__________________ TL;DR _____________________________________
В третьей главе мы подробно рассмотрим главную составляющую любой нейронной сети — перцептрон, а также то, как перцептроны соединяются в сети. В частности, мы поговорим:
• об истории искусственных нейронных сетей;
• об определении перцептрона и методах его обучения;
• о разных нелинейных функциях активации, от классических до современных;
• о том, похожа ли наша модель перцептрона на настоящие живые нейроны;
• о том, как соединять нейроны в сеть и почему это совсем не такое простое дело, как могло бы показаться.
А затем, обсудив все это, приведем живой пример сети, которая обучится распознавать рукописные цифры.
3.1. Когда появились искусственные нейронные сети
Но и простой гражданин должен читать Историю. Она мирит его с несовершенством видимого порядка вещей, как с обыкновенным явлением во всех веках...
Н. М. Карамзин. История государства Российского
Как мы уже говорили, нейронные сети — это пример математической конструкции, мотивированной и вдохновленной исследованиями человеческого мозга. Поэтому довольно естественно, что по меркам истории математики нейронные сети — достаточно молодой объект; они, очевидно, не могли появиться во времена Аристотеля, который считал, что мозг охлаждает кровь, и люди тем и отличаются от животных, что имеют большой орган для охлаждения крови и потому могут действовать более рационально. Однако по меркам истории искусственного интеллекта нейронные сети — это одна из старейших, самых первых конструкций, появившаяся еще до знаменитого эссе Тьюринга Computing Machinery and Intelligence, до Дартмутского семинара, до того, как появился собственно термин «искусственный интеллект».
По видимому, первой работой, предлагающей математическую модель нейрона и конструкцию искусственной нейронной сети, была статья Уоррена Маккаллоха (Warren McCulloch) и Уолтера Питтса[33] [356], опубликованная в 1943 году. Авторы отмечают, что из-за бинарной природы нейронной активности (нейрон либо «включен», либо «выключен», практически без промежуточных состояний) нейроны удобно описывать в терминах пропозициональной логики, а для нейронных сетей разрабатывают целый логический аппарат, формализующий ациклические графы. Сама конструкция искусственного нейрона, который у Маккаллоха и Питтса называется Threshold Logic Unit (TLU), или Linear Threshold Unit, получилась очень современной: линейная комбинация входов, которая затем поступает на вход нелинейности в виде «ступеньки», сравнивающей результат с некоторым порогом (threshold).
С одной стороны, работа Маккаллоха и Питтса еще не относилась к машинному обучению: в ней модели нейрона и нейронной сети были введены чисто логически, как система аксиом и правил вывода; затем с помощью этих правил был доказан ряд общих теорем. Авторы скорее рассуждали о том, что вообще можно было бы сделать с помощью таких искусственных нейронов, основанных на сравнении с порогом, чем пытались предложить конкретные работающие алгоритмы для этого. Такая «нейронная сеть» еще не умела обучаться ни в каком смысле слова, и ее непосредственный эффект был скорее в том, чтобы вообще предложить идею формализации нейронных сетей и нейронной активности, показав, что у нас в голове вполне может содержаться собранная из нейронов машина Тьюринга (идея машины Тьюринга тогда тоже была совсем свежей).
Статья Маккаллоха и Питтса прошла практически незамеченной среди нейробиологов, но создатель кибернетики Норберт Винер сразу понял перспективы искусственных нейронных сетей и идеи о том, как мышление может самопроизвольно возникать из таких простых логических элементов. Винер познакомил Маккаллоха и Питтса с фон Нейманом, и они впятером, вместе с когнитивистом Джеромом Леттвином, стали работать над тем, как адаптировать статистическую механику для моделирования мышления, а потом и построить работающий компьютер на основе моделирования нейронов. Память в таком компьютере предполагалось получить из замкнутых контуров активации нейронов, когда последовательная активация превращается в самоподдерживающийся процесс (в настоящем мозге очень много таких замкнутых контуров, и то, как они работают и для чего нужны, до сих пор не вполне ясно). Питтс считался самым гениальным ученым в этой группе и объявил, что пишет диссертацию о вероятностных трехмерных нейронных сетях, с трехмерной структурой связей между ними.
