Е.Е. Минина
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ИНФОРМАТИКИ
Методические указания по выполнению самостоятельной работы для аспирантов очной и заочной форм обучения на базе высшего образования
для специальностей 05.12.13 «Системы, сети и устройства телекоммуникаций» 08.00.05 «Экономика и управление народным хозяйством (по отраслям)»
05.13.15 «Вычислительные машины, комплексы и компьютерные сети»
Екатеринбург
ББК 22.19
УДК 517.9
Рецензент: к.п.н., доцент кафедры информатики вычислительной техники и методики обучения информатике А.И. Газейкина
Минина Е.Е.
Теоретические основы информатики: Методические указания к самостоятельным работам / Е.Е. Минина. — Екатеринбург: УрТИСИ ГОУ ВПО «СибГУТИ», 2010. —29с.
Методические указания содержат темы для подготовки рефератов, теоретический материал и задания по темам:
Рекомендовано НМС УрТИСИ ГОУ ВПО СибГУТИ в качестве методических указаний по выполнению самостоятельной работы аспирантами для специальностей 05.12.13 «Системы, сети и устройства телекоммуникаций», 08.00.05 «Экономика и управление народным хозяйством (по отраслям)», 05.13.15 «Вычислительные машины, комплексы и компьютерные сети»
ББК 22.19
УДК 517.9
Кафедра информационных систем и технологий
Ó УрТИСИ ГОУ ВПО «СибГУТИ», 2010
Содержание
1 Пояснительная записка. 4
2 Темы для подготовки рефератов. 5
3 Элементы теории кодирования. 6
3.1 Основные понятия теории кодирования. 6
3.2 Кодирование целых чисел. 8
3.3 Алфавитное кодирование. 11
3.4 Оптимальное алфавитное кодирование. 14
3.5 Почти оптимальное алфавитное кодирование. 18
Литература. 29
Пояснительная записка
Данное пособие разработано с целью оказания методической помощи аспирантам во время их самостоятельной работы по дисциплине «Теоретические основы информатики».
В пособии приведены темы для подготовки и написания рефератов. Темы отражают круг основных вопросов дисциплины. Так же приведен теоретический материал для углубления и осознания некоторых тем курса. Пособие содержит перечень рекомендованной основной и дополнительной литературы.
Рабочей программой курса предусмотрены следующие виды самостоятельной работы студентов:
| Виды и содержание самостоятельной работы
| Кол-во часов
|
| 1. Подготовка реферата
|
|
| 2. Изучение дополнительного материала по изучаемым темам и подготовка к лабораторным работам
|
|
| 3. Подготовка и написание статьи
|
|
| Итого:
|
|
2 Темы для подготовки рефератов
1. Информация и ее сущность в информационно-энергетической концепции строения Вселенной.
2. Энтропия и количество информации по К. Шеннону и их свойства.
3. Синтактические меры количества и прагматические характеристики качества информации.
4. Информация и работы Чижевского.
5. Учение В.И. Вернадского о ноосфере и информация.
6. Психология информатики.
7. Модели и моделирование.
8. Предельные теоремы (законы) сложных систем.
9. Самореферентные системы.
10. Квантовые вычислители и вычисления.
11. Хаос и информатика.
12. Синергетика.
13. Биоэнергоинформатика.
14. Компьютерная лингвистика.
15. Компьютерная преступность и правовая охрана интеллектуальной собственности.
16. Технологический процесс в системных методах исследования.
17. Метрическое пространство. (n-мерное Евклидово пространство.Функциональное пространство: основные понятия, метрики, неравенства.)
18. Линейные пространства. Линейная зависимость. Функционалы. Нормированные пространства.
19. Случайные сигналы и их модели.
20. Статический анализ сигналов: анализ распределений, корреляционный, спектральный. Фильтрация сигналов.
21. Теоремы Шеннона об оптимальном кодировании информации.
22. Канал связи и его пропускная способность. Теорема Шеннона о скорости передачи информации по каналу связи.
23. Помехоустойчивые коды.
24. Множества и пространства сигналов. Отображения и функционалы от сигналов. Преобразования Фурье и представление сигналов рядами.
25. Аналоговые, когнитивные и нейрокомпьютерные средства информатики.
26. Языки программирования. Перспективы развития.
27. Эстетика и информатика.
28. Фракталы и области их применения.
29. Представление знаний.
30. Нейрокомпьютеры и интеллектуальные сети.
