История становления статистики как науки
Уже в древний период истории человечества хозяйственные и военные нужды требовали наличия данных о населении, его составе, имущественном положении. С целью налогообложения организовывались переписи населения, производился учет земель.
Со временем собирание данных о массовых общественных явлениях приобрело регулярный характер.
С середины XIX в. благодаря усилиям Адольфа Кетле (1796-1874 гг.) были выработаны правила переписей населения и установлена регулярность их проведения в развитых странах. Для координации развития статистики по инициативе А. Кетле проводились международные статистические конгрессы, а в 1885 г. был основан Международный статистический институт, существующий и сейчас.
Становление государственной статистики можно отнести к концу XII - началу XIII в., хотя первые переписи земель и населения с постоянно усложнявшейся программой проводились еще в Киевской Руси (IX - XII вв.).
Петровская реформа налоговой системы связана с появлением новой единицы, ею стала «душа» мужского пола, что потребовало подушной переписи населения - ревизии. Первая ревизия была объявлена 26 ноября 1718 г., ревизию проводила армия.
В начале XIII в. зарождался и текущий учет населения.
Первая половина XIX в. связана с новым этапом в развитии отечественной статистики. В сентябре 1802 г. в соответствии с Высочайшим манифестом императора Александра I вводится письменная отчетность министерств. Так началось операционно-структурное оформление государственной статистики.
Особое место в истории статистики принадлежит земской статистике. При земствах, органах местного самоуправления, с середины 70-х годов XIX века были созданы специальные статистические бюро. Земские статистики собирали и разрабатывали огромный статистический материал, который использовался для глубоких экономических и социальных исследований. Работа земской статистики характеризуется не только сбором и разработкой статистических данных, но и развитием статистической методологии.
В 90-х годах были созданы фабрично-заводские инспекции, которые вели текущую статистику, разрабатывали данные по статистике труда, в том числе о составе рабочей силы, несчастных случаях, стачках и др.
Период 1917-1930 гг. отличается исключительной интенсивностью: проводится большое число специально организованных, статистических переписей и обследований, плодотворно работают различные научные коллективы, строится первый баланс народного хозяйства.
Последующее развитие статистики тормозилось созданием в 30-е годы административно-бюрократической системы, массовыми репрессиями, в том числе и лучших экономистов и статистиков (Н.Д. Кондратьева, А.В. Чаянова, В.Г. Громана, О.А. Квитнина и многих других).
В это время формируются отраслевые статистики, складывается система объемных показателей, скрывающая негативные тенденции в развитии народного хозяйства. Активно разрабатываются и качественные статистические показатели (индексы производительности труда, себестоимости и др.). Статистика подчиняется решению оперативных задач, оценке выполнения плана в ущерб ее аналитическим функциям.
В годы Великой Отечественной войны перед советской статистикой стояли задачи по оперативному учету трудовых, материальных ресурсов, перемещение производственных сил страны в восточные районы.
После войны роль и значение статистики возросли: развернулись балансовые работы, углубилась теория индексного метода и расширилась практика его применения, получили распространение экономико-математические модели и методы, развитие прикладной статистики.
Статистические совокупности
Статистическая совокупность - это множество (масса) однокачественных (однородных) хотя бы по одному какому-либо признаку явлений, существование которых ограничено в пространстве и времени. Статистическая совокупность (множество) совсем не обязательно представляет большую численность единиц, в принципе она может быть и очень маленькой; например, объем совокупности малой выборки может составлять иногда 8-10 единиц.
Важнейшим свойством статистической совокупности является ее неразложимость. Это означает, что дальнейшее дробление индивидуальных явлений не вызывает потери их качественной основы. Исчезновение или ликвидация одного или ряда явлений не разрушает качественной основы статистической совокупности в целом. Так, население страны или города останется населением, несмотря на постоянно происходящие процессы механического и естественного движения населения.
Количественные изменения значение признака при переходе от одной единицы совокупности к другой называются вариацией. Вариация возникает под воздействием случайных, прежде всего внешних причин.
Единицы статистической совокупности обладают определенными свойствами которые называются признаками.
