
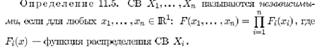
Основные числовые характеристики(мат ожид, дисперсия,корреляц матрица,коэф корреляц,нормированная корреляционная марица)
Математическим ожиданием (МО) случайного вектора X называется вектор
| M[ X ]
| Δ =
| mX
| Δ =
| col(m 1,..., mn), где
| mi
| Δ =
| M[ Xi ], i = 1, n.
|
Матрицу K размерности n x n с элементами
| kij
| Δ =
| M[(Xi - mi)(Xj - mj)]
|
называют ковариационной. Элементы kij ковариационной матрицы являются ковариациями СВ Xi и Xj при i ≠ j, а диагональные элементы kij - дисперсии СВ Xi, т.е.
| kij
| Δ =
| di
| Δ =
| (σi)2 = M[(Xi - mi)2], i = 1, n.
|
Дисперсии di, i = 1, n, характеризуют рассеивание реализаций компонент случайного вектора относительно средней точки mX = col(m 1,..., mn), а ковариации kij - степень линейной зависимости между СВ Xi и Xj. В частности, по свойству 2)kXY при линейной связи между Xi и Xj ковариация между ними равна kij = ±σiσj. Так как по свойству 1)kXY всегда | kXY | ≤ σiσj, то при линейной зависимости между Xi и Xj модуль | kij | максимален.
Нормированную ковариационную матрицу R, элементами которой являются коэффициенты корреляции rij, называют корреляционной матрицей
безразмерную величину 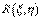 , определяемую соотношением.
, определяемую соотношением.
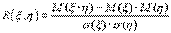
| (73)
|
и называемую коэффициентом корреляции.
16. основные задачи математической статистики. Занимается методами обработки опытных данных, полученных в рез-те наблюдения над случайными явлениями. Задачи мат стата:1)указать способы сбора и группировки стат. сведений, полученных в рез-те наблюдения за случ. процессами. 2)Разработка методов анализа стат. Данных в зависимости от цели исследования. Генеральная и выборочная совокупность. Ген совокупность-множество объектов, из которых производится выборка.Выборочная совокупность-сов-ть случайно отобранных объектов из генеральной совокупности. Повторная и бесповторная выборка.Повторная – при которой отобранный объект возвращается в ген совокупность. Бесповторная – при которой отобранный объект не возвращается в ген совокупность.Репрезентативность выборки.Выборка является репрезентативной, когда достаточно полно представлены изучаемые признаки генеральной совокупности.Условием обеспечения репрезентативности выборкия явл, соблюдение случайности отбора, т.е. все обекты ген выборки имеют равную возм попать в выборку. Теоретическая ФР. по определению, F(x)= mх/n, где n - объем выборки, mх - число выборочных значений величины X, меньших х. В отличие от выборочной функции F(x) интегральную функцию F(x) генеральной совокупности называют теоретической дикцией распределения. Главное различие функций F(x) и F(x) состоит в том, что теоретическая функция распределения F(x) определяет вероятность события Х<х, а выборочная функция - относительную частоту этого события. Статистическое распределение выборки. Распред в тоер вероят – соответствие м/у возможными значениями случ. вел-ны и их вероятностями. Распред в мат статист-соответствие м/у наблюдаемыми вариантами и их частотами.Перечень вариантов и соответствующих частот или частостей назыв статистическим распред выборки. Эмпирическая функция распределения называется функция 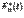 определяющая для каждого значения х частость события {X<x}:
определяющая для каждого значения х частость события {X<x}: 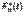 =p*{X<x}. Для нахожд значений эмпирической ф-ии удобно
=p*{X<x}. Для нахожд значений эмпирической ф-ии удобно 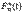 записать в виде
записать в виде 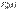 = Nx/n, n-объем выборки,Nx-число наблюдений, меньших х. Эмпирическая функция распределения