Диссертация Питтса наверняка стала бы очередным прорывом в кибернетике, но, к сожалению, закончилось все трагически. Жене Винера Маргарет категорически не нравились вечеринки, которые устраивал Маккаллох на своей ферме, и когда в 1952 году Маккаллох объявил, что переезжает в Кембридж, Маргарет рассказала Винеру о том, что эти «мальчики» якобы соблазнили их дочь Барбару, пока та гостила в доме Маккаллоха в Чикаго. На деле ничего такого, конечно, не было, но Винер поверил и мгновенно прекратил всякое общение с Маккаллохом и Питтсом. Для Питтса, который к тому времени уже был подвержен депрессиям, это стало поворотным моментом: он стал все больше пить, перестал появляться в MIT, сжег (!) свою диссертацию и все записи о ней, полностью прекратил заниматься наукой и умер в 46 лет от кровоизлияния, связанного с циррозом печени [174].
Другой первый шаг искусственных нейронных сетей, также весьма релевантный современным исследованиям, — это книга Дональда Хебба The Organization of Behaviour, вышедшая в 1949 году [209]. Сама книга относится скорее к нейробиологии, чем к математике, но некоторые ее части содержат ключевые идеи, послужившие основой всего дальнейшего обучения нейронных сетей. Основная конкретная идея, перешедшая из работ Хебба в современное машинное обучение практически без изменений, — это так называемое правило Хебба, которое сам Дональд Хебб в первоисточнике формулировал так: «Когда аксон клетки А находится достаточно близко, чтобы возбудить клетку В, и многократно или постоянно участвует в том, чтобы ее активировать, в одной или обеих клетках происходит некий процесс роста или изменение метаболизма, в результате которого эффективность А как клетки,
возбуждающей В, увеличивается». Проще говоря, если связь между двумя нейронами часто используется, она от этого упражняется и становится сильнее. Эта простая, но очень мощная идея не только мотивировала дальнейшие исследования, но и сама по себе легла в основу так называемого обучения по Хеббу (Hebbian learning), группы методов обучения без учителя, основанных на этом базовом правиле. В данной книге мы не будем подробно останавливаться на обучении по Хеббу, а просто упомянем сети Хопфилда (Hopfield networks) [230], обучение которых основано на этом принципе, а также недавние работы, связанные со временем активации нейронов. Дело в том, что Хебб говорил о причинном участии клетки А в активации нейрона В, а не просто одновременном срабатывании, то есть клетка А должна была все же срабатывать чуть раньше; современное развитие этой идеи известно как пластичность, зависящая от времени спайков (spike-timing dependent plasticity) [351,497].
Как только идеи Хебба оформились, тут же последовала их программная реализация; точнее, в те времена это была, конечно, реализация «в железе». В 1951 году Марвин Минский, которого мы уже не раз упоминали, и его аспирант Дин Эдмунд (Dean Edmund) построили сеть из сорока синапсов. Синапсы были случайным образом соединены друг с другом и обучались по правилам Хебба на основе вознаграждений, которые им давали исследователи. Эта модель получила название SNARC (Stochastic Neural Analog Reinforcement Calculator), и хотя непосредственного развития она не получила, можно сказать, что это первая настоящая реализация обучения с подкреплением (о котором речь пойдет в главе 9).
Следующим прорывом в нейробиологии стали работы Хьюбела и Визеля [235, 236,569], которые смогли достаточно подробно изучить активации нейронов в зрительной коре, что стало мотивацией для появления сверточных нейронных сетей и в некотором смысле глубокого обучения вообще (см. раздел 5.1). Но это было уже после появления первых перцептронов Розенблатта [455, 456], о которых пойдет речь в следующем разделе.
Завершая этот краткий исторический экскурс (впрочем, вся эта глава во многом рассказывает именно об истории развития нейронных сетей, так что к ней мы еще не раз вернемся), упомянем один подробный обзор современной истории нейронных сетей, работу Юргена Шмидхубера[34] [475]. Несмотря на то что это очень плотный и довольно сухой текст, зачастую представляющий собой просто набор ссылок, он выгодно отличается от многих других обзоров и исторических очерков тем, что анализирует именно историю идей', как развивались не просто нейронные
сети в целом, а конкретные конструкции и алгоритмы оптимизации, чего они достигали на каждом этапе развития, и где сейчас все эти идеи применяются. Кроме того, автор старается проследить историю каждой идеи до самых ее истоков, до первого появления в литературе, зачастую с неожиданными результатами. В подготовке этой книги мы не раз использовали обзор Шмидхубера и искренне его рекомендуем.
