Задача анализа текстов
Впервые «ручные» техники Text Mining появились в середине 1980-х, а в следующее десятилетие развитие технологий позволило значительно их усовершенствовать. В междисциплинарном смысле Text Mining лежит на стыке поиска информации, Data Mining, машинного самообучения, статистики и компьютерной лингвистики.
Например, текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В то же время в тексте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста. В западной литературе такой анализ называют Text Mining.
Text Mining часто называют также текстовым дейтамайнингом (text data mining), что отчасти раскрывает взаимосвязь двух этих технологий. Если дейтамайнинг позволяет извлекать новые знания (скрытые закономерности, факты, неизвестные взаимосвязи и т.п.) из больших объемов структурированной информации (хранимой в базах данных), то текстомайнинг — находить новые знания в неструктурированных текстовых массивах.
В этом смысле Text Mining добавляет к технологии data mining дополнительный этап — перевод неструктурированных текстовых массивов в структурированные. После чего данные могут обрабатываться с помощью стандартных методов data mining.
Методы анализа в неструктурированных текстах лежат на стыке нескольких областей: Data Mining, обработка естественных языков, поиск информации, извлечение информации и управление знаниями.
Типичные задачи Text Mining включают категоризацию, кластеризацию текстов, извлечение концептов и объектов, создание таксономий, смысловой анализ, обобщение документации и моделирование объектов, то есть установление связей между различными известными объектами. Анализ текстов включает себя извлечение информации и лингвистический анализ для выявления частоты вхождений различных слов, выявление шаблонов, расставление тэгов и аннотирование, техники Data Mining, включая анализ связей и ассоциаций, визуализацию и прогностический анализ. В конечном счете, общая цель всего этого состоит в том, чтобы превратить текст в данные, доступные для анализа.
Наиболее простой задачей является Text Mining слабоструктурированных узкоспециализированных текстовых массивов (различные отчеты о поломках, результаты опросов и т.п.). В текстовых массивах, где форма документа и набор лексики ограничены, новую информацию можно извлекать, анализируя статистику на уровне отдельных ключевых слов (терминов).
Когда мы говорим о неструктурированных текстах, то в общем виде задача сводится к «пониманию» произвольных текстов на естественном языке — это одна из старейших задач искусственного интеллекта (ИИ), которая может решаться с использованием различных технологий, в первую очередь на базе методов обработки данных на естественном языке — NLP (Natural Language Processing), на основе нейросетевых подходов, а также других методов и их комбинаций.
Огромное количество информации скапливается в многочисленных текстовых базах, хранящихся в личных ПК, локальных и глобальных сетях. И объем этой информации стремительно увеличивается. Чтение объемных текстов и поиск в гигантских массивах текстовых данных малоэффективны, поэтому становятся все более востребованными решения Text Mining.
Актуальность Text Mining растет по мере того, как людям самых разных профессий приходится принимать решения на базе анализа большого объема неструктурированных и слабоструктурированных текстов (рис. 1).
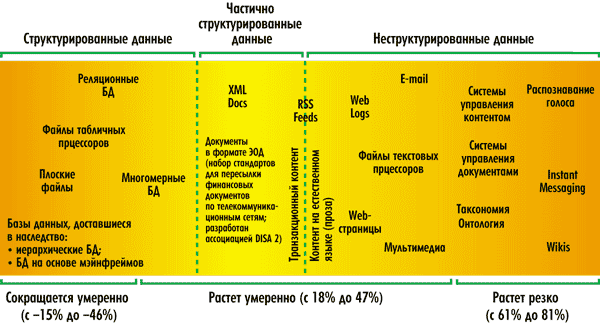
Рис. 1. (источник: Businessobjects)
Все более интересным становится анализ общественного мнения, выраженного в Web, в том числе блогосфера. Одним из новых направлений текстомайнинга является Opinion Mining (OM) (буквально — раскопка мнений) — технология, которая концентрируется не столько на содержании документа, сколько на мнении, которое он выражает.
Оценить успешность проведенной рекламной кампании, узнать, как к фирме относятся в прессе, — на эти и другие вопросы можно получить ответ с помощью технологии Opinion Mining.
Процесс анализа текстовых документов можно представить как последовательность нескольких шагов (рис. 2).