= Nx/n, n-объем выборки,Nx-число наблюдений, меньших х. Эмпирическая функция распределения 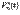 явл оценкой вероятности события {X<x},т.е. оценкой теоретической функции распределения F(x) с.в.Х Гистограмма, полигон относительных частот.Гистограммой частот называют ступнчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длины h, а высоты равны отношению Ni/h-Плотность частоты.)площадь гистограммы частот равна объему выборки, а площадь гистограммы частостей равна единице. Полигон относит частот- ломаная, отрезки которой соединяют точки(xi p* i;) Статистические оценки параметров распределения (выборочная средняя, групповая, общая среднее, выборочная дисперсия.) Выборочным средним ¯x в называется среднее арифметическое всех значений выборки: ¯x в= 1/n∑х i n i; Групповая средняя – ср. арифметическое значение признака,
явл оценкой вероятности события {X<x},т.е. оценкой теоретической функции распределения F(x) с.в.Х Гистограмма, полигон относительных частот.Гистограммой частот называют ступнчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длины h, а высоты равны отношению Ni/h-Плотность частоты.)площадь гистограммы частот равна объему выборки, а площадь гистограммы частостей равна единице. Полигон относит частот- ломаная, отрезки которой соединяют точки(xi p* i;) Статистические оценки параметров распределения (выборочная средняя, групповая, общая среднее, выборочная дисперсия.) Выборочным средним ¯x в называется среднее арифметическое всех значений выборки: ¯x в= 1/n∑х i n i; Групповая средняя – ср. арифметическое значение признака,
i=1
принадлежащее группе. Общая средняя – ср. арифметическое знач. признака, принадлежащее всей сов-ти. Выборочная дисперсия – ср. арифметическое квадратов отклонения наблюдаемых значений признака от их ср. значения. 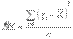 .Если данные наблюдений представлены в виде дискретного вариационного ряда, причем x1, x2, x3,..., xn - наблюдаемые варианты, a m1, m2, m3,..., mv - соответствующие им частоты, то выборочная дисперсия определяется формулой:
.Если данные наблюдений представлены в виде дискретного вариационного ряда, причем x1, x2, x3,..., xn - наблюдаемые варианты, a m1, m2, m3,..., mv - соответствующие им частоты, то выборочная дисперсия определяется формулой: 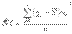
Формула для вычисления дисперсии. D в =х¯2-[х¯]2 (ср.арифметический квадрат значений выборки-квадрат общей средней) Док-во:
17. Основные распределения в математической статистике Распределение хи-квадратПусть Uk, k = 1, n, - набор из n независимых нормально распределенных СВ, Uk ~ N (0,1). Тогда СВ
имеет распределение хи-квадрат (χ2-распределение) с n степенями свободы, что обозначается X ~ X2 (n). СВ X имеет следующую плотность распределения:
| fX (x)=
| {
|
2(n /2)Γ(n /2) 0
| x (n /2)-1 e-x /2
| , ,
| x ≥ 0, x < 0,
|
где
| Γ(m)
| Δ =
| +∞ ∫ 0
| ym -1 e-y d y - гамма-функция.
|
Графики функции fX (x) (см. рис. 1), называемые кривыми Пирсона, асимметричны и, начиная с n ≥ 2, имеют один максимум в точке x = n - 2.
 Характеристическая функция СВ X имеет вид:
Характеристическая функция СВ X имеет вид:
| gX (t) =
| +∞ ∫ -∞
| f X (x) eitx d x = (1 - 2 ti)- n /2.
|
Начальные моменты СВ X находятся по свойству 3)gX(t):
| ν 1 =
|
i
| d
d t
| g (t)
| |
| t =0
| = -
| n
2 i
| (-2 i)(1 - 2 ti)-(n /2)-1
| |
| t =0
| = n,
|
| ν 2 =
| 1
i 2
| d2
d t 2
| g (t)
| |
| t =0
| =
| n
i
| (-2 i)(-
| n
| - 1)(1 - 2 ti)-(n /2)-2
| |
| t =0
| = n 2+2 n,
|
| D[ X ] = ν 2 - ν 12 = n 2 + 2 n - n 2 = 2 n.
|
Сумма любого числа m независимых СВ Xk, k = 1, m, имеющих распределение хи-квадрат с nk степенями свободы также имеет распределение хи-квадрат с
степенями свободы. Это можно доказать, используя свойства характеристической функции.
