Хотя терминология нотации IDEF1X практически совпадает с терминологией нотации IDEF1, существует ряд фундаментальных отличий в теоретических концепциях этих нотаций.
Сущность в IDEF1X описывает совокупность или набор экземпляров, похожих по свойствам, но однозначно отличаемых друх от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности.
Таким образом, сущность в IDEF1X описывает конкретный набор экземпляров реального мира.
В отличие от этого в нотации IDEF1 сущность представляет собой абстрактный набор информационных отображений реального мира.
Например, сущность "СОТРУДНИК" в нотации IDEF1X представляет собой любого из сотрудников предприятия, а один из сотрудников, Иванов Петр Сергеевич, является конкретной реализацией этой сущности.
В примере, приведенном на рис. 1, каждый экземпляр сущности «СОТРУДНИК» содержит следующую информацию: ID сотрудника, имя сотрудника, адрес сотрудника и т.п. В IDEF1X-модели эти свойства называются атрибутами сущности. Каждый атрибут содержит только часть информации о сущности.
Связи в IDEF1X представляют собой ссылки, соединения и ассоциации между сущностями. Связи это суть глаголы, которые показывают, как соотносятся сущности между собой.
Ниже приведены примеры связи между сущностями:
· Отдел <состоит из> нескольких Сотрудников
· Самолет <перевозит> нескольких Пассажиров.
· Сотрудник <пишет> разные Отчеты.
Во всех перечисленных примерах взаимосвязи между сущностями соответствуют схеме один ко многим. Это означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности. Причем первая сущность называется родительской, а вторая - дочерней.
В приведенных примерах глаголы заключены в угловые скобки. Связи отображаются в виде линии между двумя сущностями с точкой на одном конце и глагольной фразой, отображаемой над линией.
На рис. 5 представлена диаграмма связи между сущностями «Сотрудник» и «Отдел».
Отношение «многие ко многим» используется на начальной стадии разработки диаграммы, например, в диаграмме зависимости сущностей, и отображаются в IDEF1X в виде сплошной линии с точками на обоих концах. Иногда отношение «многие ко многим» на ранних стадиях моделирования идентифицируется неправильно, на самом деле представляя два или несколько случаев отношений «один-ко-многим» между связанными сущностями.
В случае необходимости хранения дополнительных сведений о связи «многие-ко-многим», например, даты или комментария, такая связь должна быть заменена дополнительной сущностью, содержащей эти сведения.
Отношение «многие ко многим» может скрыть другие правила или ограничения, поэтому такое отношение должно быть полностью исследовано на одном из этапов моделирования.
Таким образом, сущность представляет собой класс однотипных объектов, информация о которых должна быть учтена в модели. Соответственно, сущность может быть зависима или независима от идентификаторов.
Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями.
Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности.
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Экземпляр сущности - это конкретный представитель данной сущности. Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь свойства, уникальные для каждого экземпляра этой сущности.
Каждая сущность в модели изображается в виде прямоугольника с наименованием: описывается в диаграмме IDEF1X графическим объектом в виде прямоугольника.
На рис.6 приведен пример IDEF1X-диаграммы. Каждый прямоугольник, отображающий собой сущность, разделяется горизонтальной линией на часть, в которой расположены ключевые поля и часть, где расположены неключевые поля. Верхняя часть называется ключевой областью, а нижняя часть областью данных.

Рис. 5. Диаграмма связи.
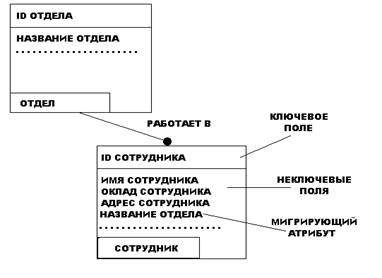
Рис. 6. Пример IDEF1X-диаграммы.
