Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов...
Процессором называют программно-управляемое устройство, осуществляющее процесс обработки информации и управление им. Первые процессоры строились с использованием элементной базы общего назначения. В настоящее время процессоры используют специализированные большие или сверхбольшие интегральные схемы (БИС/СБИС),
Микропроцессром (МП) называют построенное на одной или нескольких БИС/СБИС программно-управляемое устройство, осуществляющее процесс обработки информации и управление им. МП появились, когда уровень интеграции ИС достиг значений, при которых необходимые для программной реализации алгоритмов блоки удалось разместить на одном или нескольких кристаллах. В настоящее время понятия процессор и МП эквивалентны.
МП система (МПС) – совокупность МП, памяти и устройства ввода/вывода (внешние устройства). Решаемая задача определяется реализуемой МП программой, структура МПС остается неизменной, что и определяет ее универсальность.
Совокупность БИС/СБИС, пригодных для совместного применения в МПС, называют МП комплектом (МПК). Понятие МПК задает номенклатуру микросхем с точки зрения возможностей их совместного применения (совместимость по архитектуре, электрическим параметрам, конструктивным признакам и др.). В состав МПК могут входить микросхемы различных серий и схемотехнологических типов при условии их совместимости.
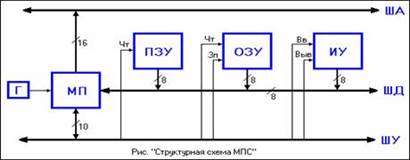
Структура МПС
Практически всегда структура МПС является магистрально-модульной. В такой структуре имеется группа магистралей (шин), к которым подключаются различные модули (блоки), обменивающиеся между собой информацией поочередно, в режиме разделения времени.
Термин "шины" относится к совокупности цепей (линий), число которых определяет разрядность шины.
Типична 3-шинная структура МПС с шинами адресов ША, данных ШД и управления ШУ. Наряду с русскими терминами применяются английские АВ (Address Bus), DB (Data Bus) и СВ (Control Bus).
Структура МПС с простым МП от Intel, который имеет мультиплексируемую шину адресов/данных.
Микропроцессор МП. Выполняя программу, МП обрабатывает команду за командой. Команда задает выполняемую операцию и содержит сведения об участвующих в ней операндах. После приема команды происходит ее расшифровка и выполнение, в ходе которого МП получает необходимые данные из памяти или внешних устройств. Ячейки памяти и внешние устройства (порты) имеют номера, называемые адресами, которыми они обозначаются в программе.
Генератор Г задает МП тактовые импульсы. По каждому МП выполняет команду.
Однонаправленная адресная шина ША. По ней МП посылает адреса, определяя объект, с которым будет обмен.
Двунаправленная шина данных ШД. По ней МП обменивается данными с модулями (блоками) системы.
Шина управления ШУ. По ней идет обмен управляющей информацией.
Постоянное запоминающее устройство - ПЗУ (ROM – Read Only Memory) хранит фиксированные программы и данные, оно является энергонезависимым и при выключении питания информацию не теряет.
Оперативное запоминающее устройство - ОЗУ (RAM - Random Access Memory) хранит оперативные данные (изменяемые программы, промежуточные результаты вычислений и др.), является энергозависимым и теряет информацию при выключении питания. Для приведения системы в работоспособное состояние после включения питания ОЗУ следует загрузить необходимой информацией.
Интерфейс управления ИУ. Осуществляет взаимодействие с устройствами ввода-вывода (УВВ) или внешними устройствами (ВУ) - техническими средствами для передачи данных извне в МП или память либо из МП или памяти во внешнюю среду. Для подключения ВУ необходимо привести их сигналы, форматы слов, скорость передачи и т. п. к стандартному виду, воспринимаемому данным МП. Это выполняется специальными блоками, называемыми адаптерами (интерфейсными блоками ввода-вывода). Интерфейсом называют совокупность аппаратных и программных средств, унифицирующих процессы обмена между модулями системы.
Кроме обозначенных блоков, в состав систем входят обычно и более сложные, чем адаптеры, блоки управления внешними устройствами - контроллеры. К их числу относятся контроллеры прерываний, прямого доступа к памяти,оллеры клавиатуры, дисплея, дисковой памяти и т. д.