Статистика изучает явления через их признаки, чем более однородна совокупность тем больше общих признаков имеют ее единицы и тем меньше варьируют значения этих признаков.

Описательный признак – признак, который может быть выражен только словесно.
Количественный признак – признак, который может быть выражен численно.
Прямой признак – свойство непосредственно присуще характерному объекту.
Косвенный признак – свойства не самого характеризуемого объекта, а объекта связанного с ним либо входящих в него.
Первичный признак – абсолютная величина, может быть измерен.
Вторичный признак – результат сопоставления первичных признаков, он измеряется непосредственно.
Натуральный признак – измеряется в штуках, кг, тоннах, литрах и т.д.
Трудовой признак – измеряется в человеко-днях, человеко-часах.
Стоимостной признак - измеряется в рублях, $,?, ₤.
Безразмерный признак – измерение в долях, %
Альтернативный признак – признак, который принимает только одно значение из нескольких возможных.
Дискретный признак – принимает только целое значение, без промежуточного.
Непрерывный признак – признак, принимающий любые значения в определенном диапазоне.
Факторный признак – признак, под действием которого изменяется другой признак.
Результативный признак – признак, который изменяется под признаком другого.
Моментный признак – признак, измеренный на определенный момент времени.
Интервальный признак – признак за определенный интервал времени.
Виды измерительных шкал
Шкала (лат. scala — лестница) в буквальном значении есть измерительный инструмент.
1) Номанативная (НШ) (номинальная, шкала наименований). Это шкала, классифицирующая по названию. Название же не измеряется количественно, оно лишь позволяет отличить один объект от другого. НШ – это способ классификации объектов или субъектов, распределения их по ячейкам классификации. Простейший случай НШ – дихотомическая шкала (ДШ), состаящая всего лишь из двух ячеек. Признак, который измеряется по ДШ наименований, называется альтернативным. Он может принимать всего 2 значения. Более сложный вариант НШ – классификация из 3 и более ячеек. Т.о., НШ позволяет подсчитать частоты встречаемости разных «наименований», или значений признака, и затем работать с этими частотами с помощью математических методов.
2) Порядковая (ординальная) шкала (ПШ) – шкала, классифицирующая по принципу «больше-меньше». Классификационные ячейки располагаются в последовательности от ячейки «самое малое значение» к ячейке «самое большое значение» (или наоборот). В ПШ должно быть не менее трех классов (ячеек). Истинное расстояние между классами неизвестно, известно лишь, что они образуют последовательность. Чем больше классов в шкале, тем больше возможностей для математической обработки полученных данный и проверки гипотез. Единица измерения в ПШ – расстояние в 1 класс или в 1 ранг (может быть разным).
3) Интервальная (шкала равных интервалов) (ИШ) – шкала, классифицирующая по принципу «больше на определенное количество единиц-меньше на определенное количество единиц». Каждое из возможных значений признака отстоит от другого на равном расстоянии.
4) Шкала равных отношений (ШРО) – шкала, классифицирующая объекты или субъектов пропорционально степени выраженности измеряемого свойства. В ШРО классы обозначаются числами, которые пропорциональны друг другу: 2 так относится к 4, как 4 к 8. это предполагает наличие абсолютной нулевой точки отсчета. В психологии примером ШРО являются шкалы порогов абсолютной чувствительности.
Другие шкалы.
1. Дихотомическая классификация часто рассматривается как вариант шкалы наименований. Это верно, за исключением одного случая, когда мы измеряем свойство, имеющее всего лишь два уровня выраженности: «есть—нет», так называемое «точечное» свойство. Примеров таких свойств много: наличие или отсутствие у испытуемого какой-либо наследственной болезни (дальтонизм, болезнь Дауна, гемофилия и др.), абсолютного слуха и др. В этом случае исследователь имеет право проводить «оцифровку» данных, присваивая каждому из типов цифру «1» или «0», и работать с ними как со значениями шкалы интервалов.