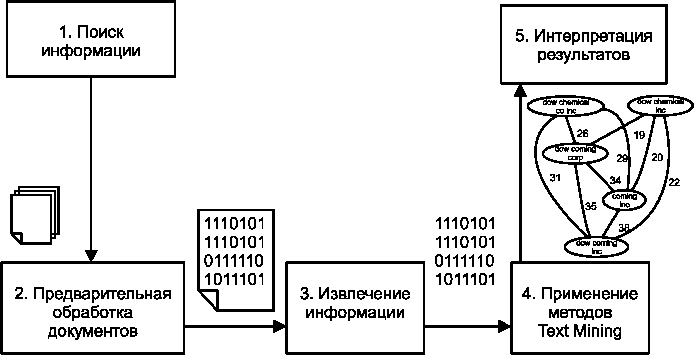
Рис. 2. Этапы Text Mining
Поиск информации. На первом шаге необходимо идентифицировать, какие документы должны быть подвергнуты анализу, и обеспечить их доступность.
Предварительная обработка документов. На этом шаге выполняются простейшие, но необходимые преобразования с документами для представления их в виде, с которым работают методы Text Mining. Целью таких преобразований является удаление лишних слов и придание тексту более строгой формы.
Извлечение информации. Извлечение информации из выбранных документов предполагает выделение в них ключевых понятий, над которыми в дальнейшем будет выполняться анализ.
Применение методов Text Mining. На данном шаге извлекаются шаблоны и отношения, имеющиеся в текстах. Данный шаг является основным в процессе анализа текстов.
Интерпретация результатов. Последний шаг в процессе обнаружения знаний предполагает интерпретацию полученных результатов. Как правило, интерпретация заключается или в представлении результатов на естественном языке, или в их визуализации в графическом виде.
Визуализация также может быть использована как средство анализа текста. Для этого извлекаются ключевые понятия, которые и представляются в графическом виде. Такой подход помогает пользователю быстро идентифицировать главные темы и понятия, а также определить их важность.
Важная задача технологии Text Mining связана с извлечением из текста его характерных элементов или свойств, которые могут использоваться как метаданные документа, ключевых слов, аннотаций. Другая важная задача состоит в отнесении документа к некоторым категориям из заданной схемы их систематизации. Text Mining также обеспечивает новый уровень семантического поиска документов.
Возможности современных систем Text Mining могут применяться при управлении знаниями для выявления шаблонов в тексте, для автоматического «выталкивания» или размещения информации по интересующим пользователей профилям, создавать обзоры документов
2. Методы предварительной обработки текста
Одной из главных проблем анализа текстов является большое количество слов в документе. Если каждое из этих слов подвергать анализу, то время поиска новых знаний резко возрастет и вряд ли будет удовлетворять требованиям пользователей. В то же время очевидно, что не все слова в тексте несут полезную информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т.п.) на самом деле означают одинаковые понятия. Таким образом, удаление неинформативных слов, а также приведение близких по смыслу слов к единой форме значительно сокращают время анализа текстов. Устранение описанных проблем выполняется на этапе предварительной обработки текста.
Обычно используют следующие приемы удаления неинформативных слов и повышения строгости текстов:
· удаление стоп-слов. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Обычно заранее составляются списки таких слов, и в процессе предварительной обработки они удаляются из текста. Типичным примером таких слов являются вспомогательные слова и артикли, например: "так как", "кроме того" и т. п.;
· стемминг — морфологический поиск. Он заключается в преобразовании каждого слова к его нормальной форме. Нормальная форма исключает склонение слова, множественную форму, особенности устной речи и т. п. Например, слова "сжатие" и "сжатый" должны быть преобразованы в нормальную форму слова "сжимать". Алгоритмы морфологического разбора учитывают языковые особенности и вследствие этого являются языковозависимыми алгоритмами;
· N-граммы — это альтернатива морфологическому разбору и удалению стоп-слов. N-грамма — это часть строки, состоящая из N символов. Например, слово "дата" может быть представлено 3-граммой "_да", "дат", "ата", "та_" или 4-граммой "_дат", "дата", "ата_", где символ подчеркивания заменяет предшествующий или замыкающий слово пробел. По сравнению со стеммингом или удалением стоп-слов, N-граммы менее чувствительны к грамматическим и типографическим ошибкам. Кроме того, N-граммы не требуют лингвистического представления слов, что делает данный прием более независимым от языка. Однако N-граммы, позволяя сделать текст более строгим, не решают проблему уменьшения количества неинформативных слов;
· приведение регистра. Этот прием заключается в преобразовании всех символов к верхнему или нижнему регистру. Например, все слова "текст", "Текст", "ТЕКСТ" приводятся к нижнему регистру "текст".