Контроллеры прерываний обеспечивают обмен с внешними устройствами в режиме прерывания (временной остановки) выполняемой программы для обслуживания запроса от внешнего устройства.
Контроллеры прямого доступа к памяти обслуживают режим прямой связи между внешними устройствами и памятью без участия МП. При управлении обменом со стороны МП пересылка данных между внешними устройствами и памятью происходит в два этапа — сначала данные принимаются МПом, а затем выдаются им на приемник данных. В режиме прямого доступа к памяти МП отключается от шин системы и передает управление ими контроллеру прямого доступа, а передачи данных осуществляются в один этап — непосредственно от источника к приемнику.
В состав МПС часто входят также программируемые таймеры, формирующие различные сигналы (интервалы, последовательности импульсов и т. д.) для проведения операций, связанных со временем.
В современных МП системах используются наборы микросхем (Chip sets), которые соединяют компонеты:
· Северный мост для связи МП с памятью.
· Южный мост для ввода-вывода.
Основные понятия в архитектуре МПС
Архитектура вычислительной машины — концептуальная структура вычислительной машины, определяющая проведение обработки информации и включающая методы преобразования информации в данные и принципы взаимодействия технических средств и программного обеспечения. В более подробное описание, определяющее конкретную архитектуру, также входят:
· структурная схема ЭВМ,
· средства и способы доступа к элементам этой структурной схемы,
· организация и разрядность интерфейсов ЭВМ,
· набор и доступность регистров,
· организация памяти и способы её адресации,
· набор и формат машинных команд процессора,
· способы представления и форматы данных, правила обработки прерываний.
По перечисленным признакам и их сочетаниям среди архитектур выделяют:
· По разрядности интерфейсов и машинных слов: 8-, 16-, 32-, 64-, 128- разрядные (ряд ЭВМ имеет и иные разрядности).
· По особенностям набора регистров, формата команд и данных: CISC, RISC, VLIW;
· По количеству центральных процессоров: однопроцессорные, многопроцессорные, суперскалярные.
Многопроцессорные по принципу взаимодействия с памятью делят на:
· симметричные многопроцессорные (SMP),
· массивно-параллельные (MPP),
· распределенные.
Аппаратная платформа включает:
· АСК - Архитектура системы команд (ISA - instruction set architecture). АСК — это приблизительно то же самое, что и модель программирования, с точки зрения программиста на языке ассемблера или создателя компилятора.
· Микропрограмма (firmware - микрокод). Это системное программное обеспечение, встроенное («зашитое») в аппаратное устройство, и хранящееся в его энергонезависимой памяти ПЗУ.
· Микроархитектура (иногда сокращаемая до µarch или uarch) — это способ, которым данная архитектура набора команд реализована в процессоре. Каждая архитектура может быть реализована с помощью различных микроархитектур. Реализации могут варьироваться в зависимости от целей данного дизайна или в результате изменений в технологиях. Архитектура компьютера является комбинацией микроархитектуры, микрокода и архитектуры.
Центральный процеессор ЦП (или центральное процессорное устройство — ЦП; central processing unit - CPU) - микросхема, исполнитель машинных инструкций (кода программ), главная часть аппаратного обеспечения компьютера. Иногда называют МП или просто процессором.
Архитектура фон Неймана
Большинство современных процессоров основаны на той или иной версии циклического процесса последовательной обработки данных, изобретённого Джоном фон Нейманом в 1946.
Отличительной особенностью архитектуры фон Неймана (иначе принстонской) является то, что инструкции и данные хранятся в одной и той же памяти по разным адресам.
.
Важнейшие этапы процесса работы МП приведены ниже. В различных архитектурах и для различных команд могут потребоваться дополнительные этапы. Например, для арифметических команд могут потребоваться дополнительные обращения к памяти, во время которых производится считывание операндов и запись результатов.
Этапы цикла выполнения:
· МП выставляет число, хранящееся в регистре счётчика команд, на шину адреса ША и по шине управления ШУ отдаёт памяти команду чтения.
