

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Топ:
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Марксистская теория происхождения государства: По мнению Маркса и Энгельса, в основе развития общества, происходящих в нем изменений лежит...
Выпускная квалификационная работа: Основная часть ВКР, как правило, состоит из двух-трех глав, каждая из которых, в свою очередь...
Интересное:
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
ch14‑timers
^D
POSIX оставляет неопределенным, как интервальные таймеры взаимодействуют с функцией, если вообще взаимодействуют. GLIBC не использует для реализации функцию, поэтому на системах GNU/Linux не взаимодействует с интервальным таймером. Однако, для переносимых программ, вы не можете делать такое предположение.
Более точные паузы:
Функция (см. раздел 10.8.1 «Сигнальные часы:, и») дает программе возможность приостановиться на указанное число секунд. Но, как мы видели, она принимает лишь целое число секунд, что делает невозможным задержки на короткие периоды, она потенциально может также взаимодействовать с обработчиками. Функция компенсирует эти недостатки:
Эта функция является частью необязательного расширения POSIX «Таймеры» (TMR). Два аргумента являются запрошенным временем задержки и оставшимся числом времени в случае раннего возвращения (если не равен). Оба являются значениями:
Значение должно быть в диапазоне от 0 до 999 999 999. Как и в случае со, время задержки может быть больше запрошенного в зависимости оттого, когда и как ядро распределяет время для исполнения процессов.
В отличие от, не взаимодействует ни с какими сигналами, делая ее более безопасной и более простой для использования.
Возвращаемое значение равно 0, если выполнение процесса было задержано в течение всего указанного времени. В противном случае оно равно ‑1, с, указывающим ошибку. В частности, если равен, была прервана сигналом. В этом случае, если не равен,, на которую она указывает, содержит оставшееся время задержки. Это облегчает повторный вызов для продолжения задержки.
Хотя это выглядит немного странным, вполне допустимо использовать одну и ту же структуру для обоих параметров:
|
|
и сходны друг с другом, отличаясь лишь компонентом долей секунд. Заголовочный файл GLIBC определяет для их взаимного преобразования друг в друга два полезных макроса:
Вот они:
ЗАМЕЧАНИЕ. To, что некоторые системные вызовы используют микросекунды, а другие – наносекунды, в самом деле сбивает с толку. Причина этого историческая: микросекундные вызовы были разработаны на системах, аппаратные часы которых не имели более высокого разрешения, тогда как наносекундные вызовы были разработаны более недавно для систем со значительно более точными часами. C'est la vie. Почти все, что вы можете сделать, это держать под руками ваше руководство.
Расширенный поиск с помощью двоичных деревьев
В разделе 6.2 «Функции сортировки и поиска» мы представили функции для поиска и сортировки массивов. В данном разделе мы рассмотрим более продвинутые возможности.
Введение в двоичные деревья
Массивы являются почти простейшим видом структурированных данных. Их просто понимать и использовать. Хотя у них есть недостаток, заключающийся в том, что их размер фиксируется во время компиляции. Таким образом, если у вас больше данных, чем помещается в массив, вам не повезло. Если у вас значительно меньше данных, чем размер массива, память расходуется зря. (Хотя на современных системах много памяти, подумайте об ограничениях программистов, пишущих программы для внедренных систем, таких, как микроволновые печи и мобильные телефоны. С другого конца спектра, подумайте о проблемах программистов, имеющих дело с огромными объемами ввода, таких, как прогнозирование погоды.
В области компьютерных наук были придуманы многочисленные динамические структуры данных, структуры, которые увеличивают и уменьшают свой размер по требованию и которые являются более гибкими, чем простые массивы, даже массивы, создаваемые и изменяемые динамически с помощью и. Массивы при добавлении или удалении новых элементов требуется также повторно сортировать.
|
|
Одной из таких структур является дерево двоичного поиска, которое мы для краткости будем называть просто «двоичным деревом» («binary tree»). Двоичное дерево хранит элементы в сортированном порядке, вводя их в дерево в нужном месте при их появлении. Поиск по двоичному дереву также осуществляется быстро, время поиска примерно такое же, как при двоичном поиске в массиве. В отличие от массивов, двоичные деревья не нужно каждый раз повторно сортировать с самого начала при добавлении к ним элементов.
У двоичных деревьев есть один недостаток. В случае, когда вводимые данные уже отсортированы, время поиска в двоичном дереве сводится ко времени линейного поиска. Техническая сторона этого вопроса должна иметь дело с тем, как двоичные деревья управляются внутренне, что вскоре будет описано.
Теперь не избежать некоторой формальной терминологии, относящейся к структурам данных. На рис. 14.1 показано двоичное дерево. В информатике деревья изображаются, начиная сверху и расширяясь вниз. Чем ниже спускаетесь вы по дереву, тем больше его глубина. Каждый объект внутри дерева обозначается как вершина (node). На вершине дерева находится корень дерева с глубиной 0. Внизу находятся концевые вершины различной глубины. Концевые вершины отличают по тому, что у них нет ответвляющихся поддеревьев (subtrees), тогда как у внутренних вершин есть по крайней мере одно поддерево. Вершины с поддеревьями иногда называют родительскими (parent), они содержат порожденные вершины (children).
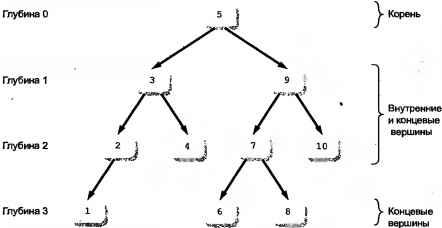
Рис. 14.1. Двоичное дерево
Чистые двоичные деревья отличаются тем, что каждая вершина содержит не более двух порожденных вершин. (Деревья с более чем двумя вершинами полезны, но не существенны для нашего обсуждения.) Порожденные вершины называются в этом случае левой и правой соответственно.
Деревья двоичного поиска отличаются еще и тем, что значения, хранящиеся в левой порожденной вершине, всегда меньше значения в родительской вершине, а значения, хранящиеся в правой порожденной вершине, всегда больше значения в родительской вершине. Это предполагает, что внутри дерева нет повторяющихся значений. Этот факт также объясняет, почему деревья не эффективны при работе с предварительно отсортированными данными: в зависимости от порядка сортировки, каждый новый элемент данных сохраняется либо только слева, либо только справа от находящегося впереди него элемента, образуя простой линейный список.
|
|
К двоичным деревьям применяют следующие операции:
Ввод
Добавление к дереву нового элемента.
Поиск
Нахождение элемента в дереве.
Удаление
Удаление элемента из дерева.
Прохождение (traversal)
Осуществление какой‑либо операции с каждым хранящимся в дереве элементом. Прохождение дерева называют также обходом дерева (tree walk). Есть разнообразные способы «посещения» хранящихся в дереве элементов. Обсуждаемые здесь функции реализуют лишь один из таких способов. Мы дополнительно расскажем об этом позже.
|
|
|

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰)...

Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...

История развития хранилищ для нефти: Первые склады нефти появились в XVII веке. Они представляли собой землянные ямы-амбара глубиной 4…5 м...

Архитектура электронного правительства: Единая архитектура – это методологический подход при создании системы управления государства, который строится...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!