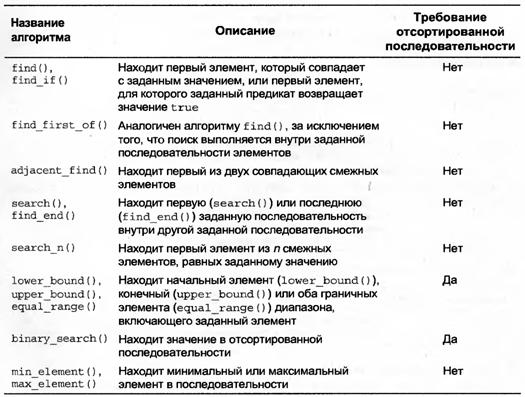
Алгоритмы сортировки


В каких контейнерах элементы хранятся упорядоченно?
Map, set
Кучав STL. Алгоритмы STL.
Куча STL
В контексте сортировки кучей (heap) называется бинарное дерево, реализованное в виде последовательной коллекции. Кучи обладают двумя важными свойствами:
· первый элемент всегда является максимальным;
· добавление и удаление элементов производится с логарифмической сложностью.
Куча является идеальной основой для реализации приоритетных очередей (очередей, которые автоматически сортируют свои элементы), поэтому алгоритмы, работающие с кучей, используются контейнером priority_queue. В STL определены четыре алгоритма для работы с кучами:
· make_heap(it first, it last) преобразует интервал элементов в кучу;
· push_heap(it first, it last) добавляетновыйэлементвкучу;
· pop_heap(it first, it last) удаляетэлементизкучи;
· sort_heap(…) преобразует кучу в упорядоченную коллекцию (после этого перестает быть кучей).
Как обычно, критерий сортировки может задаваться бинарным предикатом. По умолчанию сортировка осуществляется оператором <.
Алгоритмы STL
В библиотеке STL существует группа функций, выполняющих некоторые стандартные действия, например поиск, преобразование, сортировку, копирование и т. д. Они называются алгоритмами. Параметрами для алгоритмов, как правило, служат итераторы. Алгоритму нет никакого дела до типа переданного ему итератора. Главное, чтобы последний подпадал под определенную категорию. К примеру, если параметром алгоритма должен быть однонаправленный итератор, то подставляемый итератор должен быть либо однонаправленным, либо двунаправленным, или же итератором произвольного доступа.
|
|
1) equal(it1 first1, it1 last1, it2 first2) - сравнивает две цепочки данных, адресуемых входными итераторами
2) count (It beg, It end, const T& v) – подсчет элементов со значением равным v;
3) count_if (It beg, It end, UPredicate op) – подсчетэлементовдлякоторых op(el) == true;
4) lexicographical_compare (It1 beg1, It1 end1, It2 beg2, It2 end2) – лекс-граф. сравнение 2хпоследовательноcтей
5) find(Itbeg, Itend, constT&v) – поиск первого элемента со значением (Возвращает итератор, ссылающийся на найденный элемент, или итератор конца диапазона, если элемент не найден)
6) find_if(It beg, It end, UPredicate op) – поискпервогоэлементадлякоторогоунарнаяоперация op == true;
7) min_element (It beg, It end) – поиск минимального элемента последовательности;
8) min_element (It beg, It end, BPredicate op) – поиск минимального элемента для которых операция op == true;
9) copy (It sBeg, It sEnd, OIt dBeg) – копирование последовательности;
10) replace(FIt beg, FIt end, const T& v, const T& rv) – заменить в последовательности значения v на rv;
11) swap_ranges (FIt1 beg1, FIt1 end1, FIt2 beg2) – обменять соотв. элементы двух последовательностей.
12) accumulate(It beg, It end, BPredicate op) – суммирует элементы последовательности
Ассоциативный массив. Интерфейс, варианты реализации.
Ассоциативный массив (словарь) — абстрактный тип данных (интерфейс к хранилищу данных), позволяющий хранить пары вида «(ключ, значение)» и поддерживающий операции добавления пары, а также поиска и удаления пары по ключу.
Реализация:
Существует множество различных реализаций ассоциативного массива.
Самая простая реализация может быть основана на обычном массиве, элементами которого являются пары (ключ, значение). Для ускорения операции поиска можно упорядочить элементы этого массива по ключу и осуществлять нахождение методом бинарного поиска. Но это увеличит время выполнения операции добавления новой пары, так как необходимо будет «раздвигать» элементы массива, чтобы в образовавшуюся пустую ячейку поместить новую запись.