2. Шкала разностей, в отличие от шкалы отношений, не имеет естественного нуля, но имеет естественную масштабную единицу измерения. Ей соответствует аддитивная группа действительных чисел. Классическим примером этой шкалы является историческая хронология. Она сходна со шкалой интервалов. Разница лишь в том, что значения этой шкалы нельзя умножать (делить) на константу. Поэтому считается, что шкала разностей — единственная с точностью до сдвига.
3. Абсолютная шкала является развитием шкалы отношении и отличается от нее тем, что обладает естественной единицей измерения. В этом ее сходство со шкалой разностей. Число решенных задач («сырой» балл), если задачи эквивалентны, — одно из проявлений абсолютной шкалы.
В психологии абсолютные шкалы не используются. Данные, полученные с помощью абсолютной шкалы, не преобразуются, шкала тождественна сама себе. Любые статистические меры допустимы.
4. В литературе, посвященной проблемам психологических измерений, упоминаются и другие типы шкал: Ординальная (порядковая) с естественным началом, лог-интервальная, Упорядоченная метрическая и др.
Все написанное выше относится к одномерным шкалам. Шкалы могут быть и многомерными: шкалируемый признак в этом случае имеет ненулевые проекции на два (или более) соответствующих параметра. Векторные свойства, в отличие от скалярных, являются многомерными.
Основные виды графиков
Существует множество видов графических изображений. Их классификация основана на ряде признаков:
а) способ построения графического образа;
б) геометрические знаки, изображающие статистические показатели и отношения;
в) задачи, решаемые с помощью графического изображения.
Статистические графики по форме графического образа:
Линейные: статистические кривые.
Плоскостные: столбиковые, полосовые, квадратные, круговые, секторные, фигурные, точечные, фоновые.
Объемные: поверхности распределения.
Статистические графики по способу построения и задачам изображения:
Диаграммы: диаграммы сравнения, диаграммы динамики, структурные диаграммы.
Статистические карты: картограммы, картодиаграммы.
По способу построения статистические графики делятся на диаграммы и статистические карты. Диаграммы - наиболее распространенный способ графических изображений. Это графики количественных отношений. Виды и способы их построения разнообразны. Диаграммы применяются для наглядного сопоставления в различных аспектах (пространственном, временном и др.) независимых друг от друга величин: территорий, населения и т. д. При этом сравнение исследуемых совокупностей производится по какому-либо существенному варьирующему признаку. Статистические карты - графики количественного распределения по поверхности. По своей основной цели они близко примыкают к диаграммам и специфичны лишь в том отношении, что представляют собой условные изображения статистических данных на контурной географической карте, т. е. показывают пространственное размещение или пространственную распространенность статистических данных. Геометрические знаки, как было сказано выше, - это либо точки, либо линии или плоскости, либо геометрические тела. В соответствии с этим различают графики точечные, линейные, плоскостные и пространственные (объемные).
При построении точечных диаграмм в качестве графических образов применяются совокупности точек; при построении линейных - линии. Основной принцип построения всех плоскостных диаграмм сводится к тому, что статистические величины изображаются в виде геометрических фигур и, в свою очередь, подразделяются на столбиковые, полосовые, круговые, квадратные и фигурные.
Статистические карты по графическому образу делятся на картограммы и картодиаграммы.
В зависимости от круга решаемых задач выделяются диаграммы сравнения, структурные диаграммы и диаграммы динамики.
Степенные средние величины
Степенные средние в зависимости от представления исходных данных могут быть простыми и взвешенными.
Если вариант  встречается один раз, расчеты проводим по средней простой (например зарплата в 3 тыс.руб. встречается только у одного рабочего), а если вариант повторяется неодинаковое число раз, то есть имеет разные частоты
встречается один раз, расчеты проводим по средней простой (например зарплата в 3 тыс.руб. встречается только у одного рабочего), а если вариант повторяется неодинаковое число раз, то есть имеет разные частоты  (например зарплата в 4 тыс.рублей встречается у пяти работников), то расчет проводим по средней взвешенной.
(например зарплата в 4 тыс.рублей встречается у пяти работников), то расчет проводим по средней взвешенной.