Ключевая область объекта СОТРУДНИК содержит поле "Уникальный идентификатор сотрудника", в области данных находятся поля "Имя сотрудника", "Адрес сотрудника", "Телефон сотрудника" и т.д.
Ключевая область содержит первичный ключ для сущности. Первичный ключ - это набор атрибутов, выбранных для идентификации уникальных экземпляров сущности. Атрибуты первичного ключа располагаются над линией в ключевой области.
Неключевой атрибут - это атрибут, который не был выбран ключевым. Неключевые атрибуты располагаются на модели в области данных.
При создании сущности в IDEF1X-модели одним из главных вопросов является способ идентификации уникальной записи. Уникальная идентификация каждой записи необходима для того, чтобы правильно создать логическую модель данных. Для сущности в нотации IDEF1X должны быть определены ключевые атрибуты.
Выбор первичного ключа для сущности является важным моментом разработки модели. В качестве первичных ключей могут быть использованы несколько атрибутов или групп атрибутов. Атрибуты, которые могут быть выбраны первичными ключами, называются кандидатами в ключевые атрибуты (потенциальные атрибуты). Кандидаты в ключи должны уникально идентифицировать каждую запись сущности. В соответствии с этим, ни одна из частей ключа не может быть NULL, не заполненной или отсутствующей.
Например, для того, чтобы корректно использовать сущность «СОТРУДНИК» в IDEF1X-модели данных необходимо иметь возможность уникально идентифицировать записи. Правила, по которым выбирается первичный ключ из списка предполагаемых ключей устанавливают, что атрибуты и группы атрибутов должны:
· уникальным образом идентифицировать экземпляр сущности.
· не использовать NULL значений.
· не изменяться со временем.
Экземпляр идентифицируется при помощи ключа. При изменении ключа, соответственно меняется экземпляр.
Ключ должен быть короткими, что удобно для индексирования и получения данных.
Если нужно использовать ключ, являющийся комбинацией ключей из других сущностей, то каждая из частей ключа должна соответствовать приведенным правилам.
Для наглядного представления о том, как целесообразно выбирать первичные ключи, приведем пример выбора первичного ключа для сущности "СОТРУДНИК":
Атрибут "ID сотрудника" является потенциальным ключом, так как он уникален для всех экземпляров сущности «СОТРУДНИК».
Атрибут "Имя сотрудника" не очень подходит для потенциального ключа, так как среди служащих на предприятии может быть, к примеру, два человека с одинаковой фамилией.
Атрибут "Номер страхового полиса сотрудника" является уникальным, но сотрудник в принципе может не иметь полиса.
Комбинация атрибутов "имя сотрудника" и "дата рождения сотрудника" может оказаться удачной и стать искомым потенциальным ключом.
После проведенного анализа можно назвать два потенциальных ключа - первый "Номер сотрудника" и комбинация, включающая поля "имя сотрудника" и "Дата рождения сотрудника". Так как атрибут "Номер сотрудника" имеет самые короткие и уникальные значения, то он лучше других подходит для первичного ключа.
При выборе первичного ключа для сущности, разработчики модели часто используют дополнительный (суррогатный) ключ, т.е. произвольный номер, который уникальным образом определяет запись в сущности. Атрибут "Номер сотрудника" является примером суррогатного ключа.
Суррогатный ключ лучше всего подходит на роль первичного ключа потому, что является коротким и быстрее всего идентифицирует экземпляры в объекте. Кроме того, суррогатные ключи могут автоматически генерироваться системой так, чтобы нумерация была сплошной, т.е. без пропусков.
Потенциальные ключи, которые не выбраны первичными, могут быть использованы в качестве вторичных или альтернативных ключей. С помощью альтернативных ключей часто отображают различные индексы доступа к данным в конечной реализации реляционной базы.
Если сущности в IDEF1X-диаграмме связаны, связь передает ключ (или набор ключевых атрибутов) дочерней сущности. Эти атрибуты называются внешними ключами. Внешние ключи определяются как атрибуты первичных ключей родительского объекта, переданные дочернему объекту через их связь.
