Рис. 3. Классическая каскадная модель с обратной связью
В результате выполнения генерируются внутренние или внешние данные проекта, включай документацию и ПО. Документы по анализу требований впоследствии передаются системным специалистам, которые в свою очередь передают их разработчикам программных систем более высокого уровня. Программисты передают детальные технические характеристики программистам, которые уже представляют готовый код тестерам.
Переход от одной фазы к другой осуществляется посредством формального обзора. Таким образом, клиент получает общее представление о процессе разработки, кроме того происходит проверка качества программного продукта. Как правило, прохождение стадии обзора указывает на договоренность между командой разработчиков и клиентом о том, что текущая фаза завершена и можно перейти к выполнению следующей фазы. Окончание фазы удобно принимать за стадию в процессе выполнения проекта.
В результате завершения определенных фаз формируется базовая линия, которая в данной точке "замораживает" продукты разработки. Если возникает потребность в их изменении, тогда для внесения изменений используется формальный процесс изменений.
В критических точках каскадной модели формируются базовые линии, последняя из которых является базовой линией продукта. После формирования заключительной базовой линии производится обзор приемки.
Попытки оптимизации каскадной модели привели к возникновению других циклов разработки ПО. Прототипирование программ позволяет обеспечить полное понимание требований, в то время как инкрементные и спиральные модели позволяют повторно возвращаться к фазам, соотнесенным с классической каскадной моделью, прежде чем полученный продукт будет признан окончательным.
Отличительным свойством каскадной модели можно назвать то, что она представляет собой формальный метод, разновидность разработки "сверху вниз", она состоит из независимых фаз, выполняемых последовательно, и подвержена частому обзору.
Недостатки каскадной модели
Но при использовании каскадной модели для проекта, который трудно назвать подходящим для нее, проявляются следующими недостатки:
- в основе модели лежит последовательная линейная структура, в результате чего каждая попытка вернуться на одну или две фазы назад, чтобы исправить какую-либо проблему или недостаток, приведет к значительному увеличению затрат и сбою в графике;
- она не может предотвратить возникновение итераций между фазами, которые так часто встречаются при разработке ПО, поскольку сама модель создается согласно стандартному циклу аппаратного инжиниринга;
- она не отображает основное свойство разработки ПО, направленное на разрешение задач. Отдельные фазы строго связаны с определенными действиями, что отличается от реальной работы персонала или коллективов;
- она может создать ошибочное впечатление о работе над проектом. Выражение типа "35 процентов выполнено" — не несет никакого смысла и не является показателем для менеджера проекта;
- интеграция всех полученных результатов происходит внезапно в завершающей стадии работы модели. В результате такого единичного прохода через весь процесс, связанные с интегрированием проблемы, как правило, дают о себе знать слишком поздно. Следовательно, проявятся не обнаруженные ранее ошибки или конструктивные недостатки, повысить степень риска при небольшом задаче времени на восстановление продукта;
- у клиента едва ли есть возможность ознакомиться с системой заранее, это происходит лишь в самом конце жизненного цикла. Клиент не имеет возможности воспользоваться доступными промежуточными результатами, и отзывы пользователей нельзя передать обратно разработчикам. Поскольку готовый продукт не доступен вплоть до окончания процесса, пользователь принимает участие в процессе разработки только в самом начале — при сборе требований, и в конце — во время приемочных испытаний;
- пользователи не могут убедиться в качестве разработанного продукта до окончания всего процесса разработки. Они не имеют возможности оценить качество, если нельзя увидеть готовый продукт разработки;
- у пользователя нет возможности постепенно привыкнуть к системе. Процесс обучения происходит в конце жизненного цикла, когда ПО уже запущено в эксплуатацию;
- проект можно выполнить, применив упорядоченную каскадную модель, и привести его в соответствие с письменными требованиями, что, однако, не гарантирует его запуска в эксплуатацию;
- каждая фаза является предпосылкой для выполнения последующих действий, что превращает такой метод в рискованный выбор для систем, не имеющих аналогов, так как он не поддается гибкому моделированию;