Наиболее популярны реализации, основанные на различных деревьях поиска. Так, например, в стандартной библиотеке STL языка С++ контейнер map реализован на основе красно-чёрного дерева.
|
|
У каждой реализации есть свои достоинства и недостатки. Важно, чтобы все три операции выполнялись как в среднем, так и в худшем случае за время  , где
, где  — текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено.
— текущее количество хранимых пар. Для сбалансированных деревьев поиска (в том числе для красно-чёрных деревьев) это условие выполнено.
В реализациях, основанных на хэш-таблицах, среднее время оценивается как 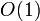 , что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как
, что лучше, чем в реализациях, основанных на деревьях поиска. Но при этом не гарантируется высокая скорость выполнения отдельной операции: время операции INSERT в худшем случае оценивается как  . Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.
. Операция INSERT выполняется долго, когда коэффициент заполнения становится высоким и необходимо перестроить индекс хэш-таблицы.
Хэш-таблицы плохи также тем, что на их основе нельзя реализовать быстро работающие дополнительные операции MIN, MAX и алгоритм обхода всех хранимых пар в порядке возрастания или убывания ключей.
Интерфейс:
template<Key, Value>
class IMap {
public:
virtual ~IMap() =0; //virtual destructor
virtual bool Insert(Key, Value) =0; //returns true if a new element was inserted or false if an element with the same key existed (new element wasn't inserted)
virtual bool Exist(Key) const =0; //returns true if element with specified key exists
virtual void Delete(Key) =0;
virtual void DeleteAll() =0;
virtual int Size() const =0; //returns number of elements.
virtual const Value* Find(Key) const =0; //returns 0 if there is no element with specified key in container or pointer to element otherwise
virtual Value* Find(Key) =0;
virtual const Value& operator[](Key) const =0; //returns reference to element that was in container in this moment or throw exception otherwise
virtual Value& operator[](Key) =0; //returns reference to element that was in container in this moment or newly created element with specified key otherwise
};
Хеш-табли́ца (unorderedmap) — это структура данных, реализующая интерфейс ассоциативного массива, а именно, она позволяет хранить пары (ключ, значение) и выполнять три операции: операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу.
Хеш-функцией называется односторонняя функция, предназначенная для получения дайджеста или "отпечатков пальцев" файла, сообщения или некоторого блока данных. По хеш-функции вычисляем значение, куда вставить/откуда удалить элемент из хеш-таблицы.
Хеш-таблица – вектор из пары ключ-значение, или из списков, или что-то еще
A=N/M – коэффициент заполнения. Где M – размер таблицы, а N – количество элементов в ней.
Если А>1 то одному значению из 0…M соответствует несколько ключей – коллизия (увеличиваем M вдвое и создаем новую хеш-таблицу. Минус – придется пересчитать все значения. Для этого существуют способы разрешения коллизий). Можно хранить в виде списков (Vector<list<par<Key,Value>>>)
|
|
Хеш-функция всегда дает один и тот же ответ!
Хеш-функция должна удовлетворять целому ряду условий:
· Хеш-функция должна быть чувствительна к всевозможным изменениям в тексте M, таким как вставки, выбросы, перестановки и т.п.;
· На одном входе один и тот же результат;
· Равномерное распределение по хеш-таблицу
· Хеш-функция должна обладать свойством необратимости, то есть задача подбора документа M', который обладал бы требуемым значением хеш-функции, должна быть вычислительно неразрешима;
· Вероятность того, что значения хеш-функций двух различных документов (вне зависимости от их длин) совпадут, должна быть ничтожно мала.
Существует множество алгоритмов хеширования с различными характеристиками (разрядность, вычислительная сложность, криптостойкость и т. п.).
Выбор той или иной хеш-функции определяется спецификой решаемой задачи.
