Классификация. Классификацию можно использовать для получения представления о типе покупателей, товаров или объектов, описывая несколько атрибутов для идентификации определенного класса. Например, автомобили легко классифицировать по типу (седан, внедорожник, кабриолет), определив различные атрибуты (количество мест, форма кузова, ведущие колеса). Изучая новый автомобиль, можно отнести его к определенному классу, сравнивая атрибуты с известным определением. Те же принципы можно применить и к покупателям, например, классифицируя их по возрасту и социальной группе.
Кроме того, классификацию можно использовать в качестве входных данных для других методов. Например, для определения классификации можно применять деревья принятия решений.
Прогнозирование ― это широкая тема, которая простирается от предсказания отказов компонентов оборудования до выявления мошенничества и даже прогнозирования прибыли компании. В сочетании с другими методами интеллектуального анализа данных прогнозирование предполагает анализ тенденций, классификацию, сопоставление с моделью и отношения. Анализируя прошлые события или экземпляры, можно предсказывать будущее.
Например, используя данные по авторизации кредитных карт, можно объединить анализ дерева решений прошлых транзакций человека с классификацией и сопоставлением с историческими моделями в целях выявления мошеннических транзакций. Если покупка авиабилетов в США совпадает с транзакциями в США, то вполне вероятно, что эти транзакции подлинны.
Деревья решений.
Метод деревьев решений (decision trees) является одним из наиболее популярных методов решения задач классификации и прогнозирования. Иногда этот метод Data Mining также называют деревьями решающих правил, деревьями классификации и регрессии.
Как видно из последнего названия, при помощи данного метода решаются задачи классификации и прогнозирования.
Если зависимая, т.е. целевая переменная принимает дискретные значения, при помощи метода дерева решений решается задача классификации.
Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает зависимость этой переменной от независимых переменных, т.е. решает задачу численного прогнозирования.
В наиболее простом виде дерево решений - это способ представления правил в иерархической, последовательной структуре. Основа такой структуры - ответы "Да" или "Нет" на ряд вопросов.
На рис. 9.1 приведен пример дерева решений, задача которого - ответить на вопрос: "Играть ли в гольф?" Чтобы решить задачу, т.е. принять решение, играть ли в гольф, следует отнести текущую ситуацию к одному из известных классов (в данном случае - "играть" или "не играть"). Для этого требуется ответить на ряд вопросов, которые находятся в узлах этого дерева, начиная с его корня.
Первый узел нашего дерева "Солнечно?" является узлом проверки, т.е. условием. При положительном ответе на вопрос осуществляется переход к левой части дерева, называемой левой ветвью, при отрицательном - к правой части дерева. Таким образом, внутренний узел дерева является узлом проверки определенного условия. Далее идет следующий вопрос и т.д., пока не будет достигнут конечный узел дерева, являющийся узлом решения. Для нашего дерева существует два типа конечного узла: "играть" и "не играть" в гольф.
В результате прохождения от корня дерева (иногда называемого корневой вершиной) до его вершины решается задача классификации, т.е. выбирается один из классов - "играть" и "не играть" в гольф.
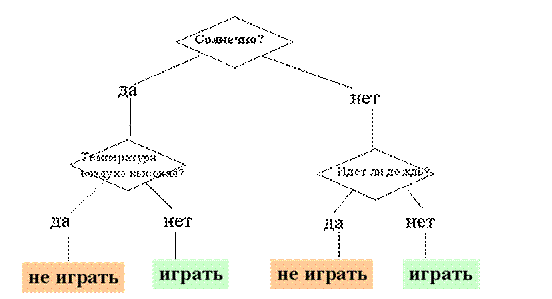
Рисунок 5- Дерево решений "Играть ли в гольф?"