Распределение Стьюдента Пусть U и X - независимые СВ, U ~ N (0,1), X ~ X2 (n). Тогда СВ
имеет распределение Стьюдента с n степенями свободы, что обозначают как T ~ S (n). СВ T имеет плотность распределения
| fT (x) =
| Γ((n +1)/2)
√ nπ Γ(n /2)
| (1+
| x 2
n
| )-(n +1)/2.
|
1 Графики функции fT (x) (рис. 2), называемые кривыми Стьюдента, симметричны при всех n = 1,2,... относительно оси ординат.

Рисунок 2.
2Можно показать, что при n → ∞ плотность вероятности распределения СВ T ~ S (n) сходится к плотности вероятности стандартного нормального распределения N (0,1), т.е.
| fT (x) →
|
√2 π
| exp(- x 2 / 2), n → ∞.
|
Действительно, пусть n = 2 m. Тогда
| (1+
| x 2
n
| )-(n +1)/2 = (1 +
| x 2
2 m
| )- m -(1/2).
|
Если n → ∞ и m → ∞, то согласно известному замечательному пределу получим
| (1+
| x 2
2 m
| )-1/2 (1+
| x 2
2 m
| )- m → exp{- x 2/2}.
|
Таким образом,
| fT (x) → k exp{- x 2/2} при n → ∞.
|
Так как fT (x) удовлетворяет условию нормировки, то и предельная функция должна удовлетворять условию нормировки, т.е. являться плотностью. Поэтому из условия нормировки плотности получаем
| Γ((n +1)/2)
√ nπ Γ(n /2)
| → k =
|
√2 π
| при n → ∞.
|
При n > 30 распределение Стьюдента практически не отличается от N (0,1). Однако при n ≤ 30 отличия существенны.
Замечание 3. При n = 1 распределение Стьюдента S (1) совпадает с распределением Коши, плотность которого равна
т.к. при n = 1 имеем Γ(1/2) = 1 / √ π, Γ(1) = 1. Особенность распределения Коши состоит в том, что у него нет ни одного начального момента νr, r ≥ 1, так как расходятся несобственные интегралы
| νr
| Δ =
| 1
π
| ∞ ∫ -∞
| xr
x 2+1
| d x.
|
Любопытно, если попробовать вычислить МО M [ T ] СВ T, имеющей распределение Коши, как предел значений определенного интеграла на отрезке [- a, a ], то можно получить неверный ответ:
| l i m n →∞
|
π
| a ∫ - a
| x
x 2+1
| d x = 0.
|
Распределение Фишера Пусть независимые СВ Xn и Xm имеют распределения хи-квадрат с n и m степенями свободы соответственно. Тогда СВ
имеет распределение Фишера с n и m степенями свободы, что записывают как X ~ F (n, m). 1 СВ X имеет плотность fX (x) = 0 при x < 0 и
| fX (x) =
| Γ((n+m)/2)
Γ(n /2)Γ(m /2)
| nn /2 mm /2
| x (n /2)-1
(m+nx)(n+m)/2
| , x ≥ 0.
|
Графики функции fX (x) (см. рис. 3), называемые кривыми Фишера, асимметричны и достигают максимальных значений в окрестности точки
близкой к единице.

2 Распределение Фишера используют, например, при сравнении выборочных дисперсий для нормальных СВ. В частности, распределение F (n, m) имеет следующая СВ:
| X
| Δ =
| [
| 1
n
| n +1 ∑ k =1
| (Xk -
| ^ MX
| )2] / [
| 1
m
| m +1 ∑ k =1
| (Yk -
| ^ MY
| )2],
|
где СВ X 1,..., Xn +1, Y 1,..., Ym +1 - независимы и имеют нормальное распределение: Xi ~ N (mX, σ), Yi ~ N (mY, σ).
