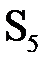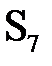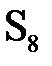Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...
Топ:
Особенности труда и отдыха в условиях низких температур: К работам при низких температурах на открытом воздухе и в не отапливаемых помещениях допускаются лица не моложе 18 лет, прошедшие...
Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда...
Интересное:
Как мы говорим и как мы слушаем: общение можно сравнить с огромным зонтиком, под которым скрыто все...
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Влияние предпринимательской среды на эффективное функционирование предприятия: Предпринимательская среда – это совокупность внешних и внутренних факторов, оказывающих влияние на функционирование фирмы...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Наиболее распространенным классом компьютерных симметричных криптосистем стали алгоритмы шифрования, построенные по принципу сети Фейстела [5, 6]. Входной блок делится на несколько равной длины подблоков, называемых ветвями, как правило, по 32 бита каждая[†]. Каждая ветвь обрабатывается независимо от другой, после чего осуществляется циклический сдвиг всех ветвей влево. Такое преобразование выполняется несколькими циклами или раундами.
Другим подходом к построению блочных шифров является использование обратимых зависящих от ключа преобразований. В этом случае на каждой итерации изменяется весь блок и, соответственно, общее количество итераций может быть сокращено. Каждая итерация представляет собой последовательность преобразований (так называемых «слоев»), каждое из которых выполняет свою функцию. K недостаткам данного подхода можно отнести то, что для процедур шифрования и дешифрования в общем случае нельзя использовать одни и те же блоки, как при использовании сетей Фейстела, что увеличивает аппаратные и/или программные затраты на реализацию.
Характеристики наиболее используемых симметричных блочных алгоритмов приведены в таблице 3.1.
Таблица 3.1 – Характеристики основных симметричных блочных алгоритмов [5]
| Название | Длина ключа, битов | Размер обрабатываемых блоков, битов | Число раундов |
| AES(Rijndael) | 128, 192, 256 | 128, 192, 256 | 10, 12, 14 |
| Blowfish | 32–448 | 64 | 16 |
| CAST-128 | 128 | 64 | 16 |
| CAST-256 | 256 | 128 | 16 |
| DES | 56 | 64 | 16 |
| IDEA | 128 | 64 | 8 |
| NewDES | 120 | 64 | 17 |
| RC2 | До 1024 | 64 | 16 |
| RC5 | До 2048 | 32, 64, 128 | 0…255 |
| ГОСТ 28147-89 | 256 | 64 | 16, 32 |
Блочное шифрование может использовать различные режимы, в которых каждый блок текста может шифроваться как отдельным ключом, так и для всех блоков текста может использоваться один и тот же ключ. Достоинством его является то, что небольшое изменение в шифруемом тексте может вызвать изменения в открытом тексте. Недостатками является относительное удобство для криптоанализа и размножение ошибок.
|
|
Американский алгоритм шифрования DES (Data Encryption Standard) [5, 6], являвшийся официальным стандартом шифрования США с 1978-го по 2000 г., осуществляет шифрование 64-битовых блоков данных с помощью 56-битового ключа. Дешифрование в DES является операцией, обратной шифрованию, и выполняется путем повторения операций шифрования в обратной последовательности. Структура алгоритма DES приведена на рисунке 3.1.