Передаваемые атрибуты называются мигрирующими.
При разработке модели встречаются сущности, уникальность которых зависит от значений атрибута внешнего ключа. Для этих сущностей (для уникального определения каждой сущности) внешний ключ должен быть частью первичного ключа дочернего объекта.
Дочерняя сущность, уникальность которой зависит от атрибута внешнего ключа, называется зависимой сущностью.
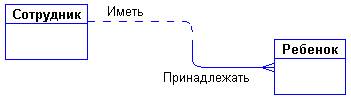
Рис. 7. Пример графического изображения связи между сущностями.

Рис. 8. Типы связей.
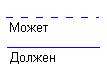
Рис. 9. Модальность связи.
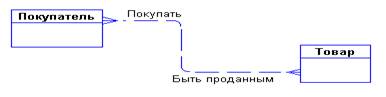
Рис. 10. Вариант диаграммы для сбытового подразделения.
В примере на рис.5 сущность «СОТРУДНИК» является зависимой сущностью потому, что его идентификация зависит от сущности «ОТДЕЛ». В обозначениях IDEF1X зависимые сущности представлены в виде закругленных прямоугольников.
Зависимые сущности далее классифицируются на сущности, которые не могут существовать без родительской сущности и сущности, которые не могут быть идентифицированы без использования ключа родителя (сущности, зависящие от идентификации). Сущность «СОТРУДНИК» принадлежит ко второму типу зависимых сущностей, так как сотрудники могут существовать и без отдела.
Напротив, существуют ситуации, в которых одна сущность зависит от существования другой сущности.
Рассмотрим две сущности: «ЗАПРОС», используемый для отслеживания запросов покупателей, и «ПОЗИЦИЯ ЗАПРОСА», который отслеживает отдельные элементы в сущности «ЗАПРОС». Связь между этими двумя сущностями может быть выражена в следующем виде:
ЗАПРОС <содержит> один или несколько ПОЗИЦИЙ ЗАПРОСА.
В этом случае «ПОЗИЦИЯ ЗАПРОСА» зависит от существования «ЗАПРОСА».
Сущности, не зависящие при идентификации от других объектов в модели, называются независимыми сущностями. В вышеописанном примере сущность «ОТДЕЛ» является независимой. В IDEF1X независимые сущности представлены в виде прямоугольников.
Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою.
Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей:
- каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка;
- каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка;
- каждый экземпляр сущности-родителя должен иметь не более одного связанного с ним экземпляра сущности-потомка;
- каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка.
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае - неидентифицирующей.
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности (см рис.7).
Каждая связь имеет два конца и одно или два наименования. Наименование выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Связь может принадлежать к одному из следующих типов:
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней.
Связь типа многие-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи многие-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Условные обозначения для связи каждого типа приведены на рис.8.
Каждая связь может характеризоваться одной из следующих модальностей связи.
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Кроме того, связь может иметь разную модальность с разных концов (рис. 9).
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
<Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>.
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на рис. 7 читается так:
Слева направо: "каждый сотрудник может иметь несколько детей".
Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".
2.3. Уровни представления данных. Этапы проектирования
Ситуация реального проекта обследования предприятияхарактеризуется в первую очередьсложностью выделения и формализации процессов, описания форматов данных.
Принята следующая классификация уровней представления данных:
1. Логический уровень соответствует такому взгляду на данные, при котором они представляются так, как выглядят в реальном мире, и могут называться так, как они называются в реальном мире, например "Постоянный клиент", "Отдел" или "Фамилия сотрудника". Объекты модели, представляемые на логическом уровне, называются сущностями и атрибутами. Логическая модель данных может быть построена на основе другой логической модели, например на основе модели процессов. Логическая модель данных является универсальной и никак не связана с конкретной реализацией СУБД.