- для каждой фазы создаются результативные данные, которые по его завершению считаются замороженными. Это означает, что они не должны изменяться на следующих этапах жизненного цикла продукта. Если элемент результативных данных какого-либо этапа изменяется (что встречается весьма часто), на проект окажет негативное влияние изменение графика, поскольку ни модель, ни план не были рассчитаны на внесение и разрешение изменения на более поздних этапах жизненного цикла;
- все требования должны быть известны в начале жизненного цикла, но клиенты редко могут сформулировать все четко заданные требования на этот момент разработки. Модель не рассчитана на динамические изменения в требованиях на протяжении всего жизненного цикла, так как получаемые данные "замораживаются". Использование модели может повлечь за собой значительные затраты, если требования в недостаточной мере известны или подвержены динамическим изменениям во время протекания жизненного цикла;
- возникает необходимость в жестком управлении и контроле, поскольку в модели не предусмотрена возможность модификации требований;
- модель основана на документации, а значит, количество документов может быть избыточным;
- весь программный продукт разрабатывается за один раз. Нет возможности разбить систему на части. В результате взятых разработчиками обязательств разработать целую систему за один раз могут возникнуть проблемы с финансированием проекта. Происходит распределение больших денежных средств, а сама модель едва ли позволяет повторно распределить средства, не разрушив при этом проект в процессе его выполнения;
- отсутствует возможность учесть переделку и итерации за рамками проекта.
Рис. 4. V –образная модель жизненного цикла разработки ПО
Фазы V-образной модели
Ниже подано краткое описание каждой фазы V-образной модели, начиная от планирования проекта и требований вплоть до приемочных испытаний:
- планирование проекта и требований – определяются системные требования, а также то, каким образом будут распределены ресурсы организации с целью их соответствия поставленным требованиям. (в случае необходимости на этой фазе выполняется определение функций для аппаратного и программного обеспечения);
- анализ требований к продукту и его спецификации – анализ существующей на данный момент проблемы с ПО, завершается полной спецификацией ожидаемой внешней линии поведения создаваемой программной системы;
- архитектура или проектирование на высшем уровне – определяет, каким образом функции ПО должны применяться при реализации проекта;
- детализированная разработка проекта – определяет и документально обосновывает алгоритмы для каждого компонента, который был определен на фазе построения архитектуры. Эти алгоритмы в последствии будут преобразованы в код;
- разработка программного кода – выполняется преобразование алгоритмов, определенных на этапе детализированного проектирования, в готовое ПО;
- модульное тестирование – выполняется проверка каждого закодированного модуля на наличие ошибок;
- интеграция и тестирование – установка взаимосвязей между группами ранее поэлементно испытанных модулей с целью подтверждения того, что эти группы работают также хорошо, как и модули, испытанные независимо друг от друга на этапе поэлементного тестирования;
- системное и приемочное тестирование – выполняется проверка функционирования программной системы в целом (полностью интегрированная система), после помещения в ее аппаратную среду в соответствии со спецификацией требований к ПО;
- производство, эксплуатация и сопровождение – ПО запускается в производство. На этой фазе предусмотрены также модернизация и внесение поправок;
- приемочные испытания (на рис. не показаны) – позволяет пользователю протестировать функциональные возможности системы на соответствие исходным требованиям. После окончательного тестирования ПО и окружающее его аппаратное обеспечение становятся рабочими. После этого обеспечивается сопровождение системы.
Рис. 6. Спиральная модель

Общее
"Гибкие" (agile) методы разработки ПО появились как альтернатива формальным и "тяжеловесным" методологиям, наподобие CMM и RUP. Талантливые программисты не желают превращения разработки ПО в рутину, хотят иметь максимум свобод и обещают взамен высокую эффективность. С другой стороны, практика показывает, что "тяжеловесные" методологии в значительном количестве случаев неэффективны. Основными положениями гибких методов, закрепленных в Agile Manifesto в 2007 году являются следующее1:
· работающее ПО вместо сложной документации;
· взаимодействие с заказчиком вместо жестких контрактов;
· реакция на изменения вместо следования плану.