Элементы теории кодирования
Основные понятия теории кодирования
Теория кодирования и теория информации возникли в начале XX века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К. Шеннона, которые заложили фундамент для дальнейших исследований в этой области.
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов:

Рисунок 1 -Модель системы передачи сигналов
Кодирование – способ представления информации в виде, удобном для хранения и передачи.
В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач программирования:
1. Представление данных произвольной структуры (числа, текст, графика) в памяти компьютера.
2. Обеспечение помехоустойчивости при передаче данных по каналам связи.
3. Сжатие информации в базах данных.
Под сжатием понимается компактное представление данных, осуществляемое за счет избыточности, содержащейся в сообщениях. Большое значение для практического использования имеет неискажающее сжатие, позволяющее полностью восстановить исходное сообщение. При неискажающем сжатии происходит кодирование сообщения перед началом передачи или хранения, а после окончания процесса сообщение однозначно декодируется (это соответствует модели канала без шума (помех)).
Начальным звеном в приведенной выше модели являетсяисточник информации. Мы будем рассматривать дискретные источники, в которых выходом является последовательность символов некоторого фиксированного алфавита. Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 32 русских букв, пробела и знаков препинания.
Кодирование дискретного источника заключается в сопоставлении символов алфавита А источника символам некоторого другого алфавита В. Причем обычно символу исходного алфавита А ставится в соответствие не один, а группа символов алфавита В, называемых кодовым словом.Кодовый алфавит – множество различных символов, используемых для записи кодовых слов.Кодом называется совокупность всех кодовых слов, применяемых для представления порождаемых источником символов.
Пример. Азбука Морзе является общеизвестным кодом из символов телеграфного алфавита, в котором буквам русского языка соответствуют кодовые слова (последовательности) из «точек» и «тире».
Далее будем рассматривать двоичное кодирование, т.е. размер кодового алфавита равен 2. Конечную последовательность битов (0 и 1) назовем кодовым словом, а количество битов в этой последовательности – длиной кодового слова.
Пример. Код ASCII (американский стандартный код для обмена информацией) каждому символу ставит в однозначное соответствие кодовое слово длиной 8 бит.
Пусть даны алфавит источника А={a1, …,an}, кодовый алфавит B={b1, …,bm}, S  A* – множество всевозможных сообщений в алфавите А. Тогда функция F: S→B* – кодирование (преобразует множество сообщений в алфавит В). Если α
A* – множество всевозможных сообщений в алфавите А. Тогда функция F: S→B* – кодирование (преобразует множество сообщений в алфавит В). Если α  S, то F(α)=β B* – кодовое слово. Обратная функция F-1 (если она существует) называется декодированием.
S, то F(α)=β B* – кодовое слово. Обратная функция F-1 (если она существует) называется декодированием.
Задача кодирования сообщения ставится следующим образом. Требуется при заданных алфавитах А и В и множестве сообщений S найти такое кодирование F, которое обладает определенными свойствами (т.е. удовлетворяет заданным ограничениям) и оптимально в некотором смысле. Свойства, которые требуются от кодирования, могут быть различными:
1. Существование декодирования.
2. Помехоустойчивость или исправление ошибок: функция декодирования обладает свойством F-1(β)=F-1(β'), β~β' (эквивалентно β' с ошибкой).
3. Обладает заданной трудоемкостью (время, объем памяти).
Известны два класса методов кодирования дискретного источника информации: равномерное и неравномерное кодирование. Под равномерным кодированием понимается использование кодов со словами постоянной длины. Для того, чтобы декодирование равномерного кода было возможным, разным символам алфавита источника должны соответствовать разные кодовые слова. При этом длина кодового слова должна быть не меньше  символов, где m – размер исходного алфавита, n – размер кодового алфавита.
символов, где m – размер исходного алфавита, n – размер кодового алфавита.
Пример. Для кодирования источника, порождающего 26 букв латинского алфавита, равномерным двоичным кодом, требуется построить кодовые слова длиной не меньше 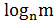 =5 бит.
=5 бит.
При неравномерном кодировании источника используются кодовые слова разной длины. Причем кодовые слова обычно строятся так, что часто встречающиеся символы кодируются более короткими кодовыми словами, а редкие символы – более длинными (за счет этого и достигается «сжатие» данных).
Кодирование целых чисел
Рассмотрим семейство методов, не учитывающих вероятности появления элементов. В общем случае никаких предположений о свойствах значений элементов не делается, просто каждому целому числу из определенного диапазона ставится в соответствие свое кодовое слово. Поэтому эту группу методов также называют представлением целых чисел (Representation of Integers).