Формула степенной простой в общем виде

где
 — индивидуальное значение признака
— индивидуальное значение признака  -й единицы совокупности
-й единицы совокупности
 — показатель степени средней величины
— показатель степени средней величины
 — число единиц совокупности
— число единиц совокупности
Формула степенной средней взвешенной в общем виде

где
 — частота повторения -й варианты.
— частота повторения -й варианты.
Типы выборок
Выборки делятся на два типа:
- - вероятностные
- - невероятностные
Вероятностные выборки:
1. Простая вероятностная выборка:
- Простая повторная выборка. Использование такой выборки основывается на предположении, что каждый респондент с равной долей вероятности может попасть в выборку. На основе списка генеральной совокупности составляются карточки с номерами респондентов. Они помещаются в колоду, перемешиваются и из них наугад вынимается карточка, записывается номер, потом возвращается обратно. Далее процедура повторяется столько раз, какой объём выборки нам необходим. Минус: повторение единиц отбора.
- Простая бесповторная выборка. Процедура построения выборки такая же, только карточки с номерами респондентов не возвращаются обратно в колоду.
2.Систематическая вероятностная выборка. Является упрощенным вариантом простой вероятностной выборки. На основе списка генеральной совокупности через определённый интервал (К) отбираются респонденты. Величина K определяется случайно. Наиболее достоверный результат достигается при однородной генеральной совокупности, иначе возможны совпадение величины шага и каких-то внутренних циклических закономерностей выборки (смешение выборки). Минусы: такие же как и в простой вероятностной выборке.
3.Серийная (гнездовая) выборка. Единицы отбора представляют собой статистические серии (семья, школа, бригада и т.п.). Отобранные элементы подвергаются сплошному обследованию. Отбор статистических единиц может быть организован по типу случайной или систематической выборки. Минус: Возможность большей однородности, чем в генеральной совокупности.
4.Районированная выборка. В случае неоднородной генеральной совокупности, прежде, чем использовать вероятностную выборку с любой техникой отбора, рекомендуется разделить генеральную совокупность на однородные части, такая выборка называется районированной. Группами районирования могут выступать как естественные образования (например, районы города), так и любой признак, заложенный в основу исследования. Признак, на основе которого осуществляется разделение, называется признаком расслоения и районирования.
5.«Удобная» выборка. Процедура «удобной» выборки состоит в установлении контактов с «удобными» единицами выборки - с группой студентов, спортивной командой, с друзьями и соседями. Если необходимо получить информацию о реакции людей на новую концепцию, такая выборка вполне обоснованна. «Удобную» выборку часто используют для предварительного тестирования анкет.
Невероятностные выборки (отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д.):
1. Квотная выборка – выборка строится как модель, которая воспроизводит структуру генеральной совокупности в виде квот (пропорций) изучаемых признаков. Число элементов выборки с различным сочетанием изучаемых признаков определяется с таким расчётом, чтобы оно соответствовало их доле (пропорции) в генеральной совокупности.
Плюсы: обычно такие выборки репрезентативны.
Минусы: применение данного способа построения выборки возможно при наличии достаточно полной информации о генеральной совокупности.
2.Метод снежного кома. Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
3.Стихийная выборка – выборка так называемого «первого встречного». Часто используется в теле- радио- опросах. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов.
Минусы: невозможно установить какую генеральную совокупность представляют опрошенные, и как следствие – невозможность определить репрезентативность.
4.Маршрутный опрос – часто используется, если единицей изучения является семья. На карте населённого пункта, в котором будет производится опрос, нумеруются все улицы. С помощью таблицы (генератора) случайных чисел отбираются большие числа. Каждое большое число рассматривается как состоящее из 3-х компонентов: номер улицы (2-3 первых числа), номер дома, номер квартиры.
5.Районированная выборка с отбором типичных объектов. Если после районирования из каждой группы отбирается типичный объект, т.е. объект, который по большинству изучаемых в исследовании характеристик приближается к средним показателям, такая выборка называется районированной с отбором типичных объектов.
22. Методика определения необходимой численности выборки
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем теории вероятностей, которые позволяют установить, какой объем единиц следует выбрать из генеральной совокупности, чтобы он был достаточным и обеспечивал репрезентативность выборки.