Фактически, гибкие методологии говорят о небольших, самоорганизующихся командах, состоящих из высококвалифицированных и энергичных людей, ориентированных на бизнес, то есть, например, разрабатывающих свой собственный продукт для выпуска его на рынок. У этого подхода есть, очевидно, свои плюсы и свои минусы.
Extreme Programming
Самым известным гибким методом является Extreme Programming (известное сокращенное название – XP). Он был создан талантливым специалистом в области программной инженерии Кентом Беком в результате его работы в 1996-1999 годах над системой контроля платежей компании "Крайслер".
Модель процесса по XP выглядит как частая последовательность выпусков (releases) продукта, столь частых, сколь это возможно. Но при этом обязательно, чтобы в выпуск входила новая целиковая функциональность. Ниже перечислены основные принципы организации процесса по XP.
1. Планирование (Planning Game), основанное на принципе, что разработка ПО является диалогом между возможностями и желаниями, при этом изменятся и то и другое.
2. Простой дизайн (Simple Design) – против избыточного проектирования.
3. Метафора (Metaphor) – суть проекта должна умещаться в 1-2 емких фразах или в некотором образе.
4. Рефакторинг (Refactoring) – процесс постоянного улучшения (упрощения) структуры ПО, необходимый в связи с добавлением новой функциональности.
5. Парное программирование (Pair Programming) – один программирует, другой думает над подходом в целом, о новых тестах, об упрощении структуры программы и т.д.
6. Коллективное владение кодом (Collective Ownership).
7. Участие заказчика в разработке (On-site Customer) – представитель заказчика входит в команду разработчика.
8. Создание и использование стандартов кодирования (Coding Standards) в проекте – при написании кода (создаются и) используются стандарты на имена идентификаторов, составление комментариев и т.д.
9. Тестирование – разработчики сами тестируют свое ПО, перемежая этот процесс с разработкой. При этом рекомендуется создавать тесты до того, как будет реализована соответствующая функциональность. Заказчик создает функциональные тесты.
10. Непрерывная интеграция. Сама разработка представляется как последовательность выпусков.
11. 40-часовая рабочая неделя.
Однако в полном объеме XP не была использована даже ее авторами и является, скорее, философией. Кроме того, известны и внедряются отдельные практики XP, как, например, парное программирование, коллективное владение кодом, и, конечно же, рефакторинг кода. Идея простого, неизбыточного дизайна проекта также оказала значительное влияние на мир разработчиков ПО.
Более практичным "гибким" методом разработки является Scrum.
Scrum
История. В 1986 японские специалисты Hirotaka Takeuchi и Ikujiro Nonaka опубликовали сообщение о новом подходе к разработке новых сервисов и продуктов (не обязательно программных). Основу подхода составляла сплоченная работа небольшой универсальной команды, которая разрабатывает проект на всех фазах. Приводилась аналогия из регби, где вся команда двигается к воротам противника как единое целое, передавая (пасуя) мяч своим игрокам как вперед, так и назад. В начале 90-х годов данный подход стал применяться в программной индустрии и обрел название Scrum (термин из регби, означающий - схватка), в 1995 году Jeff Sutherland и Ken Schwaber представили описание этого подхода на OOPSLA '95 – одной из самых авторитетных конференций в области программирования. С тех пор метод активно используется в индустрии и многократно описан в литературе. Scrum активно используется также в России.
Общее описание. Метод Scrum позволяет гибко разрабатывать проекты небольшими командами (7 человек плюс/минус 2) в ситуации изменяющихся требований. При этом процесс разработки итеративен и предоставляет большую свободу команде. Кроме того, метод очень прост – легко изучается и применяется на практике. Его схема изображена на рис. 11.1.

Рис. 11.1.
Вначале создаются требования ко всему продукту. Потом из них выбираются самые актуальные и создается план на следующую итерацию. В течение итерации планы не меняются (этим достигается относительная стабильность разработки), а сама итерация длится 2-4 недели. Она заканчивается созданием работоспособной версии продукта (рабочий продукт), которую можно предъявить заказчику, запустить и подемонстрировать, пусть и с минимальными функциональными возможностями. После этого результаты обсуждаются и требования к продукту корректируются. Это удобно делать, имея после каждой итерации продукт, который уже можно как-то использовать, показывать и обсуждать. Далее происходит планирование новой итерации и все повторяется.