· Выставленное число является для памяти адресом. Память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных ШД и по шине ШУ сообщает о готовности.
· МП получает число с шины данных, интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её (по подпрограмме, хранимой в ПЗУ).
· Если последняя команда не является командой перехода, то МП увеличивает на единицу (в предположении, что длина каждой команды равна единице) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды.
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса МП считывает последовательность команд, содержащихся в памяти, и исполняет их. Такая последовательность команд называется программой и представляет алгоритм работы МП. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода, тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды останова или переключение в режим обработки прерывания.
Команды МП являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно. Не производится никакой проверки на допустимость выполняемых действий, в частности, не проверяется возможная потеря ценных данных. Чтобы компьютер выполнял только допустимые действия, команды должны быть соответствующим образом организованы в виде необходимой программы.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов в секунду называется тактовой частотой.
Гарвардская архитектура
Существует альтернативный тип архитектуры МП системы — это архитектура с раздельными шинами данных и команд (двухшинная, или гарвардская). Эта архитектура предполагает наличие в системе отдельной памяти для данных и отдельной памяти для команд. Обмен процессора с каждым из двух типов памяти происходит по своей шине.
В случае двухшинной архитектуры обмен по обеим шинам может быть независимым, параллельным во времени. Соответственно, структуры шин (количество разрядов кода адреса и кода данных, порядок и скорость обмена информацией и т.д.) могут быть выбраны оптимально для той задачи, которая решается каждой шиной. Поэтому при прочих равных условиях переход на двухшинную архитектуру ускоряет работу МП системы, хотя и требует дополнительных затрат на аппаратуру, усложнения структуры процессора. Память данных в этом случае имеет свое распределение адресов, а память команд — свое.
Архитектура с раздельными шинами данных и команд сложнее, она заставляет процессор работать одновременно с двумя потоками кодов, обслуживать обмен по двум шинам одновременно. Программа может размещаться только в памяти команд, данные — только в памяти данных. Такая узкая специализация ограничивает круг задач, решаемых системой, так как не дает возможности гибкого перераспределения памяти. Память данных и память команд в этом случае имеют не слишком большой объем, поэтому применение систем с данной архитектурой ограничивается обычно не слишком сложными задачами.
В чем же преимущество архитектуры с двумя шинами (гарвардской)? В первую очередь, в быстродействии. Проще всего преимущества двухшинной архитектуры реализуются внутри одной микросхемы. В этом случае можно также существенно уменьшить влияние недостатков этой архитектуры. Поэтому основное ее применение — в микроконтроллерах, от которых не требуется решения слишком сложных задач, но зато необходимо максимальное быстродействие при заданной тактовой частоте.
Параллельная архитектура
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через МП, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах. Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
· SISD — один поток команд, один поток данных;
· SIMD — один поток команд, много потоков данных;
· MISD — много потоков команд, один поток данных;
· MIMD — много потоков команд, много потоков данных.
Конвейерная архитектура
Конвейерная архитектура (Pipelining) была введена в ЦП с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифровка команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер МП с архитектурой IA-32 содержит 6 модулей, корые выполняют стадии обработки:
· Модуль шинного интерфейса, ввод/вывод данных.
· Модуль предварительной выборки, считывание инструкции и помещение ее в очередь.
· Модуль декодирования, выборка инструкции из очереди и ее декодирование.
· Модуль выполнения, исполняет последовательность инструкций, полученных от модуля декодирования. операций,
· Модуль сегментации, преобразует логические адреса в линейные адреса и выполняет проверки, связанные с защитой памяти.
· Модуль страничной организации преобразует линейные адреса в физические адреса памяти, выполняет проверки адресов, связанные с защитой страниц памяти, а также ведет список страниц, к которым недавно осуществлялся
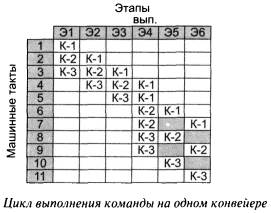
Предположим, что каждый этап выполнения команды в процессоре длится ровно 1 машинный такт. На рисунке показана матрица шестиступенчатого выполнения команд в процессоре, не поддерживающем режим конвейерной обработки. Подобный режим выполнения команд был реализован в процессорах фирмы Intel до появления на свет модели Intel486.