18 Статистические оценки Точечные
Пусть выборка
соответствует функции распределения
зависящей от неизвестного параметра θ. Точечной (выборочной) оценкой неизвестного параметра θ называется функция
случайной выборки Zn, реализация
которой принимается за приближенное значение θ.
2 Оценка
параметра θ называется несмещенной, если ее МО при любом n равно θ, т.е.
3 Оценка
называется состоятельной, если она сходится по вероятности к θ, т.е.
| ^ θ (Zn)
| P →
| θ при n → ∞.
|
Свойствами состоятельности и несмещенности могут обладать сразу несколько оценок неизвестного параметра θ.
Несмещенная оценка
параметра θ называется эффективной, если
| D[
| ^ θ
| *(Zn)] ≤ D[
| ^ θ
| (Zn)]
|
для всех несмещенных оценок
т.е. ее дисперсия минимальна по сравнению с дисперсиями других несмещенных оценок при одном и том же объеме n выборки Zn.
Замечание 2. Пусть СВ X имеет нормальное распределение N (mX, σX) с неизвестными параметрами
В этом случае выборочное среднее является эффективной оценкой МО.
| zn
| Δ =
| col(x 1, x 2,..., xn):
|
2. Метод максимального правдоподобия На практике часто удается предсказать вид плотности распределения fX (x, θ 1,..., θs) непрерывной СВ X с точностью до неизвестных параметров θ 1,..., θs (например θ 1 = mX, θ 2 = dX при s = 2), которые требуется оценить по выборке Zn. Рассмотрим выборку Zn, соответствующую плотности fX (x, θ 1,..., θs) СВ X. Функцией правдоподобия называется плотность распределения n-мерной СВ Zn с реализацией
| L (zn, θ 1,..., θs)
| Δ =
| fZ
| n
| (zn, θ 1,..., θs)
| Л13.Р1.О1 =
| n ∏ k =1
| fX (xk, θ 1,..., θs).
|
Оценкой максимального правдоподобия (ММП-оценкой), найденной по методу максимального правдоподобия, называется оценка
максимизирующая для каждой реализации zn функцию правдоподобия:
| ^ θ (Zn) = arg
| max θ
| L (zn, θ), θ
| Δ =
| col(θ 1,..., θs).
|
Аналогично определяется ММП-оценка θ при неоднородной выборке
когда СВ Xk, к = 1, n, по-прежнему независимы, но имеют различные плотности распределения fXk (xk, θ 1,..., θs), зависящие от одного и того же набора неизвестных параметров θ 1,..., θs.
3. Метод наименьших квадратовРассмотрим линейную регрессионную модель из предыдущего раздела, не предполагая, что ошибки Wk имеют нормальное распределение, и, кроме того, считая, что коэффициенты Xk случайны:
k = 1, n. Пусть M [ Wk ] = 0, D [ Wk ] = σ 2 и неизвестна, СВ Wk, k = 1, n, независимы. Предположим, что СВ Xk и Wk, k = 1, n, независимы, причем Xk имеют одно и то же, но неизвестное распределение FX (x). По результатам наблюдений (y 1, x 1),...,(yn, xn) требуется оценить неизвестные параметры a и b в линейной регрессионной модели. Для неоднородной выборки
| zn
| Δ =
| col(y 1,..., yn, x 1,..., xn)
|
рассмотрим квадратическую функцию:
| Q (zn, a, b) =
|
n
| n ∑ k =1
| (yk - axk - b)2,
|
характеризующую среднюю по n квадратическую ошибку предсказания того, что в n наблюдениях СВ Y примет значения yk, k = 1, n.
МНК-оценками, полученными по методу наименьших квадратов неизвестных параметров a и b в линейной регрессионной модели
k = 1, n, называются оценки
значения которых минимизируют квадратическую функцию Q (zn, a, b), построенную по апостериорной выборке zn.