Внутри итерации проектом полностью занимается команда. Она является плоской, никаких ролей Scrum не определяет. Синхронизация с менеджментом и заказчиком происходит после окончания итерации. Итерация может быть прервана лишь в особых случаях.
Роли. В Scrum есть всего три вида ролей.
Владелец продукта (Product Owner) – это менеджер проекта, который представляет в проекте интересы заказчика. В его обязанности входит разработка начальных требований к продукту (Product Backlog), своевременное их изменение, назначение приоритетов, дат поставки и пр. Важно, что он совершенно не участвует в выполнении самой итерации.
Scrum-мастера (Scrum Master) обеспечивает максимальную работоспособность и продуктивную работу команды – как выполнение Scrum-процесса, так и решение хозяйственных и административных задач. В частности, его задачей является ограждение команды от всех воздействий извне во время итерации.
Scrum-команда (Scrum Team) – группа, состоящая из пяти–девяти самостоятельных, инициативных программистов. Первой задачей команды является постановка для итерации реально достижимых и приоритетных для проекта в целом задач (на основе Project Backlog и при активном участии владельца продукта и Scrum-мастера). Второй задачей является выполнение этой задачи во что бы то ни стало, в отведенные сроки и с заявленным качеством. Важно, что команда сама участвует в постановке задачи и сама же ее выполняет. Здесь сочетается свобода и ответственность, подобно тому, как это организовано в MSF. Здесь же "просвечивает" дисциплина обязательств.
Практики. В Scrum определены следующие практики.
Sprint Planning Meeting. Проводится в начале каждого Sprint. Сначала Produсt Owner, Scrum-мастер, команда, а также представители заказчика и пр. заинтересованные лица определяют, какие требования из Project Backlog наиболее приоритетные и их следует реализовывать в рамках данного Sprint. Формируется Sprint Backlog. Далее Scrum-мастер и Scrum- команда определяют то, как именно будут достигнуты определенные выше цели из Sprint Backlog. Для каждого элемента Sprint Backlog определяется список задач и оценивается их трудоемкость.
Daily Scrum Meeting – пятнадцатиминутное каждодневное совещание, целью которого является достичь понимания того, что произошло со времени предыдущего совещания, скорректировать рабочий план сообразно реалиям сегодняшнего дня и обозначить пути решения существующих проблем. Каждый участник Scrum-команды отвечает на три вопроса: что я сделал со времени предыдущей встречи, мои проблемы, что я буду делать до следующей встречи? В этом совещании может принимать участие любое заинтересованное лицо, но только участники Scrum-команды имеют право принимать решения. Правило обосновано тем, что они давали обязательство реализовать цель итерации, и только это дает уверенность в том, что она будет достигнута. На них лежит ответственность за их собственные слова, и, если кто-то со стороны вмешивается и принимает решения за них, тем самым он снимает ответственность за результат с участников команды. Такие встречи поддерживают дисциплину обязательств в Scrum-команде, способствуют удержанию фокуса на целях итерации, помогают решать проблемы "в зародыше". Обычно такие совещания проводятся стоя, в течение 15-20 минут.
Sprint Review Meeting. Проводится в конце каждого Sprint. Сначала Scrum- команда демонстрирует Product Owner сделанную в течение Sprint работу, а тот в свою очередь ведет эту часть митинга и может пригласить к участию всех заинтересованных представителей заказчика. Product Owner определяет, какие требования из Sprint Backlog были выполнены, и обсуждает с командой и заказчиками, как лучше расставить приоритеты в Sprint Backlog для следующей итерации. Во второй части митинга производится анализ прошедшего спринта, который ведет Scrum-мастер. Scrum- команда анализирует в последнем Sprint положительные и отрицательные моменты совместной работы, делает выводы и принимает важные для дальнейшей работы решения. Scrum- команда также ищет пути для увеличения эффективности дальнейшей работы. Затем цикл повторяется.