Основная идея кодирования состоит в том, чтобы отдельно описывать порядок значения элемента xi («экспоненту» Ei) и отдельно – значащие цифры значения xi («мантиссу» Мi). Значащие цифры начинаются со старшей ненулевой цифры; порядок числа определяется позицией старшей ненулевой цифры в двоичной записи числа. Как и при десятичной записи, порядок равен числу цифр в записи числа без предшествующих незначащих нулей. Например, порядок двоичного числа 000001101 равен 4, а мантисса – 1101.
Рассмотрим две группы методов кодирования целых чисел. Условно их можно обозначить так:
Fixed + Variable (фиксированная длина экспоненты – переменная длина мантиссы).
Variable + Variable (переменная длина экспоненты – переменная длина мантиссы).
3.2.1 Коды класса Fixed + Variable
В кодах класса Fixed + Variable под запись значения порядка числа отводится фиксированное количество бит, а значение порядка числа определяет, сколько бит потребуется под запись мантиссы. Для кодирования целого числа необходимо произвести с числом две операции: определение порядка числа и выделение бит мантиссы (можно хранить в памяти готовую таблицу кодовых слов). Рассмотрим процесс построения кода данного класса на примере.
Пример. Пусть R=15 – количество бит исходного числа. Отведем E= 4 бита под экспоненту (порядок), т.к. R?24. При записи мантиссы можно сэкономить 1 бит: не писать первую единицу т.к. это всегда будет только единица. Таким образом, количество бит мантиссы равно количество бит для порядка минус 1.
Таблица 1. Код класса Fixed + Variable
| число
| кодовое слово
| длина кодового слова
|
| 0 1
| 0000 0001
| 4 4
|
| 2 3
| 0010 0 0010 1
| 5 5
|
| 4 5 6 7
| 0011 00 0011 01 0011 10 0011 11
| 6 6 6 6
|
| 8 9 10 … 15
| 0100 000 0100 001 0100 010 … 0100 111
| 7 7 7.. 7
|
| 16 17 …
| 0101 0000 0101 0001 …
| 8 8..
|
3.2.2 Коды класса Variable + Variable
В качестве кода числа записываем сначала подряд несколько нулей (их количество равно значению порядка числа), затем единицу как признак окончания экспоненты переменной длины, затем мантиссу переменной длины (как в кодах Fixed + Variable). Рассмотрим пример построение кода этого класса.
Таблица 2. Код класса Variable + Variable
| число
| кодовое слово
| длина кодового слова
|
| 0 1
| 1 0 1
| 1 2
|
| 2 3
| 00 1 0 00 1 1
| 4 4
|
| 4 5 6 7
| 000 1 00 000 1 01 000 1 10 000 1 11
| 6 6 6 6
|
| 8 9 10 …
| 0000 1 000 0000 1 001 0000 1 010 …
| 8 8 8
|
Если в рассмотренном выше коде исключить кодовое слово для нуля, то можно уменьшить длины кодовых слов на 1 бит, убрав первый нуль. В результате получаем гамма-код Элиаса.
Таблица 3. g - код Элиаса
| число
| кодовое слово
| длина кодового слова
|
|
|
|
|
| 2 3
| 01 0 01 1
| 3 3
|
| 4 5 6 7
| 00 1 00 00 1 01 00 1 10 00 1 11
| 5 5 5 5
|
| 8 9 10 …
| 000 1 000 000 1 001 000 1 010 …
| 7 7 7
|
Другим примером кода класса Variable + Variable является омега-код Элиаса (Ω-код Элиаса).В нем первое значение (кодовое слово для единицы) задается отдельно. Другие кодовые слова состоят из последовательности групп длиной L1, L2, … Lm, начинающихся с единицы. Конец всей последовательности задается нулем. Длина первой группы – 2 бита и далее длина каждой следующей группы равна значению битов предыдущей группы плюс 1. Значение битов последней группы является итоговым значением всей последовательности групп, т.е. первые m-1 групп служат для указания длины последней группы.