случае видно, что функция Q (zn, a, b) совпадает по форме с точностью до коэффициентов с логарифмической функцией правдоподобия из примера Л15.Р2.П1:
| Q (zn, a, b) = -2 σ 2
| ~ L (zn, a, b) -2 σ 2 n ln(σ √2 π).
|
Поэтому минимум функции Q (zn, a, b) по параметрам a и b достигается при тех же значениях
что и в методе максимального правдоподобия (минимизация функции Q (zn, a, b) по a и b эквивалентна максимизации функции
Найденные по методу наименьших квадратов оценки
неизвестных параметров a и b имеют место для произвольных случайных ошибок Wk и случайных коэффициентов Xk, тогда как по методу максимального правдоподобия эти же оценки получены в предположении о нормальности Wk и для детерминированных значений xk, k =1, n. Иными словами, МНК-оценки оказываются более робастными (т.е. менее чувствительными к априорной информации о случайных коэффициентах Xk и ошибках Wk) по сравнению с ММП-оценками.
19 Статистическая проверка гипотез Статистическими гипотезами называются любые предположения относительно закона распределения СВ X, проверяемые по выборке Zn. По выборке Zn требуется проверить гипотезу H 0 о том, что mX = m, где m - некоторое фиксированное число. Статистикой называется произвольная функция Z = φ (Zn) выборки Zn, для значений которой известны условные плотности распределения f (z | H 0) и f (z | H 1) относительно проверяемой гипотезы H 0 и конкурирующей с ней альтернативной гипотезы H 1.Из опред следует, что Z есть СВ. Практическое применение математической статистики состоит в проверке соответствия результатов экспериментов предполагаемой гипотезе. С этой целью строится процедура (правило) проверки гипотезы. Критерием согласия называется правило, в соответствии с которым по реализации
статистики Z, вычисленной на основании апостериорной выборки zn, гипотеза H 0 принимается или отвергается. Критической областью G называется область реализаций z статистики Z, при которых гипотеза H 0 отвергается. Доверительной областью G называется область значений z статистики Z, при которых гипотеза H 0 принимается. Уровнем значимости p критерия согласия называется вероятность события, стоящего в том, что гипотеза H 0 отвергается, когда она верна, т.е.
где вероятность P соответствует условной плотности распределения f (z | H 0). Мощностью γ критерия согласия называется вероятность события, состоящего в том, что гипотеза H 0 отвергается, когда она неверна, т.е.
где вероятность P соответствует условной плотности f (z | H 1). Критической точкой zβ называется точка на оси Oz, являющаяся квантилью уровня
распределения F (z | H 0), соответствующего плотности распределения f (z | H 0). На рис.1 показана графическая интерпретация введенных понятий, где β + p = 1, δ + γ = 1.
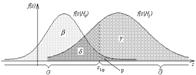
В качестве критерия согласия примем правило:
1) если значение
статистики Z = φ (Zn) лежит в критической области G, то гипотеза H 0 отвергается и принимается альтернативная гипотеза H 1; 2) если реализация
статистики Z = φ (Zn) лежит в доверительной области G, то гипотеза H 0 принимается.
При реализации данного правила могут возникнуть ошибки двух видов. Ошибкой 1-го рода называется событие, состоящее в том, что гипотеза H 0 отвергается, когда она верна. Вероятность этой ошибки равна
Ошибкой 2-го рода называется событие, состоящее в том, что гипотеза H 0 принимается, когда она неверна. Вероятность этой ошибки равна
| δ
| Δ =
| P{ Z G | H 1} = 1 - γ.
|
Из рисунка видно, что с уменьшением вероятности p ошибки 1-го рода возрастает вероятность ошибки 2-го рода и наоборот, т.е. при выборе критической и доверительной областей должен достигаться определенный компромисс.
Проверка гипотезы о значении параметров нормального распределения Замечание 1. Пусть известно, что СВ X имеет нормальное распределение. Требуется проверить гипотезу H 0, состоящую в том, что mX = m (m - некоторое фиксированное число), используя апостериорную выборку zn. Возможны два случая: дисперсия (σX)2 известна или неизвестна.