Рис. 11.2.
«Agile Model» (гибкая методология разработки)
В «гибкой» методологии разработки после каждой итерации заказчик может наблюдать результат и понимать, удовлетворяет он его или нет. Это одно из преимуществ гибкой модели. К ее недостаткам относят то, что из-за отсутствия конкретных формулировок результатов сложно оценить трудозатраты и стоимость, требуемые на разработку. Экстремальное программирование (XP) является одним из наиболее известных применений гибкой модели на практике.
В основе такого типа — непродолжительные ежедневные встречи — «Scrum» и регулярно повторяющиеся собрания (раз в неделю, раз в две недели или раз в месяц), которые называются «Sprint». На ежедневных совещаниях участники команды обсуждают:
· отчёт о проделанной работе с момента последнего Scrum’a;
· список задач, которые сотрудник должен выполнить до следующего собрания;
· затруднения, возникшие в ходе работы.
Методология подходит для больших или нацеленных на длительный жизненный цикл проектов, постоянно адаптируемых к условиям рынка. Соответственно, в процессе реализации требования изменяются. Стоит вспомнить класс творческих людей, которым свойственно генерировать, выдавать и опробовать новые идеи еженедельно или даже ежедневно. Гибкая разработка лучше всего подходит для этого психотипа руководителей. Внутренние стартапы компании мы разрабатываем по Agile. Примером клиентских проектов является Электронная Система Медицинских Осмотров, созданная для проведения массовых медосмотров в считанные минуты. Во втором абзаце этого отзыва, наши американские партнеры описали очень важную вещь, принципиальную для успеха на Agile.
Когда использовать Agile?
Когда потребности пользователей постоянно меняются в динамическом бизнесе.
· Изменения на Agile реализуются за меньшую цену из-за частых инкрементов.
· В отличие от модели водопада, в гибкой модели для старта проекта достаточно лишь небольшого планирования.
· 
Agile
- Внедрение нового функционала и внесение необходимых корректировок интегрированы в сам процесс разработки, что позволяет делать это на любом из этапов создания продукта. Это повышает конкурентные преимущества готового программного обеспечения;
- Весь проект – это набор прозрачных итераций, завершающихся за короткие промежутки времени;
- За счет существующего механизма внесения корректировок уменьшаются риски проекта;
- Первая версия ПО выходит довольно быстро.
Waterfall
- Прозрачная и интуитивно понятная структура работы, которая подходит для опытных команд;
- Высокое качество и детализации всей документации;
- Каскадная модель позволяет легко отслеживать ресурсы, риски и время, потраченное на реализацию проекта;
- Поставленные задачи максимально стабильны на всем протяжении разработки.
Agile
- Отсутствие возможности рассчитать полную сумму, затраченную на создание нового программного обеспечения, в связи с постоянно меняющимися требованиями в ходе реализации;
- Так как Agile больше всего напоминает философию, все участники проекта должны полностью погрузиться в нее, что часто бывает крайне тяжело;
- Члены команды должны быть опытными, высококвалифицированными специалистами; они должны работать на удовлетворение потребностей клиента;
- Возникновение новых требований может вступить в конфликт с существующей структурой и функционалом;
- Возможность постоянного внесения корректировок может привести к тому, что проект перейдет в категорию бесконечных.
Waterfall
- Определение в начальном этапе всех требований приводит к тому, что проект перестает быть гибким;
- Проект требует большего объема ресурсов и сроков;
- Заказчик увидит результаты работы проектной команды в самом конце этапа разработки;
- Полное отсутствие коммуникативного взаимодействия между этапами реализации.
Системы версионного контроля. Локальные, централизованные и децентрализованные. Управление изменениями и версиями. Ветвления (branches), метки (labels, tags) и объединение (merge). Пример использования в курсовом проекте.
Система контроля версий (Version Control System, VCS) представляет собой программное обеспечение, которое позволяет отслеживать изменения в документах, при необходимости производить их откат, определять, кто и когда внес исправления и т.п. В статье рассмотрены виды VCS, принципы их работы, а также приведены примеры программных продуктов.