Пример:
class CHash {
public:
int Max;
CHash(int _max = 10): Max(_max) {};
int Hash(int);
int Hash(double);
int Hash(CString);
};
int CHash::Hash(int n) {
returnn % (Max-1); // -1, т.к. если M – степень двойки, то будут одинаковые ключи
}
int CHash::Hash(double n) {
if(n < 1 && n > 0) return int(n * Max); else return int(n) % Max;
}
int CHash::Hash(CString str) {
int result = 0, i = 0;
int k = (str.Length() - 1) % Max;
while(i < k) {
result += (int)str[i];
i++;
}
return result % Max; // или например цикл от первой буквы до последней h=((a^h)*’V’)%M, где V –i-ая буква, h увеличиваем с 0 в каждой итерации на 1, а а – простое число. Тогда “abc” при a=256: ‘a’*256^2+’b’*256+’c’
}
Хорошо брать простоеM, ибо тогда уменьшаем вероятность одинаковых значений разных хеш-функций
Разрешение коллизий
Метод цепочек - Каждая ячейка массива H является указателем на связный список (цепочку) пар ключ-значение, соответствующих одному и тому же хеш-значению ключа. Коллизии просто приводят к тому, что появляются цепочки длиной более одного элемента.
Операции поиска или удаления элемента требуют просмотра всех элементов соответствующей ему цепочки, чтобы найти в ней элемент с заданным ключом.
|
|
Для добавления элемента нужно добавить элемент в конец или начало соответствующего списка, и, в случае, если коэффициент заполнения станет слишком велик, увеличить размер массива H и перестроить таблицу.
При предположении, что каждый элемент может попасть в любую позицию таблицы H с равной вероятностью и независимо от того, куда попал любой другой элемент, среднее время работы операции поиска элемента составляетΘ(1 + α), где α — коэффициент заполнения таблицы.
Открытая адресация (зондирование)
В массиве H хранятся сами пары ключ-значение. Алгоритм вставки элемента проверяет ячейки массива H в некотором порядке до тех пор, пока не будет найдена первая свободная ячейка, в которую и будет записан новый элемент. Этот порядок вычисляется на лету, что позволяет сэкономить на памяти для указателей, требующихся в хеш-таблицах с цепочками.
Последовательность, в которой просматриваются ячейки хеш-таблицы, называется последовательностью проб. В общем случае, она зависит только от ключа элемента, то есть это последовательность h 0(x), h 1(x), …, hn — 1(x), где x — ключ элемента, а hi (x) — произвольные функции, сопоставляющие каждому ключу ячейку в хеш-таблице.
Первый элемент в последовательности, как правило, равен значению некоторой хеш-функции от ключа, а остальные считаются от него одним из приведённых ниже способов.
Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы все ячейки хеш-таблицы оказались просмотренными ровно по одному разу.
Линейное зондирование - Алгоритм поиска просматривает ячейки хеш-таблицы в том же самом порядке, что и при вставке, до тех пор, пока не найдется либо элемент с искомым ключом, либо свободная ячейка (что означает отсутствие элемента в хеш-таблице).
Удаление элементов в такой схеме несколько затруднено. Обычно поступают так: заводят булевый флаг для каждой ячейки, помечающий, удален ли элемент в ней или нет. Тогда удаление элемента состоит в установке этого флага для соответствующей ячейки хеш-таблицы, но при этом необходимо модифицировать процедуру поиска существующего элемента так, чтобы она считала удалённые ячейки занятыми, а процедуру добавления — чтобы она их считала свободными и сбрасывала значение флага при добавлении.
Можно применить двойное зондирование– в первый раз считаем по h1(x), если коллизия, то по h2(x). Так мы избегаем многочисленных переходов на следующую пару, но проигрываем в памяти.
Универсальное хеширование – то же самое, но в каждой ячейке своя хеш-таблица со своей хеш-функцией.
Если хеш-таблица заполнена – удваиваем M и создаем новую.
|
|
Алгоритм кукушки
Основная идея заключается в использовании двух хэш-функции, а не только одной.Это дает два возможных места в хэш-таблице для каждого ключа. В одной из наиболее часто используемых вариантов алгоритма хэш-таблице делится на две меньшие таблицы одинакового размера, и каждая хэш-функция дает индекс в одном из этих двух таблиц.
Когда новый ключ вставлен, жадный алгоритм: новый ключ вставляется в один из двух возможных мест, "ногами из", то есть перемещение, любой ключ, который, возможно, уже находится в этом месте. Это перемещенный ключ вставляется в другое место, опять же ногой из любой клавиши, которые могут находиться там, пока вакантное место будет найдено, или процедура входит в бесконечный цикл. В последнем случае, хэш-таблицы восстановлен на месте, используя новые хэш-функции.
Опасность – можем зациклиться (если попали в ячейку, откуда началось), тогда меняем хеш-функции. Минус – увеличиваем память в 2 раза.
|
|
|

Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!