3.2. Как работает перцептрон
К 80-м годам двадцатого столетия... Минский и Гуд разработали методику автоматического зарождения и самовоспроизведения нервных цепей в соответствии с любой произвольно выбранной программой. Оказалось, что искусственный мозг можно «выращивать» посредством процесса, поразительно сходного с развитием человеческого мозга. Точные детали этого процесса в каждом отдельном случае так и оставались неизвестными; впрочем, будь они даже известны, человеческий разум не смог бы постичь всю их сложность.
А. Кларк. Космическая Одиссея 2001, пер. Н. Галь
Мы, люди старого века, мы полагаем, что без принсипов (Павел Петрович выговаривал это слово мягко, на французский манер, Аркадий, напротив, произносил «прынцип», налегая на первый слог), без принсипов, принятых, как ты говоришь, на веру, шагу ступить, дохнуть нельзя.
И. С. Тургенев. Отцы и дети
Итак, мы наконец-то приступаем к рассмотрению собственно математики происходящего. И начнем мы, конечно, с азов, с первой конструкции линейного перцептрона}, описанного еще Фрэнком Розенблаттом[35] [36] в 1950-х годах [455,456].
По сути своей перцептрон Розенблатта — это линейная модель классификации. В главе 1.3 мы уже обсуждали задачи классификации, а здесь будем иметь дело с самой простой, бинарной классификацией, когда все объекты в тренировочной выборке помечены одной из двух меток (скажем, +1 или -1), и задача состоит в том, чтобы научиться расставлять эти метки и у новых, ранее не виденных объектов. А «линейная модель» означает, что в результате обучения модель разделит все пространство входов на две части гиперплоскостью: правило принятия решения о том, какую метку ставить, будет линейной функцией от входящих признаков.
Для простоты мы будем считать, что каждый вход представляет собой вектор вещественных чисел х = (х^х 2,...,а^) £ и входы в тренировочном множестве снабжены известными выходами у(х) е {—1,1}. Вообще говоря, природа объектов на входе модели — это обычно больной вопрос в машинном обучении: часто нелегко сделать так, чтобы одна и та же модель могла принимать на вход и непрерывные, и дискретные признаки, но мы пока абстрагируемся от всех этих проблем. Тогда в наших терминах «линейная модель» означает, что мы будем искать такие веса wo,w... G Rd, чтобы знак линейной функции
sign (wo + w\x\ + W2X2... + WdXd) как можно чаще совпадал бы с правильным ответом у(х). Для удобства, чтобы не тащить везде за собой свободный член w$, мы введем в вектор х лишнюю «виртуальную» размерность и будем считать, что х выглядит как х = (1,д?1,Ж2, •. •,х^), их £ Rd+1; тогда wo + W\X\ + W2X2... + WdXd можно считать просто скалярным произведением w^x вектора весов w = (wo,wi,W2,... ,wd) на входной вектор х. Естественно, ни задача, ни ответ на нее от этого преобразования не меняются; это стандартный трюк, и мы часто будем им пользоваться.
Как обучать такую функцию? Сначала нужно выбрать функцию ошибки. Было бы, конечно, хорошо выбрать ее как число неверно классифицированных примеров. Но тогда, как мы обсуждали в разделе 2.3, получится кусочно-гладкая функция ошибки с массой разрывов: она будет принимать только целые значения и резко менять их при переходе от одного числа неверно классифицированных примеров к другому. Градиентный спуск к такой функции не применишь, и становится совершенно непонятно, как обучать w. Поэтому в перцептроне Розенблатта используется другая функция ошибки, так называемый критерий перцептрона:
Ep(w) = - (wT®),
Хем
где М обозначает множество тех примеров, которые перцептрон с весами w классифицирует неверно.