Таблица 4. Ω - код Элиаса
| число
| кодовое слово
| длина кодового слова
|
| 1 2 3
| 0 10 0 11 0
| 1 3 3
|
| 4 5 6 7
| 10 100 0 10 101 0 10 110 0 10 111 0
| 6 6 6 6
|
| 8 9.. 15
| 11 1000 0 11 1001 0 … 11 1111 0
| 7 7.. 7
|
| 16 17.. 31
| 10 100 10000 0 10 100 10001 0 … 10 100 11111 0
| 11 11.. 11
|
|
| 10 101 100000 0
|
|
При кодировании формируется сначала последняя группа, затем предпоследняя и т.д., пока процесс не будет завершен. При декодировании, наоборот, сначала считывается первая группа, по значению ее битов определяется длина следующей группы, или итоговое значение кода, если следующая группа – 0.
Рассмотренные типы кодов могут быть эффективны в следующих случаях
Вероятности чисел убывают с ростом значений элементов и их распределение близко к такому: P(x) >> P(x+1), при любом x, т.е. маленькие числа встречаются чаще, чем большие.
Диапазон значений входных элементов не ограничен или неизвестен. Например, при кодировании 32-битовых чисел реально большинство чисел маленькие, но могут быть и большие.
При использовании в составе других схем кодирования.
Алфавитное кодирование
Кодирование F может сопоставлять код всему сообщению из множества S как единому целому или строить код сообщения из кодов его частей. Элементарной частью сообщения является одна буква алфавита А={a1,a2,…,an}.
Пример 1. А={a1,a2,a3}, B={0,1} a1 →1001, a2 →0, a3→010.
Сообщение a2a1a2a3 → 010010010.
Пример 2. Азбука Морзе. Входной алфавит – английский. Наиболее часто встречающиеся буквы кодируются более короткими словами:
А > 01, В > 1000, С > 1010, D > 100, E > 0, ….
Побуквенное кодирование задается таблицей кодовых слов:σ = < α1→β1, …, αn → βn>, αi A, βi B*.Множество кодовых слов V={βi} называется множеством элементарных кодов. Побуквенное кодирование пригодно для любого множества сообщений S: F: A* →B*, αi1 …αik=α A*, F(α)=βi1…βik.
Количество букв в слове α=α1…αk называется длиной слова |α| = k. Пустое слово обозначим Λ. Если α=α1α2, то α1 – начало (префикс) слова α, α2 – окончание (постфикс) слова α.
Побуквенный код называется разделимым (или однозначно декодируемым), если любое сообщение из символов алфавита источника, закодированное этим кодом, может быть однозначно декодировано, т.е. если βi1 …βik = βj1 …βjt, то k=t и при любых s=1,…,k is=js, т.е. любое кодовое слово единственным образом разлагается на элементарные коды. Например, код из первого примера не является разделимым, поскольку кодовое слово 010010 может быть декодируемо двумя способами a3a3 или a2a1a2.
Побуквенный код называется префиксным, если в его множестве кодовых слов ни одно слово не является началом другого, т.е. элементарный код одной буквы не является префиксом элементарного кода другой буквы. Например, код из первого примера не является префиксным, поскольку элементарный код буквы a2 является префиксом элементарного кода буквы a3.
Утверждение. Префиксный код является разделимым.
Доказательство (от противного). Пусть префиксный код не является разделимым. Тогда существует такая кодовая последовательность β, что она представлена различными способами из элементарных кодов: β=βi1, …,βik = βj1, …,βjt (побитовое представление одинаковое) и существует L такое, что при любом S<L следует (βis= βjs) и (βit≠ βjt), т.е. начало каждого из этих представлений имеет одинаковую последовательность элементарных кодов. Уберем эту часть. Тогда βiL…βik = βjL, …,βjt, т.е. последовательности элементарных кодов разные и существует β/, что βiL=βjLβ/ или βjL=βiLβ/, т.е. βiL – начало βjL, или наоборот. Получили противоречие с префиксностью кода.
Заметим, что разделимый код может быть не префиксным.
Пример. Разделимый, но не префиксный код: A={a,b}, B={0,1}, φ = {a→0, b→01}
Приведем основные теоремы побуквенного кодирования.
Теорема(Крафт). Для того, чтобы существовал побуквенный двоичный префиксный код с длинами кодовых слов L1,…,Ln необходимо и достаточно, чтобы
 .
.
Доказательство. Докажем необходимость. Пусть существует префиксный код с длинами L1,…,Ln. Рассмотрим полное двоичное дерево. Каждая вершина закодирована последовательностью нулей и единиц (как показано на рисунке 2).