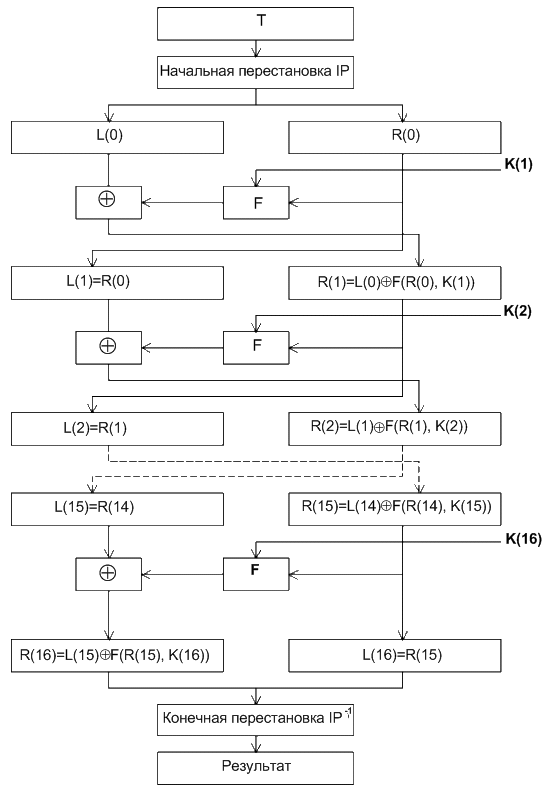
Рисунок 3.1 – Структура алгоритма шифрования DES
Процесс шифрования заключается в начальной перестановке бит 64-битового блока, 16 циклах шифрования и, наконец, в обратной перестановке битов. Необходимо отметить, что все таблицы, приведенные ниже, являются стандартными (IP, IP-1, блоки перестановок S-boxes). Все перестановки и коды в таблицах подобраны разработчиками таким образом, чтобы максимально затруднить процесс дешифрования путем подбора ключа.
Пусть из файла считан очередной 8-байтовый блок T, который преобразуется с помощью матрицы начальной перестановки IP (таблица 3.2) следующим образом: бит 58 блока T становится битом 1, бит 50 – битом 2 и т.д., что даст в результате: T(0) = IP(T).
Полученная последовательность битов T(0) разделяется на две последовательности по 32 бита каждая: L(0) – левые, или старшие, биты; R(0) – правые, или младшие, биты. Затем выполняется шифрование, состоящее из 16 итераций. Результат i-й итерации описывается следующими формулами:
| L(i) = R(i−1), i = 1, 2,…,16 R(i) = L(i−1) Å F(R(i−1), K(i)), i = 1,2,…, 16, | (3.1) |
где Å – операция XOR, сложение по модулю 2.
Функция F называется функцией шифрования. Ее аргументы – это
32-битовая последовательность R(i−1), полученная на (i−1)-й итерации, и
48-битовый ключ K(i), который является результатом преобразования
64-битового ключа K. Подробно функция шифрования и алгоритм получения ключей К(i) описаны ниже.
|
|
На 16-й итерации получают последовательности R(16) и L(16) (без перестановки), которые конкатенируют в 64-битовую последовательность R(16)L(16). Затем позиции битов этой последовательности переставляют в соответствии с матрицей IP−1 (таблица 3.3).
Таблица 3.2 – Матрица начальной перестановки IP
| Таблица 3.3 – Матрица обратной перестановки IP−1
|
Матрицы IP−1 и IP соотносятся следующим образом: значение первого элемента матрицы IP-1 равно 40, а значение 40-го элемента матрицы IP равно 1; значение второго элемента матрицы IP−1 равно 8, а значение 8-го элемента матрицы IP равно 2 и т.д.
Процесс дешифрования данных является инверсным по отношению к процессу шифрования. Итеративный процесс дешифрования может быть описан следующими формулами:
| R(i−1) = L(i), i = 1, 2,…,16; L(i−1) = R(i) Å F(L(i), K(i)), i = 1,2,…, 16. | (3.2) |
Рассмотрим функцию шифрования F(R(i−1), K(i)), схематически показанную на рисунке 3.2.
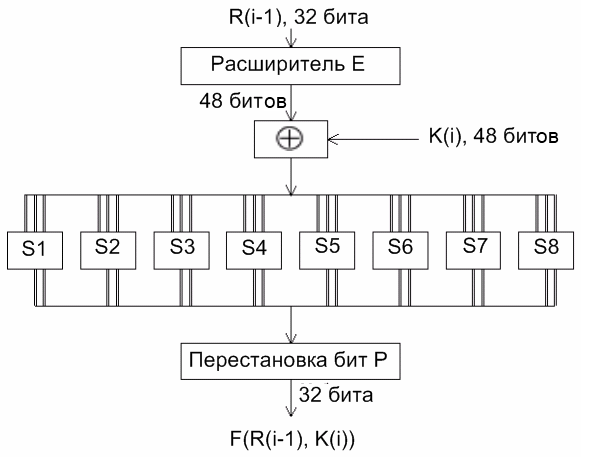
Рисунок 3.2 – Вычисление функции F(R(i−1), K(i))
Для вычисления значения функции F используются следующие функции-матрицы:
– Е – расширение 32-битовой последовательности до 48-битовой;
– S1, S2,..., S8 – преобразование шестибитового блока в четырехбитовый;
– Р – перестановка битов в 32-битовой последовательности.
