Преимущество второго способа подсчета по критерию U наиболее отчетливо проявляется в тех случаях, когда две или большее количество одинаковых величин будут входить в оба сравниваемых ряда. Поскольку в таких случаях нет определенного правила расстановки одинаковых чисел, то возможна следующая ситуация, представленная в таблицах 7.2 и 7.3. В этом случае одинаковые числа равные 25 встречаются в обоих столбцах.
Таблица 7.2
| № 1
| № 2
| № 3
| №4
|
| Группа X
| Группа Y
| Инверсии X/Y
| Инверсии Y/X
|
|
| -
|
| -
|
| -
|
| -
|
|
|
| -
|
| -
|
|
| -
|
| -
|
|
| -
|
| -
|
| -
|
| -
|
|
| -
|
| -
|
|
| -
|
| -
|
|
| Сумма
|
|
|
|
Таблица 7.3
| № 1
| № 2
| №3
| № 4
| |
| Группах
| Группа Y
| Инверсии X/Y
| Инверсии Y/X
| |
|
| -
|
| -
| |
| -
|
| -
|
| |
| -
|
| -
|
| |
| -
|
| -
|
| |
| -
|
| -
|
|
|
| -
|
| -
|
|
| -
|
| -
|
|
| -
|
| -
|
| Сумма
|
|
|
|
| | | | | | | | |
Мы отчетливо видим, что сеуммы инверсий в обоих столбцах различны и зависят от того, как расположены одинаковые числа. Подчеркнем, что расположение одинаковых чисел в обоих столбцах правильное. В подобных случаях следует пользоваться для расчета вторым, более сложным способом. Но есть возможность производить расчет и первым способом. Для этого следует располагать эти числа равномерно друг под другом, например, так:
| Ряд X
| Ряд Y
|
| -
| -
|
|
| -
|
| -
|
|
|
| -
|
| -
|
|
|
| -
|
| -
|
|
В условиях той же задачи (7.1) несколько изменим экспериментальные данные таким образом, чтобы в обеих выборках имелись одинаковые значения. Представим эти измененные данные в виде таблицы 7.4.
Таблица 7.4
| № 1
| № 2
| N2 3
| № 4
| |
| Группа с дополнительной мотивацией Х(п1 =8)
| Группа без дополнительной мотивации
Y(n2 = 9)
| Ранги X R(x)
| Ранги Y R(y)
| |
|
| -
|
| -
| |
| -
|
| -
|
| |
|
| -
| (3) 3,5
| -
| |
|
| -
| (4) 3,5
| -
|
|
| -
| (5) 5,5
| -
|
| -
|
| -
| (6) 5,5
|
| -
|
| -
|
|
|
| -
|
| -
|
|
| -
| (9) 10,5
| -
|
| -
|
| -
| (10) 10,5
|
| -
|
| -
| (11) 10,5
|
|
| -
| (12) 10,5
| -
|
|
| -
|
| -
|
| -
|
| -
|
|
| -
|
| -
|
|
| -
|
| -
|
|
| -
|
| -
|
|
| Суммы рангов
| | 55,5
| 97,5
|
| | | | | | | | |
 Исходные данные 7.4 располагаются так же, как и в таблице 7.1. Затем в двух столбцах проставляются ранги, так, как будто бы оба столбца образуют собой один упорядоченный ряд чисел. Подчеркнем, однако, что ранги для чисел первого столбца помещаются в третий столбец, а ранги чисел второго столбца — в четвертый. По каждому столбцу в отдельности подсчитываются суммы рангов.
Исходные данные 7.4 располагаются так же, как и в таблице 7.1. Затем в двух столбцах проставляются ранги, так, как будто бы оба столбца образуют собой один упорядоченный ряд чисел. Подчеркнем, однако, что ранги для чисел первого столбца помещаются в третий столбец, а ранги чисел второго столбца — в четвертый. По каждому столбцу в отдельности подсчитываются суммы рангов.
Следующим этапом, как обычно при ранжировании, является проверка его правильности. Для этого:
1. Подсчитывается общая сумма рангов из таблицы 7.4:
55,5 + 97,5 = 153
2. Рассчитывается сумма рангов по формуле (1.1):

Поскольку расчетные суммы случаев совпали, то ранжирование было проведено правильно.
3. Затем находится наибольшая по величине ранговая сумма. Она обозначается как Rmax.. В нашем случае она равна 97,5.
4. U вычисляется по следующей формуле:

Где n1 — численное значение первой выборки,
n2 — численное значение второй выборки,
Rmax – наибольшая по величине сумма рангов,
пх — количество испытуемых в группе с большей суммой рангов.
Подсчитываем величину Uэмп no формуле 7.4.

