Входной поток для кодирования рассматривается как последовательность из нулей и единиц. Идея кодирования заключается в том, чтобы кодировать последовательности одинаковых элементов (например, нулей) как целые числа, указывающие количество элементов в этой последовательности. Последовательность одинаковых элементов называется серией, количество элементов в ней – длиной серии. Например, входную последовательность (общая длина 31бит) можно разбить на серии, а затем закодировать их длины.
000000 1 00000 1 0000000 1 1 00000000 1
Используем, например, Ω-код Элиаса. Т.к. в коде нет кодового слова для нуля, то будем кодировать длину серии +1, т.е. последовательность 7 6 8 1 9
7 6 8 1 9 => 00111 00110 0001000 1 0001001
Длина полученной кодовой последовательности равна 25 бит. Метод актуален для кодирования данных, в которых есть длинные последовательности одинаковых бит. В нашем примере, если P(0) >> P(1).
Алфавитное кодирование
Кодирование F может сопоставлять код всему сообщению из множества S как единому целому или строить код сообщения из кодов его частей. Элементарной частью сообщения является одна буква алфавита А={a1,a2,…,an}.
Пример 1. А={a1,a2,a3}, B={0,1} a1 →1001, a2 →0, a3→010.
Сообщение a2a1a2a3 → 010010010.
Пример 2. Азбука Морзе. Входной алфавит – английский. Наиболее часто встречающиеся буквы кодируются более короткими словами:
А > 01, В > 1000, С > 1010, D > 100, E > 0, ….
Побуквенное кодирование задается таблицей кодовых слов:σ = < α1→β1, …, αn → βn>, αi  A, βi B*.Множество кодовых слов V={βi} называется множеством элементарных кодов. Побуквенное кодирование пригодно для любого множества сообщений S: F: A* →B*, αi1 …αik=α A*, F(α)=βi1…βik.
A, βi B*.Множество кодовых слов V={βi} называется множеством элементарных кодов. Побуквенное кодирование пригодно для любого множества сообщений S: F: A* →B*, αi1 …αik=α A*, F(α)=βi1…βik.
Количество букв в слове α=α1…αk называется длиной слова |α| = k. Пустое слово обозначим Λ. Если α=α1α2, то α1 – начало (префикс) слова α, α2 – окончание (постфикс) слова α.
Побуквенный код называется разделимым (или однозначно декодируемым), если любое сообщение из символов алфавита источника, закодированное этим кодом, может быть однозначно декодировано, т.е. если βi1 …βik = βj1 …βjt, то k=t и при любых s=1,…,k is=js, т.е. любое кодовое слово единственным образом разлагается на элементарные коды. Например, код из первого примера не является разделимым, поскольку кодовое слово 010010 может быть декодируемо двумя способами a3a3 или a2a1a2.
Побуквенный код называется префиксным, если в его множестве кодовых слов ни одно слово не является началом другого, т.е. элементарный код одной буквы не является префиксом элементарного кода другой буквы. Например, код из первого примера не является префиксным, поскольку элементарный код буквы a2 является префиксом элементарного кода буквы a3.
Утверждение. Префиксный код является разделимым.
Доказательство (от противного). Пусть префиксный код не является разделимым. Тогда существует такая кодовая последовательность β, что она представлена различными способами из элементарных кодов: β=βi1, …,βik = βj1, …,βjt (побитовое представление одинаковое) и существует L такое, что при любом S<L следует (βis= βjs) и (βit≠ βjt), т.е. начало каждого из этих представлений имеет одинаковую последовательность элементарных кодов. Уберем эту часть. Тогда βiL…βik = βjL, …,βjt, т.е. последовательности элементарных кодов разные и существует β/, что βiL=βjLβ/ или βjL=βiLβ/, т.е. βiL – начало βjL, или наоборот. Получили противоречие с префиксностью кода.
Заметим, что разделимый код может быть не префиксным.
Пример. Разделимый, но не префиксный код: A={a,b}, B={0,1}, φ = {a→0, b→01}
Приведем основные теоремы побуквенного кодирования.
Теорема(Крафт). Для того, чтобы существовал побуквенный двоичный префиксный код с длинами кодовых слов L1,…,Ln необходимо и достаточно, чтобы
 .
.
Доказательство. Докажем необходимость. Пусть существует префиксный код с длинами L1,…,Ln. Рассмотрим полное двоичное дерево. Каждая вершина закодирована последовательностью нулей и единиц (как показано на рисунке 2).