Как только завершается этап Э6 выполнения команды К-1, начинается выполнение этапа Э1 команды К-2. При этом для выполнения двух команд К-1 и К-2 требуется 12 машинных тактов. Другими словами, если цикл выполнения команды состоит из к этапов, то для выполнения последовательности из n команд потребуется n x к машинных тактов. Очевидно, что подобный ЦП работает крайне неэффективно, поскольку за 1 машинный такт выполняется только одна шестая часть команды.
В то же время, если в процессоре поддерживается режим конвейерной обработки, то уже на втором машинном такте процессор может приступить к этапу Э1 выполнения новой команды. При этом предыдущая команда будет находиться на этапе Э2 своего выполнения. Таким образом, конвейерная обработка позволяет совместить выполнение двух машинных команд во времени. Как только процессор переходит к этапу Э2 выполнения команды K1, начинается выполнение этапа Э1 команды К-2. Вследствие этогодля выполнения 2 машинных команд требуется уже не 12, а всего лишь 7 машинных тактов. При полной загрузке конвейера, в текуший момент времени работают все 6 его ступеней.
Факторы, снижающие эффективность конвейера:
· Простой конвейера, когда некоторые ступени не используются (например, адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами).
· Ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд — out-of-order execution).
· Очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода). Не существует единого мнения по поводу оптимальной длины конвейера: различные программы могут иметь существенно различные требования.
Процессор с одним конвейером называется скалярным.
Суперскалярная архитектура
Процессор, построенный по суперскалярной архитектуре, имеет 2 (или больше) конвейера для выполнения команд. Это позволяет одновременно выполнять 2 (или больше) команды. Чтобы лучше понять целесообразность применения суперскалярной архитектуры в процессоре, давайте рассмотрим предыдущий пример конвейерной обработки, в котором мы для упрощения предполагали, что этап выполнения команды (Э4) длится всего 1 машинный такт. А что же произойдет, если этап выполнения команды Э4 длится 2 машинных такта? Тогда в работе конвейера возникнут сбои, как показано на рисунке.
Процессор не сможет перейти к фазе выполнения Э4 команды K2, пока он полностью не завершит фазу выполнения команды K1. В результате цикл выполнения команды К-2 увеличится на 1 машинный такт, т.е. на время ожидания освобождения конвейера на этапе Э4. По мере поступления на конвейер дополнительных команд, некоторые его ступени будут работать вхолостую (на рисунке они выделены серым цветом).
Для борьбы с простоями оборудования используются нескольео конвеййеров. В процессоре Intel Pentium было применено 2 конвейера. Он стал первым процессором семейства IA-32, построенным по суперскалярной архитектуре. В процессоре Pentium Рго впервые было применено 3 конвейера.
Продолжим рассмотрение нашего примера шестиступенчатого конвейера и введем в него еше один (т.е. второй) конвейер. Как и раньше мы будем предполагать, что фаза выполнения команды Э4 длится 2 машинных такта. Как показано на рисунке, команда с нечетным номером поступает на u-конвейер, а команда с четным номером — на v-конвейер. Подобный подход позволяет ликвидировать простои в работе конвейера.
В МП с такой архитектурой применяется распараллеливание исполнения команд между несколькими конвейерами, причём решение о параллельном исполнении команд принимается аппаратурой процессора на этапе исполнения. Эффективное использование такой архитектуры требует специальной оптимизации машинного кода в компиляторе для генерации пар независимых команд (когда результат одной команды не является аргументом другой).
Суперскалярные МП могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств.
В типичной суперскалярной машине аппаратура может осуществлять выдачу от 1 до 8 команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной
Архитектура VLIW
Архитектуры VLIW (Very Long Instruction Word) используют очень длинное слово команды. Отличаются от суперскалярной архитектуры тем, что решение о распараллеливании принимается компилятором на этапе генерации кода, а не аппаратурой на этапе исполнения. Команды очень длинны и содержат явные инструкции по распараллеливанию нескольких субкоманд на несколько устройств исполнения.