Рисунок 2 – Полное двоичное дерево с помеченными вершинами
В этом дереве выделим вершины, соответствующие кодовым словам. Тогда любые два поддерева, соответствующие кодовым вершинам дерева, не пересекаются, т.к. код префиксный. У i-того поддерева на r-том уровне – 2r-Li вершин. Всего вершин в поддереве 2r. Тогда  ,
,  , .
, .
Докажем достаточность утверждения. Пусть существует набор длин кодовых слов такой, что . Рассмотрим полное двоичное дерево с помеченными вершинами. Пусть длины кодовых слов упорядочены по возрастанию L1≤ L2≤ … ≤ Ln. Выберем в двоичном дереве вершину V1 на L1 уровне. Уберем поддерево с корнем в вершине V1. В оставшемся дереве возьмем вершину V2 на уровне L2 и удалим поддерево с корнем в этой вершине и т.д. Последовательности, соответствующие вершинам V1, V2,…, Vn образуют префиксный код.
Пример. Построить префиксный код с длинами L1=1, L2=2, L3=2 для алфавита A={a1,a2,a3}. Проверим неравенство Крафта для набора длин  . Неравенство выполняется и, следовательно, префиксный код с таким набором длин кодовых слов существует. Рассмотрим полное двоичное дерево с 23 помеченными вершинами и выберем вершины дерева, как описано выше. Тогда элементарные коды могут быть такими a1 →0, a2→10, a3 →11.
. Неравенство выполняется и, следовательно, префиксный код с таким набором длин кодовых слов существует. Рассмотрим полное двоичное дерево с 23 помеченными вершинами и выберем вершины дерева, как описано выше. Тогда элементарные коды могут быть такими a1 →0, a2→10, a3 →11.
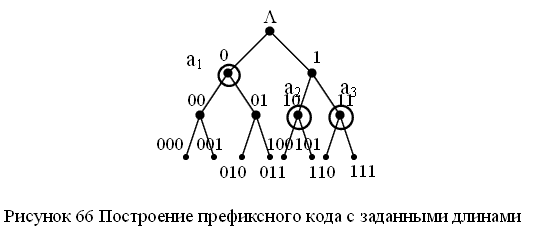
Рисунок 3 – Построение префиксного кода с заданными длинами
Процесс декодирования выглядит следующим образом. Просматриваем полученное сообщение, двигаясь по дереву. Если попадем в кодовую вершину, то выдаем соответствующую букву и возвращаемся в корень дерева и т.д.
Теорема (МакМиллан). Для того, чтобы существовал побуквенный двоичный разделимый код с длинами кодовых слов L1,…,Ln, необходимо и достаточно, чтобы .
Доказательство. Покажем достаточность. По теореме Крафта существует префиксный код с длинами L1,…,Ln, и он является разделимым.
Докажем необходимость утверждения. Рассмотрим тождество

Положим 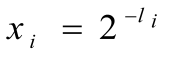 . Тогда тождество можно переписать следующим образом
. Тогда тождество можно переписать следующим образом
 ,
,
где  ,
,  – число всевозможных представлений числа j в виде суммы
– число всевозможных представлений числа j в виде суммы  . Сопоставим каждому представлению числа j в виде суммы последовательность нулей и единиц длины j по следующему правилу
. Сопоставим каждому представлению числа j в виде суммы последовательность нулей и единиц длины j по следующему правилу
 ,
,
где bs элементарный код длины s. Тогда различным представлениям числа j будут соответствовать различные кодовые слова, поскольку код является разделимым. Таким образом,  и
и  . Используя предельный переход получим
. Используя предельный переход получим 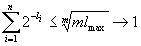 при
при  .
.
Пример. Азбука Морзе – это схема алфавитного кодирования
A>01, B>1000, C>1010, D>100, E>0, F>0010, G>110, H>0000, I>00, J>0111, K>101, L>0100, M>11, N>10, O>111, P>0110, Q>1101, R>010, S>000, T>1, U>001, V>0001, W>011, X>1001, Y>1011, Z>1100.
Неравенство МакМиллана для азбуки Морзе не выполнено, поскольку

Следовательно, этот код не является разделимым. На самом деле в азбуке Морзе имеются дополнительные элементы – паузы между буквами (и словами), которые позволяют декодировать сообщение. Эти дополнительные элементы определены неформально, поэтому прием и передача сообщений (особенно с высокой скоростью) является некоторым искусством, а не простой технической процедурой.
Алгоритм на псевдокоде.
Код Шеннона
Код Шеннона позволяет построить почти оптимальный код с длинами кодовых слов Li < - log pi +1. Тогда Lcp <H(p1, …,pn)+1. Код Шеннона строится следующим образом.