Уменьшение стандартной ошибки выборки, а следовательно, увеличение точности оценки всегда связано с увеличением объема выборки, поэтому уже на стадии организации выборочного наблюдения приходится решать вопрос о том, каков должен быть объем выборочной совокупности, чтобы была обеспечена требуемая точность результатов наблюдений. Расчет необходимого объема выборки строится с помощью формул, выведенных из формул предельных ошибок выборки (Δ),соответствующих тому или иному виду и способу отбора. Так, для случайного повторного объема выборки (n) имеем:
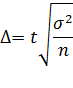
откуда
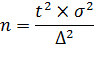
Суть этой формулы – в том, что при случайном повторном отборе необходимой численности объем выборки прямо пропорционален квадрату коэффициента доверия (t2) и дисперсии вариационного признака (σ2) и обратно пропорционален квадрату предельной ошибки выборки ( Δ 2). В частности, с увеличением предельной ошибки в два раза необходимая численность выборки может быть уменьшена в четыре раза. Из трех параметров два (t и σ) задаются исследователем. При этом исследователь исходя из цели и задач выборочного обследования должен решить вопрос: в каком количественном сочетании лучше включить эти параметры для обеспечения оптимального варианта? В одном случае его может больше устраивать надежность полученных результатов (t), нежели мера точности (σ), в другом – наоборот.
В целом формула предельной ошибки выборочной средней величины позволяет определять:
- величину возможных отклонений показателей генеральной совокупности от показателей выборочной совокупности;
- необходимую численность выборки, обеспечивающую требуемую точность, при которой пределы возможной ошибки не превысят некоторой заданной величины;
- вероятность того, что в проведенной выборке ошибка будет иметь заданный предел.
Таблица сопряженности как метод представления совместного распределения (группировки) двух признаков.
Таблица сопряженности - средство представления совместного распределения двух переменных, предназначенное для исследования связи между ними. Таблица сопряженности является наиболее универсальным средством изучения статистических связей, так как в ней могут быть представлены переменные с любым уровнем измерения.
Строки таблицы сопряженности соответствуют значениям одной переменной, столбцы - значениям другой переменной (количественные шкалы предварительно должны быть сгруппированы в интервалы). На пересечении строки и столбца указывается частота совместного появления fij соответствующих значений двух признаков xi и yj. Сумма частот по строке fi называется маргинальной частотой строки; сумма частот по столбцу fj - маргинальной частотой столбца. Сумма маргинальных частот равна объему выборки n; их распределение представляет собой одномерное распределение переменной, образующей строки или столбцы таблицы.
В таблицах сопряженности могут быть представлены как абсолютные, так и относительные частоты (в долях или процентах). Относительные частоты могут рассчитываться по отношению:
- к маргинальной частоте по строке
- к маргинальной частоте по столбцу
- к объему выборки
Таблицы сопряженности используются для проверки гипотезы о наличии связи между двумя признаками (Статистическая связь, Критерий "хи-квадрат"), а также для измерения тесноты связи (Коэффициент фи, Коэффициент контингенции, Коэффициент Крамера)
Понятие ранжирования
Ранжирование - это процесс преобразования простого статистического ряда на основе упорядочения (группирования) числовых значений элементов ряда по убыванию
 ,
,
или по возрастанию
 ,
,
где i это ранг элемента ранжированного ряда значений признака I [1, n].
В результате преобразования получим ранжированный ряд в виде убывающей или возрастающей по значению признака
числовой последовательности, в котором значение первого ранга элементов убывающего ряда равно числовому значению n–го ранга элементов возрастающего ряда. Табличное представление ранжированного ряда аналогично виду простого статистического ряда.
Процесс преобразования простого статистического ряда из n числовых значений в возрастающую (убывающую) числовую последовательность основан на применении алгоритмов "Определение наибольшего числового значения элементов ряда"; "Перестановка элементов ряда".