Наиболее эффективно совместное применение перечисленных методов.
Задачи Text Mining
Задачи Text Mining: классификация, кластеризация, и характерные только для текстовых документов задачи: автоматическое аннотирование, извлечение ключевых понятий и др.
Классификация (classification) — стандартная задача из области Data Mining. Ее целью является определение для каждого документа одной или нескольких заранее заданных категорий, к которым этот документ относится. Особенностью задачи классификации является предположение, что множество классифицируемых документов не содержит "мусора", т. е. каждый из документов соответствует какой-нибудь заданной категории.
Частным случаем задачи классификации является задача определения тематики документа. В существующих сегодня системах классификация применяется, например, в таких задачах: группировка документов в intranet- сетях и на Web-сайтах, размещение документов в определенные папки, сортировка сообщений электронной почты, избирательное распространение новостей подписчикам. М
Целью кластеризации (clustering) документов является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества. Отметим, что группы формируются только на основе попарной схожести описаний документов, и никакие характеристики этих групп не задаются заранее.
Автоматическое аннотирование (summarization) позволяет сократить текст, сохраняя его смысл. Решение этой задачи обычно регулируется пользователем при помощи определения количества извлекаемых предложений или процентом извлекаемого текста по отношению ко всему тексту. Результат включает в себя наиболее значимые предложения в тексте.
Первичной целью извлечения ключевых понятий (feature extraction) является идентификация фактов и отношений в тексте. В большинстве случаев такими понятиями являются имена существительные и нарицательные: имена и фамилии людей, названия организаций и др. Алгоритмы извлечения понятий могут использовать словари, чтобы идентифицировать некоторые термины и лингвистические шаблоны для определения других.
Навигация по тексту (text-base navigation) позволяет пользователям перемещаться по документам относительно тем и значимых терминов. Это выполняется за счет идентификации ключевых понятий и некоторых отношений между ними.
Web mining
Web Mining – еще одна технология извлечения знаний, которая представляет собой использование методов и алгоритмов Data Mining для поиска и нахождения знаний и зависимостей в материалах сети Интернет.
Эта технология развивается на пересечении извлечения знаний из баз данных, эффективного поиска информации, искусственного интеллекта, машинного обучения и обработки естественных языков.
В Интернете содержится неизмеримое множество знаний и информации. Такое обилие часто создает сложности при поиске необходимой информации. Подобного рода проблемы могут иметь различный характер, например:
1.Пользователь не всегда в состоянии сразу найти необходимые ему источники электронной информации, так как не все ссылки ведут туда, куда указано, а не проиндексированную поисковыми системами информацию таким способом и вовсе невозможно найти.
2.Найдя множество информации, пользователь часто испытывает сложности с тем, чтобы извлечь из нее полезные знания и понять их.
3.Когда речь идет об изучении информации о потребителях, возникает необходимость предоставлять им те сведения, которые им интересны – например, давать пользователю подсказки при выборе нужного товара.
Всё это приводит к необходимости каких-то специальных технологий для извлечения полезных знаний из сети Интернет. Технология Web Mining может успешно служить этим целям.
Рассмотрим основные этапы использования Web Mining:
1.Вводный этап (input) – получение сырых данных из источников, которые используются для анализа. Это могут быть логи серверов, электронные документы и так далее.
2.Предварительная обработка (preprocessing) – предоставление данных в той форме, которая нужна для построения той или иной модели.
3.Этап моделирования (pattern discovery).
4.Анализ полученной модели (pattern analysis) – интерпретация полученных результатов.
Таковы общие стадии, которые всегда необходимо пройти для Web Mining анализа, но конкретные процедуры, которые будут совершаться на каждой стадии, будут зависеть от поставленной задачи.
По типу решаемых задач выделяются различные разновидности технологии Web Mining:
анализ использования веб-ресурсов,
извлечение веб- структур,
извлечение веб-контента.