Рисунок 2 – Полное двоичное дерево с помеченными вершинами
В этом дереве выделим вершины, соответствующие кодовым словам. Тогда любые два поддерева, соответствующие кодовым вершинам дерева, не пересекаются, т.к. код префиксный. У i-того поддерева на r-том уровне – 2r-Li вершин. Всего вершин в поддереве 2r. Тогда  ,
,  , .
, .
Докажем достаточность утверждения. Пусть существует набор длин кодовых слов такой, что . Рассмотрим полное двоичное дерево с помеченными вершинами. Пусть длины кодовых слов упорядочены по возрастанию L1≤ L2≤ … ≤ Ln. Выберем в двоичном дереве вершину V1 на L1 уровне. Уберем поддерево с корнем в вершине V1. В оставшемся дереве возьмем вершину V2 на уровне L2 и удалим поддерево с корнем в этой вершине и т.д. Последовательности, соответствующие вершинам V1, V2,…, Vn образуют префиксный код.
Пример. Построить префиксный код с длинами L1=1, L2=2, L3=2 для алфавита A={a1,a2,a3}. Проверим неравенство Крафта для набора длин  . Неравенство выполняется и, следовательно, префиксный код с таким набором длин кодовых слов существует. Рассмотрим полное двоичное дерево с 23 помеченными вершинами и выберем вершины дерева, как описано выше. Тогда элементарные коды могут быть такими a1 →0, a2→10, a3 →11.
. Неравенство выполняется и, следовательно, префиксный код с таким набором длин кодовых слов существует. Рассмотрим полное двоичное дерево с 23 помеченными вершинами и выберем вершины дерева, как описано выше. Тогда элементарные коды могут быть такими a1 →0, a2→10, a3 →11.
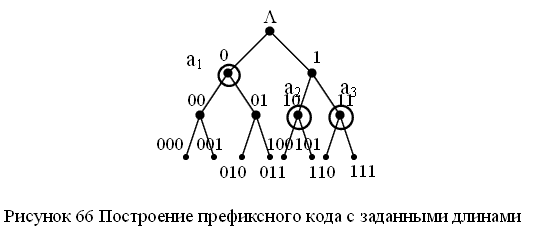
Рисунок 3 – Построение префиксного кода с заданными длинами
Процесс декодирования выглядит следующим образом. Просматриваем полученное сообщение, двигаясь по дереву. Если попадем в кодовую вершину, то выдаем соответствующую букву и возвращаемся в корень дерева и т.д.
Теорема (МакМиллан). Для того, чтобы существовал побуквенный двоичный разделимый код с длинами кодовых слов L1,…,Ln, необходимо и достаточно, чтобы .
Доказательство. Покажем достаточность. По теореме Крафта существует префиксный код с длинами L1,…,Ln, и он является разделимым.
Докажем необходимость утверждения. Рассмотрим тождество

Положим 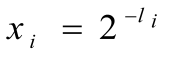 . Тогда тождество можно переписать следующим образом
. Тогда тождество можно переписать следующим образом
 ,
,
где  ,
,  – число всевозможных представлений числа j в виде суммы
– число всевозможных представлений числа j в виде суммы  . Сопоставим каждому представлению числа j в виде суммы последовательность нулей и единиц длины j по следующему правилу
. Сопоставим каждому представлению числа j в виде суммы последовательность нулей и единиц длины j по следующему правилу
 ,
,
где bs элементарный код длины s. Тогда различным представлениям числа j будут соответствовать различные кодовые слова, поскольку код является разделимым. Таким образом,  и
и  . Используя предельный переход получим
. Используя предельный переход получим 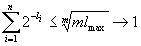 при
при  .
.
Пример. Азбука Морзе – это схема алфавитного кодирования
A>01, B>1000, C>1010, D>100, E>0, F>0010, G>110, H>0000, I>00, J>0111, K>101, L>0100, M>11, N>10, O>111, P>0110, Q>1101, R>010, S>000, T>1, U>001, V>0001, W>011, X>1001, Y>1011, Z>1100.
Неравенство МакМиллана для азбуки Морзе не выполнено, поскольку

Следовательно, этот код не является разделимым. На самом деле в азбуке Морзе имеются дополнительные элементы – паузы между буквами (и словами), которые позволяют декодировать сообщение. Эти дополнительные элементы определены неформально, поэтому прием и передача сообщений (особенно с высокой скоростью) является некоторым искусством, а не простой технической процедурой.