Что такое система контроля версий?
Наверное, всем знакома ситуация, когда при работе над проектом, возникает необходимость внести изменения, но при этом нужно сохранить работоспособный вариант, в таком случае, как правило, создается новая папка, название которой скорее всего будет “Новая папка” с дополнением в виде даты или небольшой пометки, в нее копируется рабочая версия проекта и уже с ним производится работа. Со временем количество таких папок может значительно возрасти, что создает трудности в вопросе отката на предыдущие версии, отслеживании изменений и т.п. Эта ситуация значительно ухудшается, когда над проектом работает несколько человек.
Для решения таких проблем как раз и используется система контроля версий, она позволяет комфортно работать над проектом как индивидуально, так в коллективе. VCS отслеживает изменения в файлах, предоставляет возможности для создания новых и слияние существующих ветвей проекта, производит контроль доступа пользователей к проекту, позволяет откатывать исправления и определять кто, когда и какие изменения вносил в проект. Основным понятием VCS является репозиторий (repository) – специальное хранилище файлов и папок проекта, изменения в которых отслеживаются. В распоряжении разработчика имеется так называемая “рабочая копия” (working copy) проекта, с которой он непосредственно работает. Рабочую копию необходимо периодически синхронизировать с репозиторием, эта операция предполагает отправку в него изменений, которые пользователь внес в свою рабочую копию (такая операция называется commit) и актуализацию рабочей копии, в процессе которой к пользователю загружается последняя версия из репозитория (этот процесс носит название update).
Централизованные и распределенные системы контроля версий
Системы контроля версий можно разделить на две группы: распределенные и централизованные.
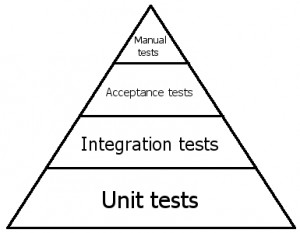
Тестирование кода разработчиками: модульное тестирование (unit testing, Test Driven Development - TDD). Использование Mock-объектов. Покрытие кода тестами. Пример использования в курсовом проекте
Модульное тестирование, или юнит-тестирование (англ. unit testing) — процесс в программировании, позволяющий проверить на корректность отдельные модули исходного кода программы.
Идея состоит в том, чтобы писать тесты для каждой нетривиальной функции или метода. Это позволяет достаточно быстро проверить, не привело ли очередное изменение кода к регрессии, то есть к появлению ошибок в уже оттестированных местах программы, а также облегчает обнаружение и устранение таких ошибок.
Не нужно писать тесты, если
Вы делаете простой сайт-визитку из 5 статических html-страниц и с одной формой отправки письма. На этом заказчик, скорее всего, успокоится, ничего большего ему не нужно. Здесь нет никакой особенной логики, быстрее просто все проверить «руками»
Вы занимаетесь рекламным сайтом/простыми флеш-играми или баннерами – сложная верстка/анимация или большой объем статики. Никакой логики нет, только представление
Вы делаете проект для выставки. Срок – от двух недель до месяца, ваша система – комбинация железа и софта, в начале проекта не до конца известно, что именно должно получиться в конце. Софт будет работать 1-2 дня на выставке
Вы всегда пишете код без ошибок, обладаете идеальной памятью и даром предвидения. Ваш код настолько крут, что изменяет себя сам, вслед за требованиями клиента. Иногда код объясняет клиенту, что его требования — гов не нужно реализовывать
Преимущества
Цель модульного тестирования — изолировать отдельные части программы и показать, что по отдельности эти части работоспособны.
Этот тип тестирования обычно выполняется программистами.
Поощрение изменений
Модульное тестирование позже позволяет программистам проводить рефакторинг, будучи уверенными, что модуль по-прежнему работает корректно (регрессионное тестирование). Это поощряет программистов к изменениям кода, поскольку достаточно легко проверить, что код работает и после изменений.
Упрощение интеграции[править | править вики-текст]
Модульное тестирование помогает устранить сомнения по поводу отдельных модулей и может быть использовано для подхода к тестированию «снизу вверх»: сначала тестируя отдельные части программы, а затем программу в целом.