Анализ использования веб-ресурсов – это извлечение данных из логов веб- серверов для понимания предпочтений пользователей тех или иных ресурсов сети Интернет. При таком анализе важно тщательно подбирать и предварительно обрабатывать данные. Узнав, как и когда пользователь открывает те или иные электронные страницы, можно понять его предпочтения и проанализировать общие тенденции использования того или иного сайта, чтобы затем при необходимости его оптимизировать.
Извлечение веб структур – анализирует взаимосвязи между веб- страницами, рассматривая связи между ними. Полученные таким образом модели можно использовать, чтобы разбивать веб-ресурсы по категориям, находить между ними сходства и различия. Такая работа может быть предварительным этапом для извлечения веб-контента.
Извлечение веб-контента – анализ содержание электронных документов, путем нахождения схожих по смыслу слов и их количеств, чтобы провести классификацию либо кластеризацию и сгруппировать документы по смысловой близости. Такая работа может проводиться для оптимизации поиска проиндексированных документов.
Глобально, цели использования технологии Web Mining сводятся к поиску необходимой информации и знаний, невзирая на несовершенства поисковых систем; анализ структур сегментов сети, то есть структуры ссылок между разными страницами и сайтами в конкретном сетевом сегменты (например, используется для анализа цитирования различных авторов); выявлению знаний из веб-ресурсов – поиск ключевых слов, общих тем и так далее; персонализации информации – создание веб-систем, которые адаптируются под предпочтения пользователя, например, предложение схожих с уже купленными товаров; обнаружение шаблонов в поведении пользователей, чтобы спрогнозировать следующие его действия и использовать полученные знания для дальнейшей оптимизации сайта.
Итак, технология Web Mining может решать в управлении знаниями и бизнес-аналитике такие конкретные задачи:
1.Описание пользователей сайта. 2
.Описание покупателей в Интернет-магазинов.
3.Описание типичных сессий посещений сайта и навигационных траекторий пользователей.
4.Описание групп и сегментов посетителей.
5.Поиск зависимостей при использовании сайта и его услуг.
Рассмотрим удачный практический пример использования технологии Web Mining. Компания Google использовала этот подход, чтобы понять, ожидают ли пользователи всемирной сети наступления экономического кризиса. В сотрудничества с профессором экономики Университета Калифорнии в Беркли Х. Варианом специалисты компании создали инструмент Google Correlate, предназначенный для отслеживания статистики запросов в поисковой системе, чтобы наложить полученные результаты на реальные экономические данные. Выяснилось, что динамика определенных запросов почти полностью совпадает с динамикой экономических величин – то есть, ее можно использовать для прогнозирования.
Иллюстрацией этой закономерности послужил поисковый запрос «Пособие по безработице» - выяснилось, что его динамика в Google совпадает с динамикой числа заявлений, подаваемых в службы занятости США. Инструмент позволяет пользователям загружать собственные данные, а затем ищет поисковые запросы со схожей динамикой. Издание Forbes решило воспользоваться им, чтобы построить прогноз экономической активности в России. Был взят экономический показатель «промышленное производство». Оказалось, что его динамика связана с поисковыми запросами пользователей о кредитах. Статистика запросов о кредитовании равно или слегка опережает реальную статистику производства.
Задача анализа текстов
Впервые «ручные» техники Text Mining появились в середине 1980-х, а в следующее десятилетие развитие технологий позволило значительно их усовершенствовать. В междисциплинарном смысле Text Mining лежит на стыке поиска информации, Data Mining, машинного самообучения, статистики и компьютерной лингвистики.
Например, текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В то же время в тексте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста. В западной литературе такой анализ называют Text Mining.
Text Mining часто называют также текстовым дейтамайнингом (text data mining), что отчасти раскрывает взаимосвязь двух этих технологий. Если дейтамайнинг позволяет извлекать новые знания (скрытые закономерности, факты, неизвестные взаимосвязи и т.п.) из больших объемов структурированной информации (хранимой в базах данных), то текстомайнинг — находить новые знания в неструктурированных текстовых массивах.
В этом смысле Text Mining добавляет к технологии data mining дополнительный этап — перевод неструктурированных текстовых массивов в структурированные. После чего данные могут обрабатываться с помощью стандартных методов data mining.