VLIW процессором в его классическом виде является Itanium. Разработка эффективного компилятора для VLIW является сложнейшей задачей. Преимущество VLIW перед суперскалярной архитектурой заключается в том, что компилятор может быть более развитым, нежели устройства управления процессора, и он способен хранить больше контекстной информации для принятия более верных решений по оптимизации.
VLIW - архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно. Задача распределения между ними работы решается программно
Архитектуры CISC, RISC
Архитектура CISC – это классическая архитектура. В ней использована полная система команд (около 300 команд), из которых практически используется третья часть. В настоящее время применяется для совместимости с созданными ранее программами.
Пример использования - иямикроконтроллер MCS-51 (Intel 8051). Для него существует кросс-ассемблер ASM51, выпущенный корпорацией MetaLink. Кроме того, многие фирмы — разработчики программного обеспечения, такие как IAR или Keil, представили свои варианты ассемблеров. В ряде случаев применение этих ассемблеров оказывается более эффективным благодаря удобному набору директив и наличию среды программирования, объединяющей в себе профессиональный ассемблер и язык программирования Си, отладчик и менеджер программных проектов.
Архитектура RISC – это современная архитектура. В ней использована сокращенная система команд, из которых практически все используются. Наиболее употребим реализация AVR. На данный момент существуют 2 компилятора производства Atmel (AVRStudio 3 и AVRStudio4). Вторая версия — попытка исправить не очень удачную первую.
Ассемблеры
Программа Ассемблер
Ассемблер (assembler — сборщик) — компьютерная программа, компилятор исходного текста программы, написанной на языке ассемблера, в программу на машинном языке.
Как и сам язык ассемблера, ассемблеры, как правило, специфичны конкретной архитектуре, операционной системе и варианту синтаксиса языка. Вместе с тем существуют мультиплатформенные или вовсе универсальные (точнее, ограниченно-универсальные, потому что на языке низкого уровня нельзя написать аппаратно-независимые программы) ассемблеры, которые могут работать на разных платформах и операционных системах. Среди последних можно также выделить группу кросс-ассемблеров, способных собирать машинный код и исполняемые модули (файлы) для других архитектур и ОС.
Ассемблирование может быть не первым и не последним этапом на пути получения исполнимого модуля программы. Так, многие компиляторы с языков программирования высокого уровня выдают результат в виде программы на языке ассемблера, которую в дальнейшем обрабатывает ассемблер. Также результатом ассемблирования может быть не исполнимый, а объектный модуль, содержащий разрозненные и непривязанные друг к другу части машинного кода и данных программы, из которого (или из нескольких объектных модулей) в дальнейшем с помощью программы-компоновщика («линкера») может быть скомпонован исполнимый файл.
Ассемблеры для DOS. Наиболее известными ассемблерами для операционной системы DOS являлись Borland Turbo Assembler (TASM), Microsoft Macro Assembler (MASM) и Watcom Assembler (WASM). Также в своё время был популярен простой ассемблер A86.
Ассемблеры для Windows. При появлении операционной системы Windows появилось расширение TASM, именуемое TASM 5+ (неофициальный пакет, созданный человеком с ником!tE), позволившее создавать программы для выполнения в среде Windows. Последняя известная версия TASM — 5.3, поддерживающая инструкции MMX, на данный момент включена в Turbo C++ Explorer. Но официально развитие программы полностью остановлено.
Microsoft поддерживает свой продукт под названием Microsoft Macro Assembler (MASM). Она продолжает развиваться и по сей день.. Но версия программы, направленная на создание программ для DOS, не развивается. Кроме того, Стивен Хатчессон создал пакет для программирования на MASM под названием «MASM32».
Ассемблеры для GNU и GNU/Linux. В состав операционной системы GNU входит пакет binutils, включающий в себя ассемблер gas (GNU Assembler), использующий AT&T-синтаксис, в отличие от большинства других популярных ассемблеров, которые используют Intel-синтаксис (поддерживается с версии 2.10).