Алгоритм определения наибольшего числового значения первого ранга элементов ряда основан на последовательном выполнении операции сравнения двух значений за n шагов. На первом шаге примем значение первого элемента x1 за начальное наибольшее значение элементов ряда (xmax=x1). На каждом i-м шаге алгоритма сравнивается значение текущего (xi, где i=2,…,n) элемента ряда с наибольшим значением xmax. На втором шаге (i=2) значение второго элемента ряда (x2) будем сравнивать с наибольшим значением x2>xmax (x2 больше, чем xmax?). Если условие выполняется, то за xmax принимается большее значение элемента ряда (xmax=x2), а при невыполнении условия xmax сохранит свое предыдущее значение (xmax=x1). На последнем n-м шаге выполняется операция сравнения xn> xmax и определяется результат алгоритма наибольшее числовое значение первого ранга (x`1) из n-элементов ряда.
Коэффициенты корреляции
Термин "корреляция" означает "связь".
Выборочным линейным парным коэффициентом корреляции К. Пирсона, как известно, называется число

Если rn = 1, то yi=axi+b причем a>0. Если же rn = - 1, то yi=axi+b причем a<0. Таким образом, близость коэффициента корреляции к 1 (по абсолютной величине) говорит о достаточно тесной линейной связи.
Для расчета непараметрического коэффициента ранговой корреляции Спирмена необходимо сделать следующее. Для каждого xi рассчитать его ранг ri в вариационном ряду, построенном по выборке x1, x2, … xn. Для каждого yi рассчитать его ранг qi в вариационном ряду, построенном по выборке y1, y2, … yn Для набора из n пар  вычислить линейный коэффициент корреляции. Он называется коэффициентом ранговой корреляции, поскольку определяется через ранги.
вычислить линейный коэффициент корреляции. Он называется коэффициентом ранговой корреляции, поскольку определяется через ранги.
Коэффициент ранговой корреляции Спирмена равен

Отметим, что коэффициент ранговой корреляции Спирмена остается постоянным при любом строго возрастающем преобразовании шкалы измерения результатов наблюдений.
Для коррелирования переменных, измеренных в дихотомической и интервальной шкале используют точечно-бисериальный коэффициент корреляции.
Точечно-бисериальный коэффициент корреляции - это метод корреляционного анализа отношения переменных, одна из которых измерена в шкале наименований и принимает только 2 значения (к примеру, мужчины/женщины, ответ верный/ответ неверный, признак есть/признака нет), а вторая в шкале отношений или интервальной шкале. Формула расчета коэффициента точечно-бисериальной корреляции:

где m1 и m0 - средние значения Х со значением 1 или 0 по Y;
σx – стандартное отклонение всех значений по Х;
n1,n0 – количество значений Х с 1 или 0 по Y;
n – общее количество пар значений.
Случаи, когда одна из переменных представлена в дихотомической шкале, а другая в ранговой (порядковой), требуют применения коэффициента рангово-бисериальной корреляции:
rpb=2 / n * (m1 - m0)
где n – число объектов измерения;
m1 и m0 - средний ранг объектов с 1 или 0 по второй переменной.
Данный коэффициент применяется при проверке валидности тестов.
Множественная регрессия
В настоящее время множественная регрессия - один из наиболее распространенных методов в статистике. Основная цель множественной регрессии - построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель.
Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели, который в свою очередь включает 2 круга вопросов: отбор факторов и выбор уравнения регрессии. Отбор факторов обычно осуществляется в два этапа:
1) теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
2) количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции).
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
1. Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность
2. Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
3. Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность - тесная линейная связь между факторами. Мультиколлинеарность может привести к нежелательным последствиям:
1) оценки параметров становятся ненадежными. Они обнаруживают большие стандартные ошибки. С изменением объема наблюдений оценки меняются (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
2) затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированны; параметры линейной регрессии теряют экономический смысл;
3) становится невозможным определить изолированное влияние факторов на результативный показатель.
Мультиколлинеарность имеет место, если определитель матрицы межфакторной корреляции близок к нулю.
Если же определитель матрицы межфакторной корреляции близок к единице, то мультколлинеарности нет. Существуют различные подходы преодоления сильной межфакторной корреляции. Простейший из них - исключение из модели фактора (или факторов), в наибольшей степени ответственных за мультиколлинеарность при условии, что качество модели при этом пострадает несущественно (а именно, теоретический коэффициент детерминации -R2y(x1...xm) снизится несущественно).