Функция расширения Е определяется таблицей 3.4: первые три бита Е(R(i−1)) – это биты 32, 1 и 2, а последние – 31, 32 и 1.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Результатом функции Е(R(i−1)) является 48-битовая последовательность, которая складывается по модулю 2 (операция Å) с
48-битовым ключом К(i). Получается
48-битовая последовательность, которая разбивается на восемь шестибитовых блоков B(1)B(2)B(3)B(4)B(5)B(6)B(7)B(8), а именно:
|
|
E(R(i−1)) Å K(i) = B(1)B(2)...B(8). (3.3)
Функции S1, S2,..., S8 определяются таблицей 3.5. Пусть на вход функции-матрицы Sj поступает шестибитовый блок B(j) = b1b2b3b4b5b6, тогда двухбитовое число b1b6 указывает номер строки матрицы, а b2b3b4b5 – номер столбца. Результатом Sj(B(j)) будет четырехбитовый элемент, расположенный на пересечении указанных строки и столбца. Например, В(1) = 011011. Тогда S1(В(1)) расположен на пересечении строки 1 и столбца 13. В столбце 13 строки 1 задано значение 5. Значит, S1(011011) = 0101. Применив операцию выбора к каждому из шестибитовых блоков B(1), B(2),..., B(8), получаем
32-битовую последовательность S1(B(1))S2(B(2))S3(B(3))...S8(B(8)).
Для получения результата функции шифрования надо переставить биты этой последовательности. Для этого применяется функция перестановки P (таблица 3.6). Во входной последовательности биты перестанавливаются так, чтобы бит 16 стал битом 1, а бит 7 – битом 2 и т.д. Таким образом:
F(R(i−1), K(i)) = P(S1(B(1)),...S8(B(8))). (3.4)
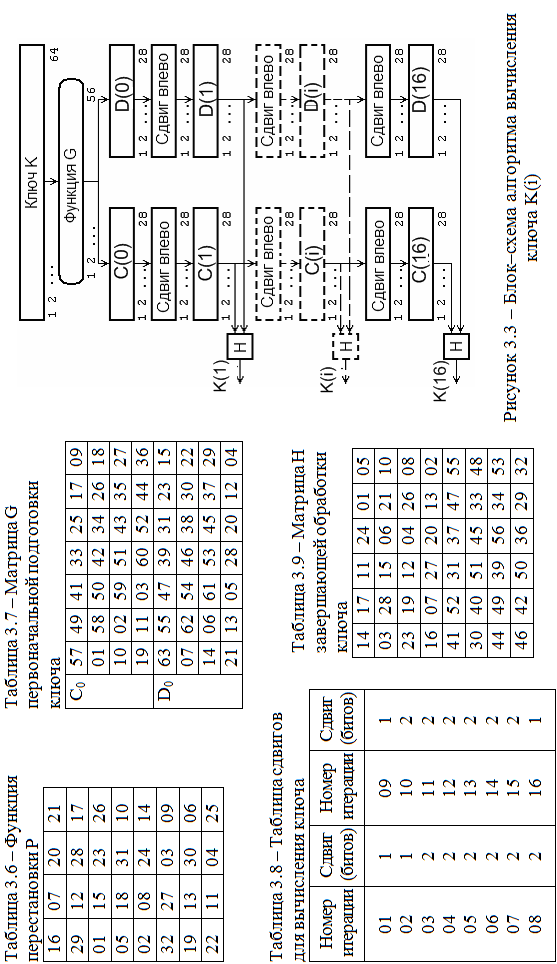
Чтобы завершить описание алгоритма шифрования данных, проведем алгоритм получения 48-битовых ключей К(i), i = 1,..., 16. На каждой итерации используется новое значение ключа K(i), которое вычисляется из начального ключа K. K представляет собой 64-битовый блок с восемью битами контроля по четности, расположенными в позициях 8, 16, 24, 32, 40, 48, 56, 64.
