Предположим, мы работаем с сообщениями, которые составляются из некоторого набора символов. Известна вероятность появления каждого символа в сообщении. Мы хотим закодировать каждый символ некоторой последовательностью нулей и единиц (возможно, разной длины), чтобы записывать сообщения в двоичном коде.
Например:
| Символ
| Код
|
| a
| 1
|
| b
| 011
|
| c
| 00
|
| d
| 010
|
Сообщение bacd в таком коде запишется как 011100010.
Наоборот, закодированное сообщение 000111 декодируется в cba.
Можно сформулировать два условия, которым должен удовлетворять код:
1). По любому закодированному сообщению можно однозначно восстановить исходное.
2). Средняя длина кода должна быть минимальной.
1-е условие можно реализовать по-разному. Например, будем последовательно брать из начала закодированного сообщения коды символов (префиксы). Если по ним можно однозначно восстановить все символы исходного сообщения, то такое свойство кода называется префиксным. Именно такие коды нас и интересуют.
Для примера рассмотрим несколько кодов:
| Символ
| Вероятность
| Код1
| Код2
| Код3
|
| a
| 0.55
| 00
| 1
| 1
|
| b
| 0.15
| 01
| 011
| 011
|
| c
| 0.2
| 10
| 00
| 10
|
| d
| 0.1
| 11
| 010
| 101
|
Ясно, что 1-й код обладает префиксным свойством (все коды символов имеют одинаковую длину и все они различны).
Легко проверить, что 2-й код тоже обладает префиксным свойством. Проверить можно, например, так. Максимальная длина кода=3. Возьмём все комбинации первых трёх символов сообщения и убедимся, что для каждой из них подходит только 1 код (или не подходит ни одного):
| Последовательность
| Код
| Символ
|
| 000…
| 00
| c
|
| 001…
| 00
| c
|
| 010…
| 010
| d
|
| 011…
| 011
| b
|
| 100…
| 1
| a
|
| 101…
| 1
| a
|
| 110…
| 1
| a
|
| 111…
| 1
| a
|
Извлекаем этот код и снова приходим к этой же самой задаче и т.д.
3-й код не обладает префиксным свойством. Например, последовательность 1011 можно декодировать и как da, и как ab.
Код с префиксным свойством, для которого средняя длина закодированного сообщения минимальна, называется кодом Хаффмана. Вместо средней длины закодированного сообщения удобнее рассматривать среднюю длину кода отдельного символа. Она находится как сумма произведений длин кодов символов на их вероятности. Например, для второго кода из примера средняя длина символа = 1*0,55+3*0,15+2*0,2+3*0,1 = 1,7.
Очевидно, что средняя длина символа для первого кода равна 2, значит второй код является более оптимальным.
Чтобы сократить среднюю длину символа до минимума, рассмотрим способ построения оптимального кода (алгоритм Хаффмана). В нём используется лес, в котором листья деревьев помечены кодируемыми символами, а сумма их вероятностей составляет вес дерева.
Вначале каждому символу соответствует дерево, состоящее из одного узла. На каждом шаге выбирается два дерева с минимальным весом и объединяются в одно путём создания нового корня. При этом дерево с наименьшим весом становиться левым сыном, а другое дерево – правым сыном нового узла. Так продолжается до тех пор, пока не останется только одно дерево.
В этом дереве путь от корня к любому листу представляет код соответствующего символа (при движении влево пишем 0, вправо – 1).
Пример:
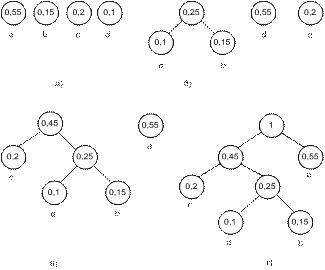
Рис.3.14. Деревья Хаффмана
Алгоритм Хаффмана можно применять, например, для сжатия файлов. Сжимая файл по алгоритму Хаффмана, первое, что мы должны сделать - прочитать файл полностью и подсчитать сколько раз встречается каждый символ. После этого строим декодирующее дерево, кодируем файл и сохраняем данные и таблицу соответствия символов и кодов Хаффмана.
Пример. Требуется в заданной строке получить вероятности появления каждого символа и получить для нее оптимальный код Хаффмана.
Для начала опишем структуры данных, которые нам потребуются для построения кодов и для их использования. Приведенный ниже фрагмент кода является началом нашей программы.
#include <iostream.h>
#include <string.h>
struct tree //структура дерева
{float probability;//частота встречи символов дерева
int root; //указатель на корень (индекс в массиве)
};
tree *letters[256], //массив букв
forest[256]; //массив деревьев (лес)
struct node //структура узла дерева
{ int left, right, parent; //указатели на сыновей и на родителя
};
node nodes[1000]; //массив узлов
int lasttree=0, //количество деревьев в лесу
lastnode=0; //общее количество узлов
char codes[256][10];//массив кодов символов (для кодирования)
char leafs[256]; //массив листьев (для декодирования)
В данной программе производится построение деревьев с помощью массива узлов nodes. Каждый его элемент представляет собой три указателя – на левого и правого сына, а также на родителя. Сами указатели имеют целочисленный тип и представляют собой индексы соответствующих элементов массива nodes. Указатель на родителя parent нужен для того, чтобы по известному символу можно было восстановить полный путь от корня до соответствующего листа. Это потребуется при построении таблицы кодов (массива codes). Количество элементов nodes взято 1000, на самом деле их должно быть гораздо меньше.