2. Физический уровень представления данных, зависит от конкретной СУБД, фактически являясь отображением системного каталога. В физической модели содержится информация обо всех объектах БД Поскольку стандартов на объекты БД не существует (например, нет стандарта на типы данных), физическая модель зависит от конкретной реализации СУБД. Следовательно, одной и той же логической модели могут соответствовать несколько разных физических моделей. Если в логической модели не имеет значения, какой конкретно тип данных имеет атрибут, то в физической модели важно описать всю информацию о конкретных физических объектах - таблицах, колонках, индексах, процедурах и т. д
3. Уровень документирование модели. Многие СУБД имеют ограничение на именование объектов (например, ограничение на длину имени таблицы или запрет использования специальных символов - пробела и т. п.). Зачастую разработчики имеют дело с нелокализованными версиями СУБД. Это означает, что объекты БД могут называться короткими словами, только латинскими символами и без использования специальных символов (т. е. нельзя назвать таблицу предложением - только одним словом).
Кроме того, проектировщики БД нередко злоупотребляют "техническими" наименованиями, в результате таблица и колонки получают наименования типа RTD_324 или CUST_A12 и т. д. Полученную в результате структуру могут понять только специалисты (а чаще всего только авторы модели), ее невозможно обсуждать с экспертами предметной области.
Разделение модели на логическую и физическую позволяет решить проблему анализа группой специалистов. На физическом уровне объекты БД могут называться так, как того требуют ограничения СУБД. На логическом уровне можно этим объектам дать синонимы - имена более понятные неспециалистам, в том числе на кириллице и с использованием специальных символов.
Например, таблице CUST_A12 может соответствовать сущность «Постоянный клиент». Такое соответствие позволяет лучше документировать модель и дает возможность обсуждать структуру данных с экспертами предметной области.
Создание модели данных, как правило, начинается с создания логической модели. После описания логической модели, проектировщик может выбрать необходимую СУБД и применить информационную среду автоматической генерации физической модели, например Design IDEF, Erwin или др. На основе физической модели в среде может быть выполнена генерация системного каталога СУБД или соответствующего SQL-скрипта. Этот процесс называется прямым проектированием (Forward Engineering).
Тем самым достигается масштабируемость - создав одну логическую модель данных, можно провести генерацию физической модели для поддерживаемой средой моделирования СУБД.
С другой стороны, среда моделирования дает возможность по содержимому системного каталога или SQL-скрипту воссоздать физическую и логическую модель данных (Reverse Engineering).
На основе полученной логической модели данных можно выполнить генерацию физической модели для другой СУБД и затем провести генерацию системного каталога для этой СУБД.
Следовательно, информационное моделирование в принципе позволяет решить задачу переноса структуры данных с одного сервера на другой. Например, можно перенести структуру данных с Oracle на Informix (или наоборот) или перенести структуру dbf-файлов в реляционную СУБД, тем самым облегчив решение по переходу от файл-серверной к клиент-серверной информационной системе.
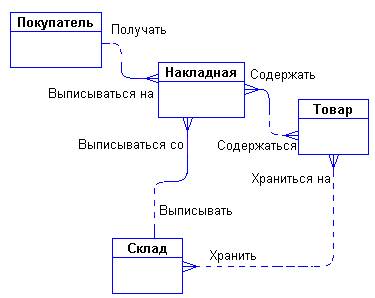
Рис. 11. Уточненная диаграмма для сбытового подразделения.
Заметим, что формальный перенос структуры "плоских" таблиц на реляционную СУБД обычно неэффективен; для того чтобы извлечь выгоды от перехода на клиент-серверную технологию, структуру данных следует модифицировать.
При разработке ER-моделей создается следующий набор формализованных сведений о предметной области:
· список сущностей предметной области.
· список атрибутов сущностей.
· списание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным.