1. Упорядочим символы исходного алфавита А={a1,a2,…,an} по убыванию их вероятностей: p1≥p2≥p3≥…≥pn.
2. Составим нарастающие суммы вероятностей Qi:
3. Q0=0, Q1=p1, Q2=p1+p2, Q3=p1+p2+p3, …, Qn=1.
4. Представим Qi в двоичной системе счисления и возьмем в качестве кодового слова первые  знаков после запятой.
знаков после запятой.
Для вероятностей, представленных в виде десятичных дробей, удобно определить длину кодового слова Li из соотношения
 ,
,  .
.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице.
Таблица 6. Код Шеннона

Построенный код является префиксным. Вычислим среднюю длину кодового слова и сравним ее с энтропией. Значение энтропии вычислено при построении кода Хаффмана (H = 2.37).
Lср= 0.36.2+(0.18+0.18).3+(0.12+0.09+0.07).4=2.92< 2.37+1
Алгоритм на псевдокоде
Код Фано
Метод Фано построения префиксного почти оптимального кода заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на две части так, чтобы суммы вероятностей букв, входящих в эти части, как можно меньше отличались друг от друга. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по одной букве.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице и на рисунке.
Таблица 7. Код Фано


Рисунок 6 – Кодовое дерево для кода Фано
Полученный код является префиксным и почти оптимальным со средней длиной кодового слова
Lср=0.36.2+0.18.2+0.18.2+0.12.3+0.09.4+0.07.4=2.44
Алгоритм на псевдокоде
Алгоритм Фано
P-массив вероятностей, упорядоченный по убыванию
L - левая граница обрабатываемой части массива P
R- правая граница обрабатываемой части массива P
k - длина уже построенной части элементарных кодов
С - массив элементарных кодов
Length - массив длин элементарных кодов.
Fano(L,R,k)
IF (L<R)
k:=k+1
m:=Med(L,R)
DO (i=L,…,R)
IF (i≤m) C[i,k]:=0, Length[i]:= Length[i]+1
ELSE C[i,k]:=1, Length[i]:= Length[i]+1
FI
OD
Fano (L,m,k)
Fano (m+1,R,k)
FI
Функция Med находит медиану массива P, т.е. такой индекс L≤m≤R, что
величина  минимальна.
минимальна.
Med (L,R)
SL:=0
DO (i=L,…,R-1)
SL:=SL+p[i] <сумма элементов первой части>
OD
SR:=p[R] <сумма элементов второй части>
m:=R
DO (SL ≥ SR)
m:=m-1
SL:=SL-p[m]
SR:=SR+p[m]
OD
Med:=m
Вариант 1
1. а) 58510; б) 67310; в) 62610.
2. а) 0101010101012; б) 100110002; в) 0100000101102.
3. IBM PC.
4. 8A AE AC AF EC EE E2 A5 E0.
5. а) 22410; б) 25310; в) 22610.
6. а) 11510; б) –3410; в) –7010.
7. а) 2249110; б) 2383210.
8. а) 2085010; б) –1864110.
9. а) 0011010111010110; б) 1000000110101110.
10. а) –578,375; б) –786,375.
11. а) 408E130000000000; б) C077880000000000.
Вариант 2
1. а) 28510; б) 84610; в) 16310.
2. а) 0001010100012; б) 0101010100112; в) 0110100010002.
3. Автоматизация.
4. 50 72 6F 67 72 61 6D.
5. а) 24210; б) 13510; в) 24810.
6. а) 8110; б) –4010; в) –2410.
7. а) 1850910; б) 2818010.
8. а) 2888210; б) –1907010.
9. а) 0110010010010101; б) 1000011111110001.
10. а) –363,15625; б) –487,15625.
11. а) C075228000000000; б) 408B9B0000000000.
Вариант 3
1. а) 90510; б) 50410; в) 51510.
2. а) 0100100101002; б) 0010000001002; в) 011100002.
3. Информатика.
4. 50 72 6F 63 65 64 75 72 65.
5. а) 20710; б) 21010; в) 22610.
6. а) 9810; б) –11110; в) –9510.
7. а) 1983510; б) 2224810.
8. а) 1815610; б) –2884410.
9. а) 0111100011001000; б) 1111011101101101.
10. а) 334,15625; б) 367,15625.
11. а) C07C08C000000000; б) C0811B0000000000.