Документирование кода[править | править вики-текст]
Модульные тесты можно рассматривать как «живой документ» для тестируемого класса. Клиенты, которые не знают, как использовать данный класс, могут использовать юнит-тест в качестве примера.
Отделение интерфейса от реализации[править | править вики-текст]
Поскольку некоторые классы могут использовать другие классы, тестирование отдельного класса часто распространяется на связанные с ним. Например, класс пользуется базой данных; в ходе написания теста программист обнаруживает, что тесту приходится взаимодействовать с базой. Это ошибка, поскольку тест не должен выходить за границу класса. В результате разработчик абстрагируется от соединения с базой данных и реализует этот интерфейс, используя свой собственный mock-объект. Это приводит к менее связанному коду, минимизируя зависимости в системе.
Использование Mock-объектов
Еще один длинный, но, надеюсь, полезный пост:) Пригодится тем, кто хочет начать писать unit-тесты, уже пишет их и хочет увеличить свои познания, и даже тем, кто тесты не пишет, но хочет быть в курсе того, что же это за зверь такой страшный - unit-тестирование.
Как я уже писал в предыдущем посте об unit-тестировании, иногда, для того, чтобы протестировать какой-нибудь кусок кода (например, метод), нужно довольно сильно постараться. Причем, это еще не тот вид извращений, когда вы тестируете методы UI, проблемы могут начаться с тестирования бизнес-логики. Дело в том, что очень часто тестируемый метод может вызывать методы других классов, которые в данном случае тестировать не нужно. Unit-тест потому и называется модульным, что тестирует отдельные модули, а не их взаимодействие. Причем, чем меньше тестируемый модуль – тем лучше с точки зрения будущей поддержки тестов. Для тестирования взаимодействия используются интеграционные тесты, где вы уже тестируете скорее полные use cases, а не отдельную функциональность.
Однако наши классы очень часто используют другие классы в своей работе. Например, слой бизнес логики (Business Logic layer) часто работает с другими объектами бизнес логики или обращается к слою доступа к данным (Data Access layer). В трехслойной архитектуре веб-приложений это вообще постоянный процесс: Presentation layer обращается к Business Logic layer, тот, в свою очередь, к Data Access layer, а Data Access layer – к базе данных. Как же тестировать подобный код, если вызов одного метода влечет за собой цепочку вплоть до базы данных?
В таких случаях на помощь приходят так называемые mock-объекты, предназначенные для симуляции поведения реальных объектов во время тестирования. Вообще, понятие mock-объект достаточно широко: оно может, с одной стороны, обозначать любые тест-дублеры (Test Doubles) или конкретный вид этих дублеров – mock-объекты. Я постараюсь использовать этот термин исключительно во втором случае, чтобы никого не путать, и не запутаться самому:)
Понятие тест-дублеров введено неким Gerard Meszaros в своей книге «XUnit Test Patterns» и теперь с подачи небезызвестного Мартина Фаулера эта терминология набирает популярность. Джерард и Мартин делят все тест-дублеры на 4 группы:
· Dummy – пустые объекты, которые передаются в вызываемые внутренние методы, но не используются. Предназначены лишь для заполнения параметров методов.
· Fake – объекты, имеющие работающие реализации, но в таком виде, который делает их неподходящими для production-кода (например, In Memory Database).
· Stub – объекты, которые предоставляют заранее заготовленные ответы на вызовы во время выполнения теста и обычно не отвечающие ни на какие другие вызовы, которые не требуются в тесте. Также могут запоминать какую-то дополнительную информацию о количестве вызовов, параметрах и возвращать их потом тесту для проверки.
· Mock – объекты, которые заменяют реальный объект в условиях теста и позволяют проверять вызовы своих членов как часть системы или unit-теста. Содержат заранее запрограммированные ожидания вызовов, которые они ожидают получить. Применяются в основном для т.н. interaction (behavioral) testing.