Иначе говоря, мы минимизируем суммарное отклонение наших ответов от правильных, но только в неправильную сторону; верный ответ ничего не вносит в функцию ошибки. Умножение на у(х) здесь нужно для того, чтобы знак произведения всегда получался отрицательным: если правильный ответ —1, значит, перцептрон выдал положительное число (иначе бы ответ был верным), и наоборот. В результате у нас получилась кусочно-линейная функция, дифференцируемая почти везде, а этого вполне достаточно.
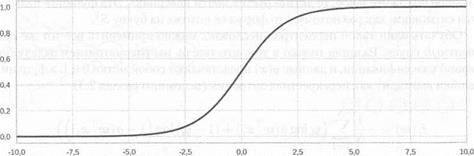
Рис. 3.1. Логистический сигмоид
Теперь мы можем оптимизировать ее градиентным спуском. На очередном ша-
| ге получаем:
| ЮС+1) _ w (r) _ n V w Ep(w) = Vl№ + r}t n x n.
|
Алгоритм такой — мы последовательно проходим примеры а?Ж2, ••• из обучающего множества, и для каждого хп
• если он классифицирован правильно, не меняем ничего;
• а если неправильно, прибавляем rjtnXn к w.
Ошибка на примере хп при этом, очевидно, уменьшается, но, конечно, совершенно никто не гарантирует, что вместе с тем не увеличится ошибка от других примеров. Это правило обновления весов так и называется — правило обучения перцептрона, и это было основной математической идеей работы Розенблатта.
Но и это еще не все. Чтобы двигаться дальше, нам нужно добавить в перцептрон еще один компонент — так называемую функцию активации. Дело в том, что в реальности перцептроны, как мы увидим буквально в следующем разделе, не могут быть линейными, как мы их определили сейчас: если они останутся линейными, то из них невозможно будет составить содержательную сеть. На выходе перцептрона обязательно присутствует нелинейная функция активации, которая принимает на вход все ту же линейную комбинацию. Функции активации бывают разными, и мы их подробно рассмотрим в разделе 3.3. Но самая классическая, наиболее популярная исторически и до сих пор часто используемая функция активации — это логистический сигмоид:
График его показан на рис. 3.1. Как и другие функции активации нейронов, это монотонно неубывающая функция, которая при х -со стремится к нулю, а при х -> оо стремится к единице; неформально говоря, это значит, что если на вход подают большое отрицательное число, то нейрон совсем не активируется, а если большое положительное, то активируется почти наверняка. Эта функция называется сигмоидом как раз потому, что форма ее похожа на букву S[37].
Обучать один такой перцептрон несложно: можно применить все тот же градиентный спуск. Разница только в том, что теперь мы рассматриваем задачу бинарной классификации, и данные у(х) представляют собой метки 0 и 1, а функция ошибки выглядит как перекрестная энтропия (вспомним раздел 2.3):
1 N
E(w) = (Уг + (1 - yi) log (1 - ar^T*;f)).
2=1
От этой функции по-прежнему несложно взять производную. В итоге перцептрон с логистическим сигмоидом в качестве функции активации фактически реализует логистическую регрессию и строит при этом линейные разделяющие поверхности.
Еще стоит отметить, что один перцептрон — это просто разновидность линейной ’ регрессии; мы говорили о линейной регрессии в разделе 2.2, где функцией ошибки был квадрат отклонения. И разные нелинейности на выходе одного нейрона можно рассматривать как разные формы функции ошибки. В обычной линейной регрессии нелинейности нет совсем, и ошибка считается как сумма квадратов отклонений: Е(х, у) = (у — wTx)[38]. В логистической регрессии добавляется сигмоид, и ошибка теперь считается как перекрестная энтропия; от этого задача регрессии превращается в задачу классификации, а выходы нейрона теперь можно интерпретировать как вероятности. И другие нелинейности, о которых мы поговорим ниже, тоже можно рассматривать как разные формы функции ошибки для базовой конструкции перцептрона — линейной комбинации входов.