Интуитивность деревьев решений. Классификационная модель, представленная в виде дерева решений, является интуитивной и упрощает понимание решаемой задачи. Результат работы алгоритмов конструирования деревьев решений, в отличие, например, от нейронных сетей, представляющих собой "черные ящики", легко интерпретируется пользователем. Это свойство деревьев решений не только важно при отнесении к определенному классу нового объекта, но и полезно при интерпретации модели классификации в целом. Дерево решений позволяет понять и объяснить, почему конкретный объект относится к тому или иному классу.
Алгоритм конструирования дерева решений не требует от пользователя выбора входных атрибутов (независимых переменных). На вход алгоритма можно подавать все существующие атрибуты, алгоритм сам выберет наиболее значимые среди них, и только они будут использованы для построения дерева. В сравнении, например, с нейронными сетями, это значительно облегчает пользователю работу, поскольку в нейронных сетях выбор количества входных атрибутов существенно влияет на время обучения.
Точность моделей, созданных при помощи деревьев решений, сопоставима с другими методами построения классификационных моделей (статистические методы, нейронные сети).
Разработан ряд масштабируемых алгоритмов, которые могут быть использованы для построения деревьев решения на сверхбольших базах данных; масштабируемость здесь означает, что с ростом числа примеров или записей базы данных время, затрачиваемое на обучение, т.е. построение деревьев решений, растет линейно. Примеры таких алгоритмов: SLIQ, SPRINT.
Обработка больших объёмов данных.
Термин «большие данные» — это калька англоязычного термина. Большие данные не имеют строгого определения. Нельзя провести четкую границу — это 10 терабайт или 10 мегабайт? Само название очень субъективно. Слово «большое» — это как «один, два, много» у первобытных племен.
Однако есть устоявшееся мнение, что большие данные — это совокупность технологий, которые призваны совершать три операции. Во-первых, обрабатывать бо́льшие по сравнению со «стандартными» сценариями объемы данных. Во-вторых, уметь работать с быстро поступающими данными в очень больших объемах. То есть данных не просто много, а их постоянно становится все больше и больше. В-третьих, они должны уметь работать со структурированными и плохо структурированными данными параллельно в разных аспектах. Большие данные предполагают, что на вход алгоритмы получают поток не всегда структурированной информации и что из него можно извлечь больше чем одну идею.
Появление больших данных в публичном пространстве было связано с тем, что эти данные затронули практически всех людей, а не только научное сообщество, где подобные задачи решаются давно. В публичную сферу технологии Big Data вышли, когда речь стала идти о вполне конкретном числе — числе жителей планеты. 7 миллиардов, собирающихся в социальных сетях и других проектах, которые агрегируют людей. YouTube, Facebook, ВКонтакте, где количество людей измеряется миллиардами, а количество операций, которые они совершают одновременно, огромно. Поток данных в этом случае — это пользовательские действия. Например, данные того же хостинга YouTube, которые переливаются по сети в обе стороны. Под обработкой понимается не только интерпретация, но и возможность правильно обработать каждое из этих действий, то есть поместить его в нужное место и сделать так, чтобы эти данные каждому пользователю были доступны быстро, поскольку социальные сети не терпят ожидания.
Многое из того, что касается больших данных, подходов, которые используются для их анализа, на самом деле существует довольно давно. Например, обработка изображений с камер наблюдения, когда мы говорим не об одной картинке, а о потоке данных. Или навигация роботов. Все это существует десятки лет, просто сейчас задачи по обработке данных затронули гораздо большее количество людей и идей.
Многие разработчики привыкли работать со статическими объектами и мыслить категориями состояний. В больших данных парадигма другая. Ты должен уметь работать с непрекращающимся потоком данных, и это интересная задача. Она затрагивает все больше и больше областей.
В нашей жизни все больше аппаратных средств и программ начинают генерировать большое количество данных — например, «интернет вещей».
Вещи уже сейчас генерируют огромные потоки информации. Полицейская система «Поток» отправляет со всех камер информацию и позволяет находить машины по этим данным. Все больше входят в моду фитнес-браслеты, GPS-трекеры и другие вещи, обслуживающие задачи человека и бизнеса.