Разработав первый приближенный вариант диаграмм, далее этот вариант уточняется на основании результатов опросов экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что поставлена задача разработать информационную систему по заказу сбытового подразделения предприятия. В первую очередь необходимо изучить предметную область и процессы, происходящие в ней. Для этого опрашиваютя сотрудники, анализируется документация, изучаются формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам выяснилось, что с точки зрения менеджера проектируемая система должна обеспечивать следующие функции:
· хранить информацию о покупателях;
· распечатывать накладные на отпущенные товары;
· позволять отслеживать наличие товаров на складе.
Сущностями могут быть «покупатель», «накладная», «товар». Если предприятие имеет несколько складов, то «склад» также может являться новой сущностью.
Связь между сущностями может быть быть описана следующим образом:
· "покупатели могут покупать много товаров";
· "товары могут продаваться многим покупателям".
Соответствующий вариант диаграммы представлен на рис.10.
Внесем дополнительную информацию. Например, в ходе обследования территории предприятия выяснилось, что имеетсыя несколько складов, причем каждый товар может храниться на любом из складов и может быть продан с любого склада.
Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя.
Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма примет вид, изображенный на рис.11.
Определим атрибуты сущностей:
· каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты;
· каждый товар имеет наименование, цену, а также характеризуется единицами измерения;
· каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной; накладная выписывается с определенного склада и на определенного покупателя;
· каждый склад имеет свое наименование.
Проанализируем полученные описания следующим образом:
· «юридическое лицо» - предприятие не работает с физическими лицами, поэтому данный термин не является существенной характеристикой;
· наименование покупателя - является характеристикой покупателя;
· адрес - является характеристикой покупателя;
· банковские реквизиты - являются характеристикой покупателя;
· наименование товара - является характеристикой товара;
· единица измерения - является характеристикой товара;
· номер накладной - является характеристикой накладной, причем уникальной характеристикой;
· дата накладной - является характеристикой накладной, причем уникальной характеристикой;
· список товаров в накладной - нужно выделить список в отдельную сущность;
· сумма накладной - является характеристикой накладной, однако эта характеристика не независима (сумма накладной равна сумме стоимостей всех товаров, входящих в накладную);
· наименование склада - является характеристикой склада.
Предположим, что в ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен.

Рис. 12. Диаграмма для сбытового подразделения с учетом результата анализа дополнительных данных.
Оказалось, что каждый товар имеет некоторую текущую цену. Это цена, по которой товар продается в данный момент.
Цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С понятием "Список товаров в накладной"имеется ясность. Сущности "Накладная" и "Товар" связаны друг с другом отношением типа «многие-ко-многим». Такая связь должна быть раскрыта как две связи типа «один-ко-многим». Для этого требуется дополнительная сущность.
Этой сущностью может являться сущность "Список товаров в накладной".
Связь этой новой сущности с сущностями "Накладная" и "Товар" характеризуется следующим образом:
· "каждая накладная обязана иметь несколько записей из списка товаров в накладной";
· "каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную";
· "каждый товар может включаться в несколько записей из списка товаров в накладной";
· "каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром".
Атрибуты "Количество товара в накладной" и "Цена товара в накладной" являются атрибутами сущности "Список товаров в накладной".
Аналогично проанализируем связь, соединяющую сущности "Склад" и "Товар". Введем дополнительную сущность "Товар на складе". Атрибутом этой сущности будет "Количество товара на складе". Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
На рис.12 представлена диаграмма для рассмотренного примера.
Следует отметить, что возникающие при реструктуризации предприятий задачи разработки информационной модели и реляционных баз данных с особенностями именно конкретного подразделения относятся к числу новых технических реализаций; они могут дополнять типовые контуры MRP, ERP или CRM. Новизны научной или методической в таких технических реализациях не имеется.
Для случаев, когда данные не могут быть описаны средствами бинарной алгебры, общая теория и модель применимы с ограничениями, или вообще не работают; оптимизатор запроса в такой среде также не может быть спроектирован по стандартной технологии. Обеспечение качества и целостности данных в таких задачах является открытой научной проблемой.