Теперь, когда мы разобрались с конструкцией одного перцептрона, мы можем собрать из них целую сеть. Она будет представлять собой граф вычислений, который мы рассматривали в разделе 2.5. Один перцептрон может служить одним узлом в этом графе, выступая в роли элементарной функции: нам для этого требуется только уметь считать частные производные по всем переменным, что для перцептрона сделать совсем не сложно. В этой паре предложений произошел гигантский скачок: теперь мы фактически умеем обучать любые нейронные сети (кроме пока что рекуррентных), и для этого годится общий алгоритм обратного распространения, который мы обсудили в разделе 2.5. Конечно, обучать сложные сети буквально стохастическим градиентным спуском — не самая лучшая идея. Вся глава 4 будет посвящена разным способам заставить обучение работать лучше. И все же уже сейчас мы теоретически можем обучить сколь угодно сложную нейронную сеть!
| | | |
|  | |  |

Рис. 3.2. Основная идея архитектуры нейронных сетей: а — граф вычислений для
перцептрона; б — полносвязная нейронная сеть с одним скрытым уровнем и одним
выходным уровнем
На рис. 3.2 мы показали структуру одного перцептрона (рис. 3.2, а), которую уже подробно обсудили выше, а также пример простой нейронной сети (рис. 3.2, б). Каждый вход этой сети подается на вход каждому перцептрону «первого уровня». Затем выходы перцептронов «первого уровня» подаются на вход перцептронам «второго уровня», а их выходы уже считаются выходами всей сети целиком.
Есть еще одно важное замечание по поводу того, как объединять нейроны в сеть. Обычно в любой сети отдельные нейроны объединены в слои. Вектор входов подается сразу в несколько параллельных нейронов, у каждого из которых свои собственные веса, а затем выходы этих параллельных нейронов опять рассматриваются как единое целое, новый вектор выходов. Так, на рис. 3.2, б изображена сеть с одним скрытым слоем и одним выходным слоем, то есть всего их здесь два.
Казалось бы, для графа вычислений теоретически нет разницы, • какую именно архитектуру выбрать, все равно это всего лишь набор независимых нейронов. Однако концепция слоя очень важна с вычислительной, практической точки зрения. Дело в том, что вычисления в целом слое нейронов можно векторизовать, то есть представить в виде умножения матрицы на вектор и применения ' вектор-функции активации с одинаковыми компонентами. Если в слое К нейронов, и веса у них wi,wo,. ..,wc, Wi = (wn... win)т, а на вход подается вектор х = (^1 ж2 хп)т, то в результате мы получим у нейрона с весами wz выход уг — f(wJ ж), где f — его функция активации. Тогда вычисление, которое делают все нейроны сразу, можно будет представить в векторной форме так: и вычисление всего слоя сведется к умножению матрицы весов на вектор входов, а затем покомпонентному применению одной и той же функции активации. При этом оказывается, что матричные вычисления можно реализовать гораздо эффективнее, в частности на графических процессорах (видеокартах), чем те же вычисления, но представленные в виде обычных циклов. Поэтому такое векторизованное представление — это один из главных инструментов для того, чтобы перенести обучение и применение нейронных сетей на видеокарты, а это ускоряет все процессы буквально в десятки раз.
| /уЛ
| = y = f(Wx) =
|
| | \Ук/
|
| на
|
| |
В заключение этого раздела давайте еще на минутку вернемся к истории; теперь мы можем продолжить сюжет, начатый в разделе 1.2, и проследить историю первых перцептронов до конца. История искусственного интеллекта полна, простите за клише, взлетов и падений. Циклы чрезмерного оптимизма и неизбежных после этого разочарований, то, что по-английски называется boom-and-bust cycles, в истории развития методов машинного обучения были особенно яркими, ярче, чем в других науках. И неудивительно, ведь искусственный интеллект часто обещал продвижения, которые, с одной стороны, выглядят совершенно потрясающе — разговаривающие роботы! самодвижущиеся машины! автоматический поиск по всем книгам мира! — а с другой стороны, все время кажутся как бы «сразу за горизонтом», как будто вот-вот, еще немножко, и все получится, андроиды будут приятным голосом сообщать послезавтрашнюю погоду, приносить кофе и писать стихи, а нам останется только чувствовать себя белыми сахибами среди кремниевых слуг.