Методы анализа в неструктурированных текстах лежат на стыке нескольких областей: Data Mining, обработка естественных языков, поиск информации, извлечение информации и управление знаниями.
Типичные задачи Text Mining включают категоризацию, кластеризацию текстов, извлечение концептов и объектов, создание таксономий, смысловой анализ, обобщение документации и моделирование объектов, то есть установление связей между различными известными объектами. Анализ текстов включает себя извлечение информации и лингвистический анализ для выявления частоты вхождений различных слов, выявление шаблонов, расставление тэгов и аннотирование, техники Data Mining, включая анализ связей и ассоциаций, визуализацию и прогностический анализ. В конечном счете, общая цель всего этого состоит в том, чтобы превратить текст в данные, доступные для анализа.
Наиболее простой задачей является Text Mining слабоструктурированных узкоспециализированных текстовых массивов (различные отчеты о поломках, результаты опросов и т.п.). В текстовых массивах, где форма документа и набор лексики ограничены, новую информацию можно извлекать, анализируя статистику на уровне отдельных ключевых слов (терминов).
Когда мы говорим о неструктурированных текстах, то в общем виде задача сводится к «пониманию» произвольных текстов на естественном языке — это одна из старейших задач искусственного интеллекта (ИИ), которая может решаться с использованием различных технологий, в первую очередь на базе методов обработки данных на естественном языке — NLP (Natural Language Processing), на основе нейросетевых подходов, а также других методов и их комбинаций.
Огромное количество информации скапливается в многочисленных текстовых базах, хранящихся в личных ПК, локальных и глобальных сетях. И объем этой информации стремительно увеличивается. Чтение объемных текстов и поиск в гигантских массивах текстовых данных малоэффективны, поэтому становятся все более востребованными решения Text Mining.
Актуальность Text Mining растет по мере того, как людям самых разных профессий приходится принимать решения на базе анализа большого объема неструктурированных и слабоструктурированных текстов (рис. 1).
Рис. 1. (источник: Businessobjects)
Все более интересным становится анализ общественного мнения, выраженного в Web, в том числе блогосфера. Одним из новых направлений текстомайнинга является Opinion Mining (OM) (буквально — раскопка мнений) — технология, которая концентрируется не столько на содержании документа, сколько на мнении, которое он выражает.
Оценить успешность проведенной рекламной кампании, узнать, как к фирме относятся в прессе, — на эти и другие вопросы можно получить ответ с помощью технологии Opinion Mining.
Процесс анализа текстовых документов можно представить как последовательность нескольких шагов (рис. 2).
Рис. 2. Этапы Text Mining
Поиск информации. На первом шаге необходимо идентифицировать, какие документы должны быть подвергнуты анализу, и обеспечить их доступность.
Предварительная обработка документов. На этом шаге выполняются простейшие, но необходимые преобразования с документами для представления их в виде, с которым работают методы Text Mining. Целью таких преобразований является удаление лишних слов и придание тексту более строгой формы.
Извлечение информации. Извлечение информации из выбранных документов предполагает выделение в них ключевых понятий, над которыми в дальнейшем будет выполняться анализ.
Применение методов Text Mining. На данном шаге извлекаются шаблоны и отношения, имеющиеся в текстах. Данный шаг является основным в процессе анализа текстов.
Интерпретация результатов. Последний шаг в процессе обнаружения знаний предполагает интерпретацию полученных результатов. Как правило, интерпретация заключается или в представлении результатов на естественном языке, или в их визуализации в графическом виде.
Визуализация также может быть использована как средство анализа текста. Для этого извлекаются ключевые понятия, которые и представляются в графическом виде. Такой подход помогает пользователю быстро идентифицировать главные темы и понятия, а также определить их важность.
Важная задача технологии Text Mining связана с извлечением из текста его характерных элементов или свойств, которые могут использоваться как метаданные документа, ключевых слов, аннотаций. Другая важная задача состоит в отнесении документа к некоторым категориям из заданной схемы их систематизации. Text Mining также обеспечивает новый уровень семантического поиска документов.