Определение факторов, ответственных за мультиколлинеарность, может быть основано на анализе матрицы межфакторной корреляции. При этом определяют пару признаков-факторов, которые сильнее всего связаны между собой (коэффициент линейной парной корреляции максимален по модулю). Из этой пары в наибольшей степени ответственным за мультиколлинеарность будет тот признак, который теснее связан с другими факторами модели (имеет более высокие по модулю значения коэффициентов парной линейной корреляции).
Еще один способ определения факторов, ответственных за мультиколлинеарность основан на вычислении коэффициентов множественной детерминации (R2xj(x1,...,xj-1,xj+1,...,xm)), показывающего зависимость фактора xj от других факторов модели x1,..., xj-1, x j+1,..., xm. Чем ближе значение коэффициента множественной детерминации к единице, тем больше ответственность за мультиколлинеарность фактора, выступающего в роли зависимой переменной. Сравнивая между собой коэффициенты множественной детерминации для различных факторов можно проранжировать переменные по степени ответственности за мультиколлинеарность. При выборе формы уравнения множественной регрессии предпочтение отдается линейной функции:
yi =a+b1·x1i+ b2·x2i+...+ bm·xmi+ui
в виду четкой интерпретации параметров.
Данное уравнение регрессии называют уравнением регрессии в естественном (натуральном) масштабе. Коэффициент регрессии bj при факторе хj называют условно-чистым коэффициентом регрессии. Он измеряет среднее по совокупности отклонение признака-результата от его средней величины при отклонении признака-фактора хj на единицу, при условии, что все прочие факторы модели не изменяются (зафиксированы на своих средних уровнях).
Если не делать предположения о значениях прочих факторов, входящих в модель, то это означало бы, что каждый из них при изменении х j также изменялся бы (так как факторы связаны между собой), и своими изменениями оказывали бы влияние на признак-результат.
Основные понятия факторного анализа
Факторный анализ — статистический метод, который используется при обработке больших массивов экспериментальных данных. Задачами факторного анализа являются сокращение числа переменных и определение структуры взаимосвязей между переменными, т.е. классификация переменных, поэтому факторный анализ используется как метод сокращения данных или как метод структурной классификации.
Задачами факторного анализа являются:
- сокращение числа переменных,
- определение структуры взаимосвязей между переменными, т.е. классификация переменных.
Факторный анализ может быть:
- разведочным — он осуществляется при исследовании скрытой факторной структуры без предположения о числе факторов и их нагрузках;
- конфирматорным, предназначенным для проверки гипотез о числе факторов и их нагрузках
Поэтому факторный анализ используется как метод сокращения данных или как метод структурной классификации.
Материалом для факторного анализа служат корреляционные связи, а точнее — коэффициенты корреляции Пирсона, которые вычисляются между переменными, включенными в обследование. Иными словами, факторному анализу подвергают корреляционные матрицы, или, как их иначе называют, матрицы интеркорреляции. Наименования столбцов и строк в этих матрицах одинаковы так как они представляют собой перечень переменных, включенных в анализ. По этой причине матрицы интеркорреляций всегда квадратные, т.е. число строк в них равно числу столбцов, и симметричные, т.е. на симметричных местах относительно главной диагонали стоят одни и те же коэффициенты корреляции.
Главное понятие факторного анализа — фактор. Это искусственный статистический показатель, возникающий в результате специальных преобразований таблицы коэффициентов корреляции между изучаемыми психологическими признаками, или матрицы интеркорреляций. Процедура извлечения факторов из матрицы интеркорреляций называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, выделяемые в результате факторизации, как правило, неравноценны по своему значению.
Элементы факторной матрицы называются «факторными нагрузками, или весами», и они представляют собой коэффициенты корреляции данного фактора со всеми показателями, использованными в исследовании.
История становления статистики как науки
Уже в древний период истории человечества хозяйственные и военные нужды требовали наличия данных о населении, его составе, имущественном положении. С целью налогообложения организовывались переписи населения, производился учет земель.
Со временем <