Конечно, раскручивали очередной виток спирали зачастую не сами ученые, а журналисты, и делали это с фантазией, но надо сказать, что ученые тоже скромностью не отличались. Например, мы с вами уже подробно рассмотрели перцептрон Розенблатта и увидели, что эта модель обучает простой линейный классификатор. А вот что писала о перцептроне The New York Times (вовсе не таблоид, так что вряд ли эта косвенная речь сильно искажена) 8 июля 1958 года: «Психолог показывает эмбрион компьютера, разработанного, чтобы читать и становиться мудрее. Разработанный ВМФ... стоивший 2 миллиона долларов компьютер “704”, обучился различать левое и правое после пятидесяти попыток... По утверждению ВМФ, они используют этот принцип, чтобы построить первую мыслящую машину класса “Перцептрон”, которая сможет читать и писать; разработку планируется завершить через год, с общей стоимостью $100 000... Ученые предсказывают, что позже Перцептроны смогут распознавать людей и называть их по имени, мгновенно переводить устную и письменную речь с одного языка на другой. Мистер Розенблатт сказал, что в принципе возможно построить “мозги”, которые смогут воспроизводить самих себя на конвейере и которые будут осознавать свое собственное существование». А в разделе 1.2 мы уже цитировали грантозаявку отцов-основателей на проведение Дартмутского семинара летом 1956 года, в которой они обещали «обучить машины использовать естественные языки, формировать абстракции и концепции... и улучшать самих себя». Оптимистическое было время, что и говорить.
Кстати, именно со «мгновенным переводом устной и письменной речи» вышел казус, который в свое время послужил спусковым крючком для первой настоящей «зимы искусственного интеллекта». Любопытно, что без русских здесь не обошлось; скорее, правда, Ruskies, чем Russians. Во времена холодной войны американскому правительству очень хотелось получить машину, которая могла бы быстро и надежно переводить документы с русского на английский и обратно. Начиная с 1954 года, соответствующие исследования активно спонсировались, и оптимизм был, опять же, безграничен: начало исследований в искусственном интеллекте совпало со знаменитыми разработками Ноама Хомского[39] [40] о трансформациях и порождающих грамматиках. Казалось, что естественный язык вот-вот получится описать достаточно просто и аналитически... но нет. После десяти лет исследований выяснилось, что машинный перевод — это все-таки очень и очень непростая задача, и даже различать омонимы совсем нелегко. Именно из этих исследований появился знаменитый пример двойного перевода, после которого the spirit is strong but the flesh is weak («дух силен, плоть слаба») превращается в the vodka is good but the meat is rotten («водка хорошая, но мясо протухло»); и, главное, все правильно! Теоретически такой смысл здесь тоже мог бы быть, просто для нас, знающих естественный язык и его не слишком очевидные особенности, вероятность такого прочтения ничтожно мала. А в середине 1960-х годов этот пример смешным вовсе не показался, ALPAC (Automatic Language Processing Advisory Committee — тогда в США очень любили создавать всевозможные комитеты) в своем отчете заключил, что машинный перевод получается гораздо хуже, дороже и медленнее человеческого, все финансирование свернули, и усилия в направлении машинного перевода прекратились надолго.
За перцептронами пришли немногим позже. В 1969 году Марвин Минский2 и Сеймур Пейперт опубликовали книгу с нехитрым названием «Перцептроны» [365], которая вызвала серьезное разочарование в конструкции перцептронов
Рис. 3.3. Пример линейно неразделимых множеств
Розенблатта. Эту историю часто рассказывают так, как будто бы основным аргументом Минского и Пейперта была линейность перцептрона. ’ И действительно, очевидно, что один перцептрон Розенблатта может обучиться разделять только те множества точек, между которыми можно провести гиперплоскость (такие множества логично называются линейно разделимыми), а на свете есть и масса других множеств! Например, одинокий линейный перцептрон никогда не обучится реализовывать функцию XOR: множество ее нулей и множество ее единиц, увы, линейно неразделимы. Например, на рис. 3.3 мы изобразили два множества точек, которые похожи на значения функции XOR: одно из них (звездочки) порождено из смеси нормальных распределений с центрами в точках (—1,1) и (1, — 1), а другое (точки) — из смеси нормальных распределений с центрами в точках (-1,-1) и (1,1). Действительно, хотя точки и звездочки очевидно занимают разные области на плоскости и легко отличимы, столь же очевидно, что никакая прямая линия не может адекватно их разделить. Другое возражение против линейной конструкции состоит в том, что комбинировать линейные перцептроны в сеть тоже не имеет никакого смысла: композиция линейных функций снова будет линейной, и сеть из любого, сколь угодно большого числа линейных перцептронов сможет реализовать только те же самые линейные функции, для которых было бы достаточно и одного.