Для удаления контрольных битов и перестановки остальных используется функция G первоначальной подготовки ключа (таблица 3.7). Результат преобразования G(K) разбивается на два 28-битовых блока C(0) и D(0), причем C(0) будет состоять из битов 57, 49,..., 44, 36 ключа K, а D(0) – из битов 63, 55,..., 12, 4 ключа K. После определения C(0) и D(0) рекурсивно определяются C(i) и D(i), i = 1,..., 16. Для этого применяют циклический сдвиг влево на один или два бита в зависимости от номера итерации (таблица 3.8). Полученное значение вновь «перемешивается» в соответствии с матрицей H (таблица 3.9).
Ключ K(i) будет состоять из битов 14, 17,..., 29, 32 последовательности C(i)D(i). Таким образом:
K(i) = H(C(i)D(i)). (3.5)
Блок-схема алгоритма вычисления ключа приведена на рисунке 3.3.
| Таблица 3.5 – Функции преобразования S
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Потоковое шифрование
Суть потокового шифрования заключается в преобразовании исходного текста в шифрованный по биту, а не блоками. Часто потоковое шифрование называют гаммированием в соответствии с одним из способов потокового криптопреобразования – сложением по модулю 2 битов открытого текста с битами псевдослучайной последовательности (ПСП) [5].
Потоковые шифры по сравнению с блочными обладают рядом достоинств: более высокая скорость шифрования, относительная простота реализации и отсутствие размножение ошибок. Недостаток заключается в необходимости передачи информации синхронизации перед заголовком сообщения, которая должна быть принята до дешифрования сообщения [5].
Для дешифрования на приемной стороне ключевая принятая последовательность складывается по модулю 2 с ключевой последовательностью для получения исходного текста:
– шифрование:
Ci = Pi Å Ti; (3.6)
где Ci – зашифрованный текст; Pi – исходный текст; Ti – ключевая последовательность; Å – операция сложения по модулю 2;
– дешифрование:
Pi= CiÅ Ti = Pi Å Ti Å Ti. (3.7)
|
|
Криптостойкость потоковых шифров зависит от длины ключа для получения псевдослучайной (ключевой) последовательности и равномерности ее статистических характеристик. Если генератор последовательности имеет небольшой период, то стойкость криптосистемы на ее основе невелика. Если же генератор будет выдавать бесконечную последовательность истинно случайных бит, то получим идеально стойкую криптосистему.
Однако если два различных сообщения шифруются на одной и той же псевдослучайной последовательности, то это создает угрозу криптостойкости системы. Поэтому часто используют дополнительный случайно выбираемый ключ сообщения, который передается в начале сообщения и применяется для модификации ключа шифрования. В результате сообщения будут шифроваться с помощью различных последовательностей.
В настоящее время наиболее доступными и эффективными являются конгруэнтные генераторы ПСП. Одним из хороших конгруэнтных генераторов является линейный конгруэнтный датчик ПСП. Он вырабатывает последовательности псевдослучайных чисел T(i), описываемые соотношением:
Ti+1 = (A·Ti + C) mod m, (3.8)
где А и С – константы, от которых зависит период генерируемой псевдослучайной последовательности;
Т0 – исходная величина, выбранная в качестве порождающего числа.
m = 2s (обычно), где s – длина слова в битах.
Как показано Д. Кнутом, линейный конгруэнтный датчик ПСЧ имеет максимальную длину m тогда, когда С – нечетное и А mod 4 = 1.
|
|
|

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰)...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...

История развития хранилищ для нефти: Первые склады нефти появились в XVII веке. Они представляли собой землянные ямы-амбара глубиной 4…5 м...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!