| Предполо- жение
| Статистика Z критерия согласия
| Распре- деление
| Доверительная область G принятия гипотезы Н 0
|
| σX известно
| ^ (MX - m)√ n
σX
| N(0,1)
| [- uα, uα ]
|
| σX неизвестно
| ^ (MX - m)√ n -1
^ √ DX
| S(n -1)
| [- tα (n - 1), tα (n - 1)]
|
Для каждого случая в соответствии с примерами Л15.Р4.П1 и Л15.Р4.П2 получаем свой критерий согласия. (ниже uα, tα (n - 1) - квантили уровня
распределений N (0,1) и S (n -1) соответственно). Пусть СВ X нормально распределена, но ее дисперсия неизвестна. Требуется проверить гипотезу H 0, что σX = σ (σ - некоторое фиксированное число), на основе апостериорной выборки zn. Возможны два случая: mX - известно или mX - неизвестно (ниже χα (k), χ 1- α (k) - квантили уровня α и 1- α распределения Χ2 (k) с k степенями свободы,
| α
| Δ =
| 1 - p / 2 для k = n, n -1):
|
| Предпо- ложение
| Статистика Z критерия согласия
| Распре- деление
| Доверительная область G принятия гипотезы Н 0
|
| mX известно
| n ∑(Xk - mX)2 k =1
σ2
| Χ2(n)
| [- χ 1- α (n), χα (n)]
|
| mX неизвестно
| ^ nDX
σ 2
| Χ2(n-1)
| [- χ 1- α (n -1), χα (n -1)]
|
На практике обычно задают p [0.01, 0.05].
Проверка гипотезы о законе распределения случайной величины Замечание 1. Пусть имеется апостериорная выборка zn и требуется проверить гипотезу H 0, состоящую в том, что непрерывная СВ X имеет определенный закон распределения f (x) (например, нормальный, равномерный и т.д.). Истинный закон распределения f (x) неизвестен. Для проверки такой гипотезы обычно используют критерий согласия хи-квадрат (критерий Пирсона). Правило проверки состоит в следующем:
1. Формулируется гипотеза H0, состоящая в том, что СВ X имеет плотность распределения определенного вида f (x, θ 1,..., θs) с s неизвестными параметрами θ 1,..., θs (например, m и σ для нормального распределения, a и b - для равномерного и т.д.)
2. По апостериорной выборке zn методом максимального правдоподобия (или методом наименьших квадратов) находятся оценки
неизвестных параметров θ 1,..., θs
3. Действительная ось R 1 разбивается на j + 1 непересекающихся полуинтервалов Δ0,..., Δ j так, как это сделано в Л13.Р2.31 при построении гистограммы. Подсчитывается число nk элементов выборки, попавших в каждый полуинтервал Δ k, k = 1, j -1, кроме Δ0 и Δ j.
4. Вычисляются вероятности pk попадания СВ X в полуинтервалы Δ k, k = 0, j, по формуле
| pk =
| αk +1 ∫ αk
| f (x,
| ^ θ 1,....,
| ^ θs) d x,
|
где α 0 = -∞, αj +1 = +∞. Для разрядов Δ k, k = 1, j -1 значения pk можно вычислить приближенно по формуле
| pk f (xk,
| ^ θ 1,....,
| ^ θs)(αk +1- αk),
|
где
- середина разряда Δ k.
5. Вычисляется реализация статистики критерия хи-квадрат по формуле
| z
| Δ =
| φ (zn)
| Δ = np 0 +
| j -1 ∑ k =1
| (nk-npk)2 / (npk) + (npj).
|
6. В соответствии с критерием согласия хи-квадрат гипотеза H 0 принимается (т.е. она согласуется с выборкой zn), если φ (zn) ≤ χ 1- p (j-s), где χ 1- p (j-s) - квантиль уровня 1- p распределения хи-квадрат с (j-s) степенью свободы, p - заданный уровень значимости (обычно p = 0.05), s - количество неизвестных параметров предполагаемого закона распределения f (x, θ 1,..., θs). Если же φ (zn) > χ 1 -p (j-s), то гипотеза H 0 отвергается. При разбиении на полуинтервалы Δ k, необходимо учитывать, чтобы npk ≥ 5 для k = 1, j -1. В противном случае (npk < 5) соседние полуинтервалы объединяются.