Структура дерева tree содержит лишь указатель на корень и вероятность появления его символов (вес дерева).
Массив letters служит для быстрого подсчета вероятностей появления символов в строке. В качестве индекса можно указывать сам символ, поскольку язык С++ автоматически преобразует его в целое число. При этом, если символ не встречается в строке, то соответствующий ему элемент массива letters будет представлять собой пустой указатель. Массив leafs, наоборот, служит для восстановления символа по указателю на его лист (который берется в качестве индекса). Сами указатели не могут превышать 255 поскольку все листья располагаются в начале массива nodes, а количество различных символов не может превышать 256.
Массив forest, в отличие от letters, будет хранить не только листья, но и сами деревья. При завершении алгоритма Хаффмана в нем должно остаться только одно дерево (forest[0]) с весом 1.
Следующий фрагмент программы представляет собой функцию, производящую подсчет вероятностей появления символов в строке, а также начальное или полное заполнение приведенных выше массивов.
void initialize(char *s) //заполнение массивов letters, leafs и forest
{ int i,j;
for (i=0; i<256; i++) letters[i]=NULL;
for (i=0; i<strlen(s); i++)
if(letters[s[i]])
letters[s[i]]->probability+=1.0/strlen(s);
else //создаем новый узел (лист будущего дерева)
{letters[s[i]]=new tree;
letters[s[i]]->probability=1.0/strlen(s);
letters[s[i]]->root=lastnode;
nodes[lastnode].left=nodes[lastnode].right=-1;
nodes[lastnode].parent=-1; //пустые указатели
leafs[lastnode]=s[i]; //запоминаем символ листа
lastnode++;
}
for (i=0; i<256; i++) //заполняем forest листами
if (letters[i]) {
forest[lasttree]=*letters[i]; lasttree++;
}
}
Далее идет основная функция, выполняющая построение общего дерева и таблицы кодов Хаффмана. Последняя служит только для убыстрения процесса кодирования. Для ее построения необходимо для каждого листа восстановить полный путь до него от корня дерева. При этом, чтобы сохранить прямой порядок следования цифр, каждая новая из них вставляется в начало строки, а не в ее конец.
void build(char *s)//построение дерева и таблицы кодов Хаффмана
{int i,j;
while (lasttree>1)
{ int first=0, second=1, //указатели на самые "легкие" деревья
root1, root2; //указатели на их корни
if ((lasttree>0)&&(forest[first].probability >
forest[second].probability)){ first=1; second=0;}
for (i=0; i<lasttree; i++)//вычисление first и second
if ((i!=first)&&(i!=second))
if(forest[i].probability<=forest[first].probability)
{ second=first; first=i; }
else
if(forest[i].probability<forest[second].probability)
second=i;
root1=forest[first].root;
root2=forest[second].root;
//создаем новый узел:
nodes[lastnode].left=root1;
nodes[lastnode].right=root2;
nodes[lastnode].parent=-1;
//объединяем деревья с корнями root1 и root2 в новое дерево:
nodes[root1].parent=nodes[root2].parent=lastnode;
forest[lasttree].probability=
forest[first].probability+forest[second].probability;
forest[lasttree].root=lastnode; lastnode++;
//удаляем самые "легкие" деревья:
forest[first]=forest[lasttree];
forest[second]=forest[lasttree-1];
lasttree--; //сокращаем лес на одно дерево
}
char tmp[9]; //временная строка
for (i=0;i<256;i++)//построение таблицы кодов Хаффмана
if (letters[i])
{ strcpy(codes[i],""); j=letters[i]->root;
while (nodes[j].parent!=-1)
{ strcpy(tmp,codes[i]);
if (nodes[nodes[j].parent].left==j) strcpy(codes[i],"0");
else strcpy(codes[i],"1");
strcat(codes[i],tmp);
j=nodes[j].parent;
}
cout<<char(i)<<" = "<<codes[i]<<endl; //выводим таблицу
}
}
Таким образом, при последовательном выполнении функций initialize и build заполняются все основные структуры данных. По ним легко можно закодировать строку и восстановить ее обратно. Приведем для этого две функции.
void encode(char *s, char *out)//кодирование в строку out
{ int i,j; strcpy(out,"");
for (i=0; i<strlen(s); i++)
strcat(out,codes[s[i]]);
}
void decode(char *out, char *s)//декодирование в строку s
{ int i=0,j=forest[0].root; //j - указатель на корень дурева Хаффмана
strcpy(s,"");
while (i<strlen(out))
{if((out[i]=='0')&&(nodes[j].left>-1))
j=nodes[j].left;
if((out[i]=='1')&&(nodes[j].left>-1))
j=nodes[j].right;
if ((nodes[j].left==-1)&&(nodes[j].right==-1))
{ strcat(s," "); s[strlen(s)-1]=leafs[j];
j=forest[0].root;
}
i++;
}
}
В завершение приведем небольшую демонстрационную программу, показывающую порядок работы с приведенными структурами данных и функциями.
main()
{ cout<<"Введите строку текста:\n";
char s[100];
cin.getline(s,100);
initialize(s); build(s);
char out[800];
encode(s,out);
cout<<"Закодированная строка: "<<out<<endl;
decode(out,s);
cout<<"Раскодированная строка: "<<s<<endl;
cin.get();
return 0;
}
Собрав вместе приведенные фрагменты, получим готовую программу, которую можно использовать для кодирования и декодирования любых строк текста