Вариант 4
1. а) 48310; б) 41210; в) 73810.
2. а) 0011010110002; б) 1000100100102; в) 0101010001102.
3. Computer.
4. 84 88 91 8A 8E 82 8E 84.
5. а) 18510; б) 22410; в) 19310.
6. а) 8910; б) –6510; в) –810.
7. а) 2940710; б) 2534210.
8. а) 2364110; б) –2307010.
9. а) 0111011101000111; б) 1010110110101110.
10. а) 215,15625; б) –143,375.
11. а) C071760000000000; б) 407FF28000000000.
Вариант 5
1. а) 8810; б) 15310; в) 71810.
2. а) 0001100001002; б) 1001100001112; в) 1001000110002.
3. Printer.
4. 43 4F 4D 50 55 54 45 52.
5. а) 15810; б) 13410; в) 19010.
6. а) 6410; б) –10410; в) –4710.
7. а) 3053910; б) 2614710.
8. а) 2258310; б) –2812210.
9. а) 0100011011110111; б) 1011101001100000.
10. а) –900,546875; б) –834,5.
11. а) 407C060000000000; б) C0610C0000000000.
Вариант 6
1. а) 32510; б) 11210; в) 71310.
2. а) 1001011000102; б) 0010010001102; в) 0111001101102.
3. компьютеризация.
4. 50 52 49 4E 54.
5. а) 23910; б) 16010; в) 18210.
6. а) 5510; б) –8910; в) –2210.
7. а) 1786310; б) 2589310.
8. а) 2425510; б) –2668610.
9. а) 0000010101011010; б) 1001110100001011.
10. а) –969,15625; б) –434,15625.
11. а) C082B30000000000; б) C086EB0000000000.
Вариант 7
1. а) 46410; б) 65210; в) 9310.
2. а) 0001100100102; б) 0011000110002; в) 0110000100002.
3. YAMAHA.
4. 4D 4F 44 45 4D.
5. а) 23710; б) 23610; в) 24010.
6. а) 9510; б) –6810; в) –7710.
7. а) 2865810; б) 2961410.
8. а) 3101410; б) –2401310.
9. а) 0001101111111001; б) 1011101101001101.
10. а) –802,15625; б) –172,375.
11. а) C085EB0000000000; б) C07D428000000000.
Литература
Основная:
1. Панин В. В. Основы теории информации: учеб. пособие для вузов /.- М.: БИНОМ: Лаб. базовых знаний, 2007.
2. Хохлов Г. И. Основы теории информации: учеб. пособие для вузов / Г. И. Хохлов; пер. Хохлов Г. И.- М.: Академия, 2008
Дополнительная:
3. Стариченко Б.Е. Теоретические основы информатики: учеб. пособие для студ. вузов. – М.: Горячая линия – Телеком, 2004
4. Информатика: базовый курс: учебное пособие для вузов. / под. ред. С.В.Симоновича. – 2-е изд. – СПб.: Питер, 2004
5. Сырецкий Г.А. Информатика. Фундаментальный курс. Т.1 Основы вычислительной техники. – СПб.: БХВ-Петербург, 2005
Е.Е. Минина
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ИНФОРМАТИКИ
Методические указания по выполнению самостоятельной работы для аспирантов очной и заочной форм обучения на базе высшего образования
для специальностей 05.12.13 «Системы, сети и устройства телекоммуникаций» 08.00.05 «Экономика и управление народным хозяйством (по отраслям)»
05.13.15 «Вычислительные машины, комплексы и компьютерные сети»
Екатеринбург
ББК 22.19
УДК 517.9
Рецензент: к.п.н., доцент кафедры информатики вычислительной техники и методики обучения информатике А.И. Газейкина
Минина Е.Е.
Теоретические основы информатики: Методические указания к самостоятельным работам / Е.Е. Минина. — Екатеринбург: УрТИСИ ГОУ ВПО «СибГУТИ», 2010. —29с.