Сегодня нам странно слышать, что это серьезные аргументы против: ну конечно, линейный классификатор не может реализовать XOR, но сеть из нескольких классификаторов с любой нелинейностью справится с этим без труда. Ну конечно, соединять линейные перцептроны в сеть бессмысленно, но как только мы добавим нелинейную функцию активации, даже самую простую, смысл тут же появится, и весьма, простите за каламбур, глубокий. И действительно, это понимали еще Маккаллох и Питтс (они и вовсе предлагали строить аналог машины Тьюринга на
своих перцептронах), и для Минского это тоже, конечно, не было секретом. Негативные утверждения в книге «Перцептроны» касались только некоторых конкретных архитектур: например, Минский и Пейперт показали, что сети с одним скрытым слоем не могут вычислять некоторые функции, если перцептроны скрытого слоя не связаны со всеми входами (раньше люди надеялись, что удастся обойтись «локальными» связями между перцептронами); в целом, ничего криминального. Однако в конце 1960-х годов о нейронных сетях и тем более глубоких сетях еще не было широко известно, хотя разрабатываться они уже начинали; и вышло так, что книга Минского и Пейперта, получившая широкую известность, надолго оттолкнула многих исследователей от того, чтобы продолжать изучение перцептронов и вообще нейронных сетей. Целых десять лет после этого заниматься нейронными сетями было немодно и неприбыльно; грантов на это практически не давали. Тем не менее, в 1970-е годы был достигнут очень серьезный прогресс в разработке и изучении нейронных сетей. Об этом мы поговорим в следующих главах, а пока вернемся к перцептрону и посмотрим, какие у него бывают функции активации в наше просвещенное время.
3.3. Современные перцептроны: функции активации
В области реального, физического наслаждения человек имеет не больше животного, помимо того, насколько его более потенцированная (возвышенная, утонченная) нервная система усиливает ощущения всякого наслаждения, а также и всякого страдания. Но зато какою силою отличаются возбуждаемые в нем аффекты, сравнительно с ощущениями животного! как несоразмерно сильнее и глубже волнуется его дух! и все из-за того, чтобы напоследок добиться того же результата: здоровья, пищи, крова и т. п.
А. Шопенгауэр. Parerga und Paralipomena
В наше время от базовой конструкции перцептрона, конечно же, никто не отказывается. Смысл и основная последовательность по-прежнему те же самые: сначала в перцептрон поступают входы из данных или предыдущих уровней сети, затем берется их линейная комбинация с некоторыми весами, которые, собственно, и будут обучаться в сети, а потом результат проходит через некоторую нелинейную функцию, без которой, как мы уже видели в этой главе, никакой выразительной силы у нейронной сети не получится. Именно из таких перцептронов, или нейронов, состоят все современные нейронные сети. Разница есть только в том, какова, собственно, конструкция нелинейности; и вот на этом вопросе уже стоит остановиться подробнее, он представляется чрезвычайно интересным.
Как мы уже говорили, исторически в нелинейных перцептронах обычно применялась функция активации (возбуждения нейрона) в виде логистического сигмоида: а{х) = Эта функция обладает всеми свойствами, необходимыми для
нелинейности в нейронной сети: она ограничена, стремится к нулю при х -> — оо и к единице при х -» ос, везде дифференцируема, и производную ее легко подсчитать как = с(:т)(1 — (т(х)). Но она такая, конечно же, не одна. Есть много разных функций активации, которые в разное время и для разных целей использовались в литературе. Некоторые из них показаны, для наглядности на одном и том же графике, на рис. 3.4; в этом разделе мы с ними познакомимся поближе.