Возможности современных систем Text Mining могут применяться при управлении знаниями для выявления шаблонов в тексте, для автоматического «выталкивания» или размещения информации по интересующим пользователей профилям, создавать обзоры документов
2. Методы предварительной обработки текста
Одной из главных проблем анализа текстов является большое количество слов в документе. Если каждое из этих слов подвергать анализу, то время поиска новых знаний резко возрастет и вряд ли будет удовлетворять требованиям пользователей. В то же время очевидно, что не все слова в тексте несут полезную информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т.п.) на самом деле означают одинаковые понятия. Таким образом, удаление неинформативных слов, а также приведение близких по смыслу слов к единой форме значительно сокращают время анализа текстов. Устранение описанных проблем выполняется на этапе предварительной обработки текста.
Обычно используют следующие приемы удаления неинформативных слов и повышения строгости текстов:
· удаление стоп-слов. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Обычно заранее составляются списки таких слов, и в процессе предварительной обработки они удаляются из текста. Типичным примером таких слов являются вспомогательные слова и артикли, например: "так как", "кроме того" и т. п.;
· стемминг — морфологический поиск. Он заключается в преобразовании каждого слова к его нормальной форме. Нормальная форма исключает склонение слова, множественную форму, особенности устной речи и т. п. Например, слова "сжатие" и "сжатый" должны быть преобразованы в нормальную форму слова "сжимать". Алгоритмы морфологического разбора учитывают языковые особенности и вследствие этого являются языковозависимыми алгоритмами;
· N-граммы — это альтернатива морфологическому разбору и удалению стоп-слов. N-грамма — это часть строки, состоящая из N символов. Например, слово "дата" может быть представлено 3-граммой "_да", "дат", "ата", "та_" или 4-граммой "_дат", "дата", "ата_", где символ подчеркивания заменяет предшествующий или замыкающий слово пробел. По сравнению со стеммингом или удалением стоп-слов, N-граммы менее чувствительны к грамматическим и типографическим ошибкам. Кроме того, N-граммы не требуют лингвистического представления слов, что делает данный прием более независимым от языка. Однако N-граммы, позволяя сделать текст более строгим, не решают проблему уменьшения количества неинформативных слов;
· приведение регистра. Этот прием заключается в преобразовании всех символов к верхнему или нижнему регистру. Например, все слова "текст", "Текст", "ТЕКСТ" приводятся к нижнему регистру "текст".
Наиболее эффективно совместное применение перечисленных методов.
Задачи Text Mining
Задачи Text Mining: классификация, кластеризация, и характерные только для текстовых документов задачи: автоматическое аннотирование, извлечение ключевых понятий и др.
Классификация (classification) — стандартная задача из области Data Mining. Ее целью является определение для каждого документа одной или нескольких заранее заданных категорий, к которым этот документ относится. Особенностью задачи классификации является предположение, что множество классифицируемых документов не содержит "мусора", т. е. каждый из документов соответствует какой-нибудь заданной категории.
Частным случаем задачи классификации является задача определения тематики документа. В существующих сегодня системах классификация применяется, например, в таких задачах: группировка документов в intranet- сетях и на Web-сайтах, размещение документов в определенные папки, сортировка сообщений электронной почты, избирательное распространение новостей подписчикам. М
Целью кластеризации (clustering) документов является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества. Отметим, что группы формируются только на основе попарной схожести описаний документов, и никакие характеристики этих групп не задаются заранее.
Автоматическое аннотирование (summarization) позволяет сократить текст, сохраняя его смысл. Решение этой задачи обычно регулируется пользователем при помощи определения количества извлекаемых предложений или процентом извлекаемого текста по отношению ко всему тексту. Результат включает в себя наиболее значимые предложения в тексте.
Первичной целью извлечения ключевых понятий (feature extraction) является идентификация фактов и отношений в тексте. В большинстве случаев такими понятиями являются имена существительные и нарицательные: имена и фамилии людей, названия организаций и др. Алгоритмы извлечения понятий могут использовать словари, чтобы идентифицировать некоторые термины и лингвистические шаблоны для определения других.
Навигация по тексту (text-base navigation) позволяет пользователям перемещаться по документам относительно тем и значимых терминов. Это выполняется за счет идентификации ключевых понятий и некоторых отношений между ними.
Извлечение ключевых понятий из текста
Извлечение ключевых понятий из текста может рассматриваться и как отдельный этап анализа текста, и как определенная прикладная задача. В первом случае извлеченные из текста факты используются для решения различных задач анализа: классификации, кластеризации и др. Большинство методов Data Mining, адаптированные для анализа текстов, работают именно с такими отдельными понятиями, рассматривая их в качестве атрибутов данных.