Величины критических значений уже найдены нами при расчете первым способом по таблице 7 Приложения, поэтому сразу строим «ось значимости», которая имеет следующий вид:

Несмотря на то что мы немножко «подправили» экспериментальные данные для получения одинаковых чисел в обоих столбцах, рассчитанное значение Uэмп вновь попало в зону незначимости, следовательно принимается гипотеза Но о сходстве. Тем самым психолог может утверждать, что мотивация не приводит к статистически значимому увеличению эффективности времени решения технической задачи.
Для применения критерия U необходимо соблюдать следующие условия:
1. Измерение должно быть проведено в шкале интервалов и отношений.
2. Выборки должны быть несвязанными.
3. Нижняя граница применимости критерия n 1 >3 и n2>3 или n 1 =2, а n 2>5.
4. Верхняя граница применимости критерия: n 1и n 2<60.
Замечание. Критерий U применяют и для связных выборок, рассматривая их при этом как независимые. Последнее возможно, если связи внутри генеральной совокупности оказываются слабыми, а различия между двумя связными выборкам — сильными. В этом случае возможно получение значимых различий по критерию U, в то время как критерии, специально предназначенные для связанных выборок (см. главу 6), могут и не обнаружить значимых различий.
7.2. Критерий Q Розенбаума
Этот критерий существенно проще, чем критерий U. Он основан на сравнении двух упорядоченных, но не обязательно равных по численности рядов наблюдений.
Работа с критерием Розенбаума предполагает подсчет так называемых «хвостов». Потому этот критерий имеет также название — «критерий хвостов». Что же такое «хвост»?
Из предыдущего критерия мы помним, что два сравниваемых ряда имеют идеальное расположение (см. 7.2), если они могут быть представлены так:
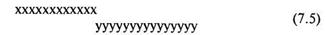
Поскольку в этом случае между элементами обоих рядов нет пересечений (одинаковых элементов), то между этими двумя рядами будет статистически значимое различие.
В том случае, если в сравниваемых рядах будут равные элементы, их следует размещать точно друг под другом. В этом случае два сравниваемых ряда можно расположить друг под другом следующими двумя эквивалентными способами:
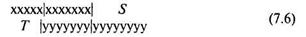
или так:

Выбор расположения либо 7.6, либо 7.7 произволен. В обоих случаях символы Т и S обозначают соответственно левый и правый «хвосты». Они подсчитываются так: величина T равна числу элементов рядов х или z, которые находятся левее начала совпадающих элементов в рядах у и n; величина S — соответственно равна числу элементов, которые находятся в рядах у и n, правее конца совпадающих элементов.
Таким образом, величина Т «левого» хвоста в случае расположения данных 7.6 равна 5, в случае 7.7 — равна 8. Величина S «правого» хвоста в случае расположения данных 7.6 равна 8, в случае 7.7 — равна 7.
Q эмп подсчитывается очень просто — это сумма величин S и Т. Иными словами:
Qэмп = S+T (7.5)
После подсчета сумм "хвостов" следует обратиться к таблице 8 Приложения в соответствии с количеством испытуемых в сравниваемых выборках. Когда сумма Qэмп = S+T достаточно велика, можно считать различия сравниваемых выборок значимыми. Для более полного знакомства с критерием решим следующую задачу.
Задача 7.2. Используя тест Векслера психолог определил показатели интеллекта у двух групп учащихся из городской и сельской школы. Его интересует вопрос — будут ли обнаружены статистически значимые различия в показателях интеллекта, если в городской выборке 11 детей, а в. сельской 12?
Решение. Для решения задачи 7.2 результаты измерений сразу представим в удобном для расчета критерия Q виде, т.е. расположив числа в порядке возрастания слева направо и одно измерение под другим (верхний ряд — городская школа, нижний — сельская):
Т |96,100, 104, 104,120,120,120, 120, |126,130,134
76,82,82,84,88,|96, 100, 102, 104, 110, 118, 120 | S
В этом случае S= 3, Т= 5, Qэмп = S + Т= 3 + 5 = 8
Критические значения для критерия Q находим по таблице 8 Приложения, по которой определяем, что для n 1 = 11 и n 2= 12 при Р = 0,05 QKp = 7, а при Р = 0,01 QKp = 9. В привычных обозначениях это выглядит следующим образом:

Соответствующая ось значимости имеет вид:

Полученное значение Qэмп попало в зону неопределенности. Психолог поэтому может считать полученные различия между рядами значимыми на уровне 5% (т. е. принимать, что уровень интеллекта учащихся городской школы выше, чем у учащихся сельской школы) и незначимыми на уровне 1%, т.е. исходить из того, что показатели интеллекта не различаются в обеих школах. Подчеркнем еще раз, что этот выбор уровня значимости определяется планом и задачами эксперимента.
В терминах статистических гипотез полученный результат может звучать так: гипотеза Но — о сходстве отклоняется на уровне значимости 0,05; в этом случае принимается альтернативная гипотеза Н1 — о различии. В то же время гипотеза Но — о сходстве может приниматься на уровне значимости 0,01, в этом случае альтернативная гипотеза Н1 — о различии — отклоняется.
Как видим, вычисления по критерию Q существенно проще, чем по критерию U, и поэтому сравнение двух независимых выборок, каждая из которых имеет больше 11 элементов, целесообразно начинать именно с этого критерия. Однако критерий Q менее мощный, чем критерий U. Поэтому, если критерий Q не выявляет различий, то последнее не означает, что их нет. В таком случае целесообразно применить другие критерии. Однако, если критерий Q выявил значимые различия на уровне 1%, то можно ограничиться только этим критерием.
Для использование критерия Q необходимо соблюдать следующие условия:
1. Измерение может быть проведено в шкале порядка, интервалов и отношений.
2. Выборки должны быть независимыми.
3. В каждой из выборок должно быть не меньше 11 испытуемых.
4. Приведенная в настоящем пособии таблица ограничивает верхний предел выборки 26 испытуемыми.
5. При числе наблюдений п 1и n 2 ≥ 26 можно пользоваться следующими величинами Qкр:

6. Принципиальным условием, дающим возможность применять критерий, является наличие «хвостов», т.е. расположение данных в сравниваемых рядах по типу 7.6 и 7.7. В случае расположения выборок следующим образом:

критерий Q оказывается неприменим. Следует использовать критерий U.
7.3. Н — критерий Крускала-Уоллиса
Критерий Н применяется для оценки различий по степени выраженности анализируемого признака одновременно между тремя, четырьмя и более выборками. Он позволяет выявить степень изменения признака в выборках, не указывая, однако, на направление этих изменений.
Критерий основан на том принципе, что чем меньше взаимопересечение выборок, тем выше уровень значимости Нэмп. Следует подчеркнуть, что в выборках может быть разное количество испытуемых, хотя в приведенных ниже задачах приводится равное число испытуемых в выборках.
Работа с данными начинается с того, что все выборки условно объединяются по порядку встречающихся величин в одну выборку и значениям этой объединенной выборки проставляются ранги. Затем полученные ранги проставляются исходным выборочным данным и по каждой выборке отдельно подсчитывается сумма рангов. Критерий построен на следующей идее — если различия между выборками незначимы, то и суммы рангов не будут существенно отличаться одна от другой и наоборот.
Задача 7.3. Четыре группы испытуемых выполняли тест Бурдона в разных экспериментальных условиях. Задача в том, чтобы установить — зависит ли эффективность выполнения теста от условий или, иными словами, существуют ли статистически достоверные различия в успешности выполнения теста между группами. В каждую группу входило четыре испытуемых.
Решение. Число ошибок показателя переключаемости внимания в процентах дано в таблице 7.5:
Таблица 7,5
| № испытуемых п/п
| 1группа
| 2 группа
| 3 группа
| 4группа
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Суммы
|
|
|
|
|
Для дальнейшей работы с критерием необходимо выстроить все полученные значения в один столбец по порядку и проставить им ранги:
Таблица 7.6
| Данные
| Ранги
| Данные
| Ранги
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Проверим правильность ранжирования. Общая сумма рангов равна 136, и по формуле (1.1) она также составляет (16·17)/2 = 136, следовательно, ранги проставлены правильно.
Следующий этап в подсчете Нэмп состоит в распределении данных вновь на исходные группы, но уже с полученными рангами:
Таблица 7. 7
| №испытуемых п/п
| 1 группа
| Ранги
| 2 группа
| Ранги
| 3 группа
| Ранги
| 4 группа
| Ранги
|
| 1
|
|
|
|
|
|
|
|
|
| 2
|
|
|
|
|
|
|
|
|
| 3
|
|
|
|
|
|
|
|
|
| 4
|
|
|
|
|
|
|
|
|
| Суммы
|
|
|
|
|
|
|
|
|
Теперь можно подсчитать величину Нзмп по формуле:

 Где N — общее число членов в обобщенной выборке;
Где N — общее число членов в обобщенной выборке;
ni. — число членов в каждой отдельной выборке;
Ri2 — квадраты сумм рангов по каждой i - ой выборке.
Подставляем данные таблицы 7.7 в формулу 7.6 и получаем:

При определении критических значений критерия Н применительно к четырем и более выборкам используют таблицу 12 Приложения для критерия хи-квадрат, подсчитав предварительно число степеней свободы v для с = 4.
Тогда v = с — 1=4— 1 = 3. Находим яо таблице 12 Приложения Нкр и представляем в привычном виде:

Соответствующая «ось значимости» имеет вид:

Полученное эмпирическое значение Нзмп оказалось существенно меньше критического значения для 5% уровня. Следовательно, можно утверждать, что различий по показателю переключаемости внимания между группами нет.
Переформулируем полученный результат в терминах нулевой и альтернативной гипотез: поскольку между показателями, измеренными в четырех разных условиях, существуют лишь случайные различия, то принимается нулевая гипотеза H о, т.е. гипотеза о сходстве. Иными словами, различные условия проведения теста Бурдона не влияют на показатели переключаемости внимания.
Подчеркнем, что если использовать критерии, позволяющие сравнивать только два ряда значений, то полученный выше результат потребовал бы шести сравнений — первая выборка со второй, третьей и т.д.
Для более полного знакомства с критерием Н решим задачу 7.4.
Задача 7.4. Анализируя результаты задачи 7.3, психолог обратил внимание, что наименьшей суммарной величиной рангов обладает последняя выборка испытуемых. Предположив, что данные этой выборки повлияли на полученный результат, он исключил данные четвертой группы из расчетов и проверил наличие различий только между первыми тремя группами.
Решение. Представим исходные данные сразу в виде таблицы 7.8:
Таблица 7.8
| № испытуемых п/п
| 1 группа
| 2 группа
| 3 группа
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Суммы
|
|
|
|
Объединим все данные в один столбец и проставим им ранги:
Таблица 7.9
| Данные
| Ранги
| Данные
| Ранги
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Сумма рангов 78
|
Подсчитаем правильность ранжирования: сумма рангов из таблицы 7.9 равна 78. По формуле (1.1) сумма рангов равняется 12∙13/2 = 78, таким образом, суммы рангов совпадают и можно утверждать, что ранги проставлены правильно.
Снова разобьем обобщенный ряд на исходные группы, но уже с рангами и сделаем это в таблице 7.10:
Таблица 7.10
| № испытуемых п/п
| 1 группа
| Ранги
| 2 группа
| Ранги
| 3 группа
| Ранги
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Суммы
|
|
|
|
|
|
|
Теперь можно подсчитать величину Нзмп по формуле (7.6). Подсчет дает следующее:

В тех случаях, когда сравниваются три выборки по критерию Н, критические величины этого критерия находятся по таблице 9 Приложения. В задаче 7.4. соответствующее значение Нкр для выборки размером n 1 = 4, n 2 = 4 и n3 = 4 составляют 5,68 для Р = 0,05 и 7,59 для Р = 0,01. Используя принятый вариант записи, получаем выражение:

Соответствующая «ось значимости» в этом случае имеет вид:

Следовательно, полученные различия по тесту Бурдона, но теперь уже между тремя группами вновь незначимы. Иными словами, четвертая группа не оказала значимого влияния на общий результат. В терминах статистических гипотез: мы вновь должны принять гипотезу Но — об отсутствии различий и отклонить гипотезу Н 1
Для использование критерия H необходимо соблюдать следующие условия:
1.Измерение должно быть проведено в шкале порядка, интервалов или отношений.
2.Выборки должны быть независимыми.
3.Допускается разное число испытуемых в сопоставляемых выборках.
4.При сопоставлении трех выборок допускается, чтобы в одной из них было п = 3, а в двух других п = 2. Однако в таком случае различия могут быть зафиксированы лишь на 5% уровне значимости.
5.Таблица 9 Приложения предусмотрена только для трех выборок и (nl, п2, п3), ≤ 5, то есть максимальное число испытуемых во всех трех выборках может быть меньше и равно 5.
6.При большем числе выборок и разном количестве испытуемых в каждой выборке следует пользоваться таблицей 12 Приложения для критерия xи-квадрат. В этом случае число степеней свободы при этом определяется по формуле: v = с - 1, где с — количество сопоставляемых выборок.
 7.4. S - критерий тенденций Джонкира
7.4. S - критерий тенденций Джонкира
Этот критерий ориентирован на выявление тенденций изменения измеряемого признака при сопоставлении от трех и до шести выборок. В отличие от предыдущего критерия Н, количество элементов в каждой выборке должно быть одинаковым. Если же число элементов в каждой выборке различно, то необходимо случайным образом уравнять выборки, при этом неизбежно утрачивается часть информации. Если же потеря информации покажется слишком расточительной, то следует воспользоваться вышеприведенным критерием Н — Крускала—Уоллиса, хотя в этом случае нельзя будет выдвигать гипотезу о наличии или отсутствии искомых тенденций.
Критерий S основан на следующем принципе: все выборки располагаются слева направо в порядке возрастания значений исследуемого признака. При этом выборка, в которой среднее значение или сумма всех значений меньше, чем в остальных выборках, располагается слева, а выборка, в которой эти же значения выше, располагается правее и так далее.
После такого упорядочивания для каждого отдельного элемента, стоящего слева в выборке, подсчитывается число инверсий по отношению ко всем элементам упорядоченных выборок, расположенных правее. Инверсией для данного элемента выборки считается число элементов, которые превышают данный элемент по величине по всем выборкам справа. Инверсии по отношению к собственной выборке, т.е. той, в которой находится данный элемент, не подсчитываются. В соответствии с этим правилом у последнего столбца выборки инверсии также не подсчитываются, т.к. справа больше нет данных.
Правило подсчета инверсий позволяет утверждать, что чем выше величина инверсий у крайних правых столбцов, тем выше уровень значимости статистики S.
С помощью этого критерия вновь обратимся к решению задачи 7.3. Но, поскольку критерий S выявляет тенденции, переформулируем условие задачи.
Задача 7.4. Необходимо установить: наблюдается ли тенденция к увеличению ошибок при выполнении теста Бурдона разными испытуемыми в зависимости от условий его выполнения?
Решение. Вновь воспроизведем таблицу 7.5, но уже как таблицу 7.11:
Таблица 7.11
| №испытуемых п/п
| 1группа
| 2 группа
| 3 группа
| 4 группа
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Суммы
|
|
|
|
|
Следующий этап работы отражен в таблице 7.12. В ней данные таблицы 7.11 переструктурированы и упорядочены в соответствии с возрастанием сумм исходных данных:
Таблица 7.12
| №
испытуемых п/п
| 1 группа
| 2 группа
| 3 группа
| 4 группа
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Суммы
|
|
|
|
|
Следующий этап связан с подсчетом инверсий. Для того чтобы удобнее было подсчитывать инверсии, произведем упорядочение величин от наименьшего к наибольшему, но уже внутри каждой группы сверху вниз. Получится таблица 7.13:
Таблица 7.13
| 1 группа
| 2 группа
| 3 группа
| 4 группа
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Обратим внимание на то, что в таблице 7.13 отсутствует первый столбец с номерами испытуемых, поскольку порядок расположения испытуемых в каждой группе перемешан.
Собственно, для подсчета инверсий можно использовать и таблицу 7.13, но мы будем считать инверсии в таблице 7.14. Инверсии подсчитываются следующим образом: из таблицы 7.13 видно, что первое число первого столбца равняется 21. Оно сравнивается со всеми числами остальных столбцов. Видим, что число 21 меньше следующих чисел второго, третьего и четвертого столбцов: 34, 45, 23, 34, 35, 24, 25, 34, 40. Этих чисел 9, следовательно, количество инверсий для числа 21 равно 9. Это число и ставим в скобках рядом с числом 21 в таблице 7.14.
Второе число в первом столбце таблицы 7.13 — 22. Оно меньше следующих чисел второго, третьего и четвертого столбцов: 34, 45, 23, 34, 35, 24, 25, 34, 40. Этих чисел 9 — следовательно, число инверсий для числа 22 также 9. Это число и ставим в скобках рядом с числом 22, уже в таблице 7.14. И т.д. В последней, четвертой группе инверсий нет, поскольку последний столбец, по правилам подсчета критерия не с чем сравнивать.
Таблица 7.14
| 1 группа
| 2 группа
| 3 группа
| 4 группа
|
| 21 (9)
| 11 (8)
| 20(4)
|
|
| 22 (9)
| 12(8)
| 23(4)
|
|
| 26(6)
| 34(2)
| 34(1)
|
|
| 27(6)
| 45 (0)
| 35(1)
|
|
| (30)
| (18)
| (10)
|
|
Следующий этап — подсчет общей суммы получившихся инверсий. Это число обозначается как А. В нашем примере оно равно А = 30 + 18 + 10 = 58.
Величина Sэмп критерия вычисляется по формуле:
Sэмп = 2 ∙ А - В (7.7)
В формуле (7.7) символ В также представляет собой выражение:

где n — количество элементов в столбце (группе)
с — количество столбцов (групп)
Подставляем в эти формулы необходимые данные, получаем

По соответствующим значениям (п — число испытуемых) п = 4 и (с — число групп, столбцов) с = 4 по таблице 10 Приложения находим величины Sкр.
В привычной записи они таковы:

Строим «ось значимости»:

Согласно полученному результату Sэмп попало в зону незначимости, следовательно, принимается гипотеза Но о том, что тенденция к увеличению числа ошибок в тесте Бурдона в зависимости от условий его выполнения, не выявлена.
Для использования критерия S необходимо соблюдать следующие условия:
1. Измерение может быть проведено в шкале порядка, интервалов и отношений.
2. Выборки должны быть независимыми.
3. Количество элементов в каждой выборке должно быть одинаковым. Если это не так, то необходимо случайным образом уравнять выборки.
4. Нижняя граница применимости критерия: не менее трех выборок и не менее двух элементов в каждом наблюдении. Верхняя граница определяется таблицей 10 Приложения — не более 6 выборок и не более 10 элементов в каждой выборке. Во всех других случаях следует пользоваться критерием Н.
Глава 8
КРИТЕРИИ СОГЛАСИЯ РАСПРЕДЕЛЕНИЙ И МНОГОФУНКЦИОНАЛЬНЫЙ КРИТЕРИЙ «φ»
Критерий хи-квадрат
Критерий хи-квадрат (другая форма записи — χ2 греческая буква «хи») один из наиболее часто использующихся в психологических исследованиях, поскольку он позволяет решать большое число разных задач, и, кроме того, исходные данные для него могут быть получены в любой шкале, начиная со шкалы наименований.
Критерий хи-квадрат используется в двух вариантах:
o как расчет согласия эмпирического распределения и предполагаемого теоретического; в этом случае проверяется гипотеза Н о об отсутствии различий между теоретическим и эмпирическим распределениями;
o как расчет однородности двух независимых экспериментальных выборок; в этом случае проверяется гипотеза Но об отсутствии различий между двумя эмпирическими (экспериментальными) распределениями.
Критерий построен так, что при полном совпадении экспериментального и теоретического (или двух экспериментальных) распределений величина χ2эмп (хи-квадрат эмпирическое) = 0, и чем больше расхождение между сопоставляемыми распределениями, тем больше величина эмпирического значения хи-квадрат. Основная расчетная формула критерия хи-квадрат выглядит так:


где fэ — эмпирическая частота fm — теоретическая частота k — количество разрядов признака.
Расчетная формула критерия хи-квадрат для сравнения двух эмпирических распределений в зависимости от вида представленных данных может иметь следующий вид:

где N и M — соответственно число элементов в первой и во второй выборке. Эти числа могут совпадать, а могут быть и различными.
Для критерия хи-квадрат оценка уровней значимости (см. таблицу 12 Приложения 1) определяется по числу степеней свободы, которое обозначается греческой буквой ν (ню) и в большинстве случаев, вычисляется по формуле:
ν = k –1, где k каждый раз определяется по выборочным данным и представляет собой число элементов в выборке. Если при расчете критерия используется таблица экспериментальных данных, то величина v рассчитывается следующим образом: ν = (k - 1) • (с - 1), где k — число строк, а с — число столбцов.
Рассмотрим ряд примеров решения задач с использованием критерия хи-квадрат.