Гиперболический тангенс:
еХ _ е-х
tanh(I) -
очень похож по свойствам на логистический сигмоид: он тоже непрерывен, тоже ограничен (правда, он стремится к —1 при х — -<х>, а не к нулю, но это, конечно, не важно), и производную от него тоже легко подсчитать через него самого:
t a ah(x) = 1 - tanh2 (я)
(проверьте сами!). По сравнению с логистическим сигмоидом гиперболический тангенс значительно «круче» растет и убывает, быстрее приближается к своим пределам; например, наклон касательной в нуле у тангенса tanhz(O) = 1, а у логистического сигмоида <7(0) =
Однако есть и более важная тонкая разница: для функции а ноль является точкой насыщения, то есть если пытаться обучить значение этой функции в ноль, вход будет стремиться к минус бесконечности, а производная — к нулю, это стабильное состояние. А для tanh ноль — это как раз самая нестабильная промежуточная точка, от нуля легко оттолкнуться и начать менять аргумент в любую сторону. О том, почему это важно, мы поговорим в разделе 4.2. Гиперболический тангенс часто используется в некоторых приложениях нейронных сетей, в частности в компьютерном зрении.
В качестве функции активации можно рассмотреть и обычную ступенчатую функцию, она же функция Хевисайда:
Эта функция использовалась в ранних конструкциях перцептронов. То, что она не определена в нуле, не очень мешает вести обучение: ее можно доопределить, например, как step(x) = да и на практике случайно попасть точно в ноль вряд ли получится. Один перцептрон со ступенчатой функцией активации обучить вполне возможно. Для этого достаточно просто точно так же подсчитывать

Рис. 3.4. Различные функции активации
«мягкий» результат в виде комбинации входов и весов, но затем превращать его в «жесткое» решение: если «мягкий» результат меньше нуля, выдаем один ответ, если больше нуля, — другой. На последнем шаге классификатора это совершенно нормально, и процессу обучения не мешает.
Но сеть с несколькими уровнями на ступенчатых функциях активации, к сожалению, не построишь, ведь производная от ступеньки просто всегда равна нулю (кроме, опять же, нуля, где она не определена). Таким образом, в нейронной сети из перцептронов со ступенчатыми функциями активации градиенты не дойдут от выходов к входам: по дороге градиент будет умножаться на производную функции step, и ничего кроме нулей не получится...
Разобравшись с классическими функциями активации, давайте двигаться к современности. Здесь тоже есть о чем рассказать. Главная идея, во многом изменившая архитектурные основы современных нейронных сетей, — это так называемые rectified linear units (ReLU). Функция активации у них кусочно-линейная:
если х < 0,
если х > 0.
То же самое можно записать более кратко: ReLU(z) = max(0,:r). И снова мы должны сказать, что это не вполне современная идея: такие искусственные нейроны использовались еще в начале 1980-х годов в модели многоуровневых сетей Кунихико Фукусимы для распознавания образов, получившей название Neocognitron [166,167].
Однако потом от них надолго отказались, и возрождение ReLU произошло уже в разгар революции глубокого обучения; желающим углубиться в детали мы предложим работы [382], где ReLU-активация подробно мотивирована и описана в контексте ограниченных машин Больцмана, и [180], где практическая польза ReLU становится очевидной и в «обычных» нейронных сетях. А сами кратко пройдемся по основным идеям, которые приводят ReLU-нейроны к успеху.
Прежде всего отметим, что ReLU-нейроны эффективнее основанных на логистическом сигмоиде и гиперболическом тангенсе. Например, чтобы подсчитать производную сг'(с), нужно вычислить непростую функцию а затем умножить а(х) на 1 - а(х)\ с тангенсом примерно та же история, только нужно возводить в квадрат. А чтобы вычислить производную ReLU'(x), нужно ровно одно сравнение: если х меньше нуля, выдаем ноль, если больше нуля, — единицу. На первый взгляд это кажется несущественным, но на практике означает, что основанные на ReLU-нейронах сети при одном и том же «вычислительном бюджете» на обучение, на одном и том же «железе» могут быть значительно больше (по размеру, то есть по числу нейронов), чем сети с более сложными функциями активации. Однако сам по себе этот аргумент мало что значит: в конце концов, чтобы подсчитать производную ступенчатой функц