Поначалу эта классификация выглядит очень непонятной. Но если вдуматься, то можно разобраться, в чем заключается отличие между теми и иными типами объектов. Предположим, что вам нужно протестировать метод Foo() класса TestFoo, который делает вызов другого метода Bar() класса TestBar. Предположим, что метод Bar() принимает какой-нибудь объект класса Bla в качестве параметра и потом ничего особого с ним не делает. В таком случае имеет смысл создать пустой объект Bla, передать его в класс TestFoo (сделать это можно при помощи широко применяемого паттерна Dependency Injection или каким-либо другим приемлемым способом), а затем уже Foo() при тестировании сам вызовет метод TestBar.Bar() с переданным пустым объектом. Это и есть иллюстрация использования dummy-объекта в unit-тестировании.
К сожалению, редко можно обойтись простыми dummy-объектами. Иногда метод Bar() выполняет какие-то действия с ним (допустим, Bar() сохраняет данные в базу или вызывает веб-сервис, а мы этого не хотим). В таких случаях наш объект класса TestBar должен быть уже не таким глупым. Мы должны научить его в ответ на запрос сохранения данных просто выполнить какой-то простой код (допустим, сохранение во внутреннюю коллекцию). В таких случаях можно выделить интерфейс ITestBar, который будет реализовывать класс TestBar и наш дополнительный класс FakeBar. При unit-тестировании мы просто будем создавать объект класса FakeBar и передавать его в класс с методом Foo() через интерфейс. Естественно, при этом класс Bar будет по-прежнему создаваться в реальном приложении, а FakeBar будет использован лишь в тестировании. Это иллюстрация fake-объекта.
Со stub- и mock-объектами все немного сложнее, хотя и здесь есть от чего отталкиваться. Stub-объекты (стабы) – это типичные заглушки. Они ничего полезного не делают и умеют лишь возвращать определенные данные в ответ на вызовы своих методов. В нашем примере стаб бы подменял класс TestBar и в ответ на вызов Bar() просто бы возвращал какие-то левые данные. При этом внутренняя реализация реального метода Bar() бы просто не вызывалась. Реализуется этот подход через интерфейс и создание дополнительного класса StubBar, либо просто через создание StubBar, который является унаследованным от TestBar. В принципе, реализация очень похожа на fake-объект с тем лишь исключением, что стаб ничего полезного, кроме постоянного возвращения каких-то константных данных не требует. Типичная заглушка. Стабам позволяется лишь сохранять у себя внутри какие-нибудь данные, удостоверяющие, что вызовы были произведены или содержащие копии переданных параметров, которые затем может проверить тест.
Mock-объект (мок), в свою очередь, является, грубо говоря, более умной реализацией заглушки, которая уже не просто возвращает предустановленные данные, но еще и записывает все вызовы, которые проходят через нее, чтобы вы могли дальше в unit-тесте проверить, что именно эти методы вот этих вот классов были вызваны тестируемым методом и именно в такой последовательности (хотя учет последовательности и строгость проверки, в принципе, настраиваемая вещь). То есть мы можемсделать мок MockFoo, который будет каким-то образом вызывать реальный метод Foo() класса TestFoo и затем смотреть, какие вызовы тот сделал. Или сделать мок MockBar и затем проверить, что при вызове метода Foo() реально произошел вызов метода Bar() с нужными нам параметрами. Не совсем понятно?:) Вам нужно знать еще кое-что о unit-тестировании, чтобы понять разницу.
Unit-тестирование условно делится на два подхода:
· state-based testing, в котором мы тестируем состояние объекта после прохождения unit-теста
· interaction (behavioral) testing, в котором мы тестируем взаимодействие между объектами, поведение тестируемого метода, последовательность вызовов методов и их параметры и т.д.
То есть в state-based testing нас интересует в основном, в какое состояние перешел объект после вызова тестируемого метода, или, что более часто встречается, что в реальности вернул наш метод и правилен ли этот результат. Подобные проверки проводятся при помощи вызова методов класса Assert различных unit-тест фреймворков: Assert.AreEqual(), Assert.That(), Assert.IsNull() и т.д.
В interaction testing нас инт