Методические указания содержат темы для подготовки рефератов, теоретический материал и задания по темам:
Рекомендовано НМС УрТИСИ ГОУ ВПО СибГУТИ в качестве методических указаний по выполнению самостоятельной работы аспирантами для специальностей 05.12.13 «Системы, сети и устройства телекоммуникаций», 08.00.05 «Экономика и управление народным хозяйством (по отраслям)», 05.13.15 «Вычислительные машины, комплексы и компьютерные сети»
ББК 22.19
УДК 517.9
Кафедра информационных систем и технологий
Ó УрТИСИ ГОУ ВПО «СибГУТИ», 2010
Содержание
1 Пояснительная записка. 4
2 Темы для подготовки рефератов. 5
3 Элементы теории кодирования. 6
3.1 Основные понятия теории кодирования. 6
3.2 Кодирование целых чисел. 8
3.3 Алфавитное кодирование. 11
3.4 Оптимальное алфавитное кодирование. 14
3.5 Почти оптимальное алфавитное кодирование. 18
Литература. 29
Пояснительная записка
Данное пособие разработано с целью оказания методической помощи аспирантам во время их самостоятельной работы по дисциплине «Теоретические основы информатики».
В пособии приведены темы для подготовки и написания рефератов. Темы отражают круг основных вопросов дисциплины. Так же приведен теоретический материал для углубления и осознания некоторых тем курса. Пособие содержит перечень рекомендованной основной и дополнительной литературы.
Рабочей программой курса предусмотрены следующие виды самостоятельной работы студентов:
| Виды и содержание самостоятельной работы
| Кол-во часов
|
| 1. Подготовка реферата
|
|
| 2. Изучение дополнительного материала по изучаемым темам и подготовка к лабораторным работам
|
|
| 3. Подготовка и написание статьи
|
|
| Итого:
|
|
2 Темы для подготовки рефератов
1. Информация и ее сущность в информационно-энергетической концепции строения Вселенной.
2. Энтропия и количество информации по К. Шеннону и их свойства.
3. Синтактические меры количества и прагматические характеристики качества информации.
4. Информация и работы Чижевского.
5. Учение В.И. Вернадского о ноосфере и информация.
6. Психология информатики.
7. Модели и моделирование.
8. Предельные теоремы (законы) сложных систем.
9. Самореферентные системы.
10. Квантовые вычислители и вычисления.
11. Хаос и информатика.
12. Синергетика.
13. Биоэнергоинформатика.
14. Компьютерная лингвистика.
15. Компьютерная преступность и правовая охрана интеллектуальной собственности.
16. Технологический процесс в системных методах исследования.
17. Метрическое пространство. (n-мерное Евклидово пространство.Функциональное пространство: основные понятия, метрики, неравенства.)
18. Линейные пространства. Линейная зависимость. Функционалы. Нормированные пространства.
19. Случайные сигналы и их модели.
20. Статический анализ сигналов: анализ распределений, корреляционный, спектральный. Фильтрация сигналов.
21. Теоремы Шеннона об оптимальном кодировании информации.
22. Канал связи и его пропускная способность. Теорема Шеннона о скорости передачи информации по каналу связи.
23. Помехоустойчивые коды.
24. Множества и пространства сигналов. Отображения и функционалы от сигналов. Преобразования Фурье и представление сигналов рядами.
25. Аналоговые, когнитивные и нейрокомпьютерные средства информатики.
26. Языки программирования. Перспективы развития.
27. Эстетика и информатика.
28. Фракталы и области их применения.
29. Представление знаний.
30. Нейрокомпьютеры и интеллектуальные сети.
Элементы теории кодирования
Основные понятия теории кодирования
Теория кодирования и теория информации возникли в начале XX века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К. Шеннона, которые заложили фундамент для дальнейших исследований в этой области.
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов:
Рисунок 1 -Модель системы передачи сигналов
Кодирование – способ представления информации в виде, удобном для хранения и передачи.
В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач программирования:
1. Представление данных произвольной структуры (числа, текст, графика) в памяти компьютера.
2. Обеспечение помехоустойчивости при передаче данных по каналам связи.
3. Сжатие информации в базах данных.
Под сжатием понимается компактное представление данных, осуществляемое за счет избыточности, содержащейся в сообщениях. Большое значение для практического использования имеет неискажающее сжатие, позволяющее полностью восстановить исходное сообщение. При неискажающем сжатии происходит кодирование сообщения перед началом передачи или хранения, а после окончания процесса сообщение однозначно декодируется (это соответствует модели канала без шума (помех)).
Начальным звеном в приведенной выше модели являетсяисточник информации. Мы будем рассматривать дискретные источники, в которых выходом является последовательность символов некоторого фиксированного алфавита. Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 32 русских букв, пробела и знаков препинания.
Кодирование дискретного источника заключается в сопоставлении символов алфавита А источника символам некоторого другого алфавита В. Причем обычно символу исходного алфавита А ставится в соответствие не