Переносимые ассемблеры.
Также существует открытый проект ассемблера, версии которого доступны под различные операционные системы, и который позволяет получать объектные файлы для этих систем. Это:
· NASM (Netwide Assembler).
· YASM — это переписанная с нуля версия NASM под лицензией BSD (с некоторыми исключениями).
· FASM (flat assembler) — молодой ассемблер под модифицированной для запрета перелицензирования BSD-лицензией. Есть версии для Linux, DOS и Windows; использует Intel -синтаксис.
Язык Ассемблер
Язы́к Ассе́мблер — язык программирования низкого уровня, мнемонические команды которого (за редким исключением) соответствуют инструкциям процессора вычислительной системы. Трансляция программы в исполняемый машинный код производится программой Аассемблер - транслятором, которая и дала языку ассемблера его название.
Команды языка ассемблера один к одному соответствуют командам процессора, фактически, они представляют собой более удобную для человека символьную форму записи (мнемокод) команд и их аргументов. При этом одной команде языка ассемблера может соответствовать несколько вариантов команд процессора, в зависимости от операндов.
Кроме того, язык ассемблера позволяет использовать символические метки вместо адресов ячеек памяти, которые при ассемблировании заменяются на автоматически рассчитываемые абсолютные или относительные адреса, а также так называемые директивы (команды, не переводящиеся в процессорные инструкции, а выполняемые самим ассемблером).
Директивы ассемблера позволяют, в частности, включать блоки данных, задать ассемблирование фрагмента программы по условию, задать значения меток, использовать макроопределения с параметрами.
Каждая модель (или семейство) процессоров имеет свой набор команд и соответствующий ему язык ассемблера. Наиболее популярные синтаксисы — Intel-синтаксис и AT&T-синтаксис.
Достоинства:
· При достаточной квалификации программиста, язык ассемблера позволяет писать самый быстрый и компактный код. Возможно, даже лучше, чем генерируемый трансляторами языков более высокого уровня.
· Если код программы достаточно большой, данные, которыми он оперирует, не помещаются целиком в регистрах процессора, то есть частично или полностью находятся в оперативной памяти, то искусный программист, как правило, способен значительно оптимизировать программу по сравнению с высокоуровневыми трансляторами по одному или нескольким параметрам: скорость работы (за счёт оптимизации вычислений и/или более рационального обращения к ОП, перераспределения данных), объём кода (в том числе за счёт эффективного использования промежуточных результатов).
· Обеспечение максимального использования специфических возможностей конкретной платформы, что также позволяет создавать более эффективные программы с меньшими затратами ресурсов.
· При программировании на языке ассемблера возможен непосредственный доступ к аппаратуре, в том числе портам ввода-вывода, регистрам процессора и др.
· Язык ассемблера применяется для создания драйверов оборудования и ядра операционной системы.
· Язык ассемблера используется для создания «прошивок» BIOS.
· С помощью языка ассемблера создаются компиляторы и интерпретаторы языков высокого уровня, а также реализуется совместимость платформ.
· Существует возможность исследования других программ с отсутствующим исходным кодом с помощью дизассемблера.
Недостатки:
· В силу машинной ориентации («низкого» уровня) языка ассемблера человеку сложнее читать и понимать программу на нём по сравнению с языками программирования высокого уровня; программа состоит из слишком «мелких» элементов — машинных команд, соответственно, усложняются программирование и отладка, растёт трудоёмкость, велика вероятность внесения ошибок.
· Требуется высокая квалификация программиста. Код на ассемблере выполняется быстрее, но написанный неопытным программистом, обычно оказывается хуже сгенерированного компилятором[2]
· Как правило, меньшее количество доступных библиотек по сравнению с современными индустриальными языками программирования.
· Отсутствует переносимость программ на компьютеры с другой архитектурой и системой команд.
API функции
Ниже перечислены основные функции API, применяемые в ассемблере.
Функция
Назначение функции
AllocConsole
Создать консоль
Arc
Рисовать дугу
BeginPaint
Получить контекст при получении сообщения WM_PAINT
BitBlt
Скопировать виртуальную прямоугольную область в окно