В задаче извлечения ключевых понятий из текста интерес представляют некоторые сущности, события и отношения. При этом извлеченные понятия анализируются и используются для вывода новых.
Извлечение ключевых понятий из текстовых документов можно рассматривать как фильтрацию больших объемов текста. Этот процесс включает в себя отбор документов из коллекции и пометку определенных термов в тексте. Существуют различные подходы к извлечению информации из текста. Примером может служить определение частых наборов слов и объединение их в ключевые понятия.
Другим подходом является идентификация фактов в текстах и извлечение их характеристик. Фактами являются некоторые события или отношения. Идентификация производится с помощью наборов образцов. Образцы представляют собой возможные лингвистические варианты фактов.
Такой подход позволяет представить найденные ключевые понятия, представленные событиями и отношениями, в виде структур, которые в том числе можно хранить в базах данных.
Процесс извлечения ключевых понятий с помощью шаблонов разбивается на две стадии: локальный анализ и анализ понятий (рис. 3). На первой стадии из текстовых документов извлекаются отдельные факты с помощью лексического анализа. Вторая стадия заключается в интеграции извлеченных фактов и/или в выводе новых фактов. В конце наиболее характерные факты преобразовываются в нужную выходную форму.
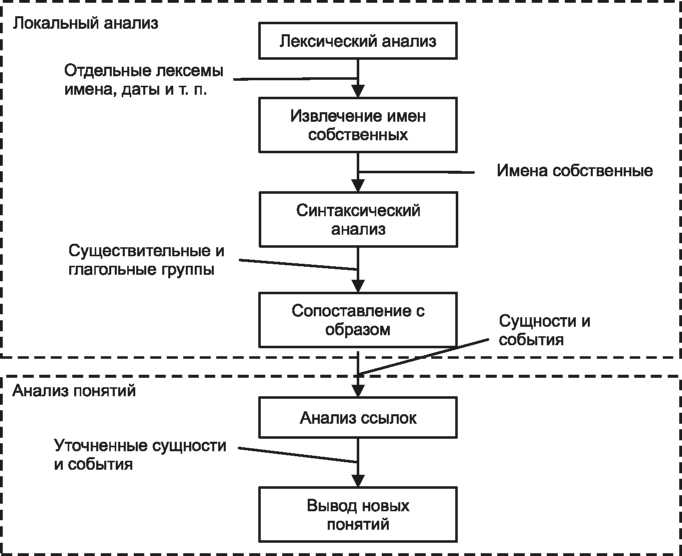
Рис. 3. Процесс извлечения ключевых понятий
На стадии интеграции найденные в документах факты исследуются и комбинируются. Это выполняется с учетом отношений, которые определяются местоимениями или описанием одинаковых событий. Также на этой стадии делаются выводы из ранее установленных фактов.
Извлечение фактов выполняется при помощи сопоставления текста с набором регулярных выражений (образцов). Если выражение сопоставляется с текстовыми сегментами, то такие сегменты помечаются метками. При необходимости этим сегментам приписываются дополнительные свойства. Образцы организуются в наборы. Метки, ассоциированные с одним набором, могут ссылаться на другие наборы.
Каждый образец имеет связанный с ним набор действий. Как правило, главное действие — это пометить текстовый сегмент новой меткой, но могут быть и другие действия. В каждый момент времени текстовому сегменту сопоставляется только один набор образцов. Каждый образец в наборе начинает сопоставляться с первого слова предложения. Если образец может быть сопоставлен более чем одному сегменту, то выбирается наиболее длинный сопоставленный сегмент. Если таких сегментов несколько, то выбирается первый. При сопоставлении выполняются действия, ассоциированные с этим образцом. Если не удалось сопоставить ни один образец, то сопоставление повторяется, начиная со следующего слова в предложении. Если сегмент сопоставлен с образцом, то сопоставление повторяется, начиная со следующего слова после сегмента. Процесс продолжается до конца предложения.
Основной целью сопоставления с образцами является выделение в тексте сущностей, связей и событий. Все они могут быть преобразованы в некоторые структуры, которые могут анализироваться стандартными методами Data Mining.






